Recognition: unknown
VulStyle: A Multi-Modal Pre-Training for Code Stylometry-Augmented Vulnerability Detection
Pith reviewed 2026-05-07 13:24 UTC · model grok-4.3
The pith
VulStyle detects more software vulnerabilities by pre-training on code text, non-terminal AST nodes, and stylometry features together.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
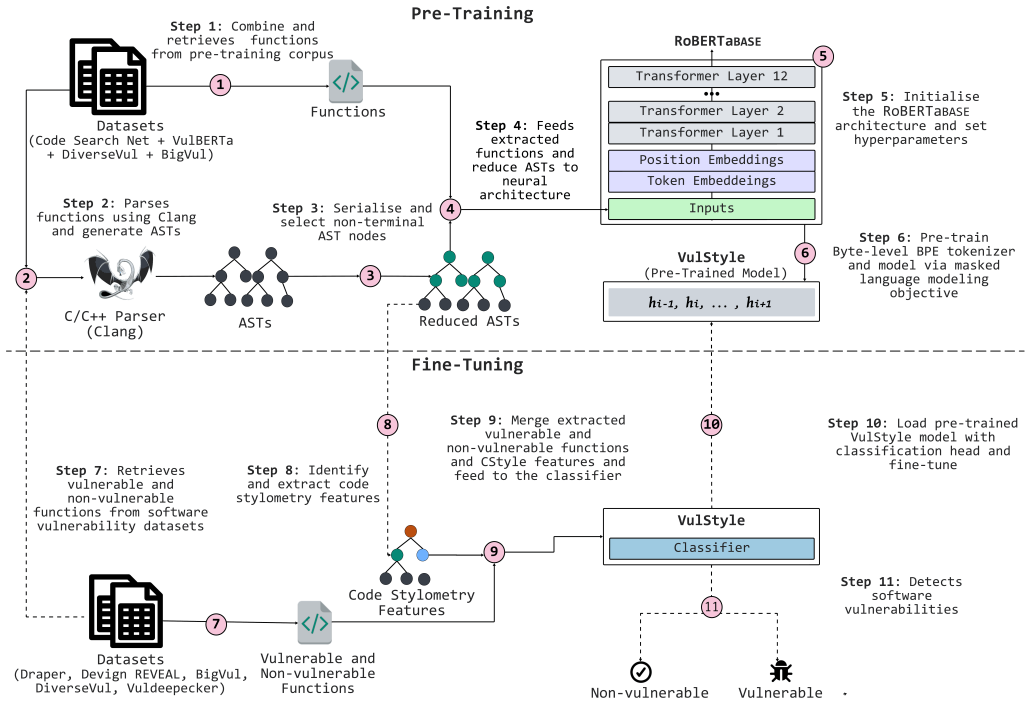
VulStyle jointly encodes function-level source code, non-terminal Abstract Syntax Tree structure, and code stylometry features. Prior work either stays at token level or uses full AST trees, which can overlook stylistic markers of risky code or add unnecessary structural cost. The model pre-trains with masked language modeling on 4.9 million functions in seven languages and then fine-tunes on Devign, BigVul, DiverseVul, REVEAL, and VulDeePecker. It reaches state-of-the-art F1 on BigVul and VulDeePecker with gains of 4-48 percent over strong baselines and remains competitive on the remaining sets.
What carries the argument
A transformer encoder that receives three aligned input streams: raw code tokens, only the non-terminal nodes of the AST, and extracted syntactic plus lexical stylometry features.
If this is right
- The ablation isolates how much the stylometry and AST streams each add to final accuracy.
- Error analysis on misclassified cases shows remaining failure modes after the new signals are included.
- The threat model situates evaluation in attacker-realistic rather than purely synthetic settings.
- Pre-training across seven languages indicates the learned representations can transfer to mixed-language codebases.
Where Pith is reading between the lines
- If style measurements correlate with vulnerability risk, the same features could be tested in related tasks such as defect prediction or code smell detection.
- Limiting the AST input to non-terminals may allow the method to scale to larger repositories while keeping structural signal.
- Evaluating the model on code written after the pre-training cutoff would test whether the gains persist on newer programming practices.
Load-bearing premise
Code stylometry measurements and the choice of only non-terminal AST nodes supply reliable extra signals about the presence of vulnerabilities.
What would settle it
Retraining the identical architecture on BigVul without the stylometry stream or the non-terminal AST nodes and checking whether the F1 score still exceeds the strongest prior transformer result.
Figures

read the original abstract
We present VulStyle, a multi-modal software vulnerability detection model that jointly encodes function-level source code, non-terminal Abstract Syntax Tree (AST) structure, and code stylometry (CStyle) features. Prior work in code representation primarily leverages token-level models or full AST trees, often missing stylistic cues indicative of risky programming practices, or incurring high structural overhead. Our approach selects only non-terminal AST nodes, reducing input complexity while preserving semantic hierarchy, and integrates syntactic and lexical CStyle features as auxiliary vulnerability signals. VulStyle is pre-trained using masked language modeling on 4.9M functions across seven programming languages, and fine-tuned across five benchmark datasets: Devign, BigVul, DiverseVul, REVEAL, and VulDeePecker. VulStyle achieves state-of-the-art performance on BigVul and VulDeePecker, improving F1 by 4-48% over strong transformer baselines, and attains competitive or best-average performance across all benchmarks. We contribute an ablation study isolating the effect of CStyle and AST structure, error case analysis, and a threat model situating the detection task in attacker-realistic scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents VulStyle, a multi-modal pre-training model for code vulnerability detection that jointly encodes function-level source code, non-terminal AST nodes, and code stylometry (CStyle) features. It is pre-trained via masked language modeling on 4.9M functions across seven languages and fine-tuned on five benchmarks (Devign, BigVul, DiverseVul, REVEAL, VulDeePecker). The central claims are state-of-the-art F1 performance on BigVul and VulDeePecker (4-48% gains over transformer baselines) with competitive or best-average results elsewhere, supported by ablations isolating CStyle and AST effects, error analysis, and a threat model for realistic attacker scenarios.
Significance. If the empirical results hold under rigorous controls, the work usefully demonstrates that stylistic cues and simplified syntactic hierarchy can serve as effective auxiliary signals for vulnerability detection, extending beyond token-only or full-AST transformers. Explicit credit is due for the ablation study isolating CStyle and non-terminal AST, the error case analysis, and the threat model that situates detection in attacker-realistic conditions; these elements make the contribution more falsifiable and reproducible than many prior code-representation papers.
major comments (2)
- [Ablation study] Ablation study section: The reported F1 gains from adding CStyle features (and from non-terminal AST) are presented as consistent improvements, but the manuscript does not report standard deviations across multiple random seeds, confidence intervals, or statistical significance tests (e.g., paired t-tests or McNemar tests) on the metric differences. This omission is load-bearing for the SOTA claims on BigVul and VulDeePecker, as fine-tuning variance in transformer models can easily produce 4-10% swings.
- [Experimental setup] Experimental setup and results sections: The pre-training corpus of 4.9M functions is large, yet the paper does not explicitly describe overlap checks or deduplication procedures between the pre-training data and the five fine-tuning benchmarks. Without this, the claimed improvements risk being inflated by data leakage, directly undermining the cross-benchmark performance assertions.
minor comments (2)
- [Abstract] Abstract: The broad range '4-48%' would be more informative if broken down by individual benchmark (e.g., exact deltas on BigVul vs. VulDeePecker).
- [Method] Notation and figures: The precise lexical and syntactic features comprising CStyle are described in text but would benefit from an explicit table or appendix listing; similarly, an illustrative example of non-terminal AST node selection would clarify the complexity reduction claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects for strengthening the empirical claims. We address each major comment below and will revise the manuscript accordingly to improve reproducibility and rigor.
read point-by-point responses
-
Referee: [Ablation study] Ablation study section: The reported F1 gains from adding CStyle features (and from non-terminal AST) are presented as consistent improvements, but the manuscript does not report standard deviations across multiple random seeds, confidence intervals, or statistical significance tests (e.g., paired t-tests or McNemar tests) on the metric differences. This omission is load-bearing for the SOTA claims on BigVul and VulDeePecker, as fine-tuning variance in transformer models can easily produce 4-10% swings.
Authors: We agree that variance estimates and statistical tests are necessary to substantiate the reported gains, particularly for the SOTA claims. In the revised manuscript, we will rerun the fine-tuning experiments across at least five random seeds, report mean F1 scores with standard deviations and confidence intervals, and include paired t-tests (or McNemar tests where appropriate) to assess the statistical significance of improvements from adding CStyle and non-terminal AST features. revision: yes
-
Referee: [Experimental setup] Experimental setup and results sections: The pre-training corpus of 4.9M functions is large, yet the paper does not explicitly describe overlap checks or deduplication procedures between the pre-training data and the five fine-tuning benchmarks. Without this, the claimed improvements risk being inflated by data leakage, directly undermining the cross-benchmark performance assertions.
Authors: We acknowledge that explicit documentation of deduplication and overlap checks is essential to rule out leakage. We will revise the experimental setup section to describe the procedures used: function-level content hashing and similarity-based filtering applied during corpus construction to remove duplicates internally and to verify no overlap with the Devign, BigVul, DiverseVul, REVEAL, and VulDeePecker benchmarks. Any remaining edge cases or limitations will also be noted. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical ML contribution: multi-modal pre-training via standard masked language modeling on 4.9M functions, followed by fine-tuning and ablation studies on public vulnerability benchmarks. No derivation chain, equations, or first-principles results are claimed. Performance numbers are experimental outcomes, not reductions of fitted parameters or self-referential definitions. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify core claims. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Masked language modeling on large code corpora produces useful representations for downstream vulnerability detection
- domain assumption Non-terminal AST nodes preserve sufficient semantic hierarchy while reducing complexity
Reference graph
Works this paper leans on
-
[1]
Browse vulnerabilities by date
M. Corporation, “Browse vulnerabilities by date.” https://www. cvedetails.com/browse-by-date.php, Accessed May 2024
2024
-
[2]
Ques- tions developers ask while diagnosing potential security vulnerabilities with static analysis,
J. Smith, B. Johnson, E. Murphy-Hill, B. Chu, and H. R. Lipford, “Ques- tions developers ask while diagnosing potential security vulnerabilities with static analysis,” inProceedings of the 2015 10th Joint Meeting on F oundations of Software Engineering, pp. 248–259, 2015
2015
-
[3]
Dynamic taint analysis for automatic detection, analysis, and signature generation of exploits on commodity software,
N. James, “Dynamic taint analysis for automatic detection, analysis, and signature generation of exploits on commodity software,” inNetwork and Distributed System Security Symposium Conference Proceedings, 2005, 2005
2005
-
[4]
Git blame who? stylistic authorship attribution of small, incomplete source code fragments,
E. Dauber, A. Caliskan, R. Harang, and R. Greenstadt, “Git blame who? stylistic authorship attribution of small, incomplete source code fragments,” inProceedings of the 40th International Conference on Software Engineering: Companion Proceeedings, pp. 356–357, 2018
2018
-
[5]
Bgnn4vd: Constructing bidi- rectional graph neural-network for vulnerability detection,
S. Cao, X. Sun, L. Bo, Y . Wei, and B. Li, “Bgnn4vd: Constructing bidi- rectional graph neural-network for vulnerability detection,”Information and Software Technology, vol. 136, p. 106576, 2021
2021
-
[6]
S. Lu, D. Guo, S. Ren, J. Huang, A. Svyatkovskiy, A. Blanco, C. Clement, D. Drain, D. Jiang, D. Tang,et al., “Codexglue: A machine learning benchmark dataset for code understanding and generation,” arXiv preprint arXiv:2102.04664, 2021
-
[7]
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang,et al., “Codebert: A pre-trained model for programming and natural languages,”arXiv preprint arXiv:2002.08155, 2020
work page internal anchor Pith review arXiv 2002
-
[8]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[9]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,”arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review arXiv 2018
-
[10]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever,et al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[11]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,”arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review arXiv 1907
-
[12]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
H. Husain, H.-H. Wu, T. Gazit, M. Allamanis, and M. Brockschmidt, “Codesearchnet challenge: Evaluating the state of semantic code search,” arXiv preprint arXiv:1909.09436, 2019
work page internal anchor Pith review arXiv 1909
-
[13]
Vulberta: Simplified source code pre-training for vulnerability detection,
H. Hanif and S. Maffeis, “Vulberta: Simplified source code pre-training for vulnerability detection,” in2022 International joint conference on neural networks (IJCNN), pp. 1–8, IEEE, 2022
2022
-
[14]
Diversevul: A new vulnerable source code dataset for deep learning based vulnerability detection,
Y . Chen, Z. Ding, L. Alowain, X. Chen, and D. Wagner, “Diversevul: A new vulnerable source code dataset for deep learning based vulnerability detection,” inProceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses, pp. 654–668, 2023
2023
-
[15]
Ac/c++ code vulnerability dataset with code changes and cve summaries,
J. Fan, Y . Li, S. Wang, and T. N. Nguyen, “Ac/c++ code vulnerability dataset with code changes and cve summaries,” inProceedings of the 17th International Conference on Mining Software Repositories, pp. 508–512, 2020
2020
-
[16]
D. Guo, S. Lu, N. Duan, Y . Wang, M. Zhou, and J. Yin, “Unixcoder: Unified cross-modal pre-training for code representation,”arXiv preprint arXiv:2203.03850, 2022
-
[17]
De-anonymizing programmers via code stylometry,
A. Caliskan-Islam, R. Harang, A. Liu, A. Narayanan, C. V oss, F. Ya- maguchi, and R. Greenstadt, “De-anonymizing programmers via code stylometry,” in24th USENIX security symposium (USENIX Security 15), pp. 255–270, 2015
2015
-
[18]
Pace: A program analysis framework for continuous performance prediction,
C. Biringa and G. Kul, “Pace: A program analysis framework for continuous performance prediction,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 4, pp. 1–23, 2024
2024
-
[19]
Intellicode compose: Code generation using transformer,
A. Svyatkovskiy, S. K. Deng, S. Fu, and N. Sundaresan, “Intellicode compose: Code generation using transformer,” inProceedings of the 28th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering, pp. 1433– 1443, 2020
2020
-
[20]
Contrabert: En- hancing code pre-trained models via contrastive learning,
S. Liu, B. Wu, X. Xie, G. Meng, and Y . Liu, “Contrabert: En- hancing code pre-trained models via contrastive learning,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pp. 2476–2487, IEEE, 2023
2023
-
[21]
arXiv preprint arXiv:2009.08366 , year=
D. Guo, S. Ren, S. Lu, Z. Feng, D. Tang, S. Liu, L. Zhou, N. Duan, A. Svyatkovskiy, S. Fu,et al., “Graphcodebert: Pre-training code repre- sentations with data flow,”arXiv preprint arXiv:2009.08366, 2020
-
[22]
Exploring soft- ware naturalness through neural language models,
L. Buratti, S. Pujar, M. Bornea, S. McCarley, Y . Zheng, G. Rossiello, A. Morari, J. Laredo, V . Thost, Y . Zhuang,et al., “Exploring soft- ware naturalness through neural language models,”arXiv preprint arXiv:2006.12641, 2020
-
[23]
Linevd: Statement-level vulnerability detection using graph neural networks,
D. Hin, A. Kan, H. Chen, and M. A. Babar, “Linevd: Statement-level vulnerability detection using graph neural networks,” inProceedings of the 19th international conference on mining software repositories, pp. 596–607, 2022
2022
-
[24]
Devign: Effective vul- nerability identification by learning comprehensive program semantics via graph neural networks,
Y . Zhou, S. Liu, J. Siow, X. Du, and Y . Liu, “Devign: Effective vul- nerability identification by learning comprehensive program semantics via graph neural networks,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[25]
Vuldeepecker: A deep learning-based system for vulnerability detection,
Z. Li, D. Zou, S. Xu, X. Ou, H. Jin, S. Wang, Z. Deng, and Y . Zhong, “Vuldeepecker: A deep learning-based system for vulnerability detec- tion,”arXiv preprint arXiv:1801.01681, 2018
-
[26]
Sysevr: A framework for using deep learning to detect software vulnerabilities,
Z. Li, D. Zou, S. Xu, H. Jin, Y . Zhu, and Z. Chen, “Sysevr: A framework for using deep learning to detect software vulnerabilities,” IEEE Transactions on Dependable and Secure Computing, vol. 19, no. 4, pp. 2244–2258, 2021
2021
-
[27]
µvuldeepecker: A deep learning-based system for multiclass vulnerability detection,
D. Zou, S. Wang, S. Xu, Z. Li, and H. Jin, “µvuldeepecker: A deep learning-based system for multiclass vulnerability detection,”IEEE Transactions on Dependable and Secure Computing, vol. 18, no. 5, pp. 2224–2236, 2019
2019
-
[28]
Llvm and clang: Next generation compiler technology,
C. Lattner, “Llvm and clang: Next generation compiler technology,” in The BSD conference, vol. 5, pp. 1–20, 2008
2008
-
[29]
Automated vulnerability detection in source code using deep representation learning,
R. Russell, L. Kim, L. Hamilton, T. Lazovich, J. Harer, O. Ozdemir, P. Ellingwood, and M. McConley, “Automated vulnerability detection in source code using deep representation learning,” in2018 17th IEEE international conference on machine learning and applications (ICMLA), pp. 757–762, IEEE, 2018
2018
-
[30]
Deep learning based vulnerability detection: Are we there yet?,
S. Chakraborty, R. Krishna, Y . Ding, and B. Ray, “Deep learning based vulnerability detection: Are we there yet?,”IEEE Transactions on Software Engineering, vol. 48, no. 9, pp. 3280–3296, 2021
2021
-
[31]
National vulnerability database
N. I. of Standards and Technology, “National vulnerability database.” https://nvd.nist.gov/, Accessed May 2024
2024
-
[32]
Software assurance reference dataset
N. I. of Standards and Technology, “Software assurance reference dataset.” https://samate.nist.gov/SARD, Accessed May 2024
2024
-
[33]
Neural Machine Translation of Rare Words with Subword Units
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,”arXiv preprint arXiv:1508.07909, 2015
work page internal anchor Pith review arXiv 2015
-
[34]
Linevul: A transformer-based line- level vulnerability prediction,
M. Fu and C. Tantithamthavorn, “Linevul: A transformer-based line- level vulnerability prediction,” inProceedings of the 19th International Conference on Mining Software Repositories, pp. 608–620, 2022
2022
-
[35]
Top score on the wrong exam: On benchmarking in machine learning for vulnerability detection,
N. Risse, J. Liu, and M. B ¨ohme, “Top score on the wrong exam: On benchmarking in machine learning for vulnerability detection,” Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 388–410, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.