Recognition: unknown
ProMax: Exploring the Potential of LLM-derived Profiles with Distribution Shaping for Recommender Systems
Pith reviewed 2026-05-07 12:56 UTC · model grok-4.3
The pith
LLM-derived user profiles can guide recommender models via dual distribution reshaping to better predict preferences on unseen items.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
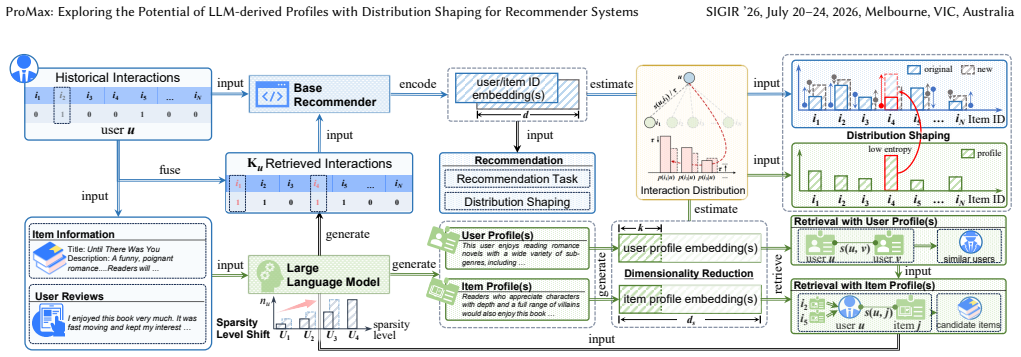
We revisit profiles from a retrieval perspective and propose a simple yet effective recommendation framework built upon distribution shaping (ProMax). We begin by employing dense retrieval to uncover the collaborative relationships between user and item profiles within the feature space. Based on this insight, we introduce a dual distribution-reshaping process, in which the profile distribution acts as a guiding signal to steer the recommendation model toward learning user preferences for unseen items beyond the scope of observed interactions.
What carries the argument
The dual distribution-reshaping process, in which the profile distribution serves as a guiding signal to steer the model toward preferences for unseen items.
If this is right
- ProMax improves performance when added to four classic recommendation methods across three public datasets.
- It outperforms prior LLM-based recommendation approaches that rely on nonlinear alignment.
- The profile distribution successfully guides learning for items outside observed user interactions.
- Distribution shaping preserves semantic content better than fusion strategies used in earlier work.
Where Pith is reading between the lines
- The same reshaping idea could be tested on sequential or graph-based recommenders to see if the guiding effect generalizes.
- If the distribution signal works reliably, systems might reduce the frequency of expensive LLM calls at inference time.
- Applying the dual reshaping to cross-domain or multi-modal profiles offers a direct next experiment.
Load-bearing premise
The profile distribution can serve as an effective guiding signal to steer the model toward learning preferences for unseen items while avoiding semantic loss and without introducing new biases from the reshaping process.
What would settle it
Running the reshaping step on a dataset and finding that accuracy on held-out items does not rise while a separate semantic similarity check between original and reshaped profiles drops would falsify the claim.
Figures







read the original abstract
The remarkable text understanding and generation capabilities of large language models (LLMs) have revitalized the field of general recommendation based on implicit user feedback. Rather than deploying LLMs directly as recommendation models, a more flexible paradigm leverages their ability to interpret users' historical interactions and semantic contexts to extract structured profiles that characterize user preferences. These profiles can be further transformed into actionable high-dimensional representations, serving as powerful signals to augment and strengthen recommendation models. However, the mechanism by which such profiles enhance recommendation performance within the feature space remains insufficiently understood. Moreover, existing studies predominantly rely on nonlinear alignment and fusion strategies to incorporate these profiles, which often lead to semantic loss and fail to fully exploit their potential. To address these limitations, we revisit profiles from a retrieval perspective and propose a simple yet effective recommendation framework built upon distribution shaping (ProMax) in this paper. We begin by employing dense retrieval to uncover the collaborative relationships between user and item profiles within the feature space. Based on this insight, we introduce a dual distribution-reshaping process, in which the profile distribution acts as a guiding signal to steer the recommendation model toward learning user preferences for unseen items beyond the scope of observed interactions. We apply ProMax to four classic recommendation methods on three public datasets. The results indicate that ProMax substantially improves base model performance and outperforms existing LLM-based recommendation approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProMax, a recommendation framework that extracts LLM-derived user and item profiles, uses dense retrieval to uncover collaborative relationships in feature space, and applies a dual distribution-reshaping process in which the profile distribution serves as a guiding signal to steer classic recommendation models toward learning preferences for unseen items. The approach is applied to four base models on three public datasets, with claims of substantial performance gains over the base models and existing LLM-based recommendation methods while avoiding semantic loss from nonlinear fusion.
Significance. If the distribution-reshaping mechanism can be shown to preserve profile semantics and avoid introducing new biases, the work would offer a simple, retrieval-based alternative to nonlinear alignment strategies for integrating LLM profiles, potentially improving the effectiveness and interpretability of hybrid LLM-augmented recommender systems.
major comments (2)
- [§3.2] §3.2 (Distribution Reshaping): The central claim that the dual reshaping process steers learning for unseen items without semantic loss or new biases is load-bearing, yet the manuscript provides no direct measurements (e.g., KL divergence between original and reshaped profile distributions or cosine similarity of embeddings before/after reshaping) to isolate this effect from implicit regularization or added signal volume.
- [§4.3, Table 2] §4.3 and Table 2 (Experimental Results): Performance improvements are reported across four base models and three datasets, but the absence of ablations that disable the reshaping component (while retaining profile signals) or compare against simple concatenation baselines leaves open the possibility that gains arise from extra data rather than the claimed guiding mechanism; this weakens attribution of the reported outperformance.
minor comments (1)
- [Abstract] The abstract and method sections use terms such as 'substantially improves' and 'powerful signals' without accompanying quantitative effect sizes or statistical significance tests in the main text; adding these would strengthen clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our distribution-reshaping mechanism. We address each major comment below and will incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Distribution Reshaping): The central claim that the dual reshaping process steers learning for unseen items without semantic loss or new biases is load-bearing, yet the manuscript provides no direct measurements (e.g., KL divergence between original and reshaped profile distributions or cosine similarity of embeddings before/after reshaping) to isolate this effect from implicit regularization or added signal volume.
Authors: We agree that explicit quantitative verification of semantic preservation would strengthen the load-bearing claim. In the revised manuscript we will add KL-divergence measurements between the original and reshaped profile distributions as well as mean cosine similarities of the embeddings before and after reshaping. These metrics will be reported for all three datasets and will be accompanied by a short discussion of any observed distributional shifts or potential biases introduced by the reshaping step. revision: yes
-
Referee: [§4.3, Table 2] §4.3 and Table 2 (Experimental Results): Performance improvements are reported across four base models and three datasets, but the absence of ablations that disable the reshaping component (while retaining profile signals) or compare against simple concatenation baselines leaves open the possibility that gains arise from extra data rather than the claimed guiding mechanism; this weakens attribution of the reported outperformance.
Authors: We acknowledge that the current experiments do not fully isolate the contribution of the dual reshaping process from the simple addition of profile signals. In the revision we will include two new ablation settings: (1) profile signals retained but reshaping disabled (via direct concatenation or feature addition), and (2) explicit comparison against a simple concatenation baseline that uses the same LLM-derived profiles. These results will be added to Table 2 and discussed in §4.3 to clarify that the reported gains are attributable to the guiding effect of distribution reshaping rather than extra data volume alone. revision: yes
Circularity Check
No circularity: empirical framework with independent experimental validation
full rationale
The paper introduces ProMax as a practical framework that uses dense retrieval on LLM-derived profiles followed by a dual distribution-reshaping process to augment base recommenders. No equations, derivations, or fitted parameters are defined in terms of the target performance metrics; improvements are measured directly on held-out data from three public datasets across four classic models. No self-citations serve as load-bearing premises, and the central mechanism is presented as an empirical intervention rather than a self-referential definition or renamed known result. The derivation chain is therefore self-contained and externally falsifiable via the reported experiments.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-derived profiles accurately capture user preferences from implicit feedback
- domain assumption Dense retrieval reliably uncovers collaborative relationships between user and item profiles
Reference graph
Works this paper leans on
-
[1]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. InProceedings of the 17th ACM Conference on Recommender Systems. 1007–1014
2023
-
[2]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al . 2024. A survey on evaluation of large language models.ACM Transactions on Intelligent Systems and Technology15, 3 (2024), 1–45
2024
-
[3]
Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2023. Bias and debias in recommender system: A survey and future directions. ACM Transactions on Information Systems41, 3 (2023), 1–39
2023
-
[4]
Jiawei Chen, Junkang Wu, Jiancan Wu, Xuezhi Cao, Sheng Zhou, and Xiangnan He. 2023. Adap-𝜏: Adaptively modulating embedding magnitude for recommen- dation. InProceedings of the ACM Web Conference 2023. 1085–1096
2023
-
[5]
Lei Chen, Le Wu, Richang Hong, Kun Zhang, and Meng Wang. 2020. Revisiting graph based collaborative filtering: A linear residual graph convolutional network approach. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 27–34
2020
-
[6]
Yan Fang, Jingtao Zhan, Qingyao Ai, Jiaxin Mao, Weihang Su, Jia Chen, and Yiqun Liu. 2024. Scaling laws for dense retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1339–1349
2024
-
[7]
Chongming Gao, Ruijun Chen, Shuai Yuan, Kexin Huang, Yuanqing Yu, and Xiangnan He. 2025. Sprec: Self-play to debias llm-based recommendation. In Proceedings of the ACM on Web Conference 2025. 5075–5084
2025
-
[8]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM Conference on Recommender Systems. 299–315
2022
-
[9]
Xavier Glorot and Yoshua Bengio. 2010. Understanding the Difficulty of Training Deep Feedforward Neural Networks. InProceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (ICAIS). 249–256
2010
-
[10]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 639–648
2020
-
[11]
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative filtering. InProceedings of the 26th International Conference on World Wide Web. 173–182
2017
-
[12]
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations
2022
-
[13]
Guoqing Hu, An Zhang, Shuo Liu, Zhibo Cai, Xun Yang, and Xiang Wang. 2025. Alphafuse: Learn id embeddings for sequential recommendation in null space of language embeddings. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1614–1623
2025
-
[14]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation.Comput. Surveys55, 12 (2023), 1–38
2023
-
[15]
Santosh Kabbur, Xia Ning, and George Karypis. 2013. Fism: factored item simi- larity models for top-n recommender systems. InProceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 659– 667
2013
-
[16]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[17]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A Method for Stochastic Opti- mization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review arXiv 2014
-
[18]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. 2024. Llara: Large language-recommendation assistant. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1785–1795
2024
-
[19]
Qidong Liu, Xian Wu, Yejing Wang, Zijian Zhang, Feng Tian, Yefeng Zheng, and Xiangyu Zhao. 2024. Llm-esr: Large language models enhancement for long- tailed sequential recommendation.Advances in Neural Information Processing Systems37 (2024), 26701–26727
2024
-
[20]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning. PMLR, 8748–8763
2021
-
[21]
Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. Representation learning with large language models for recommendation. InProceedings of the ACM on Web Conference 2024. 3464– 3475
2024
-
[22]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[23]
InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence (UAI)
BPR: Bayesian Personalized Ranking from Implicit Feedback. InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence (UAI). 452– 461
-
[24]
Steffen Rendle, Walid Krichene, Li Zhang, and John Anderson. 2020. Neural collaborative filtering vs. matrix factorization revisited. InProceedings of the 14th ACM Conference on Recommender Systems. 240–248
2020
-
[25]
Francesco Ricci, Lior Rokach, and Bracha Shapira. 2011. Introduction to Rec- ommender Systems Handbook. InRecommender Systems Handbook. Springer, 1–35
2011
-
[26]
Claude E Shannon. 2001. A mathematical theory of communication.ACM SIGMOBILE mobile computing and communications review5, 1 (2001), 3–55
2001
-
[27]
Leheng Sheng, An Zhang, Yi Zhang, Yuxin Chen, Xiang Wang, and Tat-Seng Chua. 2025. Language Representations Can be What Recommenders Need: Findings and Potentials. InThe Thirteenth International Conference on Learning Representations
2025
- [28]
-
[29]
Chen Wang, Liangwei Yang, Zhiwei Liu, Xiaolong Liu, Mingdai Yang, Yueqing Liang, and Philip S Yu. 2024. Collaborative alignment for recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2315–2325
2024
-
[30]
Lu Wang, Di Zhang, Fangkai Yang, Pu Zhao, Jianfeng Liu, Yuefeng Zhan, Hao Sun, Qingwei Lin, Weiwei Deng, Dongmei Zhang, et al. 2025. LettinGo: Explore User Profile Generation for Recommendation System. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 2985–2995
2025
-
[31]
Shuyao Wang, Zhi Zheng, Yongduo Sui, and Hui Xiong. 2025. Unleashing the Power of Large Language Model for Denoising Recommendation. InProceedings of the ACM on Web Conference 2025. 252–263
2025
-
[32]
Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural graph collaborative filtering. InProceedings of the 42nd international ACM SIGIR Conference on Research and development in Information Retrieval. 165–174
2019
-
[33]
Yu Wang, Lei Sang, Yi Zhang, and Yiwen Zhang. 2025. Intent representation learning with large language model for recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1870–1879
2025
- [34]
-
[35]
Yu Wang, Yonghui Yang, Le Wu, Yi Zhang, and Richang Hong. 2025. Multimodal Large Language Models with Adaptive Preference Optimization for Sequential Recommendation.arXiv preprint arXiv:2511.18740(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Jun- feng Wang, Dawei Yin, and Chao Huang. 2024. Llmrec: Large language models with graph augmentation for recommendation. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 806–815
2024
-
[37]
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al . 2024. A survey on large ProMax: Exploring the Potential of LLM-derived Profiles with Distribution Shaping for Recommender Systems SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia language models for recommendation.World Wide Web...
2024
-
[38]
Yunjia Xi, Weiwen Liu, Jianghao Lin, Xiaoling Cai, Hong Zhu, Jieming Zhu, Bo Chen, Ruiming Tang, Weinan Zhang, and Yong Yu. 2024. Towards open-world recommendation with knowledge augmentation from large language models. In Proceedings of the 18th ACM Conference on Recommender Systems. 12–22
2024
-
[39]
Hefei Xu, Le Wu, Chen Cheng, and Hao Liu. 2026. Multi-Value Alignment for LLMs via Value Decorrelation and Extrapolation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 34133–34141
2026
-
[40]
Hefei Xu, Le Wu, Yu Wang, Min Hou, Han Wu, Zhen Zhang, and Meng Wang
-
[41]
InProceedings of the ACM Web Conference 2026
VC-Soup: Value-Consistency Guided Multi-Value Alignment for Large Language Models. InProceedings of the ACM Web Conference 2026. 9699–9710
2026
-
[42]
Hongzhi Yin, Bin Cui, Zi Huang, Weiqing Wang, Xian Wu, and Xiaofang Zhou
-
[43]
InProceedings of the 23rd ACM international conference on Multimedia
Joint modeling of users’ interests and mobility patterns for point-of-interest recommendation. InProceedings of the 23rd ACM international conference on Multimedia. 819–822
-
[44]
Hongzhi Yin, Liang Qu, Tong Chen, Wei Yuan, Ruiqi Zheng, Jing Long, Xin Xia, Yuhui Shi, and Chengqi Zhang. 2025. On-device recommender systems: A comprehensive survey.Data Science and Engineering(2025), 1–30
2025
-
[45]
Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are graph augmentations necessary? simple graph contrastive learning for recommendation. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1294–1303
2022
-
[46]
Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Jundong Li, and Zi Huang. 2023. Self-supervised learning for recommender systems: A survey.IEEE Transactions on Knowledge and Data Engineering36, 1 (2023), 335–355
2023
-
[47]
Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to go next for recommender systems? id- vs. modality-based recommender models revisited. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2639–2649
2023
-
[48]
An Zhang, Yuxin Chen, Leheng Sheng, Xiang Wang, and Tat-Seng Chua. 2024. On generative agents in recommendation. InProceedings of the 47th international ACM SIGIR conference on research and development in Information Retrieval. 1807– 1817
2024
-
[49]
Jiaqi Zhang, Chen Gao, Liyuan Zhang, Quoc Viet Hung Nguyen, and Hongzhi Yin. 2026. Smartagent: Chain-of-user-thought for embodied personalized agent in cyber world. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 17993–18001
2026
-
[50]
Junjie Zhang, Yupeng Hou, Ruobing Xie, Wenqi Sun, Julian McAuley, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. 2024. Agentcf: Collaborative learning with autonomous language agents for recommender systems. InProceedings of the ACM Web Conference 2024. 3679–3689
2024
-
[51]
Lan Zhang, Wray Buntine, and Ehsan Shareghi. 2022. On the effect of isotropy on VAE representations of text. InAnnual Meeting of the Association of Computational Linguistics 2022. Association for Computational Linguistics (ACL), 694–701
2022
-
[52]
Lingzi Zhang, Xin Zhou, Zhiwei Zeng, and Zhiqi Shen. 2024. Are id embeddings necessary? whitening pre-trained text embeddings for effective sequential rec- ommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 530–543
2024
-
[53]
Yi Zhang, Yiwen Zhang, Yu Wang, Tong Chen, and Hongzhi Yin. 2025. Towards distribution matching between collaborative and language spaces for generative recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2006–2016
2025
-
[54]
Yi Zhang, Yiwen Zhang, Yu Wang, Tong Chen, and Hongzhi Yin. 2026. ProEx: A Unified Framework Leveraging Large Language Model with Profile Extrapolation for Recommendation. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1
2026
-
[55]
Yi Zhang, Yiwen Zhang, Dengcheng Yan, Shuiguang Deng, and Yun Yang. 2023. Revisiting graph-based recommender systems from the perspective of variational auto-encoder.ACM Transactions on Information Systems41, 3 (2023), 1–28
2023
-
[56]
Yu Zhang, Yiwen Zhang, Yi Zhang, Lei Sang, and Yun Yang. 2025. Unveiling Contrastive Learning‘ Capability of Neighborhood Aggregation for Collabora- tive Filtering. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1985–1994
2025
-
[57]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.18223(2023)
work page internal anchor Pith review arXiv 2023
-
[58]
Yuchuan Zhao, Tong Chen, Junliang Yu, Kai Zheng, Lizhen Cui, and Hongzhi Yin. 2025. Diversity-aware Dual-promotion Poisoning Attack on Sequential Recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1634–1644
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.