Recognition: unknown
GateMOT: Q-Gated Attention for Dense Object Tracking
Pith reviewed 2026-05-07 13:52 UTC · model grok-4.3
The pith
GateMOT turns attention queries into element-wise probabilistic gates to enable efficient dense object tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
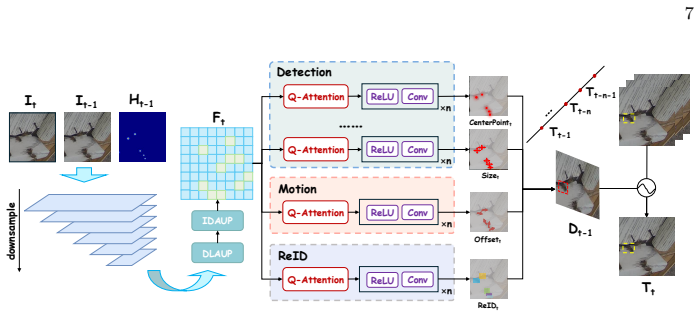
Our key idea is to repurpose the Query from a similarity-conditioning term into a learnable gating unit. This Gating-Query (Gating-Q) produces a probabilistic gate that modulates Key features in an element-wise manner, enabling explicit relevance selection instead of costly global aggregation. Built on this mechanism, parallel Q-Attention heads transform one shared feature map into task-specific yet consistent representations for detection, motion, and re-identification, yielding a tightly coupled multi-task decoder with linear-complexity gating operations.
What carries the argument
The Gating-Query (Gating-Q), which converts the query vector into a probabilistic element-wise gate that selectively modulates key features without computing pairwise similarities.
If this is right
- Parallel Q-Attention heads produce task-specific yet consistent representations for detection, motion, and re-identification from a single shared feature map.
- Gating operations run in linear rather than quadratic complexity relative to feature map size.
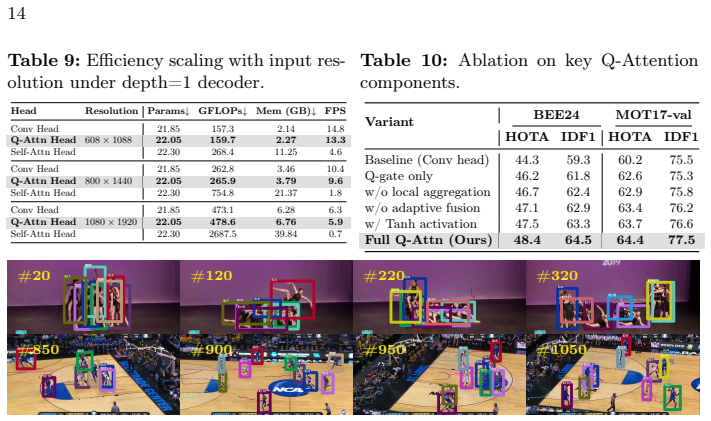
- The framework reaches state-of-the-art HOTA of 48.4, MOTA of 67.8, and IDF1 of 64.5 on the BEE24 benchmark.
- Q-Attention functions as a simple, transferable building block for attention-based modeling in other dense tracking scenarios.
Where Pith is reading between the lines
- The same query-to-gate conversion could be tested on other dense video tasks such as instance segmentation or optical flow in crowded scenes.
- Because gating stays local, the method may scale more gracefully to longer video sequences or higher frame rates than full attention.
- Replacing the learned gate with a fixed heuristic mask would provide a direct test of how much the probabilistic formulation contributes beyond simple spatial masking.
Load-bearing premise
Element-wise probabilistic gating computed from the query alone is enough to capture the spatial and temporal interactions required for accurate detection, motion, and re-identification in crowded, occlusion-heavy scenes.
What would settle it
Compare GateMOT against an otherwise identical model that uses standard quadratic attention on the BEE24 benchmark and check whether the gated version loses more than a few points in HOTA or IDF1 while using far less memory on high-resolution inputs.
Figures



read the original abstract
While large models demonstrate the strong representational power of vanilla attention, this core mechanism cannot be directly applied to Dense Object Tracking: its quadratic all-to-all interactions are computationally prohibitive for dense motion estimation on high-resolution features. This mismatch prevents Dense Object Tracking from fully leveraging attention-based modeling in crowded and occlusion-heavy scenes. To address this challenge, we introduce GateMOT, an online tracking framework centered on Q-Gated Attention (Q-Attention), an efficient and spatially aware attention variant. Our key idea is to repurpose the Query from a similarity-conditioning term into a learnable gating unit. This Gating-Query (Gating-Q) produces a probabilistic gate that modulates Key features in an element-wise manner, enabling explicit relevance selection instead of costly global aggregation. Built on this mechanism, parallel Q-Attention heads transform one shared feature map into task-specific yet consistent representations for detection, motion, and re-identification, yielding a tightly coupled multi-task decoder with linear-complexity gating operations. GateMOT achieves state-of-the-art HOTA of 48.4, MOTA of 67.8, and IDF1 of 64.5 on BEE24, and demonstrates strong performance on additional Dense Object Tracking benchmarks. These results show that Q-Attention is a simple, effective, and transferable building block for attention-based tracking in dense tracking scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GateMOT, an online framework for dense object tracking centered on Q-Gated Attention (Q-Attention). The core idea repurposes the query into a learnable Gating-Query that generates a probabilistic gate applied element-wise to key features, replacing quadratic all-to-all attention with linear-complexity operations. Parallel Q-Attention heads produce task-specific yet consistent representations for detection, motion, and re-identification in a multi-task decoder. The method reports state-of-the-art results on BEE24 (HOTA 48.4, MOTA 67.8, IDF1 64.5) and strong performance on other dense tracking benchmarks.
Significance. If the query-derived element-wise gating mechanism delivers the claimed accuracy in crowded and occluded scenes, it would offer a practical, efficient building block for attention-based modeling in dense MOT where standard quadratic attention is prohibitive. The multi-task consistency via shared features and parallel heads could influence designs for real-time tracking systems.
major comments (1)
- [Q-Attention mechanism] The central mechanism (abstract and method description) derives the probabilistic gate exclusively from the query with no explicit QK similarity term or key-dependent computation. This directly engages the weakest assumption that query-only gating suffices for dynamic relevance selection in occlusion-heavy scenes; standard attention derives relevance from pairwise comparison, and the manuscript must provide targeted ablations or occlusion-specific analysis to show the gate is not merely a static per-location mask.
minor comments (1)
- [Abstract] The abstract refers to 'additional Dense Object Tracking benchmarks' without naming them; listing the specific datasets and metrics would aid reproducibility and context.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the positive assessment of the work's potential impact. We address the single major comment below and will incorporate the requested analysis in the revised manuscript.
read point-by-point responses
-
Referee: [Q-Attention mechanism] The central mechanism (abstract and method description) derives the probabilistic gate exclusively from the query with no explicit QK similarity term or key-dependent computation. This directly engages the weakest assumption that query-only gating suffices for dynamic relevance selection in occlusion-heavy scenes; standard attention derives relevance from pairwise comparison, and the manuscript must provide targeted ablations or occlusion-specific analysis to show the gate is not merely a static per-location mask.
Authors: We confirm that Q-Attention generates the probabilistic gate solely from the Gating-Query without an explicit pairwise QK similarity or key-dependent term; this is an intentional design decision to replace quadratic attention with linear-complexity element-wise modulation. Because the Gating-Query is computed directly from the current input feature map, the resulting gate is input-dependent and varies across frames and scenes rather than acting as a static per-location mask. The strong empirical results on BEE24 (HOTA 48.4) in crowded and occluded conditions support that this query-derived gating suffices for dynamic relevance selection in the dense-tracking setting. To address the request for targeted evidence, the revision will add (i) an ablation replacing the query-only gate with a key-dependent variant and (ii) occlusion-specific performance breakdowns on BEE24 subsets. revision: yes
Circularity Check
No significant circularity; mechanism is a novel construction validated empirically
full rationale
The paper presents Q-Gated Attention as a new architectural variant that repurposes the Query tensor into an element-wise probabilistic gate applied to Key features, with parallel heads for multi-task decoding. This is introduced via description and evaluated directly on tracking benchmarks (BEE24, etc.) for HOTA/MOTA/IDF1 metrics, without any equations, derivations, or parameter fits that reduce the claimed efficiency or accuracy gains to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no known results are merely renamed. The derivation chain is self-contained as an empirical proposal of a linear-complexity attention substitute.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bot-sort: Robust associa- tions multi-pedestrian tracking,
Aharon, N., Orfaig, R., Bobrovsky, B.Z.: BoT-SORT: Robust Associations Multi- Pedestrian Tracking. arXiv preprint arXiv:2206.14651 (2022)
-
[2]
In: Proceedings of the IEEE/CVF international conference on computer vision
Bergmann,P.,Meinhardt,T.,Leal-Taixe,L.:TrackingWithoutBellsandWhistles. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 941–951 (2019)
2019
-
[3]
EURASIP Journal on Image and Video Processing 2008(1), 246309 (2008)
Bernardin, K., Stiefelhagen, R.: Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. EURASIP Journal on Image and Video Processing 2008(1), 246309 (2008)
2008
-
[4]
In: 2016 IEEE international conference on image processing (ICIP)
Bewley, A., Ge, Z., Ott, L., Ramos, F., Upcroft, B.: Simple Online and Realtime Tracking. In: 2016 IEEE international conference on image processing (ICIP). pp. 3464–3468. Ieee (2016)
2016
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cai, J., Xu, M., Li, W., Xiong, Y., Xia, W., Tu, Z., Soatto, S.: MeMOT: Multi- Object Tracking with Memory. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8090–8100 (2022)
2022
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cao, J., Pang, J., Weng, X., Khirodkar, R., Kitani, K.: Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9686– 9696 (2023)
2023
-
[7]
IEEE Transactions on Image Processing34, 743–758 (2025)
Cao, X., Zheng, Y., Yao, Y., Qin, H., Cao, X., Guo, S.: TOPIC: A Parallel Asso- ciation Paradigm for Multi-Object Tracking under Complex Motions and Diverse Scenes. IEEE Transactions on Image Processing34, 743–758 (2025)
2025
-
[8]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-End Object Detection with Transformers. In: European conference on computer vision. pp. 213–229. Springer (2020)
2020
-
[9]
In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
Chai, Y., Jin, S., Hou, X.: Highway Transformer: Self-Gating Enhanced Self- Attentive Networks. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 6887–6900 (2020)
2020
-
[10]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Z., Hu, Y., Fu, Z., Li, Z., Huang, J., Huang, Q., Wei, Y.: Intent: Invariance and Discrimination-Aware Noise Mitigation for Robust Composed Image Retrieval. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 20463–20471 (2026)
2026
-
[11]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Chen, Z., Hu, Y., Li, Z., Fu, Z., Song, X., Nie, L.: Offset: Segmentation-Based Focus Shift Revision for Composed Image Retrieval. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 6113–6122 (2025)
2025
-
[12]
arXiv preprint arXiv:2002.11338 (2020)
Cheng, Z., Xu, Y., Cheng, M., Qiao, Y., Pu, S., Niu, Y., Wu, F.: Refined Gate: A Simple and Effective Gating Mechanism for Recurrent Units. arXiv preprint arXiv:2002.11338 (2020)
-
[13]
Rethinking Attention with Performers
Choromanski, K., Likhosherstov, V., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J., Mohiuddin, A., Kaiser, L., et al.: Rethinking Attention with Performers. arXiv preprint arXiv:2009.14794 (2020)
work page internal anchor Pith review arXiv 2009
-
[14]
In: Proceedings of the IEEE/CVF Win- ter Conference on applications of computer vision
Chu, P., Wang, J., You, Q., Ling, H., Liu, Z.: TransMOT: Spatial-Temporal Graph Transformer for Multiple Object Tracking. In: Proceedings of the IEEE/CVF Win- ter Conference on applications of computer vision. pp. 4870–4880 (2023)
2023
-
[15]
In: Proceedings of the IEEE/CVF international conference on computer vision
Cui, Y., Zeng, C., Zhao, X., Yang, Y., Wu, G., Wang, L.: SportsMOT: A Large Multi-Object Tracking Dataset in Multiple Sports Scenes. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9921–9931 (2023)
2023
-
[16]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, T.: FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. arXiv preprint arXiv:2307.08691 (2023) 16
work page internal anchor Pith review arXiv 2023
-
[17]
Advances in neural information pro- cessing systems35, 16344–16359 (2022)
Dao, T., Fu, D., Ermon, S., Rudra, A., Ré, C.: FlashAttention: Fast and Memory- Efficient Exact Attention with IO-Awareness. Advances in neural information pro- cessing systems35, 16344–16359 (2022)
2022
-
[18]
International Journal of Computer Vision129(4), 845–881 (2021)
Dendorfer, P., Osep, A., Milan, A., Schindler, K., Cremers, D., Reid, I., Roth, S., Leal-Taixé, L.: MOTChallenge: A Benchmark for Single-Camera Multiple Target Tracking. International Journal of Computer Vision129(4), 845–881 (2021)
2021
-
[19]
arXiv preprint arXiv:2003.09003 (2020)
Dendorfer, P., Rezatofighi, H., Milan, A., Shi, J., Cremers, D., Reid, I., Roth, S., Schindler, K., Leal-Taixé, L.: MOT20: A Benchmark for Multi Object Tracking in Crowded Scenes. arXiv preprint arXiv:2003.09003 (2020)
-
[20]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review arXiv 2010
-
[21]
In: Proceedings of the IEEE international conference on computer vision
Feichtenhofer, C., Pinz, A., Zisserman, A.: Detect to Track and Track to Detect. In: Proceedings of the IEEE international conference on computer vision. pp. 3038– 3046 (2017)
2017
-
[22]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Gao, R., Qi, J., Wang, L.: Multiple Object Tracking as ID Prediction. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 27883–27893 (2025)
2025
-
[23]
Gao, R., Wang, L.: MeMOTR: Long-Term Memory-Augmented Transformer for Multi-ObjectTracking.In:ProceedingsoftheIEEE/CVFInternationalConference on Computer Vision. pp. 9901–9910 (2023)
2023
-
[24]
Ge, Z., Liu, S., Wang, F., Li, Z., Sun, J.: YOLOX: Exceeding YOLO Series in 2021 (2021),https://arxiv.org/abs/2107.08430
work page internal anchor Pith review arXiv 2021
-
[25]
arXiv preprint arXiv:2205.12740 (2022)
Gevorgyan, Z.: SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv preprint arXiv:2205.12740 (2022)
-
[26]
Applied Sciences12(21), 10741 (2022)
Guo, S., Wang, S., Yang, Z., Wang, L., Zhang, H., Guo, P., Gao, Y., Guo, J.: A Review of Deep Learning-Based Visual Multi-Object Tracking Algorithms for Autonomous Driving. Applied Sciences12(21), 10741 (2022)
2022
-
[27]
Applied Intelligence55(1), 33 (2025)
Han, X., Oishi, N., Tian, Y., Ucurum, E., Young, R., Chatwin, C., Birch, P.: ET- Track: Enhanced Temporal Motion Predictor for Multi-Object Tracking. Applied Intelligence55(1), 33 (2025)
2025
-
[28]
arXiv preprint arXiv:2407.04249 (2024)
Hashempoor, H., Koikara, R., Hwang, Y.D.: FeatureSORT: Essential Features for Effective Tracking. arXiv preprint arXiv:2407.04249 (2024)
-
[29]
arXiv preprint arXiv:2409.00487 (2024)
Hu,B.,Luo,R.,Liu,Z.,Wang,C.,Liu,W.:TrackSSM:AGeneralMotionPredictor by State-Space Model. arXiv preprint arXiv:2409.00487 (2024)
-
[30]
IEEE Transactions on Circuits and Systems for Video Technology33(11), 6571–6594 (2023)
Hu, M., Zhu, X., Wang, H., Cao, S., Liu, C., Song, Q.: STDFormer: Spatial- Temporal Motion Transformer for Multiple Object Tracking. IEEE Transactions on Circuits and Systems for Video Technology33(11), 6571–6594 (2023)
2023
-
[31]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hu, Y., Song, Z., Feng, N., Luo, Y., Yu, J., Chen, Y.P.P., Yang, W.: Sf2t: Self- Supervised Fragment Finetuning of Video-LLMs for Fine-Grained Understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29108–29117 (2025)
2025
-
[32]
ACM Transactions on Multimedia Computing, Communications and Applications (2026)
Hu,Y.,Li,Z.,Chen,Z.,Huang,Q.,Fu,Z.,Xu,M.,Nie,L.:Refine:ComposedVideo Retrieval via Shared and Differential Semantics Enhancement. ACM Transactions on Multimedia Computing, Communications and Applications (2026)
2026
-
[33]
In: European Conference on Computer Vision
Huang, C., Wu, B., Nevatia, R.: Robust Object Tracking by Hierarchical Associ- ation of Detection Responses. In: European Conference on Computer Vision. pp. 788–801. Springer (2008)
2008
-
[34]
Kalman, R.E.: A New Approach to Linear Filtering and Prediction Problems (1960) 17
1960
-
[35]
In: International conference on machine learning
Katharopoulos, A., Vyas, A., Pappas, N., Fleuret, F.: Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. In: International conference on machine learning. pp. 5156–5165. PMLR (2020)
2020
-
[36]
In:Convolutional neuralnetworks withswiftfor tensorflow: image recognition and dataset categorization, pp
Koonce, B.:ResNet-50. In:Convolutional neuralnetworks withswiftfor tensorflow: image recognition and dataset categorization, pp. 63–72. Springer (2021)
2021
-
[37]
Li, W., Song, Z., Zhang, J., Zhao, T., Lin, J., Wang, Y., Yang, W.: Large Language Model as Token Compressor and Decompressor (2026)
2026
-
[38]
arXiv preprint arXiv:2507.00029 (2025)
Li, W., Song, Z., Zhou, H., Zhang, Y., Yu, J., Yang, W.: LoRA-Mixer: Coordi- nate Modular LoRA Experts Through Serial Attention Routing. arXiv preprint arXiv:2507.00029 (2025)
work page internal anchor Pith review arXiv 2025
-
[39]
Advances in Neural Information Processing Systems37, 59808–59832 (2024)
Li, W., Zhou, H., Yu, J., Song, Z., Yang, W.: Coupled mamba: Enhanced mul- timodal fusion with coupled state space model. Advances in Neural Information Processing Systems37, 59808–59832 (2024)
2024
-
[40]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, Z., Hu, Y., Chen, Z., Huang, Q., Qiu, G., Fu, Z., Liu, M.: Retrack: Evidence- driven dual-stream directional anchor calibration network for composed video re- trieval. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 23373–23381 (2026)
2026
-
[41]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, Z., Hu, Y., Chen, Z., Zhang, S., Huang, Q., Fu, Z., Wei, Y.: Habit: Chrono- synergia robust progressive learning framework for composed image retrieval. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 6762– 6770 (2026)
2026
-
[42]
In: Proceedings of the IEEE international conference on computer vision
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal Loss for Dense Ob- ject Detection. In: Proceedings of the IEEE international conference on computer vision. pp. 2980–2988 (2017)
2017
-
[43]
IEEE Transactions on Circuits and Systems for Video Technology35(5), 4870–4882 (2025)
Liu, Z., Wang, X., Wang, C., Liu, W., Bai, X.: SparseTrack: Multi-Object Tracking by Performing Scene Decomposition Based on Pseudo-Depth. IEEE Transactions on Circuits and Systems for Video Technology35(5), 4870–4882 (2025)
2025
-
[44]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Lu, Z., Shuai, B., Chen, Y., Xu, Z., Modolo, D.: Self-Supervised Multi-Object Tracking with Path Consistency. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19016–19026. IEEE Computer Soci- ety (2024)
2024
-
[45]
Luiten, J., Osep, A., Dendorfer, P., Torr, P., Geiger, A., Leal-Taixé, L., Leibe, B.: HOTA:AHigherOrderMetricforEvaluatingMulti-ObjectTracking.International journal of computer vision129(2), 548–578 (2021)
2021
-
[46]
In: Proceedings of the IEEE/CVF international conference on computer vision
Luo, C., Yang, X., Yuille, A.: Exploring Simple 3D Multi-Object Tracking for Autonomous Driving. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10488–10497 (2021)
2021
-
[47]
In: Proceedings of the AAAI conference on artificial intelligence
Luo, R., Song, Z., Ma, L., Wei, J., Yang, W., Yang, M.: DiffusionTrack: Diffu- sion Model for Multi-Object Tracking. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 3991–3999 (2024)
2024
-
[48]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Lv,W.,Huang,Y.,Zhang,N.,Lin,R.S.,Han,M.,Zeng,D.:DiffMOT:AReal-Time Diffusion-Based Multiple Object Tracker with Non-Linear Prediction. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19321–19330 (2024)
2024
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Meinhardt, T., Kirillov, A., Leal-Taixe, L., Feichtenhofer, C.: TrackFormer: Multi- Object Tracking with Transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8844–8854 (2022)
2022
-
[50]
In: European conference on computer vision
Pang, Z., Li, Z., Wang, N.: SimpleTrack: Understanding and Rethinking 3D Multi-Object Tracking. In: European conference on computer vision. pp. 680–696. Springer (2022) 18
2022
-
[51]
In: European conference on computer vision
Peng, J., Wang, C., Wan, F., Wu, Y., Wang, Y., Tai, Y., Wang, C., Li, J., Huang, F.,Fu,Y.:Chained-Tracker:ChainingPairedAttentiveRegressionResultsforEnd- to-End Joint Multiple-Object Detection and Tracking. In: European conference on computer vision. pp. 145–161. Springer (2020)
2020
-
[52]
Applied Sciences12(3), 1319 (2022)
Pereira, R., Carvalho, G., Garrote, L., Nunes, U.J.: SORT and Deep-SORT Based Multi-Object Tracking for Mobile Robotics: Evaluation with New Data Association Metrics. Applied Sciences12(3), 1319 (2022)
2022
-
[53]
Qin, Z., Wang, L., Zhou, S., Fu, P., Hua, G., Tang, W.: Towards Generalizable Multi-ObjectTracking.In:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition. pp. 18995–19004 (2024)
2024
-
[54]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Qin, Z., Zhou, S., Wang, L., Duan, J., Hua, G., Tang, W.: MotionTrack: Learning Robust Short-Term and Long-Term Motions for Multi-Object Tracking. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17939–17948 (2023)
2023
-
[55]
arXiv preprint arXiv:2603.29291 (2026)
Qiu, G., Chen, Z., Li, Z., Huang, Q., Fu, Z., Song, X., Hu, Y.: MELT: Improve ComposedImageRetrievalviatheModificationFrequentation-RarityBalanceNet- work. arXiv preprint arXiv:2603.29291 (2026)
-
[56]
Advances in neural information processing systems28(2015)
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards Real-Time Ob- ject Detection with Region Proposal Networks. Advances in neural information processing systems28(2015)
2015
-
[57]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Rezatofighi, H., Tsoi, N., Gwak, J., Sadeghian, A., Reid, I., Savarese, S.: General- ized Intersection over Union: A Metric and a Loss for Bounding Box Regression. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 658–666 (2019)
2019
-
[58]
In: European Conference on Computer Vision
Segu, M., Piccinelli, L., Li, S., Van Gool, L., Yu, F., Schiele, B.: WALKER: Self- SupervisedMultipleObjectTrackingbyWalkingonTemporalAppearanceGraphs. In: European Conference on Computer Vision. pp. 1–18. Springer (2024)
2024
-
[59]
arXiv preprint arXiv:2410.01806 (2024)
Segu, M., Piccinelli, L., Li, S., Yang, Y.H., Schiele, B., Van Gool, L.: Samba: Syn- chronized Set-of-Sequences Modeling for Multiple Object Tracking. arXiv preprint arXiv:2410.01806 (2024)
-
[60]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Song, Z., Luo, R., Ma, L., Tang, Y., Chen, Y.P.P., Yu, J., Yang, W.: Temporal Coherent Object Flow for Multi-Object Tracking. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 6978–6986 (2025)
2025
-
[61]
In: Proceedings of the AAAI conference on artificial intelligence
Song, Z., Luo, R., Yu, J., Chen, Y.P.P., Yang, W.: Compact transformer tracker with correlative masked modeling. In: Proceedings of the AAAI conference on artificial intelligence. vol. 37, pp. 2321–2329 (2023)
2023
-
[62]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Song, Z., Tang, Y., Luo, R., Ma, L., Yu, J., Chen, Y.P.P., Yang, W.: Autogenic language embedding for coherent point tracking. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 2021–2030 (2024)
2021
-
[63]
Song, Z., Yu, J., Chen, Y.P.P., Yang, W.: Transformer tracking with cyclic shifting windowattention.In:ProceedingsoftheIEEE/CVFconferenceoncomputervision and pattern recognition. pp. 8791–8800 (2022)
2022
-
[64]
Song, Z., Yu, J., Chen, Y.P.P., Yang, W., Wang, X.: Hypergraph-State Collabora- tive Reasoning for Multi-Object Tracking (2026)
2026
-
[65]
In: Proceed- ings of the IEEE/CVF conference on Computer Vision and Pattern Recognition
Stone, A., Maurer, D., Ayvaci, A., Angelova, A., Jonschkowski, R.: SMURF: Self- Teaching Multi-Frame Unsupervised RAFT with Full-Image Warping. In: Proceed- ings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. pp. 3887–3896 (2021)
2021
-
[66]
arXiv preprint arXiv:2012.15460 (2020) 19
Sun, P., Cao, J., Jiang, Y., Zhang, R., Xie, E., Yuan, Z., Wang, C., Luo, P.: TransTrack: Multiple-Object Tracking with Transformer. arXiv preprint arXiv:2012.15460 (2020) 19
-
[67]
In: Proceedings of the IEEE/CVF international conference on computer vision
Tokmakov, P., Li, J., Burgard, W., Gaidon, A.: Learning to Track with Object Per- manence. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10860–10869 (2021)
2021
-
[68]
Advances in neural information processing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention Is All You Need. Advances in neural information processing systems30(2017)
2017
-
[69]
Linformer: Self-Attention with Linear Complexity
Wang, S., Li, B.Z., Khabsa, M., Fang, H., Ma, H.: Linformer: Self-Attention with Linear Complexity. arXiv preprint arXiv:2006.04768 (2020)
work page internal anchor Pith review arXiv 2006
-
[70]
Wang, Z., Zhao, H., Li, Y.L., Wang, S., Torr, P., Bertinetto, L.: Do Different Track- ing Tasks Require Different Appearance Models? Advances in neural information processing systems34, 726–738 (2021)
2021
-
[71]
arXiv preprint arXiv:2008.08063 (2020)
Weng, X., Wang, J., Held, D., Kitani, K.: AB3DMOT: A Baseline for 3D Multi- Object Tracking and New Evaluation Metrics. arXiv preprint arXiv:2008.08063 (2020)
-
[72]
In: 2017 IEEE international conference on image pro- cessing (ICIP)
Wojke, N., Bewley, A., Paulus, D.: Simple Online and Realtime Tracking with a Deep Association Metric. In: 2017 IEEE international conference on image pro- cessing (ICIP). pp. 3645–3649. IEEE (2017)
2017
-
[73]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Wu, J., Cao, J., Song, L., Wang, Y., Yang, M., Yuan, J.: Track to Detect and Segment: An Online Multi-Object Tracker. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 12352–12361 (2021)
2021
-
[74]
In: Proceedings of the IEEE international conference on computer vision
Xiang, Y., Alahi, A., Savarese, S.: Learning to Track: Online Multi-Object Track- ing by Decision Making. In: Proceedings of the IEEE international conference on computer vision. pp. 4705–4713 (2015)
2015
-
[75]
In: Proceedings of the 32nd ACM international conference on multimedia
Xiao, C., Cao, Q., Luo, Z., Lan, L.: MambaTrack: A Simple Baseline for Multi- ple Object Tracking with State Space Model. In: Proceedings of the 32nd ACM international conference on multimedia. pp. 4082–4091 (2024)
2024
-
[76]
In: Proceedings of the AAAI conference on artificial intelligence
Yang, M., Han, G., Yan, B., Zhang, W., Qi, J., Lu, H., Wang, D.: Hybrid-SORT: Weak Cues Matter for Online Multi-Object Tracking. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 6504–6512 (2024)
2024
-
[77]
arXiv preprint arXiv:2604.01617 (2026)
Yang, Q., Chen, Z., Hu, Y., Li, Z., Fu, Z., Nie, L.: Stable: Efficient Hybrid Near- est Neighbor Search via Magnitude-Uniformity and Cardinality-Robustness. arXiv preprint arXiv:2604.01617 (2026)
-
[78]
arXiv preprint arXiv:2509.21715 (2025)
Yang, X., Agam, G.: Motion-Aware Transformer for Multi-Object Tracking. arXiv preprint arXiv:2509.21715 (2025)
-
[79]
arXiv preprint arXiv:2507.00950 (2025)
Ye,L.,Zhang, Y.,Wu,Y.,Chen, Y.P.P., Yu,J., Yang,W., Song,Z.:MVP: Winning Solution to SMP Challenge 2025 Video Track. arXiv preprint arXiv:2507.00950 (2025)
-
[80]
In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition
Yu, F., Wang, D., Shelhamer, E., Darrell, T.: Deep Layer Aggregation. In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition. pp. 2403–2412 (2018)
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.