Recognition: unknown
Which Face and Whose Identity? Solving the Dual Challenge of Deepfake Proactive Forensics in Multi-Face Scenarios
Pith reviewed 2026-05-07 13:36 UTC · model grok-4.3
The pith
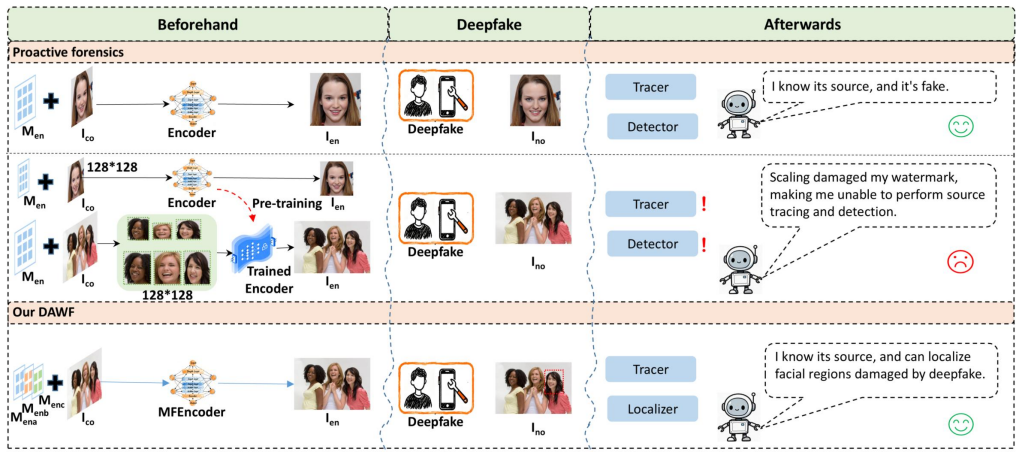
A watermarking framework locates tampered faces and traces their original identities in multi-person images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
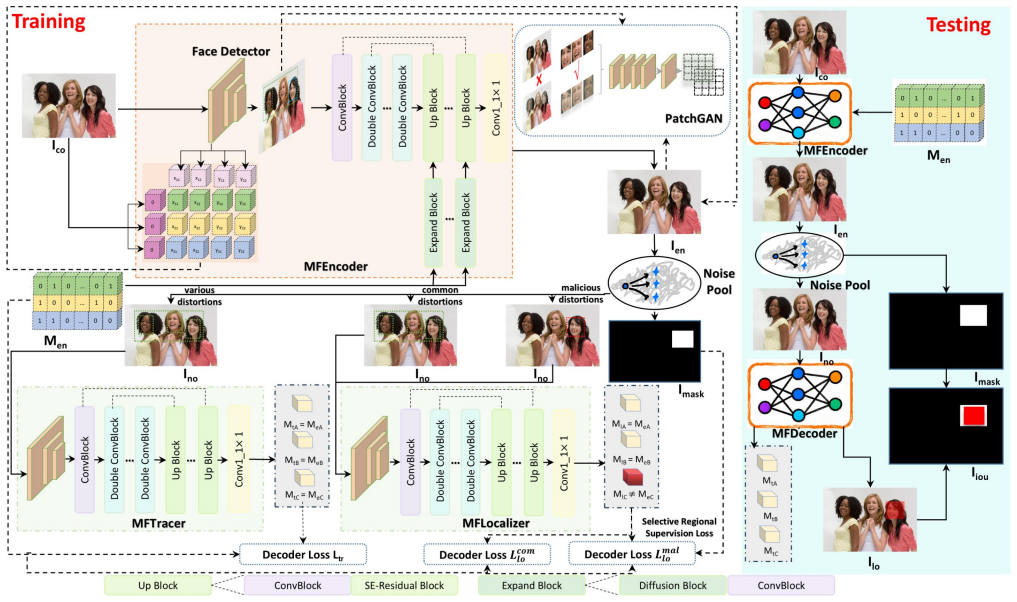
The Deep Attributable Watermarking Framework adopts a multi-face encoder-decoder architecture for parallel watermark embedding and cross-face processing. A selective regional supervision loss guides the decoder to concentrate exclusively on facial regions altered by deepfakes. Together with the embedded identity payloads, the system delivers simultaneous localization of forged areas and tracing of source identities, fulfilling the dual goal of identifying both the affected face and its original owner in complex multi-person images.
What carries the argument
The selective regional supervision loss that steers the decoder to process only the tampered facial regions amid multiple faces and background.
If this is right
- The architecture removes the need for separate offline preprocessing steps before watermark embedding.
- Parallel processing across faces in one image becomes feasible without sequential handling.
- Both spatial localization of forgeries and identity source tracing occur in a single forward pass.
- Performance holds on challenging multi-face datasets that include group interactions and meetings.
- The dual 'which face plus whose identity' output directly supports forensic reporting in complex scenes.
Where Pith is reading between the lines
- The same selective-loss principle could be tested on video clips where faces move between frames.
- Integration with camera pipelines might allow automatic protection of group photos at capture time.
- Robustness checks under social-media compression and resizing would clarify real-world deployment limits.
- Extending the identity payload to include additional attributes like age or expression could broaden forensic utility.
Load-bearing premise
The selective regional supervision loss can direct the decoder to tampered facial regions alone without distraction from other faces or background content.
What would settle it
A test set of multi-face images where the localization accuracy falls below single-face baselines when two faces share similar lighting or pose would show the selective loss fails to isolate targets reliably.
Figures





read the original abstract
Unlike single-face forgeries, deepfakes in complex multi-person interaction scenarios (such as group photos and multi-person meetings) more closely reflect real-world threats. Although existing proactive forensics solutions demonstrate good performance, they heavily rely on a "single-face" setting, making it difficult to effectively address the problems of deepfake localization and source tracing in complex multi-person environments. To address this challenge, we propose the Deep Attributable Watermarking Framework (DAWF). This framework adopts a novel multi-face encoder-decoder architecture that bypasses the cumbersome offline pre-processing steps of traditional forensics, facilitating efficient in-network parallel watermark embedding and cross-face collaborative processing. Crucially, we propose a selective regional supervision loss. This innovative mechanism guides the decoder to focus exclusively on the facial regions tampered with by deepfakes. Leveraging this mechanism alongside the embedded identity payloads, DAWF realizes the "which + who" goal, answering the dual questions of which facial region was forged and who was forged. Extensive experiments on challenging multi-face datasets show that DAWF achieves excellent deepfake localization and traceability in complex multi-person scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Deep Attributable Watermarking Framework (DAWF), a multi-face encoder-decoder architecture for proactive deepfake forensics. It enables parallel watermark embedding across faces and introduces a selective regional supervision loss to localize tampered regions while using embedded identity payloads for source tracing, addressing the dual 'which + who' challenge in multi-person images.
Significance. If the central claims hold, the work would fill a practical gap in deepfake forensics by moving beyond single-face assumptions to handle realistic multi-person scenarios such as group photos, with an in-network approach that avoids offline preprocessing. The combination of localization and traceability via watermarking represents a targeted advance over existing proactive methods.
major comments (2)
- [§3 (method)] The selective regional supervision loss is presented as the key mechanism that 'guides the decoder to focus exclusively on the facial regions tampered with by deepfakes' (abstract and §3), yet no equation, masking formulation, gradient-blocking rule, or cross-face orthogonality term is supplied. Without these, it is impossible to verify that gradients from non-tampered faces do not leak into the shared decoder weights, directly undermining the 'exclusively' claim required for reliable 'which' localization.
- [Experiments / Results] The abstract asserts 'excellent deepfake localization and traceability' on challenging multi-face datasets, but the manuscript supplies neither quantitative metrics, baseline comparisons, ablation studies on the supervision loss, nor error analysis of multi-face interference. These omissions make the empirical support for the dual-challenge solution impossible to evaluate.
minor comments (2)
- [§3] Notation for the identity payload embedding and the multi-face encoder-decoder forward pass is introduced without a clear diagram or pseudocode, making the parallel processing claim difficult to follow.
- [Introduction] The manuscript would benefit from an explicit statement of the threat model (e.g., whether the adversary knows the watermarking scheme) and how the framework remains robust under it.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will revise the manuscript accordingly to improve clarity and empirical support.
read point-by-point responses
-
Referee: [§3 (method)] The selective regional supervision loss is presented as the key mechanism that 'guides the decoder to focus exclusively on the facial regions tampered with by deepfakes' (abstract and §3), yet no equation, masking formulation, gradient-blocking rule, or cross-face orthogonality term is supplied. Without these, it is impossible to verify that gradients from non-tampered faces do not leak into the shared decoder weights, directly undermining the 'exclusively' claim required for reliable 'which' localization.
Authors: We acknowledge that the submitted manuscript does not provide the explicit mathematical formulation, masking details, gradient-blocking rules, or orthogonality terms for the selective regional supervision loss. This limits independent verification of the exclusivity claim. In the revision we will add the complete loss equation, the precise masking formulation used to isolate tampered facial regions, the gradient-blocking mechanism that prevents leakage from non-tampered faces into shared decoder weights, and any cross-face orthogonality term employed. revision: yes
-
Referee: [Experiments / Results] The abstract asserts 'excellent deepfake localization and traceability' on challenging multi-face datasets, but the manuscript supplies neither quantitative metrics, baseline comparisons, ablation studies on the supervision loss, nor error analysis of multi-face interference. These omissions make the empirical support for the dual-challenge solution impossible to evaluate.
Authors: The referee correctly notes that the current version lacks the required quantitative metrics, baseline comparisons, ablation studies, and multi-face error analysis. We will expand the experimental section to report concrete localization and traceability metrics, include relevant baseline comparisons, present ablation results isolating the selective regional supervision loss, and add an error analysis addressing potential interference across multiple faces. revision: yes
Circularity Check
No circularity detected; new architecture and loss are externally validated
full rationale
The paper introduces DAWF as a novel multi-face encoder-decoder with a selective regional supervision loss to achieve 'which + who' forensics. No equations, derivations, or parameter fits are shown that reduce by construction to inputs, fitted subsets, or self-citations. The central claims rest on the proposed architecture and loss mechanism, justified by experiments on external multi-face datasets rather than internal redefinitions or load-bearing prior work by the authors. This is a standard engineering proposal with independent empirical support.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Deep Attributable Watermarking Framework (DAWF)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shivangi Aneja, Lev Markhasin, and Matthias Nießner. 2022. Tafim: Targeted adversarial attacks against facial image manipulations. InEuropean Conference on Computer Vision. Springer, 58–75
2022
-
[2]
Renwang Chen, Xuanhong Chen, Bingbing Ni, and Yanhao Ge. 2020. Simswap: An efficient framework for high fidelity face swapping. InProceedings of the 28th ACM international conference on multimedia. 2003–2011
2020
-
[3]
Yunzhuo Chen, Jordan Vice, Naveed Akhtar, Nur Haldar, and Ajmal Mian. 2025. Dynamic watermarks in images generated by diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference(CVPR). 5271–5277
2025
-
[4]
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. 2020. Stargan v2: Diverse image synthesis for multiple domains. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition(CVPR). 8188–8197
2020
-
[5]
Chengbo Dong, Xinru Chen, Ruohan Hu, Juan Cao, and Xirong Li. 2022. Mvss-net: Multi-view multi-scale supervised networks for image manipulation detection. IEEE Transactions on Pattern Analysis and Machine Intelligence45, 3 (2022), 3539– 3553
2022
-
[6]
Alexander Groshev, Anastasia Maltseva, Daniil Chesakov, Andrey Kuznetsov, and Denis Dimitrov. 2022. GHOST—a new face swap approach for image and video domains.IEEE Access10 (2022), 83452–83462
2022
-
[7]
Sijia He, Yunfeng Diao, Yongming Li, Chen Sun, Liejun Wang, and Zhiqing Guo
-
[8]
KAD-Net: Kolmogorov-Arnold and Differential-Aware Networks for Robust and Sensitive Proactive Deepfake Forensics.Knowledge-Based Systems(2025), 114692
2025
-
[9]
Ziyuan He, Zhiqing Guo, Liejun Wang, Gaobo Yang, Yunfeng Diao, and Dan Ma
-
[10]
WaveGuard: Robust Deepfake Detection and Source Tracing via Dual-Tree Complex Wavelet and Graph Neural Networks.IEEE Transactions on Circuits and Systems for Video Technology(2025)
2025
-
[11]
Hao Huang, Yongtao Wang, Zhaoyu Chen, Yuze Zhang, Yuheng Li, Zhi Tang, Wei Chu, Jingdong Chen, Weisi Lin, and Kai-Kuang Ma. 2022. Cmua-watermark: A cross-model universal adversarial watermark for combating deepfakes. In Proceedings of the AAAI conference on artificial intelligence, Vol. 36. 989–997
2022
-
[12]
Ziyao Huang, Fan Tang, Yong Zhang, Juan Cao, Chengyu Li, Sheng Tang, Jintao Li, and Tong-Yee Lee. 2024. Identity-preserving face swapping via dual surrogate generative models.ACM Transactions on Graphics43, 5 (2024), 1–19
2024
-
[13]
Lixin Jia, Haiyang Sun, Zhiqing Guo, Yunfeng Diao, Dan Ma, and Gaobo Yang
- [14]
-
[15]
Zhaoyang Jia, Han Fang, and Weiming Zhang. 2021. Mbrs: Enhancing robustness of dnn-based watermarking by mini-batch of real and simulated jpeg compression. InProceedings of the 29th ACM international conference on multimedia. 41–49
2021
- [16]
-
[17]
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. 2017. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196(2017)
work page internal anchor Pith review arXiv 2017
-
[18]
Diederik P Kingma. 2014. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review arXiv 2014
-
[19]
Chenqi Kong, Anwei Luo, Shiqi Wang, Haoliang Li, Anderson Rocha, and Alex C Kot. 2025. Pixel-inconsistency modeling for image manipulation localization. IEEE Transactions on Pattern Analysis and Machine Intelligence(2025)
2025
-
[20]
Trung-Nghia Le, Huy H Nguyen, Junichi Yamagishi, and Isao Echizen. 2021. Open- forensics: Large-scale challenging dataset for multi-face forgery detection and segmentation in-the-wild. InProceedings of the IEEE/CVF international conference on computer vision(ICCV). 10117–10127
2021
-
[21]
Jiaming Li, Hongtao Xie, Jiahong Li, Zhongyuan Wang, and Yongdong Zhang
-
[22]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition(CVPR)
Frequency-aware discriminative feature learning supervised by single- center loss for face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition(CVPR). 6458–6467
-
[23]
Xiaodan Li, Yining Lang, Yuefeng Chen, Xiaofeng Mao, Yuan He, Shuhui Wang, Hui Xue, and Quan Lu. 2020. Sharp multiple instance learning for deepfake video detection. InProceedings of the 28th ACM international conference on multimedia. 1864–1872
2020
-
[24]
Yuezun Li and Siwei Lyu. 2018. Exposing deepfake videos by detecting face warping artifacts.arXiv preprint arXiv:1811.00656(2018)
work page Pith review arXiv 2018
-
[25]
Chenhao Lin, Fangbin Yi, Hang Wang, Jingyi Deng, Zhengyu Zhao, Qian Li, and Chao Shen. 2024. Exploiting facial relationships and feature aggregation for multi-face forgery detection.IEEE Transactions on Information Forensics and Security(2024)
2024
-
[26]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InEuropean conference on computer vision. Springer, 740–755
2014
-
[27]
Honggu Liu, Xiaodan Li, Wenbo Zhou, Yuefeng Chen, Yuan He, Hui Xue, Weiming Zhang, and Nenghai Yu. 2021. Spatial-phase shallow learning: rethinking face forgery detection in frequency domain. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition(CVPR). 772–781
2021
-
[28]
Rui Ma, Mengxi Guo, Yi Hou, Fan Yang, Yuan Li, Huizhu Jia, and Xiaodong Xie
-
[29]
InProceedings of the 30th ACM International Conference on Multi- media
Towards blind watermarking: Combining invertible and non-invertible mechanisms. InProceedings of the 30th ACM International Conference on Multi- media. 1532–1542
-
[30]
Xiaochen Ma, Bo Du, Zhuohang Jiang, Ahmed Y Al Hammadi, and Jizhe Zhou
- [31]
-
[32]
Paarth Neekhara, Shehzeen Hussain, Xinqiao Zhang, Ke Huang, Julian McAuley, and Farinaz Koushanfar. 2024. Facesigns: Semi-fragile watermarks for media authentication.ACM Transactions on Multimedia Computing, Communications and Applications20, 11 (2024), 1–21
2024
-
[33]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems32 (2019)
2019
-
[34]
Kaede Shiohara and Toshihiko Yamasaki. 2022. Detecting deepfakes with self- blended images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition(CVPR). 18720–18729
2022
-
[35]
Chen Sun, Haiyang Sun, Zhiqing Guo, Yunfeng Diao, Liejun Wang, Dan Ma, Gaobo Yang, and Keqin Li. 2025. DiffMark: Diffusion-based Robust Watermark Against Deepfakes.Information Fusion(2025)
2025
-
[36]
Justus Thies, Michael Zollhofer, Marc Stamminger, Christian Theobalt, and Matthias Nießner. 2016. Face2face: Real-time face capture and reenactment of rgb videos. InProceedings of the IEEE conference on computer vision and pattern recognition(CVPR). 2387–2395
2016
-
[37]
Run Wang, Ziheng Huang, Zhikai Chen, Li Liu, Jing Chen, and Lina Wang
- [38]
-
[39]
Tianyi Wang, Harry Cheng, Ming-Hui Liu, and Mohan Kankanhalli. 2025. Fractal- forensics: Proactive deepfake detection and localization via fractal watermarks. In Proceedings of the 33rd ACM International Conference on Multimedia. 7210–7219
2025
-
[40]
Tianyi Wang, Xin Liao, Kam Pui Chow, Xiaodong Lin, and Yinglong Wang. 2024. Deepfake detection: A comprehensive survey from the reliability perspective. Comput. Surveys57, 3 (2024), 1–35
2024
-
[41]
Zilan Wang, Junfeng Guo, Jiacheng Zhu, Yiming Li, Heng Huang, Muhao Chen, and Zhengzhong Tu. 2025. Sleepermark: Towards robust watermark against fine-tuning text-to-image diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference(CVPR). 8213–8224
2025
-
[42]
Xiaoshuai Wu, Xin Liao, and Bo Ou. 2023. Sepmark: Deep separable watermarking for unified source tracing and deepfake detection. InProceedings of the 31st ACM International Conference on Multimedia. 1190–1201
2023
-
[43]
Zhiliang Xu, Zhibin Hong, Changxing Ding, Zhen Zhu, Junyu Han, Jingtuo Liu, and Errui Ding. 2022. Mobilefaceswap: A lightweight framework for video face swapping. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 2973–2981
2022
-
[44]
Shuo Yang, Ping Luo, Chen-Change Loy, and Xiaoou Tang. 2016. Wider face: A face detection benchmark. InProceedings of the IEEE conference on computer vision and pattern recognition(CVPR). 5525–5533
2016
- [45]
-
[46]
Zijin Yang, Kai Zeng, Kejiang Chen, Han Fang, Weiming Zhang, and Nenghai Yu
-
[47]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR)
Gaussian shading: Provable performance-lossless image watermarking for diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). 12162–12171
-
[48]
Xuanyu Zhang, Runyi Li, Jiwen Yu, Youmin Xu, Weiqi Li, and Jian Zhang. 2024. Editguard: Versatile image watermarking for tamper localization and copyright protection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11964–11974
2024
-
[49]
Xuanyu Zhang, Zecheng Tang, Zhipei Xu, Runyi Li, Youmin Xu, Bin Chen, Feng Gao, and Jian Zhang. 2025. Omniguard: Hybrid manipulation localization via augmented versatile deep image watermarking. InProceedings of the Computer Vision and Pattern Recognition Conference. 3008–3018
2025
- [50]
-
[51]
Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, and Dongwei Ren
-
[52]
In Proceedings of the AAAI conference on artificial intelligence, Vol
Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 12993–13000
-
[53]
Tianfei Zhou, Wenguan Wang, Zhiyuan Liang, and Jianbing Shen. 2021. Face forensics in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition(CVPR). 5778–5788
2021
-
[54]
Jiren Zhu, Russell Kaplan, Justin Johnson, and Li Fei-Fei. 2018. Hidden: Hiding data with deep networks. InProceedings of the European conference on computer vision (ECCV). 657–672. 9
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.