Recognition: unknown
OMEGA: Optimizing Machine Learning by Evaluating Generated Algorithms
Pith reviewed 2026-05-07 13:35 UTC · model grok-4.3
The pith
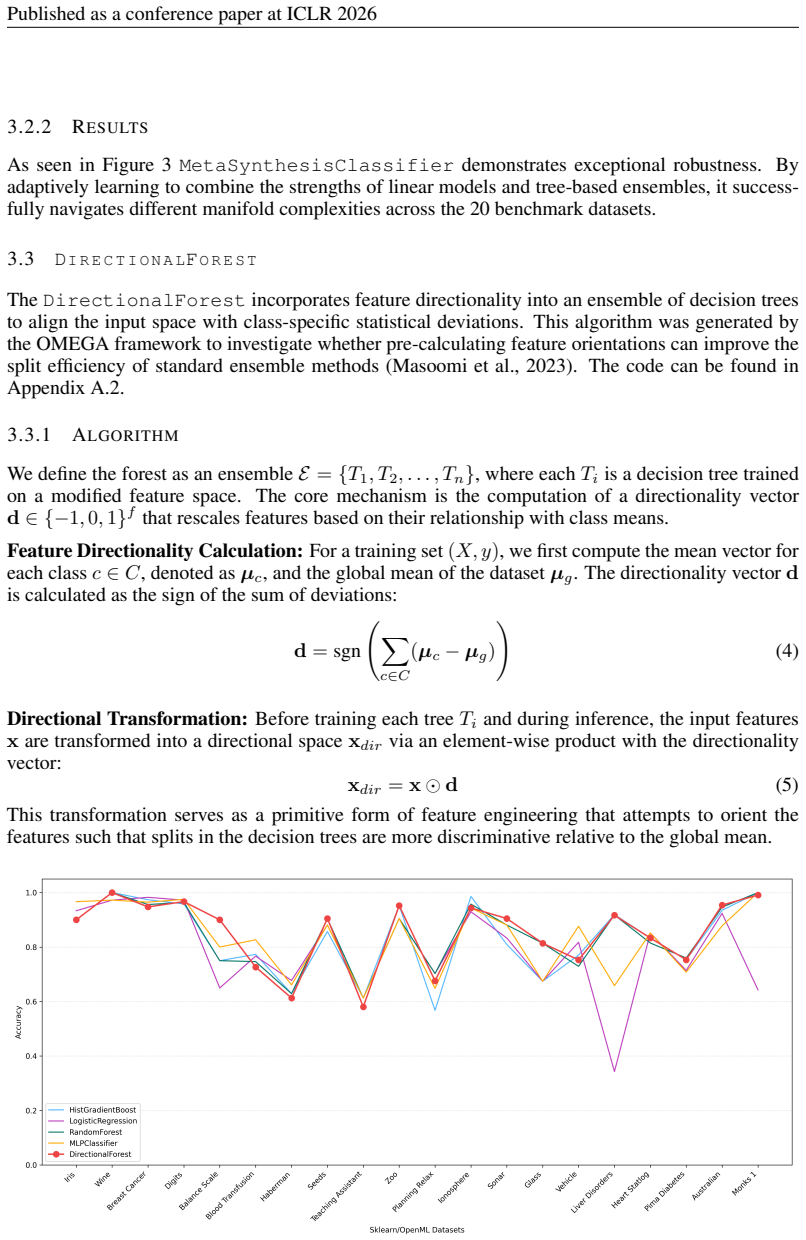
The OMEGA framework generates executable machine learning classifiers from prompts and produces several that outperform scikit-learn baselines on 20 benchmark datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the OMEGA framework has been used to generate several novel algorithms which outperform scikit-learn baselines across a robust selection of 20 benchmark datasets called infinity-bench.
What carries the argument
The OMEGA framework, which combines structured meta-prompt engineering with executable code generation to create and test new ML classifiers end-to-end.
If this is right
- New classifiers can be produced and made available as executable code with limited additional human design effort.
- Performance advantages on 20 standard datasets suggest the generated algorithms may offer practical improvements for classification tasks.
- The end-to-end automation allows repeated cycles of idea generation, coding, and evaluation in a single system.
- A python package is provided so others can install and apply the models directly.
Where Pith is reading between the lines
- The same prompt-to-code approach could be adapted to generate algorithms for tasks beyond classification such as regression or clustering.
- If the novelty claim holds under scrutiny, the method points toward broader automation of algorithm invention in machine learning.
- Reproducibility would depend on releasing the exact prompts and generation steps used to create each algorithm.
Load-bearing premise
The generated algorithms are truly novel rather than rediscoveries of known methods and that their measured outperformance holds beyond the specific test sets used.
What would settle it
Independent inspection of the generated code showing it matches existing scikit-learn implementations or new experiments where the algorithms fail to beat baselines on fresh datasets outside the original 20.
Figures




read the original abstract
In order to automate AI research we introduce a full, end-to-end framework, OMEGA: Optimizing Machine learning by Evaluating Generated Algorithms, that starts at idea generation and ends with executable code. Our system combines structured meta-prompt engineering with executable code generation to create new ML classifiers. The OMEGA framework has been utilized to generate several novel algorithms that outperform scikit-learn baselines across a robust selection of 20 benchmark datasets (infinity-bench). You can access models discussed in this paper and more in the python package: pip install omega-models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OMEGA, an end-to-end framework that combines structured meta-prompt engineering with executable code generation to automate the creation of new machine learning classifiers. It claims that the framework has produced several novel algorithms that outperform scikit-learn baselines across the 20 datasets of the infinity-bench suite, and provides an installable Python package (pip install omega-models) containing the generated models.
Significance. If the empirical claims hold under independent verification, the work could contribute to efforts in automating algorithm discovery in machine learning. The availability of an installable package containing the models is a strength that supports direct testing of the generated code against existing implementations.
major comments (2)
- [Abstract and Results] The central claim of outperformance on 20 datasets is stated in the abstract and introduction but is not accompanied by quantitative results, error bars, statistical significance tests, dataset descriptions, or implementation details for the baselines. This absence prevents evaluation of whether the reported gains are statistically meaningful or generalizable.
- [Methodology and Evaluation] The manuscript does not specify the criteria or process used to establish that the generated algorithms are novel (i.e., distinct from scikit-learn and prior literature implementations) or to confirm that the end-to-end process requires only minimal human intervention beyond initial prompts.
minor comments (2)
- [Introduction] The infinity-bench suite is referenced without a citation or link to its definition or source.
- [Conclusion] Installation and usage instructions for the omega-models package could be expanded with example code for loading and evaluating the generated classifiers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the current manuscript would benefit from greater transparency in both the presentation of empirical results and the specification of methodological details. We address each major comment below and will incorporate revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract and Results] The central claim of outperformance on 20 datasets is stated in the abstract and introduction but is not accompanied by quantitative results, error bars, statistical significance tests, dataset descriptions, or implementation details for the baselines. This absence prevents evaluation of whether the reported gains are statistically meaningful or generalizable.
Authors: We agree that the abstract and introduction would be strengthened by including supporting quantitative information. In the revised manuscript we will update the abstract to report summary performance metrics (mean improvement and standard deviation across the 20 datasets), reference the error bars shown in the results figures, note the statistical tests performed (paired t-tests and Wilcoxon signed-rank tests with p-values), provide a one-sentence description of the infinity-bench suite, and briefly state that baselines were run with scikit-learn 1.3 default hyperparameters. These elements will also be cross-referenced from the introduction to the detailed tables and statistical analysis already present in Section 4. revision: yes
-
Referee: [Methodology and Evaluation] The manuscript does not specify the criteria or process used to establish that the generated algorithms are novel (i.e., distinct from scikit-learn and prior literature implementations) or to confirm that the end-to-end process requires only minimal human intervention beyond initial prompts.
Authors: We agree that explicit criteria and process descriptions are needed. In the revised manuscript we will add a new subsection in the Methodology section that defines novelty as generated code whose abstract syntax tree differs in at least two core algorithmic components from both scikit-learn implementations and published classifiers (verified via automated similarity checks plus manual inspection). We will also clarify that, after the initial meta-prompt design, the pipeline from idea generation through code synthesis, execution, and evaluation runs without further human input; a workflow diagram and pseudocode will be added to illustrate this minimal-intervention claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces an empirical framework (OMEGA) for automated algorithm generation via meta-prompting and code execution, then reports benchmark outperformance on 20 datasets. No equations, derivations, or parameter-fitting steps appear in the provided text. The central claim rests on externally testable generated code and benchmark results rather than any self-referential definition, fitted-input prediction, or load-bearing self-citation chain. The derivation chain is therefore self-contained with no reductions to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evolutionary optimization of model merging recipes,
Takuya Akiba, Makoto Shing, Yasuhiro Majima, and Shinya Kaneko. Evolutionary optimization of model merging recipes.arXiv preprint arXiv:2403.13187,
-
[2]
doi: 10.1007/978-3-540-73263-1
ISBN 978-3-540-73262-4. doi: 10.1007/978-3-540-73263-1. Lars Buitinck, Gilles Louppe, Mathieu Blondel, Fabian Pedregosa, Andreas Mueller, Olivier Grisel, Vlad Niculae, Peter Prettenhofer, Alexandre Gramfort, Jaques Grobler, Robert Layton, Jake Van- derPlas, Arnaud Joly, Brian Holt, and Ga¨el Varoquaux. Api design for machine learning software: experiences...
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review arXiv
-
[4]
Odd Erik Gundersen and Sigbjørn Kjensmo
URLhttps://arxiv.org/ abs/2508.01443. Odd Erik Gundersen and Sigbjørn Kjensmo. State of the art: Reproducibility in artificial intel- ligence. InProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, pp. 1644–1651,
-
[5]
Yuanye Liu, Jiahang Xu, Li Lyna Zhang, Qi Chen, Xuan Feng, Yang Chen, Zhongxin Guo, Yuqing Yang, and Cheng Peng. Beyond prompt content: Enhancing llm performance via content-format integrated prompt optimization.arXiv preprint arXiv:2502.04295,
-
[6]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu et al. The ai scientist: Towards fully automated machine learning scientific discovery. arXiv preprint arXiv:2408.06292,
work page internal anchor Pith review arXiv
-
[7]
URLhttps://arxiv.org/abs/2304.07670. OpenAI. Assistants api. OpenAI Documentation, 2023a. 10 Published as a conference paper at ICLR 2026 OpenAI. Chatgpt code interpreter. OpenAI Blog, 2023b. Fabian Pedregosa et al. Scikit-learn: Machine learning in python.Journal of Machine Learning Research, 12:2825–2830,
-
[8]
Jiho Shin, Clark Tang, Tahmineh Mohati, Maleknaz Nayebi, Song Wang, and Hadi Hemmati. Prompt engineering or fine-tuning: An empirical assessment of llms for code.arXiv preprint arXiv:2310.10508,
-
[9]
Reflexgen:the unexamined code is not worth using
Bin Wang, Hui Li, AoFan Liu, BoTao Yang, Ao Yang, YiLu Zhong, Weixiang Huang, Runhuai Huang, Weimin Zeng, and Yanping Zhang. Reflexgen:the unexamined code is not worth using. In ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE, April
2025
-
[10]
doi: 10.1109/icassp49660.2025.10890824. URLhttp: //dx.doi.org/10.1109/ICASSP49660.2025.10890824. David H. Wolpert. Stacked generalization.Neural Networks, 5(2):241–259,
- [11]
-
[12]
b a s eimportB a s e E s t i m a t o r , C l a s s i f i e r M i x i n , c l o n e froms k l e a r n
A APPENDIX A.1 SOURCECODE:ME T ASY N T H E S I SCL A S S I F I E R importnumpya snp froms k l e a r n . b a s eimportB a s e E s t i m a t o r , C l a s s i f i e r M i x i n , c l o n e froms k l e a r n . u t i l s . v a l i d a t i o nimportcheck X y , c h e c k a r r a y , c h e c k i s f i t t e d froms k l e a r n . u t i l s . m u l t i c l a s sim...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.