Recognition: unknown
Shorthand for Thought: Compressing LLM Reasoning via Entropy-Guided Supertokens
Pith reviewed 2026-05-07 13:28 UTC · model grok-4.3
The pith
Large language models can compress their reasoning traces by learning supertokens for frequent structural patterns, shortening outputs by 8.1 percent with no accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
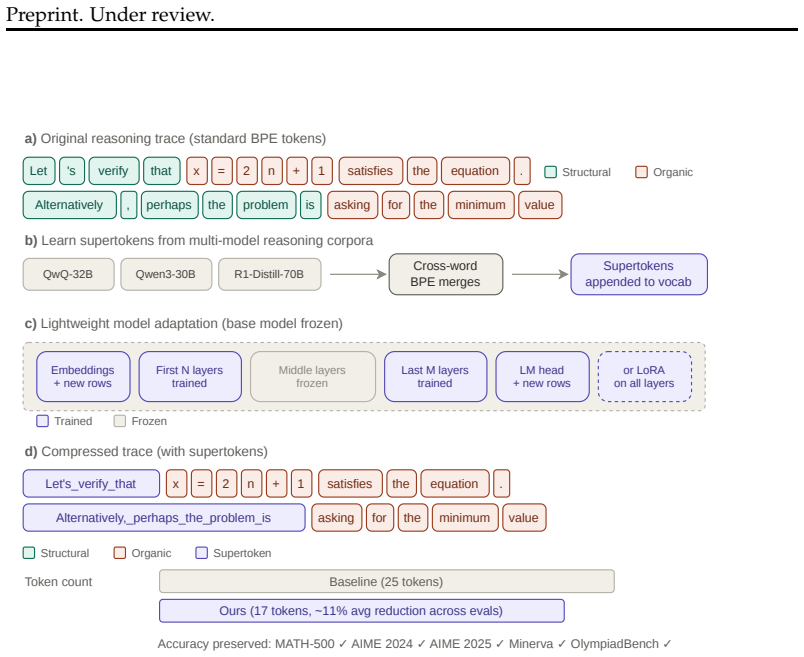
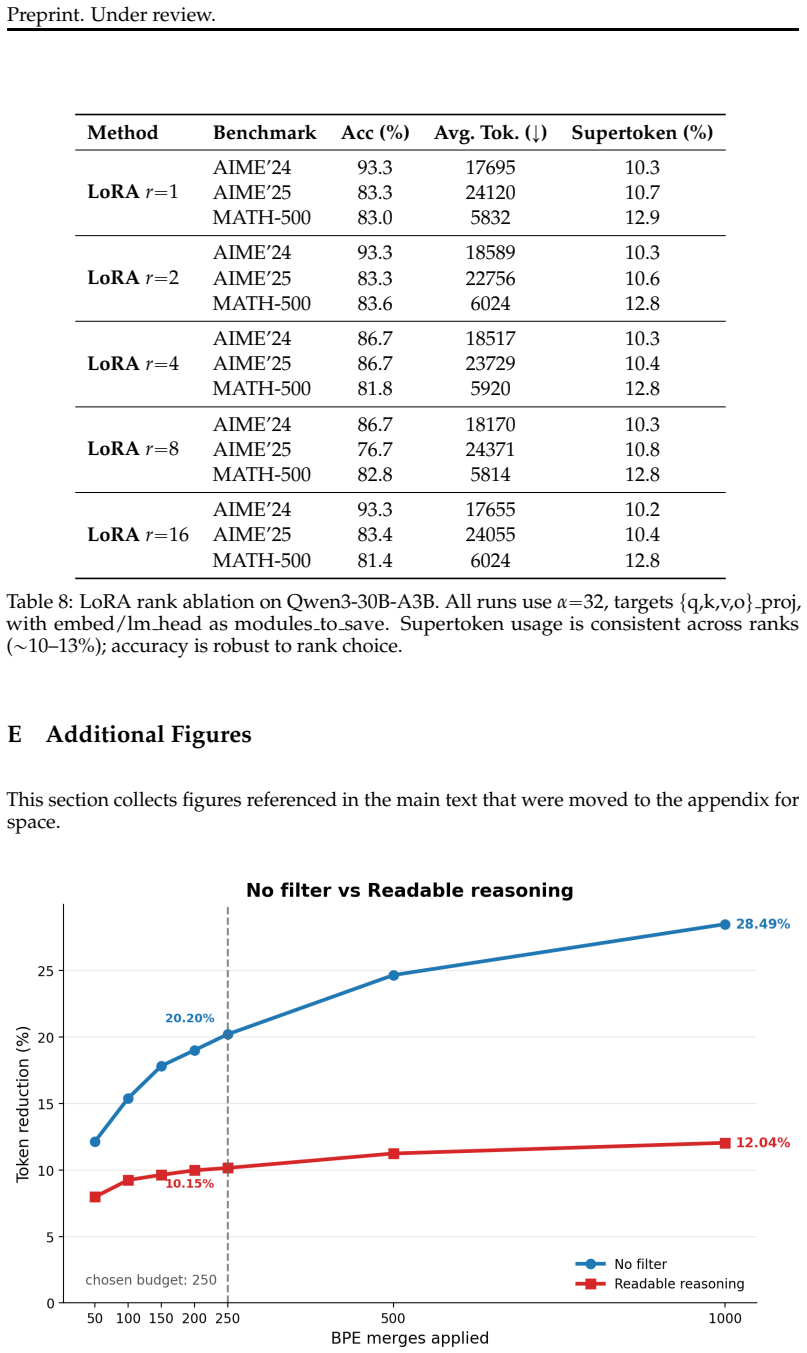
Reasoning tokens divide into low-entropy structural tokens that recur as scaffolding and higher-entropy organic tokens that advance toward solutions. Applying cross-word BPE merges to the model's reasoning traces creates supertokens that capture these structural patterns. Supervised fine-tuning then teaches the model to employ the supertokens, which shortens traces by 8.1 percent on average across three model families and five math benchmarks with no statistically significant accuracy loss on any pair. The supertokens additionally annotate high-level reasoning moves and reveal that correct traces exhibit productive recovery sequences while incorrect ones show repeated confusion cycles.
What carries the argument
Supertokens created by cross-word BPE merges on low-entropy structural tokens from the model's own reasoning traces, then adopted through supervised fine-tuning.
If this is right
- Reasoning traces require fewer tokens on average, lowering inference-time compute.
- High-level reasoning strategies become visible through the supertoken annotations.
- Transitions between structural categories can distinguish correct from incorrect traces.
- The same signals could guide reward design in reinforcement learning for reasoning.
- Early stopping rules could be based on detected confusion cycles in ongoing traces.
Where Pith is reading between the lines
- The method might extend to non-mathematical domains if similar entropy splits appear in other reasoning traces.
- Combining supertokens with techniques like speculative decoding could produce further length reductions.
- Checking whether supertokens emerge in generations without explicit fine-tuning prompts would test how deeply the model internalizes them.
- Systematic analysis of supertoken usage across correct and incorrect paths could inform targeted interventions for common failure modes.
Load-bearing premise
That supervised fine-tuning on traces containing the new supertokens causes the model to substitute them for original phrases without shifting its underlying reasoning distribution or introducing errors that cancel out when accuracy is measured in aggregate.
What would settle it
Measuring accuracy and trace length on a new set of mathematical problems or an additional model family where the supertoken version shows a statistically significant accuracy drop relative to the baseline would falsify the central claim.
Figures







read the original abstract
Reasoning in Large Language Models incurs significant inference-time compute, yet the token-level information structure of reasoning traces remains underexplored. We observe that reasoning tokens split into two functional types: low-entropy \textit{structural} tokens (recurring phrases that scaffold the reasoning process) and higher-entropy \textit{organic} tokens (problem-specific content that drives toward a solution). This asymmetry motivates a simple, model-agnostic compression pipeline: apply cross-word BPE merges on a model's own reasoning traces to derive \textit{supertokens} that capture frequent structural patterns, then teach the model to adopt them via supervised fine-tuning. Across three model families and five mathematical reasoning benchmarks, our approach shortens reasoning traces by 8.1\% on average with no statistically significant accuracy loss on any model--benchmark pair. Beyond compression, supertokens act as interpretable reasoning-move annotations (backtracking, verification, strategy shifts), exposing the model's high-level strategy at a glance. Analyzing transitions between structural categories reveals systematic differences between correct and incorrect traces: correct traces show productive recovery (backtracking followed by strategy shifts and verification), while incorrect traces are dominated by confusion cycles (repeated hedging and unresolved contradictions). These diagnostic signals suggest applications in reward shaping and early stopping for RL-based reasoning training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an entropy-guided compression method for LLM reasoning traces: low-entropy structural tokens (recurring scaffolding phrases) are identified and replaced by supertokens obtained via cross-word BPE merges on the model's own traces, after which the model is taught to use the new tokens through supervised fine-tuning. Across three model families and five mathematical reasoning benchmarks the method yields an average 8.1% shortening of reasoning traces with no statistically significant accuracy loss on any model-benchmark pair. The supertokens are further shown to function as interpretable annotations, and transition analysis between structural categories reveals systematic differences between correct traces (productive backtracking and verification) and incorrect traces (hedging loops).
Significance. If the central empirical result holds, the work provides a lightweight, model-agnostic route to lower inference cost for chain-of-thought reasoning while preserving final-answer accuracy. The additional interpretability layer—treating supertokens as high-level reasoning-move labels—could support downstream applications such as reward shaping or early stopping in RL-based reasoning training. The approach is grounded in an observable token-level entropy asymmetry rather than hand-crafted rules, which is a constructive contribution to the literature on efficient LLM inference.
major comments (2)
- [Abstract / Transition analysis] The headline claim of no statistically significant accuracy loss (Abstract) rests on the untested assumption that SFT on supertoken-augmented traces leaves the model's underlying reasoning-step distribution unchanged. Because the transition analysis between structural categories is performed exclusively on post-SFT outputs, it cannot distinguish faithful compression from the possibility that the model has learned opaque shortcuts that reach the same final answers via altered intermediate paths or error-recovery patterns.
- [Abstract / Experiments] The reported 8.1% compression figure and the null accuracy result lack any description of the precise statistical tests, run-to-run variance, baseline tokenization procedure, or controls for prompt-length confounds. Without these details it is impossible to assess whether the accuracy equivalence is robust or whether the compression benefit is partly an artifact of altered generation dynamics.
minor comments (2)
- The definitions of 'structural' versus 'organic' tokens are introduced qualitatively in the Abstract; a quantitative entropy threshold or explicit decision rule would make the pipeline reproducible.
- The manuscript would benefit from a short table listing per-model, per-benchmark compression ratios and accuracy deltas together with the exact p-values or confidence intervals used for the 'no significant loss' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify key aspects of our methodology and statistical reporting. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Transition analysis] The headline claim of no statistically significant accuracy loss (Abstract) rests on the untested assumption that SFT on supertoken-augmented traces leaves the model's underlying reasoning-step distribution unchanged. Because the transition analysis between structural categories is performed exclusively on post-SFT outputs, it cannot distinguish faithful compression from the possibility that the model has learned opaque shortcuts that reach the same final answers via altered intermediate paths or error-recovery patterns.
Authors: We acknowledge that the transition analysis is performed on post-SFT outputs, as this is the regime in which the supertokens are utilized by the model. To directly address the concern regarding potential changes to the reasoning-step distribution or introduction of opaque shortcuts, we will add a new analysis in the revised manuscript. Specifically, we will generate and label structural categories on a set of pre-SFT reasoning traces from the base models, compute the corresponding transition matrices, and compare them to the post-SFT results. This will quantify any shifts induced by SFT and allow us to discuss whether the observed differences between correct and incorrect traces reflect genuine strategy patterns or artifacts of fine-tuning. We believe this addition will support the claim of faithful compression while preserving accuracy. revision: yes
-
Referee: [Abstract / Experiments] The reported 8.1% compression figure and the null accuracy result lack any description of the precise statistical tests, run-to-run variance, baseline tokenization procedure, or controls for prompt-length confounds. Without these details it is impossible to assess whether the accuracy equivalence is robust or whether the compression benefit is partly an artifact of altered generation dynamics.
Authors: We agree that these experimental details should be explicitly documented in the main text for full transparency and reproducibility. In the revised version, we will expand the Experiments section with a clear description of the statistical tests used to establish the lack of significant accuracy differences, the run-to-run variance across multiple seeds, the baseline tokenization procedure (standard BPE without the entropy-guided merges), and the controls implemented for prompt-length confounds, including the use of fixed prompt templates and normalization of input lengths. These additions will enable readers to better evaluate the robustness of both the compression gains and the accuracy equivalence. revision: yes
Circularity Check
No circularity: core result is direct empirical measurement on held-out data
full rationale
The paper's central claim (8.1% average shortening with no significant accuracy loss) is obtained by running the trained model on separate benchmarks and counting tokens, not by any equation or definition that reduces to the training procedure itself. The pipeline (entropy split observation, BPE-derived supertokens from training traces, SFT) is a standard experimental method whose outcome is independently verifiable on held-out sets. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation of the reported numbers. The transition analysis is likewise a post-training diagnostic performed on generated outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Low-entropy tokens in reasoning traces reliably correspond to reusable structural scaffolding rather than problem-specific content
- domain assumption Supervised fine-tuning on supertoken examples transfers the compression benefit without changing solution quality
invented entities (3)
-
supertokens
no independent evidence
-
structural tokens
no independent evidence
-
organic tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kaiwen Chen et al. CtrlCoT: Dual-granularity chain-of-thought compression for controllable reasoning.arXiv preprint arXiv:2601.20467,
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evalu- ating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review arXiv
-
[3]
Learning to maximize mutual information for chain-of-thought distillation
Xin Chen, Hanxian Huang, Yanjun Gao, Yi Wang, Jishen Zhao, and Ke Ding. Learning to maximize mutual information for chain-of-thought distillation. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 6857–6868,
2024
-
[4]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[6]
From explicit cot to implicit cot: Learning to internalize cot step by step
Yuntian Deng, Yejin Choi, and Stuart Shieber. From explicit CoT to implicit CoT: Learning to internalize CoT step by step.arXiv preprint arXiv:2405.14838,
-
[7]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aieleen Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review arXiv
-
[8]
OpenThoughts: Data Recipes for Reasoning Models
URL https: //arxiv.org/abs/2506.04178. Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuan- dong Tian. Training large language models to reason in a continuous latent space,
work page internal anchor Pith review arXiv
-
[9]
Training Large Language Models to Reason in a Continuous Latent Space
URLhttps://arxiv.org/abs/2412.06769. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. OlympiadBench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Ann...
work page internal anchor Pith review arXiv
-
[10]
Jiayi Huang et al. Towards efficient large language reasoning models via extreme-ratio chain-of-thought compression.arXiv preprint arXiv:2602.08324,
-
[11]
URLhttps://arxiv.org/abs/2410.05864. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), pp. 611–626,
-
[12]
URLhttps://arxiv.org/abs/2405.05417. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35:3843–3857,
-
[13]
Plan and budget: Effective and efficient test-time scaling on large language model reasoning
URLhttps://arxiv.org/abs/2505.16122. Alisa Liu, Jonathan Hayase, Valentin Hofmann, Sewoong Oh, Noah A Smith, and Yejin Choi. SuperBPE: Space travel for language models.arXiv preprint arXiv:2503.13423,
-
[14]
Qwen Team. QwQ-32b technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review arXiv
-
[15]
Rico Sennrich, Barry Haddow, and Alexandra Birch
URL https://arxiv.org/abs/ 2504.00178. Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pp. 1715–1725,
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Li, Mingchuan Zhang, Y.K. Zhang, Yu Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review arXiv
-
[17]
URLhttps://arxiv.org/abs/2502.03275. Shicheng Sun et al. ConMax: Confidence-maximizing compression for efficient chain-of- thought reasoning.arXiv preprint arXiv:2601.04973,
-
[18]
URLhttps://arxiv.org/abs/2505.20415. 11 Preprint. Under review. Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcem...
-
[19]
Tokenskip: Controllable chain-of-thought compression in llms
arXiv:2502.12067. An Yang, Baosong Yang, Beichen Zhang, Binyuan Wang, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388,
-
[20]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models, 2023a. URLhttps://arxiv.org/abs/2305.10601. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in ...
work page internal anchor Pith review arXiv 2024
-
[21]
R1-compress: Long chain-of-thought compression via chunk compression and search
Quanjun Yi, Xiao Wu, Hai Zhu, et al. R1-Compress: Long chain-of-thought compression via chunk compression and search.arXiv preprint arXiv:2505.16838,
-
[22]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou et al. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review arXiv
-
[23]
Two ·books ·are ·now ·taken ·off ·each ·shelf
is dominated by backtracking (red) and counterargu- 13 Preprint. Under review. ments (orange) with notably fewer verification events, consistent with the confusion-cycle pattern described in Section 5.4. 0 500 1000 1500 2000 2500 3000 Token position Window 1 Window 2 Window 3 9 ·= ·1 0 ^ x . ·Hmm ,·let ·see . · First, ·maybe ·I ·shou ·try ·to ·simp ·this ...
2000
-
[24]
fires before “problem” (priority 4), yieldingHedging, reflecting that the dominant pragmatic function of the phrase is expressing uncertainty rather than referencing the problem. We verified the priority ordering by manually inspecting all 25 supertokens that match keywords from two or more categories; in each case the highest-priority rule assigns the pr...
2023
-
[25]
write exactly 3 paragraphs
H Cross-Model Entropy Validation The entropy analysis in Section 4.2 uses QwQ-32B as both generator and scorer, raising the question of whether the observed structural/organic entropy gap is an artifact of a single model’s idiosyncrasies. To address this, we re-score the same QwQ-32B reasoning traces using Qwen3-30B-A3B as the scorer model. Both models sh...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.