Recognition: unknown
Sparsity as a Key: Unlocking New Insights from Latent Structures for Out-of-Distribution Detection
Pith reviewed 2026-05-07 11:21 UTC · model grok-4.3
The pith
Sparse autoencoders on ViT class tokens produce stable class-specific activation patterns that out-of-distribution samples break.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
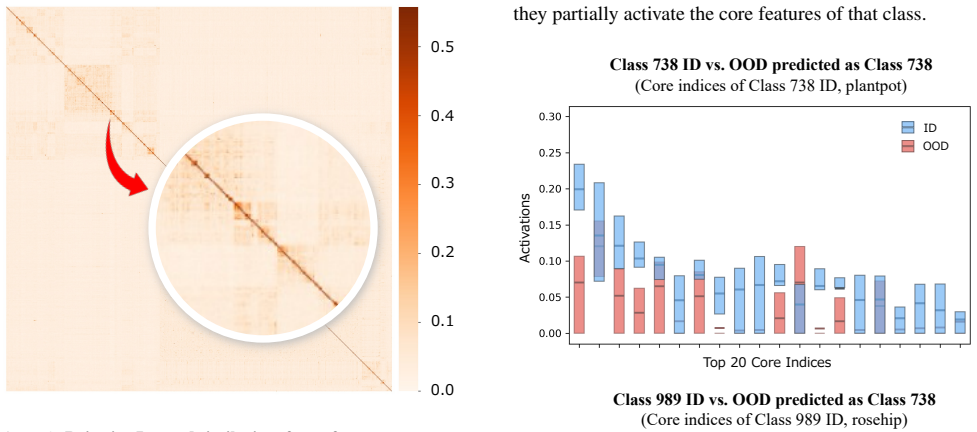
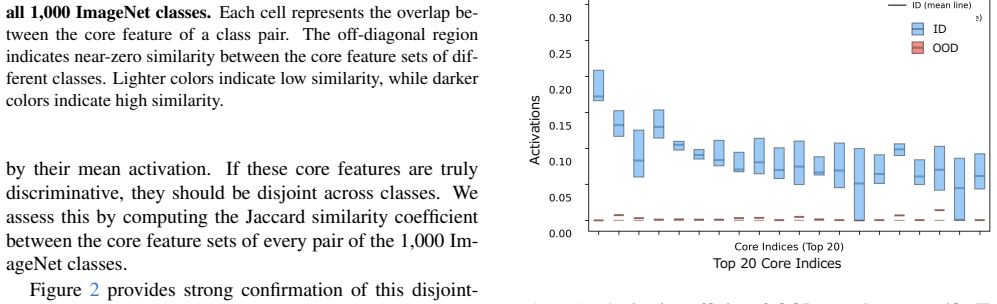
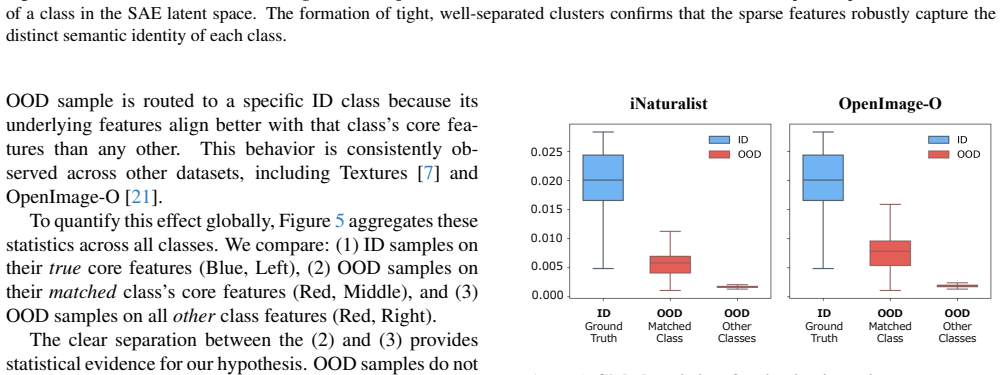
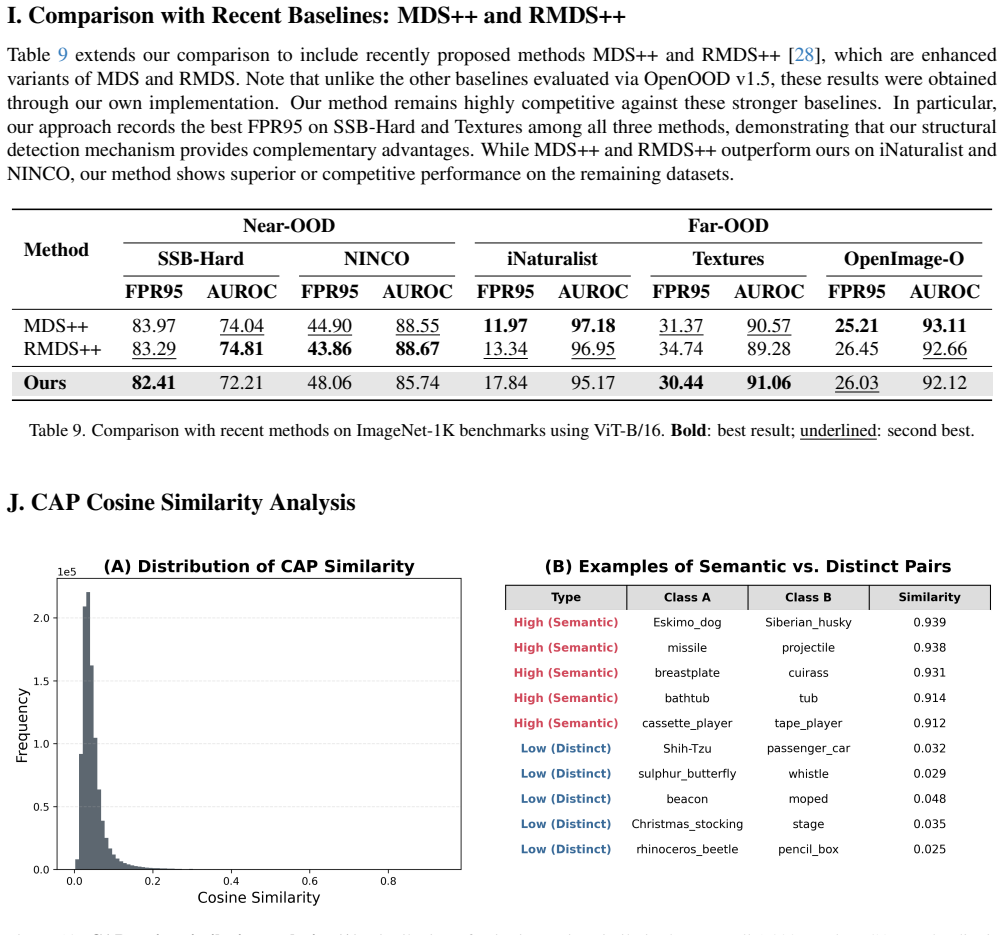
The paper establishes that in-distribution samples preserve stable, class-specific activation patterns inside the latent space produced by a Top-k sparse autoencoder on ViT class tokens, whereas out-of-distribution samples systematically disrupt those patterns; the disruption is measured by a divergence score on core energy profiles and used directly for detection.
What carries the argument
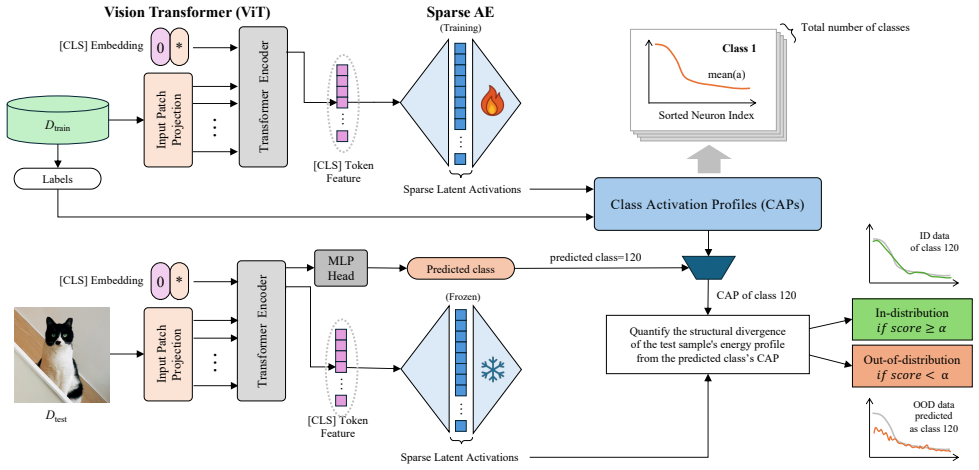
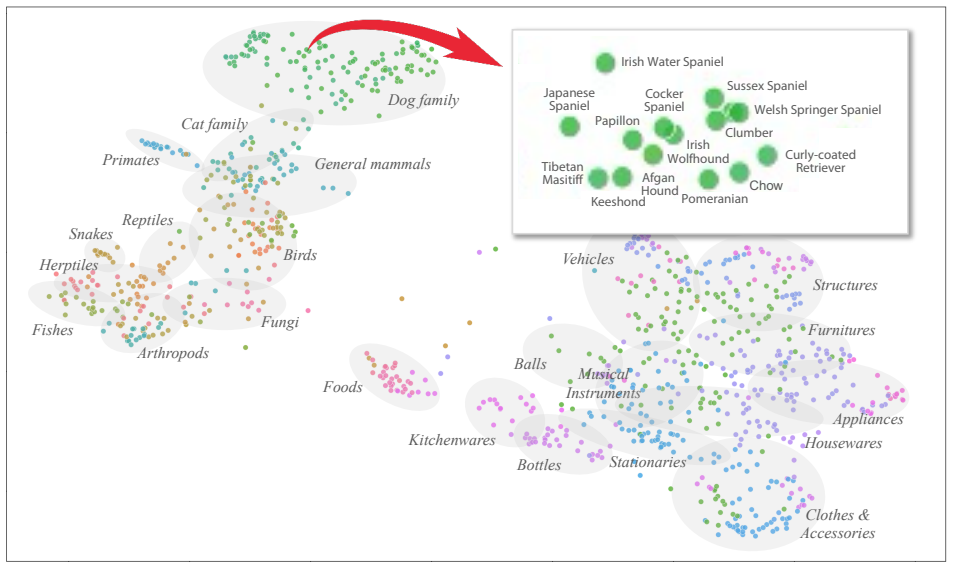
Class Activation Profiles (CAPs) extracted from the sparse latent activations of a Top-k SAE trained on ViT [CLS] tokens; these profiles encode the stable subset of features activated by each in-distribution class.
If this is right
- OOD detection no longer requires operating on entangled dense features and can instead use explicit divergence from learned class activation profiles.
- The same sparse representation supplies an interpretable signal for why a given image is flagged as out-of-distribution.
- Performance on the safety-critical FPR95 metric improves without sacrificing AUROC on standard benchmarks.
- The approach extends the use of sparse autoencoders from language models to vision transformers for a concrete downstream task.
Where Pith is reading between the lines
- If the CAP stability holds across different ViT architectures, the method could be applied to any model that produces a class token without retraining the SAE from scratch.
- The same divergence measure might be tested as an uncertainty signal inside semi-supervised or active-learning loops.
- Examining whether the disrupted features correspond to human-interpretable concepts could link the method to mechanistic interpretability work in vision.
Load-bearing premise
The Top-k SAE trained on ViT class tokens must create a latent space in which class-specific activation patterns remain consistent for in-distribution data and become measurably disrupted for out-of-distribution data rather than reflecting artifacts of the autoencoder itself.
What would settle it
If out-of-distribution samples produce activation patterns inside the same CAPs that match those of in-distribution samples when the SAE is retrained with different k or on a shifted set of images, the detection score would lose its separating power.
Figures



read the original abstract
Sparse Autoencoders (SAEs) have demonstrated significant success in interpreting Large Language Models (LLMs) by decomposing dense representations into sparse, semantic components. However, their potential for analyzing Vision Transformers (ViTs) remains largely under-explored. In this work, we present the first application of SAEs to the ViT [CLS] token for out-of-distribution (OOD) detection, addressing the limitation of existing methods that rely on entangled feature representations. We propose a novel framework utilizing a Top-k SAE to disentangle the dense [CLS] features into a structured latent space. Through this analysis, we reveal that in-distribution (ID) data exhibits consistent, class-specific activation patterns, which we formalize as Class Activation Profiles (CAPs). Our study uncovers a key structural invariant: while ID samples preserve a stable pattern within CAPs, OOD samples systematically disrupt this structure. Leveraging this insight, we introduce a scoring function based on the divergence of core energy profiles to quantify the deviation from ideal activation profiles. Our method achieves strong results on the FPR95 metric, critical for safety-sensitive applications across multiple benchmarks, while also achieving competitive AUROC. Overall, our findings demonstrate that the sparse, disentangled features revealed by SAEs can serve as a powerful, interpretable tool for robust OOD detection in vision models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper applies Top-k Sparse Autoencoders (SAEs) to the [CLS] token of Vision Transformers for out-of-distribution (OOD) detection. It identifies consistent class-specific activation patterns (Class Activation Profiles or CAPs) in in-distribution (ID) data, shows that OOD samples disrupt these patterns, and introduces a divergence-based scoring function on core energy profiles to quantify deviation from ideal profiles, claiming strong FPR95 and competitive AUROC performance.
Significance. If the empirical claims hold and the CAP stability proves robust beyond SAE training artifacts, the work could provide an interpretable, sparsity-driven approach to OOD detection that disentangles features more effectively than standard methods. The application of SAEs to ViT [CLS] tokens is a novel direction with potential for safety-critical vision tasks, but the current lack of shown results limits assessment of its actual contribution.
major comments (3)
- [Abstract] Abstract: the abstract asserts the existence of stable CAPs and a divergence-based scorer but supplies no quantitative validation, ablation on k, baseline comparisons, or error analysis; the central claim therefore rests on an unshown empirical result.
- [Method] Method (scoring function definition): the scoring function is defined as divergence from 'ideal activation profiles' that are presumably estimated from the same ID data used to train or evaluate the detector; this creates a dependence between the reference profiles and the test distribution that the abstract does not resolve.
- [Experiments] Experiments: the central claim requires demonstration that the proposed divergence-of-core-energy-profiles score captures structure beyond what a simple reconstruction-error or activation-norm baseline already detects, and that the observed CAP stability is robust to the choice of k and to alternative sparse coding methods.
minor comments (2)
- [Abstract] Abstract: the term 'core energy profiles' is introduced without a prior definition or reference to its computation, which reduces clarity for readers unfamiliar with the framework.
- [Abstract] Abstract: the claim of 'strong results on the FPR95 metric' is stated without any numerical values or comparison tables, making it difficult to gauge the magnitude of improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our application of Top-k SAEs to ViT [CLS] tokens for OOD detection. We address each major comment below with clarifications from the manuscript and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts the existence of stable CAPs and a divergence-based scorer but supplies no quantitative validation, ablation on k, baseline comparisons, or error analysis; the central claim therefore rests on an unshown empirical result.
Authors: The abstract summarizes the core contributions at a high level, as is conventional. Quantitative validation appears in Section 4, including FPR95 and AUROC results across benchmarks, k ablations in Figure 3 showing CAP stability, baseline comparisons in Table 2, and error analysis via CAP visualizations in Figure 4. We will revise the abstract to include key performance numbers for better alignment with the empirical sections. revision: partial
-
Referee: [Method] Method (scoring function definition): the scoring function is defined as divergence from 'ideal activation profiles' that are presumably estimated from the same ID data used to train or evaluate the detector; this creates a dependence between the reference profiles and the test distribution that the abstract does not resolve.
Authors: The ideal (core energy) profiles are estimated exclusively from the ID training set to capture class-specific invariants, which is standard for establishing a reference distribution in OOD detection (e.g., analogous to training-set statistics in Mahalanobis or energy-based methods). The divergence is then computed on any test sample at inference time. This design is intentional; we will add explicit clarification in the Method section and abstract to distinguish training-time profile estimation from test-time scoring. revision: yes
-
Referee: [Experiments] Experiments: the central claim requires demonstration that the proposed divergence-of-core-energy-profiles score captures structure beyond what a simple reconstruction-error or activation-norm baseline already detects, and that the observed CAP stability is robust to the choice of k and to alternative sparse coding methods.
Authors: Section 4 already reports that the divergence score outperforms reconstruction-error and activation-norm baselines on FPR95 and AUROC. Figure 3 provides k ablations confirming CAP stability across sparsity levels. We focus on Top-k SAEs for their feature-disentangling properties on [CLS] tokens; while we agree that broader comparisons to other sparse coding approaches would strengthen the work, the current results support the claims. We will expand the discussion and add limited comparisons in the revision. revision: partial
Circularity Check
Scoring function defined via divergence from ID-estimated 'ideal' CAPs creates built-in dependence on training distribution
specific steps
-
fitted input called prediction
[Abstract (scoring function paragraph)]
"we introduce a scoring function based on the divergence of core energy profiles to quantify the deviation from ideal activation profiles"
The 'ideal activation profiles' (CAPs) are computed from ID samples on which the SAE was trained; the divergence score for any input is therefore guaranteed to be larger when the input statistics differ from the ID training distribution. No independent validation is shown that the score captures structure beyond the SAE's ID-optimized sparsity constraint.
full rationale
The central OOD score is constructed as a divergence from reference profiles that are themselves derived from the same ID data used to train the Top-k SAE and to define the 'stable pattern'. This matches the fitted-input-called-prediction pattern: the reference is fit on ID statistics, then OOD deviation is reported as a discovery. The abstract and method description do not demonstrate that the observed disruption exceeds what ordinary reconstruction error or activation-norm baselines already produce after ID-only training.
Axiom & Free-Parameter Ledger
free parameters (1)
- k (sparsity level)
axioms (1)
- domain assumption Sparse autoencoders trained on dense representations yield interpretable, disentangled features
invented entities (2)
-
Class Activation Profiles (CAPs)
no independent evidence
-
core energy profiles
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Principal component analysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010
Herv ´e Abdi and Lynne J Williams. Principal component analysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010. 3
2010
-
[2]
Variational autoencoder based anomaly detection using reconstruction probability
Jinwon An and Sungzoon Cho. Variational autoencoder based anomaly detection using reconstruction probability. Special lecture on IE, 2(1):1–18, 2015. 3
2015
-
[3]
Autoencoders, unsupervised learning, and deep architectures
Pierre Baldi. Autoencoders, unsupervised learning, and deep architectures. InProceedings of ICML workshop on unsuper- vised and transfer learning, pages 37–49. JMLR Workshop and Conference Proceedings, 2012. 3
2012
-
[4]
In or out? fixing imagenet out-of-distribution detection eval- uation
Julian Bitterwolf, Maximilian Mueller, and Matthias Hein. In or out? fixing imagenet out-of-distribution detection eval- uation. InICML, 2023. 6
2023
-
[5]
Towards monosemanticity: Decomposing language models with dic- tionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nicholas L Turner, Cem Anil, Carson Denison, Amanda Askell, et al. Towards monosemanticity: Decomposing language models with dic- tionary learning.Transformer Circuits Thread, 2023. 3
2023
-
[6]
Transformer inter- pretability beyond attention visualization
Hila Chefer, Shir Gur, and Lior Wolf. Transformer inter- pretability beyond attention visualization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 782–791, 2021. 1, 3
2021
-
[7]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014. 5, 6
2014
-
[8]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023. 1, 3, 7
work page internal anchor Pith review arXiv 2023
-
[9]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 3, 6
2009
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 1, 3
work page internal anchor Pith review arXiv 2010
-
[11]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield- Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652,
work page internal anchor Pith review arXiv
-
[12]
Ex- ploring the limits of out-of-distribution detection.Advances in neural information processing systems, 34:7068–7081,
Stanislav Fort, Jie Ren, and Balaji Lakshminarayanan. Ex- ploring the limits of out-of-distribution detection.Advances in neural information processing systems, 34:7068–7081,
-
[13]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupr ´e la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. arXiv preprint arXiv:2406.04093, 2024. 2, 3, 7
work page internal anchor Pith review arXiv 2024
-
[14]
Deep anomaly detection us- ing geometric transformations.Advances in neural informa- tion processing systems, 31, 2018
Izhak Golan and Ran El-Yaniv. Deep anomaly detection us- ing geometric transformations.Advances in neural informa- tion processing systems, 31, 2018. 3
2018
-
[15]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
Dan Hendrycks and Kevin Gimpel. A baseline for detect- ing misclassified and out-of-distribution examples in neural networks.arXiv preprint arXiv:1610.02136, 2016. 1, 2
work page internal anchor Pith review arXiv 2016
-
[16]
Deep anomaly detection with outlier exposure.arXiv preprint arXiv:1812.04606, 2018
Dan Hendrycks, Mantas Mazeika, and Thomas Dietterich. Deep anomaly detection with outlier exposure.arXiv preprint arXiv:1812.04606, 2018. 2
-
[17]
Unsolved Problems in ML Safety
Dan Hendrycks, Nicholas Carlini, John Schulman, and Jacob Steinhardt. Unsolved problems in ml safety.arXiv preprint arXiv:2109.13916, 2021. 1, 7
-
[18]
On the impor- tance of gradients for detecting distributional shifts in the wild.Advances in Neural Information Processing Systems, 34:677–689, 2021
Rui Huang, Andrew Geng, and Yixuan Li. On the impor- tance of gradients for detecting distributional shifts in the wild.Advances in Neural Information Processing Systems, 34:677–689, 2021. 2
2021
-
[19]
Independent component analysis: recent advances.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 371 (1984):20110534, 2013
Aapo Hyv ¨arinen. Independent component analysis: recent advances.Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 371 (1984):20110534, 2013. 3
1984
-
[20]
On information and sufficiency.The Annals of Mathematical Statistics, 22 (1):79–86, 1951
Solomon Kullback and Richard A Leibler. On information and sufficiency.The Annals of Mathematical Statistics, 22 (1):79–86, 1951. 6
1951
-
[21]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Ui- jlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.Interna- tional journal of computer vision, 128(7):1956–1981, 2020. 5, 6
1956
-
[22]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks.Advances in neural infor- mation processing systems, 31, 2018
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks.Advances in neural infor- mation processing systems, 31, 2018. 1, 2
2018
-
[23]
Shiyu Liang, Yixuan Li, and Rayadurgam Srikant. Enhanc- ing the reliability of out-of-distribution image detection in neural networks.arXiv preprint arXiv:1706.02690, 2017. 1, 2
-
[24]
Energy-based out-of-distribution detection.Advances in neural information processing systems, 33:21464–21475,
Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li. Energy-based out-of-distribution detection.Advances in neural information processing systems, 33:21464–21475,
-
[25]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 6
2021
-
[26]
Alireza Makhzani and Brendan Frey. K-sparse autoencoders. arXiv preprint arXiv:1312.5663, 2013. 2, 3, 7
-
[27]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimen- sion reduction.arXiv preprint arXiv:1802.03426, 2018. 4
work page internal anchor Pith review arXiv 2018
-
[28]
Maximilian Mueller and Matthias Hein. Mahalanobis++: Improving ood detection via feature normalization.arXiv preprint arXiv:2505.18032, 2025. 8
-
[29]
Sparse autoencoder
Andrew Ng. Sparse autoencoder. CS294A Lecture notes, Stanford University, 2011. 3, 7
2011
-
[30]
Sparse coding with an overcomplete basis set: A strategy employed by v1?Vision research, 37(23):3311–3325, 1997
Bruno A Olshausen and David J Field. Sparse coding with an overcomplete basis set: A strategy employed by v1?Vision research, 37(23):3311–3325, 1997. 1, 3 9
1997
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 6
work page internal anchor Pith review arXiv 2023
-
[32]
Do vision trans- formers see like convolutional neural networks?Advances in neural information processing systems, 34:12116–12128,
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision trans- formers see like convolutional neural networks?Advances in neural information processing systems, 34:12116–12128,
-
[33]
React: Out-of- distribution detection with rectified activations.Advances in neural information processing systems, 34:144–157, 2021
Yiyou Sun, Chuan Guo, and Yixuan Li. React: Out-of- distribution detection with rectified activations.Advances in neural information processing systems, 34:144–157, 2021. 3
2021
-
[34]
Out- of-distribution detection with deep nearest neighbors
Yiyou Sun, Yifei Ming, Xiaojin Zhu, and Yixuan Li. Out- of-distribution detection with deep nearest neighbors. InIn- ternational conference on machine learning, pages 20827– 20840. PMLR, 2022. 1
2022
-
[35]
The inaturalist species classification and de- tection dataset
Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The inaturalist species classification and de- tection dataset. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8769–8778,
-
[36]
Open-set recognition: A good closed-set classifier is all you need
Sagar Vaze, Kai Han, Andrea Vedaldi, and Andrew Zisser- man. Open-set recognition: A good closed-set classifier is all you need. InICLR, 2022. 6
2022
-
[37]
Vim: Out-of-distribution with virtual-logit matching
Haoqi Wang, Zhizhong Li, Litong Feng, and Wayne Zhang. Vim: Out-of-distribution with virtual-logit matching. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4921–4930, 2022. 3
2022
-
[38]
Generalized out-of-distribution detection: A survey.Inter- national Journal of Computer Vision, 132(12):5635–5662,
Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey.Inter- national Journal of Computer Vision, 132(12):5635–5662,
-
[39]
Jingyang Zhang, Jingkang Yang, Pengyun Wang, Haoqi Wang, Yueqian Lin, Haoran Zhang, Yiyou Sun, Xuefeng Du, Yixuan Li, Ziwei Liu, et al. Openood v1. 5: Enhanced benchmark for out-of-distribution detection.arXiv preprint arXiv:2306.09301, 2023. 6 10 Sparsity as a Key: Unlocking New Insights from Latent Structures for Out-of-Distribution Detection Supplement...
-
[40]
120. 130. 140. 150. 160. 170. 180. 190. 20 72.2072.2172.2172.2172.2172.2072.2072.1872.17 85.7085.7085.7285.7485.7685.7785.7785.7785.77 95.1395.1495.1595.1795.1695.1895.1795.1795.17 91.0991.0891.0691.0691.0591.0591.0491.0491.03 92.1592.1392.1392.1292.1192.1192.1092.0892.06 70.00 75.00 80.00 85.00 90.00 95.00
-
[41]
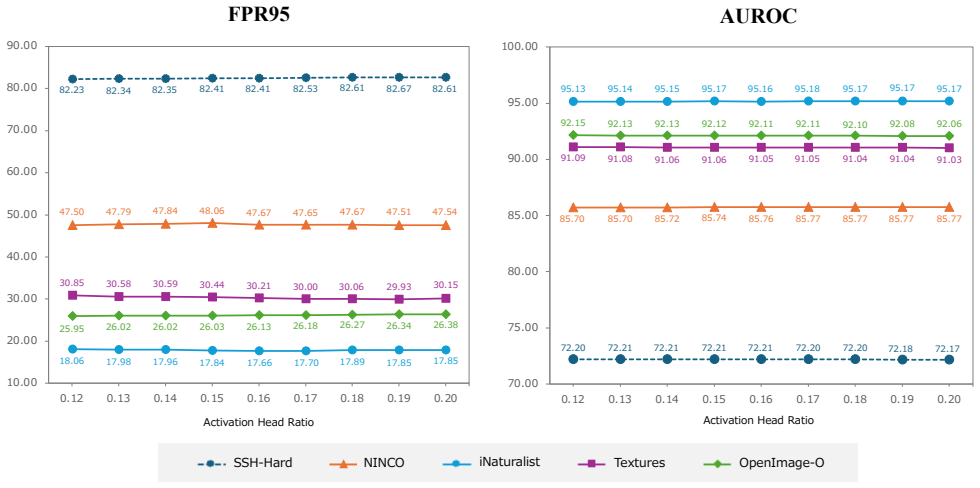
120. 130. 140. 150. 160. 170. 180. 190. 20 ActivationHeadRatio ActivationHeadRatio FPR95 AUROC SSH-Hard NINCO iNaturalistTe x t u r e sOpenImage-O Figure 11.Sensitivity analysis of the activation head ratio (p).Performance metrics, FPR95 (Left) and AUROC (Right), are evaluated across various OOD benchmarks as a function of the activation head ratio (p). T...
-
[42]
The results demonstrate that EPD maintains its effectiveness despite the significant shift in the training domain
The OOD datasets utilized for this analysis were selected from the suggested list for CIFAR-100 in the OpenOOD v 1.5 framework. The results demonstrate that EPD maintains its effectiveness despite the significant shift in the training domain. While some methods, such as KNN and GEN, showing a notable surge in performance on the CIFAR-100 domain compared t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.