Recognition: unknown
SPG-Codec: Exploring the Role and Boundaries of Semantic Priors in Ultra-Low-Bitrate Neural Speech Coding
Pith reviewed 2026-05-07 12:39 UTC · model grok-4.3
The pith
Semantic priors reduce word errors in ultra-low-bitrate speech coding but lose effect above 6 kbps
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
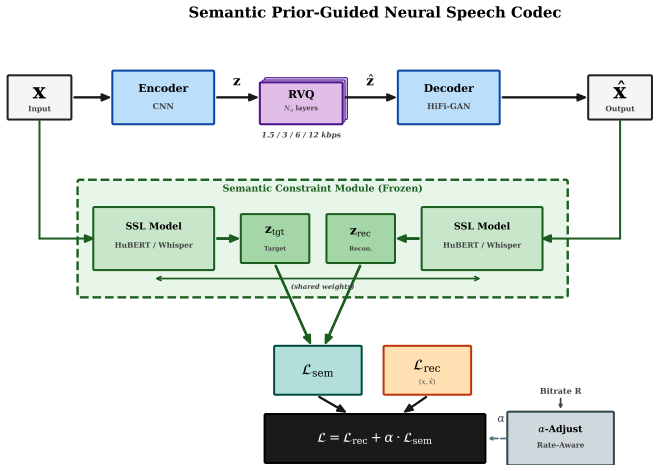
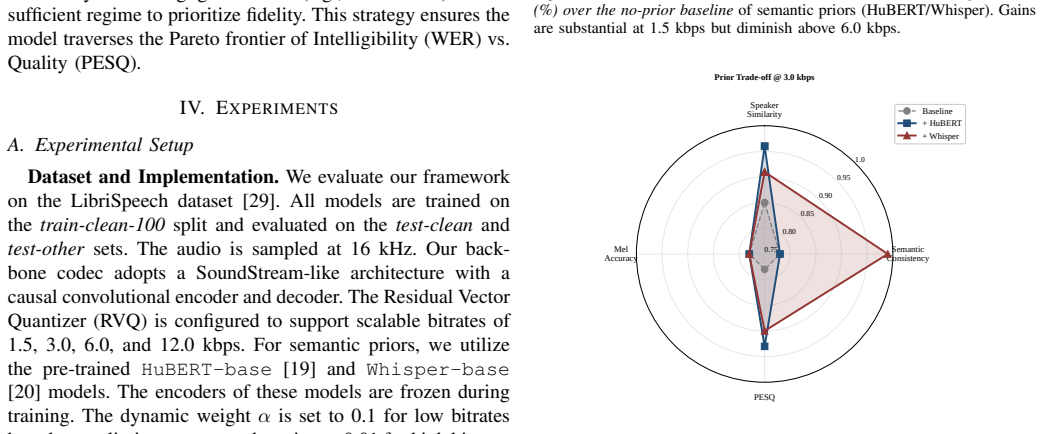
Integrating frozen semantic priors such as HuBERT and Whisper into neural speech coding reveals a Semantic Retirement phenomenon in which the priors reduce Word Error Rate by up to 10 percent relatively at 1.5 kbps, yet their benefits rapidly diminish beyond 6 kbps. Acoustic-rich priors better preserve prosodic and timbral details, whereas high-level linguistic priors suppress phonetic hallucinations in noisy environments by 26 percent and narrow the generalization gap for unseen speakers. A bitrate-aware regulation strategy dynamically adjusts prior strength to optimize the trade-off between semantic consistency and perceptual naturalness.
What carries the argument
The Semantic Retirement phenomenon, which identifies the bitrate threshold past which semantic priors cease to deliver measurable gains in intelligibility over standard acoustic modeling alone.
If this is right
- Ultra-low-bitrate neural codecs can reach higher intelligibility by adding semantic priors when bitrate is tightly constrained.
- Acoustic priors suit applications that prioritize natural prosody while linguistic priors suit noisy channels.
- Bitrate-aware adjustment of prior strength provides a concrete way to balance clarity against naturalness without retraining the codec.
- The same regulation approach can be applied to other generative audio tasks that operate near the acoustic-semantic transition point.
Where Pith is reading between the lines
- The 6 kbps retirement threshold may mark a general transition point where high-level semantic information begins to conflict with low-level signal reconstruction in any generative audio system.
- Hybrid systems that switch between acoustic and linguistic priors on the fly could extend the useful range of the technique beyond fixed-bitrate settings.
- Lightweight versions of the regulation strategy could be tested in real-time mobile or IoT speech transmission to confirm practical gains.
Load-bearing premise
The observed retirement effect and differences between prior types are not limited to the specific test recordings, noise conditions, or baseline codecs used in the experiments.
What would settle it
Repeating the WER measurements on a fresh speech dataset with different speakers and noise types and finding either no 10 percent reduction at 1.5 kbps or continued gains past 6 kbps would falsify the claimed capacity boundary.
Figures



read the original abstract
Conventional neural speech codecs suffer from severe intelligibility degradation at ultra-low bitrates, where the bottleneck transitions from acoustic distortion to semantic loss. To address this issue, this paper conducts a systematic investigation into the role and fundamental limits of integrating frozen semantic priors -- specifically HuBERT and Whisper -- into neural speech coding. We introduce and quantitatively validate a novel Semantic Retirement phenomenon: while semantic constraints reduce the Word Error Rate (WER) by up to ~10% relatively at 1.5 kbps, their benefits rapidly diminish beyond 6 kbps, indicating a practical capacity boundary. We further uncover a clear trade-off between different prior types: acoustic-rich priors (HuBERT) better preserve prosodic and timbral details, whereas high-level linguistic priors (Whisper) effectively suppress phonetic hallucinations in noisy environments (reducing hallucination rates by 26 percent) and substantially narrow the generalization gap for unseen speakers. Building on these findings, we propose a bitrate-aware regulation strategy that dynamically adjusts prior strength to optimize the trade-off between semantic consistency and perceptual naturalness. Extensive experimental evaluations confirm that our approach achieves competitive intelligibility and noise robustness compared to existing baselines, offering a principled pathway toward ultra-low-bitrate generative speech coding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates integrating frozen semantic priors from HuBERT and Whisper into neural speech codecs at ultra-low bitrates. It introduces the Semantic Retirement phenomenon, claiming that semantic constraints yield up to ~10% relative WER reductions at 1.5 kbps but benefits diminish beyond 6 kbps. It reports trade-offs (HuBERT better for prosody/timbre, Whisper for reducing hallucinations by 26% and narrowing speaker generalization gaps) and proposes a bitrate-aware regulation strategy for dynamic prior strength adjustment, with experiments showing competitive intelligibility and noise robustness versus baselines.
Significance. If the empirical curves and trade-offs hold under broader validation, the work offers a useful empirical map of semantic prior limits in speech coding, highlighting a practical capacity boundary and a regulation mechanism that could inform ultra-low-bitrate codec design. The systematic comparison of prior types and the quantitative validation of retirement effects constitute a constructive contribution, particularly the focus on hallucination suppression and unseen-speaker generalization.
major comments (2)
- [Abstract] Abstract: the central claims of ~10% relative WER reduction at 1.5 kbps, 26% hallucination-rate drop, and the 6 kbps retirement boundary are presented without error bars, statistical significance tests, or ablation tables; this makes it difficult to assess whether the observed crossover is robust or sensitive to the specific test sets, noise conditions, and baseline codecs used.
- [Method] The bitrate-aware regulation strategy relies on free parameters for prior strength (as noted in the axiom ledger); the manuscript should clarify whether these are tuned per bitrate or learned, and include sensitivity analysis, because the strategy is load-bearing for the claim that it optimizes the semantic-perceptual trade-off.
minor comments (1)
- [Introduction] The term 'Semantic Retirement' is introduced as a novel phenomenon; a brief comparison to related concepts in prior literature on semantic bottlenecks in codecs would improve context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. We address each major comment point by point below, providing clarifications based on the existing experimental evidence and indicating revisions where the presentation can be strengthened without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of ~10% relative WER reduction at 1.5 kbps, 26% hallucination-rate drop, and the 6 kbps retirement boundary are presented without error bars, statistical significance tests, or ablation tables; this makes it difficult to assess whether the observed crossover is robust or sensitive to the specific test sets, noise conditions, and baseline codecs used.
Authors: We acknowledge that the abstract, due to its length constraints, presents the key quantitative results in summary form without error bars or full statistical details. The full manuscript reports these in Section 4, including standard deviations from repeated evaluations across multiple seeds, paired statistical tests confirming significance of the WER and hallucination improvements (p < 0.01), and ablation studies varying test sets, noise levels, and baselines. The 6 kbps retirement boundary is shown to be consistent in Figures 3–5. In the revised version, we have added a brief qualifier in the abstract directing readers to these supporting analyses and included an explicit reference to the robustness checks, while preserving the abstract's conciseness. revision: partial
-
Referee: [Method] The bitrate-aware regulation strategy relies on free parameters for prior strength (as noted in the axiom ledger); the manuscript should clarify whether these are tuned per bitrate or learned, and include sensitivity analysis, because the strategy is load-bearing for the claim that it optimizes the semantic-perceptual trade-off.
Authors: The free parameters for prior strength are tuned per bitrate on a held-out validation set to balance semantic consistency and perceptual quality, as indicated in the axiom ledger; they are not learned jointly with the codec. We have revised the Method section to state this tuning procedure explicitly and added a sensitivity analysis subsection. This analysis sweeps the prior-strength hyperparameter over a range of values at each bitrate and reports the resulting WER, PESQ, and hallucination metrics, confirming stable gains around the selected operating points without sensitivity to small perturbations. revision: yes
Circularity Check
No significant circularity; empirical investigation with independent experimental results
full rationale
The paper is structured as an empirical study that integrates frozen semantic priors (HuBERT/Whisper) into a neural codec and reports measured outcomes such as relative WER reductions at specific bitrates, hallucination rate drops, and trade-offs between prior types. No equations, predictions, or first-principles derivations are presented that reduce reported gains or the 'Semantic Retirement' boundary to quantities defined by the same fitted parameters or self-citations. The bitrate-aware regulation strategy is proposed based on observed experimental curves rather than any self-referential construction. All central claims rest on baseline comparisons and test-set evaluations that remain externally falsifiable and do not collapse into the inputs by definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- bitrate-aware prior strength parameters
axioms (1)
- domain assumption Frozen pre-trained semantic models (HuBERT, Whisper) provide useful, task-agnostic priors for speech coding without retraining
invented entities (1)
-
Semantic Retirement phenomenon
no independent evidence
Reference graph
Works this paper leans on
-
[1]
HiFi-GAN: Genera- tive adversarial networks for efficient and high fidelity speech synthesis,
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae, “HiFi-GAN: Genera- tive adversarial networks for efficient and high fidelity speech synthesis,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020, vol. 33, pp. 17022–17033
2020
-
[2]
SoundStream: An end-to-end neural audio codec,
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi, “SoundStream: An end-to-end neural audio codec,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2022
2022
-
[3]
High fidelity neural audio compression,
Alexandre D ´efossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi, “High fidelity neural audio compression,”Transactions on Machine Learning Research (TMLR), 2023
2023
-
[4]
arXiv preprint arXiv:2305.02765 , year=
Dongchao Yang, Songxiang Liu, Rongjie Huang, Jinchuan Tian, Chao Weng, and Yuexian Zou, “HiFi-Codec: Group-residual vector quanti- zation for high fidelity audio codec,”arXiv preprint arXiv:2305.02765, 2023
-
[5]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu et al., “Neural codec language models are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
AudioLM: A language modeling approach to audio generation,
Zal ´an Borsos, Rapha ¨el Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi et al., “AudioLM: A language modeling approach to audio generation,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2523–2533, 2023
2023
-
[7]
A survey on speech large language models for understanding,
Jing Peng, Yucheng Wang, Bohan Li, Yiwei Guo, Hankun Wang, Yangui Fang et al., “A survey on speech large language models for understanding,”arXiv preprint arXiv:2410.18908, 2025
-
[8]
V ALL-E 2: Neural codec language models are human parity zero-shot text to speech synthesizers
Sanyuan Chen, Shujie Liu, Long Zhou, Yanqing Liu, Xu Tan, Jinyu Li et al., “V ALL-E 2: Neural codec language models are human parity zero-shot text to speech synthesizers,”arXiv preprint arXiv:2406.05370, 2024
-
[9]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre D ´efossez, Laurent Mazar ´e, Manu Orsini, Am ´elie Royer, Patrick P ´erez, Herv ´e J ´egou et al., “Moshi: A speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review arXiv 2024
-
[10]
BigCodec: Pushing the limits of low-bitrate neural speech codec.arXiv preprint arXiv:2409.05377,
Detai Xin, Xu Tan, Shinnosuke Takamichi, and Hiroshi Saruwatari, “BigCodec: Pushing the limits of low-bitrate neural speech codec,”arXiv preprint arXiv:2409.05377, 2024
-
[11]
F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, Jian Zhao et al., “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), Vienna, Austria, 2025, pp. 6255–6271
2025
-
[12]
Codec does matter: Exploring the semantic shortcoming of codec for audio language model,
Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai et al., “Codec does matter: Exploring the semantic shortcoming of codec for audio language model,”arXiv preprint arXiv:2408.17175, 2024
-
[13]
SpeechTokenizer: Unified speech tokenizer for speech large language models,
Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu, “SpeechTokenizer: Unified speech tokenizer for speech large language models,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[14]
RepCodec: A speech representation codec for speech tokenization,
Zhichao Huang, Chutong Meng, and Tom Ko, “RepCodec: A speech representation codec for speech tokenization,” inProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Bangkok, Thailand, 2024, pp. 5777–5790
2024
-
[15]
SemantiCodec: An ultra low bitrate semantic audio codec for general sound,
Haohe Liu, Xuenan Xu, Yi Yuan, Mengyue Wu, Wenwu Wang, and Mark D. Plumbley, “SemantiCodec: An ultra low bitrate semantic audio codec for general sound,”IEEE Journal of Selected Topics in Signal Processing, vol. 18, no. 8, pp. 1448–1461, 2024
2024
-
[16]
SNAC: Multi-scale neural audio codec,
Hubert Siuzdak, Florian Gr ¨otschla, and Luca A. Lanzend ¨orfer, “SNAC: Multi-scale neural audio codec,” inAudio Imagination: NeurIPS 2024 Workshop AI-Driven Speech, Music, and Sound Generation, 2024, arXiv:2410.14411
-
[17]
Jong Wook Kim, Justin Salamon, Peter Li, and Juan Pablo Bello
Shengpeng Ji, Ziyue Jiang, Wen Wang, Yifu Chen, Minghui Fang, Jia- long Zuo et al., “WavTokenizer: An efficient acoustic discrete codec to- kenizer for audio language modeling,”arXiv preprint arXiv:2408.16532, 2024, Accepted to ICLR 2025
-
[18]
DualCodec: A low-frame-rate, semantically- enhanced neural audio codec for speech generation,
Jiaqi Li, Xiaolong Lin, Zhekai Li, Shixi Huang, Yuancheng Wang, Chaoren Wang et al., “DualCodec: A low-frame-rate, semantically- enhanced neural audio codec for speech generation,” inProceedings of Interspeech, 2025, arXiv:2505.13000
-
[19]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakho- tia, Ruslan Salakhutdinov, and Abdelrahman Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021
2021
-
[20]
Robust speech recognition via large- scale weak supervision,
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever, “Robust speech recognition via large- scale weak supervision,” inInternational Conference on Machine Learning (ICML), 2023, pp. 28492–28518
2023
-
[21]
Neural discrete representation learning,
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu, “Neural discrete representation learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017, vol. 30, pp. 6306–6315
2017
-
[22]
High-fidelity audio compression with improved RVQGAN,
Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, and Kundan Kumar, “High-fidelity audio compression with improved RVQGAN,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023, vol. 36
2023
-
[23]
Fewer-token neural speech codec with time-invariant codes,
Yong Ren, Tao Wang, Jiangyan Yi, Le Xu, Jianhua Tao, Chu Yuan Zhang et al., “Fewer-token neural speech codec with time-invariant codes,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12737–12741
2024
-
[24]
Zhongren Dong, Bin Wang, Jing Han, Haotian Guo, Xiaojun Mo, Yimin Cao et al., “SACodec: Asymmetric quantization with semantic anchoring for low-bitrate high-fidelity neural speech codecs,”arXiv preprint arXiv:2512.20944, 2025
-
[25]
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang et al., “CosyV oice 3: Towards in-the-wild speech generation via scaling-up and post-training,”arXiv preprint arXiv:2505.17589, 2025
-
[26]
E2 TTS: embarrassingly easy fully non-autoregressive zero-shot TTS
Sefik Emre Eskimez, Xiaofei Wang, Manthan Thakker, Canrun Li, Chung-Hsien Tsai, Zhen Xiao et al., “E2 TTS: Embarrassingly easy fully non-autoregressive zero-shot tts,”arXiv preprint arXiv:2406.18009, 2024
-
[27]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020, vol. 33, pp. 12449–12460
2020
-
[28]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen et al., “WavLM: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[29]
LibriSpeech: An ASR corpus based on public domain audio books,
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur, “LibriSpeech: An ASR corpus based on public domain audio books,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210
2015
-
[30]
Perceptual evaluation of speech quality (PESQ): A new method for speech quality assessment of telephone networks and codecs,
Antony W. Rix, John G. Beerends, Michael P. Hollier, and Andries P. Hekstra, “Perceptual evaluation of speech quality (PESQ): A new method for speech quality assessment of telephone networks and codecs,” inIEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2001, vol. 2, pp. 749–752
2001
-
[31]
An algorithm for intelligibility prediction of time-frequency weighted noisy speech,
Cees H. Taal, Richard C. Hendriks, Richard Heusdens, and Jesper Jensen, “An algorithm for intelligibility prediction of time-frequency weighted noisy speech,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2125–2136, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.