Recognition: unknown
A Multistage Extraction Pipeline for Long Scanned Financial Documents: An Empirical Study in Industrial KYC Workflows
Pith reviewed 2026-05-07 13:39 UTC · model grok-4.3
The pith
A multistage pipeline extracts structured data from long scanned financial documents with up to 32 percentage points higher accuracy than direct vision-language model use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
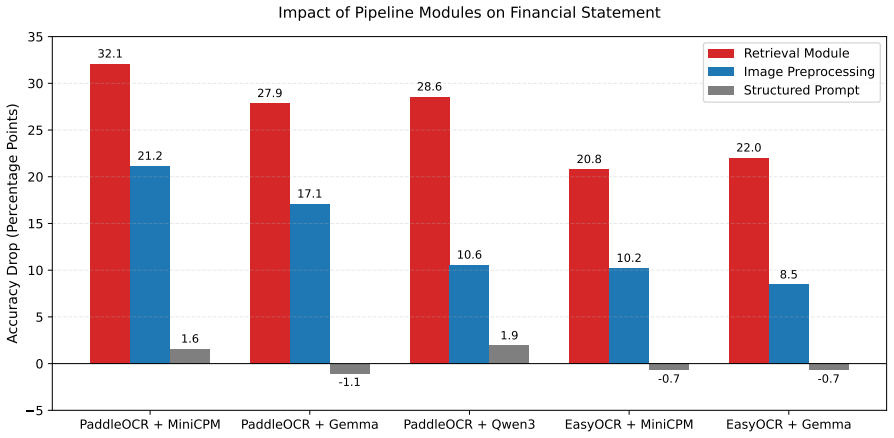
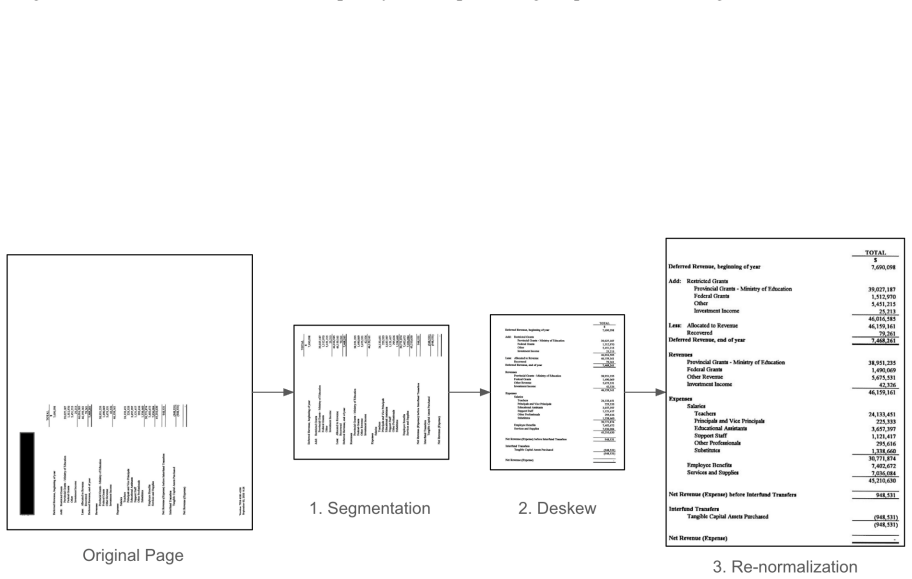
The authors present a multistage extraction framework that combines image preprocessing, multilingual OCR, hybrid page-level retrieval, and compact VLM-based structured extraction. This design separates the task of locating relevant pages from the multimodal reasoning needed to extract structured fields. On a test set of 120 production KYC documents totaling around 3000 pages, the pipeline improves field-level accuracy by as much as 31.9 percentage points over direct PDF-to-VLM baselines, with PaddleOCR paired with MiniCPM2.6 reaching 87.27 percent accuracy. Ablations confirm that the page-level retrieval component drives most of the improvement, especially on complex statements and non-Engl
What carries the argument
The hybrid page-level retrieval step that isolates relevant content before VLM processing, allowing the final extraction stage to operate on shorter and less noisy input.
If this is right
- The pipeline delivers higher accuracy on complex financial statements and non-English documents.
- Page-level retrieval accounts for the largest share of the observed gains rather than the specific choice of OCR engine or VLM.
- Multiple OCR-VLM combinations all show benefit from the multistage design.
- Direct end-to-end application of VLMs to full documents is less reliable for sparse, multipage financial material.
Where Pith is reading between the lines
- The same staged approach could be tested on long documents from legal, medical, or regulatory domains where relevant information is also sparsely distributed.
- If page-retrieval precision improves, the overall field accuracy might rise further without changing the underlying VLM.
- The results imply that retrieval-augmented pipelines may be more practical for industrial deployment than scaling up single-model context windows.
Load-bearing premise
The 120 production KYC documents represent the broader distribution of long scanned financial documents and the retrieval step selects relevant pages without systematic omissions or biases.
What would settle it
Apply both the multistage pipeline and the direct PDF-to-VLM baselines to an independent set of 200 long scanned financial documents drawn from a different sector and check whether the accuracy advantage falls below 10 percentage points.
Figures







read the original abstract
Structured information extraction from long, multilingual scanned financial documents is a core requirement in industrial KYC and compliance workflows. These documents are typically non machine readable, noisy, and visually heterogeneous. They usually span dozens of pages while containing only sparse task relevant information. Although recent vision-language models achieve strong benchmark performance, directly applying them end to end to full financial reports often leads to unreliable extraction under real world conditions. We present a multistage extraction framework that integrates image preprocessing, multilingual OCR, hybrid page-level retrieval, and compact VLM-based structured extraction. The design separates page localization from multimodal reasoning, enabling more accurate extraction from complex multipage documents. We evaluated the framework on 120 production KYC documents comprising about 3000 multilingual scanned pages. Across multiple OCR-VLM combinations, the proposed pipeline consistently outperforms direct PDF-to-VLM baselines, improving field-level accuracy by up to 31.9 percentage points. The best configuration, PaddleOCR with MiniCPM2.6, achieves 87.27 percent accuracy. Ablation studies show that page-level retrieval is the dominant factor in performance improvements, particularly for complex financial statements and non-English documents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a multistage pipeline for structured information extraction from long, multilingual scanned financial documents in industrial KYC workflows. The framework combines image preprocessing, multilingual OCR, hybrid page-level retrieval, and compact VLM-based extraction to separate page localization from multimodal reasoning. Evaluated on 120 proprietary production KYC documents (~3000 pages), the pipeline outperforms direct PDF-to-VLM baselines across OCR-VLM combinations, with gains up to 31.9 percentage points in field-level accuracy; the best configuration (PaddleOCR + MiniCPM2.6) reaches 87.27%. Ablation studies attribute the largest improvements to the page-level retrieval step, especially for complex financial statements and non-English documents.
Significance. If the evaluation protocol and retrieval metrics can be strengthened, the work offers practical value for compliance and document-processing applications by showing that hybrid retrieval-plus-VLM designs can substantially improve reliability on noisy, long-form scanned financial reports compared to end-to-end VLM application. The use of real production data and multiple OCR-VLM ablations is a positive empirical contribution, though the proprietary nature of the test set limits external validation.
major comments (4)
- [§4, §4.2] §4 (Experiments) and §4.2 (Evaluation Protocol): Field-level accuracy is reported as the primary metric, yet the manuscript provides no description of how ground-truth labels were created, what constitutes a correct field extraction (exact match vs. normalized value), or inter-annotator agreement statistics. These omissions make it impossible to assess whether the reported 31.9 pp gains are robust or sensitive to annotation choices.
- [§4.3, §3.3] §4.3 (Ablations) and §3.3 (Hybrid Retrieval): The claim that page-level retrieval is the dominant factor is central to the architectural argument, but no quantitative retrieval metrics (page-level precision, recall, or F1) or error analysis on missed relevant pages are supplied. Without these, it is unclear whether the observed gains reflect genuine isolation of relevant content or selection bias in the 120-document set.
- [§4.1] §4.1 (Dataset): The 120 production KYC documents are described only at a high level (multilingual, ~3000 pages). No breakdown by document type, language distribution, average page count, or selection criteria is given, leaving the representativeness assumption untested and raising the possibility that reported improvements are inflated by favorable document structure.
- [§4] §4 (Results): Improvements are presented as point estimates without per-document variance, confidence intervals, or statistical significance tests. This weakens the cross-configuration claim that the pipeline “consistently outperforms” baselines, as the magnitude of gains (e.g., 31.9 pp) cannot be distinguished from sampling variability.
minor comments (2)
- [Abstract, §4.1] The abstract states “about 3000 pages”; the exact total page count and any filtering criteria should be stated precisely in §4.1.
- [Figures] Figure captions and axis labels in the ablation plots (presumably Figure 3 or 4) should explicitly indicate which OCR-VLM pair is shown and what the baseline condition is.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We agree that additional details on the evaluation protocol, retrieval metrics, dataset characteristics, and statistical analysis will strengthen the work. We address each major comment below and will incorporate revisions in the next version.
read point-by-point responses
-
Referee: [§4, §4.2] §4 (Experiments) and §4.2 (Evaluation Protocol): Field-level accuracy is reported as the primary metric, yet the manuscript provides no description of how ground-truth labels were created, what constitutes a correct field extraction (exact match vs. normalized value), or inter-annotator agreement statistics. These omissions make it impossible to assess whether the reported 31.9 pp gains are robust or sensitive to annotation choices.
Authors: We agree that explicit documentation of the annotation process is necessary to evaluate robustness. In the revised §4.2 we will add: ground-truth labels were produced by two KYC compliance experts following a written guideline; a field extraction is scored correct under normalized exact match (dates and amounts normalized for format and punctuation, names and IDs under case-insensitive exact match); and inter-annotator agreement on a 20-document subset reached Cohen’s κ = 0.91. These additions will show that the reported gains are stable under the chosen matching rules. revision: yes
-
Referee: [§4.3, §3.3] §4.3 (Ablations) and §3.3 (Hybrid Retrieval): The claim that page-level retrieval is the dominant factor is central to the architectural argument, but no quantitative retrieval metrics (page-level precision, recall, or F1) or error analysis on missed relevant pages are supplied. Without these, it is unclear whether the observed gains reflect genuine isolation of relevant content or selection bias in the 120-document set.
Authors: We accept that quantitative retrieval metrics are required to substantiate the ablation claims. The revised §4.3 will include a table of page-level precision, recall, and F1 for the hybrid retriever on the full test set, plus a brief error analysis of missed pages and their downstream effect on field accuracy. These numbers will demonstrate that the largest accuracy lifts coincide with high-recall retrieval rather than dataset-specific bias. revision: yes
-
Referee: [§4.1] §4.1 (Dataset): The 120 production KYC documents are described only at a high level (multilingual, ~3000 pages). No breakdown by document type, language distribution, average page count, or selection criteria is given, leaving the representativeness assumption untested and raising the possibility that reported improvements are inflated by favorable document structure.
Authors: We agree that finer-grained dataset statistics improve interpretability. The revision will add to §4.1: mean pages per document (25.3), language distribution (English 45 %, Chinese 30 %, Spanish 15 %, other 10 %), document-type breakdown (financial statements 40 %, identity documents 35 %, contracts 25 %), and selection criteria (random draw from the production KYC queue over a three-month window, documents with <5 pages excluded). Because the corpus is proprietary, exact client identifiers and full selection logs cannot be released; the added high-level statistics nevertheless allow readers to assess representativeness. revision: partial
-
Referee: [§4] §4 (Results): Improvements are presented as point estimates without per-document variance, confidence intervals, or statistical significance tests. This weakens the cross-configuration claim that the pipeline “consistently outperforms” baselines, as the magnitude of gains (e.g., 31.9 pp) cannot be distinguished from sampling variability.
Authors: We concur that point estimates alone are insufficient. In the revised §4 we will report per-document accuracy standard deviation, 95 % bootstrap confidence intervals (1 000 resamples), and paired statistical tests (Wilcoxon signed-rank) between each pipeline configuration and its direct-VLM baseline. These additions will confirm that the observed gains, including the 31.9 pp maximum, are statistically significant (p < 0.01). revision: yes
Circularity Check
No circularity: empirical pipeline evaluated on independent production data
full rationale
The paper describes a multistage extraction framework evaluated directly on 120 production KYC documents (~3000 pages) with explicit comparisons to PDF-to-VLM baselines and ablations attributing gains to page-level retrieval. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the abstract or described claims. Performance figures (e.g., 87.27% accuracy, up to 31.9 pp gains) are reported as outcomes of empirical measurement on held-out production data rather than being defined by or reduced to the method's own inputs. The evaluation chain is therefore self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shaheera Saba Mohd Naseem Akhter and Priti P Rege
Enhancing large vision-language models with layout modality for table question answering on japanese annual securities reports.arXiv preprint arXiv:2505.17625. Shaheera Saba Mohd Naseem Akhter and Priti P Rege
-
[2]
Improving skew detection and correction in different document images using a deep learning ap- proach. In2020 11th International Conference on Computing, Communication and Networking Tech- nologies (ICCCNT), pages 1–6, Online. IEEE, IEEE. Zahra Anvari and Vassilis Athitsos. 2021. A survey on deep learning based document image enhancement. arXiv preprint a...
-
[3]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Ethan Bradley, Muhammad Roman, Karen Rafferty, and Barry Devereux. 2026. Synfintabs: A dataset of synthetic financial tables for information and ta- ble extraction. InDocument Analysis and Recogni- tion – ICDAR 2025 Workshops, pages 85–100, Cham, Switzerland. Springer Nature. Kai Chen, Mathias Seu...
work page internal anchor Pith review arXiv 2026
-
[4]
PaddleOCR 3.0 Technical Report
Paddleocr 3.0 technical report.arXiv preprint arXiv:2507.05595. Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Om- rani, Gautier Viaud, CELINE HUDELOT, and Pierre Colombo. 2025. Colpali: Efficient document re- trieval with vision language models. InThe Thir- teenth International Conference on Learning Repre- sentations (ICLR) 2025. Dianyuan Han. 2013. Comp...
work page internal anchor Pith review arXiv 2025
-
[5]
InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 5817–5834, Vienna, Austria
mplug-docowl2: High-resolution compressing for OCR-free multi-page document understanding. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 5817–5834, Vienna, Austria. Association for Computational Linguistics. Li Im Tan, Wai San Phang, Kim On Chin, and Anthony Patricia. 2015. Rule-b...
2015
-
[6]
InProceedings of the 5th ACM International Confer- ence on AI in Finance, pages 266–273
Finqapt: Empowering financial decisions with end-to-end llm-driven question answering pipeline. InProceedings of the 5th ACM International Confer- ence on AI in Finance, pages 266–273. Ray Smith. 2007. An overview of the tesseract ocr en- gine. InNinth international conference on document analysis and recognition (ICDAR 2007), volume 2, pages 629–633. IEE...
-
[7]
Layoutlmv2: Multi-modal pre-training for visually-rich document understanding. InProceed- ings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Interna- tional Joint Conference on Natural Language Pro- cessing (V olume 1: Long Papers), pages 2579–2591. Association for Computational Linguistics. Yuan Yao, Tianyu Yu, ...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.