Recognition: unknown
Last-Layer-Centric Feature Recombination: Unleashing 3D Geometric Knowledge in DINOv3 for Monocular Depth Estimation
Pith reviewed 2026-05-07 11:30 UTC · model grok-4.3
The pith
DINOv3 encodes 3D geometric knowledge non-uniformly, with deeper layers providing stronger depth signals that a last-layer-centric recombination module exploits for better monocular depth estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
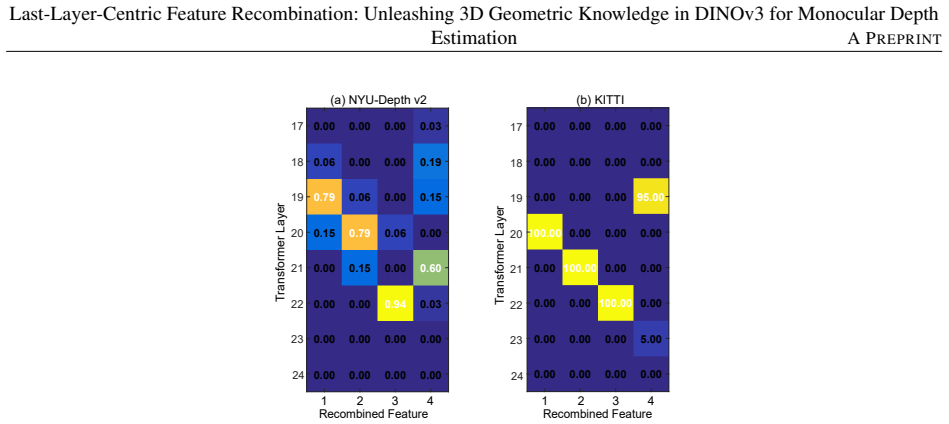
Our systematic analysis reveals that in DINOv3, deeper layers exhibit stronger depth predictability and better capture inter-sample geometric variation. Building on this, we introduce the Last-Layer-Centric Feature Recombination module that treats the final layer as a geometric anchor, adaptively selects complementary intermediate layers according to a minimal-similarity criterion, and fuses the selected features with the last-layer representation via compact linear adapters, resulting in improved monocular depth estimation performance.
What carries the argument
The Last-Layer-Centric Feature Recombination (LFR) module, which anchors on the final DINOv3 layer as a geometric reference, selects complementary intermediate layers by minimal feature similarity, and fuses them to the anchor via compact linear adapters.
If this is right
- The LFR module consistently raises monocular depth estimation accuracy over uniform layer sampling baselines.
- The method reaches state-of-the-art performance on established MDE benchmarks.
- Deeper layers alone or with targeted recombination outperform uniform multi-layer feature construction for geometry tasks.
- Linear adapters enable efficient fusion of geometric cues without requiring full model retraining.
- Vision foundation models organize 3D knowledge hierarchically, so layer selection strategies can replace uniform sampling in dense prediction pipelines.
Where Pith is reading between the lines
- The same last-layer anchoring and minimal-similarity selection could transfer to other dense 3D tasks such as surface normal prediction or multi-view reconstruction.
- If the non-uniform depth cue pattern appears in other vision foundation models, practitioners could apply analogous recombination without retraining each backbone from scratch.
- Pre-computing layer similarities once per model might allow reusable selection masks across multiple downstream datasets and tasks.
- Targeted recombination may reduce the computational cost of adapting large transformers for geometry compared with full fine-tuning or heavy decoder redesign.
Load-bearing premise
The observed non-uniform concentration of 3D cues in deeper layers of DINOv3 is stable across datasets and that selecting by minimal similarity specifically unlocks geometric expressiveness instead of merely adding generic mixing benefits.
What would settle it
If random or uniform selection of intermediate layers produces accuracy gains on standard monocular depth benchmarks comparable to the minimal-similarity selection, the claim that the criterion specifically extracts geometric knowledge would be falsified.
Figures





read the original abstract
Monocular depth estimation (MDE) is a fundamental yet inherently ill-posed task. Recent vision foundation models (VFMs), particularly DINO-based transformers, have significantly improved accuracy and generalization for dense prediction. Prior works generally follow a unified paradigm: sampling a fixed set of intermediate transformer layers at uniform intervals to build multi-scale features. This common practice implicitly assumes that geometric information is uniformly distributed across layers, which may underutilize the structural 3D cues encoded in VFMs. In this study, we present a systematic layer-wise analysis of DINOv3, revealing that 3D information is distributed non-uniformly: deeper layers exhibit stronger depth predictability and better capture inter-sample geometric variation. Motivated by this, we introduce a Last-Layer-Centric Feature Recombination (LFR) module to enhance geometric expressiveness. LFR treats the final layer as a geometric anchor and adaptively selects complementary intermediate layers according to a minimal-similarity criterion. Selected features are fused with the last-layer representation via compact linear adapters.Extensive experiments show that LFR module consistently improves MDE accuracy and achieves state-of-the-art performance. Our analysis sheds light on how geometric knowledge is organized within VFMs and offers an efficient strategy for unlocking their potential in dense 3D tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper performs a layer-wise analysis of DINOv3 revealing non-uniform distribution of 3D geometric cues, with deeper layers showing stronger depth predictability and better capture of inter-sample geometric variation. Motivated by this observation, it introduces the Last-Layer-Centric Feature Recombination (LFR) module that anchors on the final layer, adaptively selects complementary intermediate layers via a minimal-similarity criterion, and fuses them using compact linear adapters. The authors claim that LFR consistently improves monocular depth estimation (MDE) accuracy and reaches state-of-the-art performance.
Significance. If the empirical claims and the specificity of the minimal-similarity mechanism hold, the work would be significant for computer vision by challenging the uniform layer-sampling paradigm common in VFM-based dense prediction and by supplying both a practical recombination strategy and conceptual insight into how geometric knowledge is organized inside transformer layers. It could influence efficient feature utilization in other 3D tasks without requiring full model retraining.
major comments (2)
- [Layer-wise analysis and LFR module description] The central claim that LFR's minimal-similarity selection specifically unlocks geometric expressiveness (rather than generic complementarity from any multi-layer mixing) is load-bearing yet unsupported by the necessary controls. No ablations are described that compare minimal-similarity selection against random selection, maximal-similarity selection, or uniform sampling while holding the number of adapters, fusion method, and total feature count fixed. Without these, the reported accuracy gains cannot be attributed to the proposed geometric insight. (Layer-wise analysis and LFR module description)
- [Abstract] The abstract asserts 'consistent accuracy gains' and 'state-of-the-art performance' but supplies no quantitative numbers, dataset names, baseline comparisons, statistical tests, or ablation tables. This evidentiary gap prevents assessment of effect sizes and reproducibility of the central claim. (Abstract)
minor comments (2)
- [LFR module description] The similarity metric underlying the 'minimal-similarity criterion' (e.g., cosine, Euclidean, or learned) is not explicitly stated, which affects reproducibility of the layer-selection step.
- [Abstract] The abstract would benefit from a single sentence summarizing the magnitude of improvement (e.g., absolute or relative depth error reduction on a standard benchmark) to allow readers to gauge practical impact immediately.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and commit to revisions that strengthen the empirical support and clarity of the manuscript.
read point-by-point responses
-
Referee: The central claim that LFR's minimal-similarity selection specifically unlocks geometric expressiveness (rather than generic complementarity from any multi-layer mixing) is load-bearing yet unsupported by the necessary controls. No ablations are described that compare minimal-similarity selection against random selection, maximal-similarity selection, or uniform sampling while holding the number of adapters, fusion method, and total feature count fixed. Without these, the reported accuracy gains cannot be attributed to the proposed geometric insight. (Layer-wise analysis and LFR module description)
Authors: We agree that additional controlled ablations are required to isolate the contribution of the minimal-similarity criterion. While the layer-wise analysis demonstrates non-uniform 3D geometric knowledge across DINOv3 layers, we acknowledge that the manuscript does not yet include direct comparisons of minimal-similarity selection against random selection, maximal-similarity selection, or uniform sampling under fixed conditions for adapter count, fusion method, and total features. We will conduct these experiments and report the results in the revised version to substantiate the specificity of our design choice. revision: yes
-
Referee: The abstract asserts 'consistent accuracy gains' and 'state-of-the-art performance' but supplies no quantitative numbers, dataset names, baseline comparisons, statistical tests, or ablation tables. This evidentiary gap prevents assessment of effect sizes and reproducibility of the central claim. (Abstract)
Authors: We concur that the abstract should provide concrete quantitative support. The current version summarizes the improvements qualitatively. In the revision we will incorporate specific accuracy metrics, dataset names, and baseline comparisons to allow readers to evaluate effect sizes and reproducibility directly from the abstract. revision: yes
Circularity Check
No circularity in empirical layer analysis or LFR design
full rationale
The paper's chain begins with an empirical layer-wise analysis of DINOv3 features, presented as an observation that 3D information is non-uniformly distributed (deeper layers stronger on depth predictability and inter-sample variation). This observation directly motivates the LFR module, which selects complementary layers via minimal-similarity and fuses via linear adapters. The module is then evaluated experimentally on MDE benchmarks for accuracy gains. No equations or claims reduce by construction to fitted parameters renamed as predictions, no self-definitional loops exist, and no load-bearing self-citations or uniqueness theorems imported from the authors' prior work are invoked. The central claims rest on external experimental validation rather than tautological reduction to the analysis inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 3D geometric information is encoded non-uniformly across layers of DINOv3 and can be accessed via feature recombination
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Agarwal, A., Arora, C.: Attention attention everywhere: Monocular depth prediction with skip attention. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 5861–5870 (2023)
2023
-
[2]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Bhat, S.F., Alhashim, I., Wonka, P.: Adabins: Depth estimation using adaptive bins. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 4009–4018 (2021)
2021
-
[3]
In: European Con- ference on Computer Vision
Bhat, S.F., Alhashim, I., Wonka, P.: Localbins: Improving depth estimation by learning local distributions. In: European Con- ference on Computer Vision. pp. 480–496. Springer (2022)
2022
-
[4]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Bhat, S.F., Birkl, R., Wofk, D., Wonka, P., M ¨uller, M.: Zoedepth: Zero-shot transfer by combining relative and metric depth. arXiv preprint arXiv:2302.12288 (2023)
work page internal anchor Pith review arXiv 2023
-
[5]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y .T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V ., Khedr, H., Huang, A., et al.: Sam 3: Segment anything with concepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review arXiv 2025
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., J ´egou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chang, M.F., Lambert, J., Sangkloy, P., Singh, J., Bak, S., Hartnett, A., Wang, D., Carr, P., Lucey, S., Ramanan, D.: Argoverse: 3d tracking and forecasting with rich maps. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8748–8757 (2019)
2019
-
[8]
In: International Conference on Learning Representations (2020)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S.: An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations (2020)
2020
-
[9]
Advances in neural information processing systems27(2014)
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using a multi-scale deep network. Advances in neural information processing systems27(2014)
2014
-
[10]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Fu, H., Gong, M., Wang, C., Batmanghelich, K., Tao, D.: Deep ordinal regression network for monocular depth estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2002–2011 (2018)
2002
-
[11]
The international journal of robotics research32(11), 1231–1237 (2013)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. The international journal of robotics research32(11), 1231–1237 (2013)
2013
-
[12]
PLoS one13(1), e0189275 (2018)
Gerig, N., Mayo, J., Baur, K., Wittmann, F., Riener, R., Wolf, P.: Missing depth cues in virtual reality limit performance and quality of three dimensional reaching movements. PLoS one13(1), e0189275 (2018)
2018
-
[13]
Huang, T., Zhang, Z., Tang, H.: 3d-r1: Enhancing reasoning in 3d vlms for unified scene understanding. arXiv preprint arXiv:2507.23478 (2025)
-
[14]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ji, Y ., Chen, Z., Xie, E., Hong, L., Liu, X., Liu, Z., Lu, T., Li, Z., Luo, P.: Ddp: Diffusion model for dense visual prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21741–21752 (2023)
2023
-
[15]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y .: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
2023
-
[16]
Lee, J.H., Han, M.K., Ko, D.W., Suh, I.H.: From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv preprint arXiv:1907.10326 (2019)
-
[17]
In: European confer- ence on computer vision
Li, Y ., Mao, H., Girshick, R., He, K.: Exploring plain vision transformer backbones for object detection. In: European confer- ence on computer vision. pp. 280–296. Springer (2022)
2022
-
[18]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Liu, C., Yang, J., Ceylan, D., Yumer, E., Furukawa, Y .: Planenet: Piece-wise planar reconstruction from a single rgb image. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2579–2588 (2018)
2018
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, Z., Hu, H., Lin, Y ., Yao, Z., Xie, Z., Wei, Y ., Ning, J., Cao, Y ., Zhang, Z., Dong, L.: Swin transformer v2: Scaling up capacity and resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12009– 12019 (2022)
2022
-
[20]
In: Proceedings of the IEEE/CVF international conference on computer vision
Long, X., Lin, C., Liu, L., Li, W., Theobalt, C., Yang, R., Wang, W.: Adaptive surface normal constraint for depth estimation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12849–12858 (2021)
2021
-
[21]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review arXiv 2017
-
[22]
Transactions on Machine Learning Research Journal (2024)
Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A.: Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research Journal (2024)
2024
-
[23]
Park, N., Kim, S.: How do vision transformers work? In: 10th International Conference on Learning Representations, ICLR 2022 (2022) 11 Last-Layer-Centric Feature Recombination: Unleashing 3D Geometric Knowledge in DINOv3 for Monocular Depth EstimationA PREPRINT
2022
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Patil, V ., Sakaridis, C., Liniger, A., Van Gool, L.: P3depth: Monocular depth estimation with a piecewise planarity prior. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1610–1621 (2022)
2022
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Patni, S., Agarwal, A., Arora, C.: Ecodepth: Effective conditioning of diffusion models for monocular depth estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28285–28295 (2024)
2024
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Piccinelli, L., Sakaridis, C., Yu, F.: idisc: Internal discretization for monocular depth estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21477–21487 (2023)
2023
-
[27]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Qi, X., Liao, R., Liu, Z., Urtasun, R., Jia, J.: Geonet: Geometric neural network for joint depth and surface normal estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 283–291 (2018)
2018
-
[28]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[29]
IEEE transactions on pattern analysis and machine intelligence44(3), 1623–1637 (2020)
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., Koltun, V .: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE transactions on pattern analysis and machine intelligence44(3), 1623–1637 (2020)
2020
-
[30]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Ranftl, R., Bochkovskiy, A., Koltun, V .: Vision transformers for dense prediction. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 12179–12188 (2021)
2021
-
[31]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V ., Hu, Y .T., Hu, R., Ryali, C., Ma, T., Khedr, H., R¨adle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review arXiv 2024
-
[32]
Ren, Z., Zhang, Z., Li, W., Liu, Q., Tang, H.: Anydepth: Depth estimation made easy. arXiv e-prints p. arXiv: 2601.02760 (2026)
-
[33]
Advances in Neural Information Processing Systems36, 53025–53037 (2023)
Shao, S., Pei, Z., Wu, X., Liu, Z., Chen, W., Li, Z.: Iebins: Iterative elastic bins for monocular depth estimation. Advances in Neural Information Processing Systems36, 53025–53037 (2023)
2023
-
[34]
In: Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7-13, 2012, Proceedings, Part V
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from rgbd images. In: Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7-13, 2012, Proceedings, Part V
2012
-
[35]
pp. 746–760. Springer (2012)
2012
-
[36]
Sim ´eoni, O., V o, H.V ., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V ., Szafraniec, M., Yi, S., Ramamonjisoa, M.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review arXiv 2025
-
[37]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Song, S., Lichtenberg, S.P., Xiao, J.: Sun rgb-d: A rgb-d scene understanding benchmark suite. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 567–576 (2015)
2015
-
[38]
Advances in neural information processing systems37, 84839–84865 (2024)
Tian, K., Jiang, Y ., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scalable image generation via next-scale prediction. Advances in neural information processing systems37, 84839–84865 (2024)
2024
-
[39]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025)
2025
-
[40]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Liu, J., Tang, D., Wang, W., Li, W., Chen, D., Chen, J., Wu, J.: Scalable autoregressive monocular depth estimation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6262–6272 (2025)
2025
-
[41]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, R., Xu, S., Dai, C., Xiang, J., Deng, Y ., Tong, X., Yang, J.: Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5261–5271 (2025)
2025
-
[42]
In: European Conference on Computer Vision
Wang, T., Pang, J., Lin, D.: Monocular 3d object detection with depth from motion. In: European Conference on Computer Vision. pp. 386–403. Springer (2022)
2022
-
[43]
arXiv preprint arXiv:2505.23734 (2025)
Wang, W., Chen, D.Y ., Zhang, Z., Shi, D., Liu, A., Zhuang, B.: Zpressor: Bottleneck-aware compression for scalable feed- forward 3dgs. arXiv preprint arXiv:2505.23734 (2025)
-
[44]
Wang, W., Chen, Y ., Zhang, Z., Liu, H., Wang, H., Feng, Z., Qin, W., Zhu, Z., Chen, D.Y ., Zhuang, B.: V olsplat: Rethinking feed-forward 3d gaussian splatting with voxel-aligned prediction. arXiv preprint arXiv:2509.19297 (2025)
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xie, Z., Geng, Z., Hu, J., Zhang, Z., Hu, H., Cao, Y .: Revealing the dark secrets of masked image modeling. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14475–14485 (2023)
2023
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., Zhao, H.: Depth anything: Unleashing the power of large-scale unlabeled data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10371–10381 (2024)
2024
-
[47]
In: Advances in Neural Information Processing Systems
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. In: Advances in Neural Information Processing Systems. vol. 37, pp. 21875–21911 (2024)
2024
-
[48]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yang, X., Ma, Z., Ji, Z., Ren, Z.: Gedepth: Ground embedding for monocular depth estimation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12719–12727 (2023)
2023
-
[49]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Yang, Y ., Deng, J., Li, W., Duan, L.: Resclip: Residual attention for training-free dense vision-language inference. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 29968–29978 (2025)
2025
-
[50]
Vla-r1: Enhancing reasoning in vision-language-action models.arXiv preprint arXiv:2510.01623,
Ye, A., Zhang, Z., Wang, B., Wang, X., Zhang, D., Zhu, Z.: Vla-r1: Enhancing reasoning in vision-language-action models. arXiv preprint arXiv:2510.01623 (2025) 12 Last-Layer-Centric Feature Recombination: Unleashing 3D Geometric Knowledge in DINOv3 for Monocular Depth EstimationA PREPRINT
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, Z., Zheng, J., Lian, D., Zhou, Z., Gao, S.: Single-image piece-wise planar 3d reconstruction via associative embedding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1029–1037 (2019)
2019
-
[52]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yuan, W., Gu, X., Dai, Z., Zhu, S., Tan, P.: Neural window fully-connected crfs for monocular depth estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3916–3925 (2022)
2022
-
[53]
Advances in Neural Information Processing Systems35, 14128–14139 (2022)
Zhang, C., Yin, W., Wang, B., Yu, G., Fu, B., Shen, C.: Hierarchical normalization for robust monocular depth estimation. Advances in Neural Information Processing Systems35, 14128–14139 (2022)
2022
-
[54]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhao, W., Rao, Y ., Liu, Z., Liu, B., Zhou, J., Lu, J.: Unleashing text-to-image diffusion models for visual perception. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 5729–5739 (2023) 13
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.