Recognition: unknown
Featurising Pixels from Dynamic 3D Scenes with Linear In-Context Learners
Pith reviewed 2026-05-07 13:34 UTC · model grok-4.3
The pith
Linear in-context learning on noisy depth and motion cues from uncurated videos produces pixel descriptors that embed semantic and geometric properties consistently over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
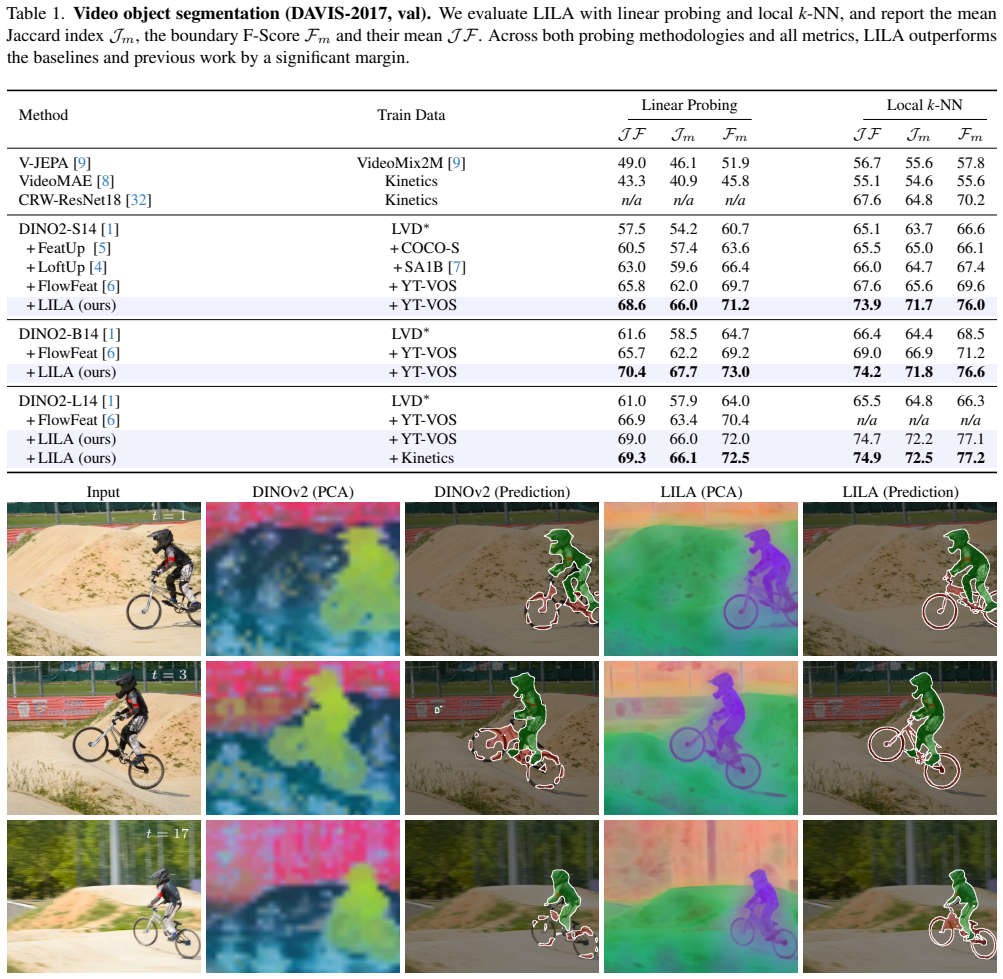
We present a framework that learns pixel-accurate feature descriptors from videos, LILA. The core element of our training framework is linear in-context learning. LILA leverages spatio-temporal cue maps -- depth and motion -- estimated with off-the-shelf networks. Despite the noisy nature of those cues, LILA trains effectively on uncurated video datasets, embedding semantic and geometric properties in a temporally consistent manner.
What carries the argument
Linear in-context learning applied to noisy spatio-temporal cue maps, which embeds semantic and geometric properties into temporally consistent pixel-level feature descriptors.
If this is right
- The descriptors directly improve accuracy on video object segmentation by supplying frame-to-frame consistent pixel labels.
- Surface normal estimation benefits from the geometric structure encoded in the same features.
- Semantic segmentation on dynamic scenes gains from the temporal consistency without requiring additional video-specific training.
- The same training procedure scales to dense prediction tasks that current action-level video models cannot address.
Where Pith is reading between the lines
- The reliance on off-the-shelf cues suggests that similar linear learners could bootstrap representations for other modalities once basic estimators exist.
- Temporally consistent pixel features could support downstream 3D reconstruction pipelines that currently require explicit multi-view geometry.
- If the linear mechanism generalizes, it may reduce the need for large-scale supervised video annotation in favor of cue-driven self-supervision.
Load-bearing premise
Noisy spatio-temporal cues estimated by off-the-shelf networks are sufficient for the linear in-context learner to embed semantic and geometric properties in a temporally consistent manner on uncurated video data.
What would settle it
A controlled test on held-out uncurated video where the learned pixel features exhibit no measurable gain in temporal consistency or task accuracy on video object segmentation compared with standard image-pretrained descriptors.
Figures






read the original abstract
One of the most exciting applications of vision models involve pixel-level reasoning. Despite the abundance of vision foundation models, we still lack representations that effectively embed spatio-temporal properties of visual scenes at the pixel level. Existing frameworks either train on image-based pretext tasks, which do not account for dynamic elements, or on video sequences for action-level reasoning, which does not scale to dense pixel-level prediction. We present a framework that learns pixel-accurate feature descriptors from videos, LILA. The core element of our training framework is linear in-context learning. LILA leverages spatio-temporal cue maps -- depth and motion -- estimated with off-the-shelf networks. Despite the noisy nature of those cues, LILA trains effectively on uncurated video datasets, embedding semantic and geometric properties in a temporally consistent manner. We demonstrate compelling empirical benefits of the learned representation across a diverse suite of vision tasks: video object segmentation, surface normal estimation and semantic segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LILA, a framework for learning pixel-accurate feature descriptors from dynamic 3D scenes in videos. The core mechanism is linear in-context learning that ingests noisy spatio-temporal cue maps (depth and motion) produced by off-the-shelf networks; training occurs on uncurated video data and is claimed to embed semantic and geometric properties in a temporally consistent manner. The learned representations are evaluated on video object segmentation, surface normal estimation, and semantic segmentation.
Significance. If the empirical claims hold, the approach would supply a scalable route to dense, temporally coherent pixel representations from large-scale uncurated video without requiring curated labels or action-level supervision. The explicit use of linear in-context learners to tolerate noisy external cues is a distinctive technical choice that could influence future video representation learning.
Simulated Author's Rebuttal
We thank the referee for their positive summary of LILA and the recommendation for minor revision. The review accurately captures the core contribution: using linear in-context learning on off-the-shelf depth and motion cues to obtain temporally consistent pixel features from uncurated video. We have no major comments to address, as none were raised.
Circularity Check
No significant circularity detected
full rationale
The paper's central framework LILA learns pixel features via linear in-context learning applied to external depth and motion cue maps produced by off-the-shelf networks, then trains on uncurated video data. No derivation step reduces to a self-definition, a fitted input renamed as prediction, or a load-bearing self-citation chain; the method is explicitly positioned as using noisy external cues rather than its own outputs, and empirical benefits are demonstrated on separate downstream tasks (video object segmentation, surface normal estimation, semantic segmentation) without the core claim collapsing into its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Off-the-shelf networks produce usable (though noisy) depth and motion cues that can supervise pixel feature learning
invented entities (1)
-
LILA training framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth \' e e Darcet, Th \' e o Moutakanni, and Huy Vo et al. DINO v2: Learning robust visual features without supervision. arXiv:2304.07193 [cs.CV], 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv \' e J \' e gou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In ICCV, 2021
2021
-
[4]
Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julien ...
work page internal anchor Pith review arXiv 2025
-
[5]
LoftUp : Learning a coordinate-based feature upsampler for vision foundation models
Haiwen Huang, Anpei Chen, Volodymyr Havrylov, Andreas Geiger, and Dan Zhang. LoftUp : Learning a coordinate-based feature upsampler for vision foundation models. In ICCV, 2025
2025
-
[6]
Brandt, Axel Feldman, Zhoutong Zhang, and William T
Stephanie Fu, Mark Hamilton, Laura E. Brandt, Axel Feldman, Zhoutong Zhang, and William T. Freeman. FeatUp : A model-agnostic framework for features at any resolution. In ICLR, 2024
2024
-
[7]
FlowFeat : Pixel-dense embedding of motion profiles
Nikita Araslanov, Anna Sonnenweber, and Daniel Cremers. FlowFeat : Pixel-dense embedding of motion profiles. In NeurIPS, 2025
2025
-
[8]
Berg, Wan - Yen Lo, Piotr Doll \' a r, and Ross B
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chlo \' e Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan - Yen Lo, Piotr Doll \' a r, and Ross B. Girshick. Segment anything. In ICCV, pages 3992--4003, 2023
2023
-
[9]
Video MAE : Masked autoencoders are data-efficient learners for self-supervised video pre-training
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Video MAE : Masked autoencoders are data-efficient learners for self-supervised video pre-training. In NeurIPS, 2022
2022
-
[10]
Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael G. Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video. TMLR, 2024
2024
-
[11]
Girshick
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll \' a r, and Ross B. Girshick. Masked autoencoders are scalable vision learners. In CVPR, pages 15979--15988, 2022
2022
-
[12]
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models
Michael Gutmann and Aapo Hyv \" a rinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In AISTATS, volume 9, pages 297--304, 2010
2010
-
[13]
Representation Learning with Contrastive Predictive Coding
A \" a ron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv:1807.03748 [cs.LG], 2018
work page internal anchor Pith review arXiv 2018
-
[14]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. A simple framework for contrastive learning of visual representations. In ICML, volume 119 of Proceedings of Machine Learning Research, pages 1597--1607, 2020
2020
-
[15]
An empirical study of training self-supervised vision transformers
Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self-supervised vision transformers. In ICCV, pages 9620--9629, 2021
2021
-
[16]
Exploring simple siamese representation learning
Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In CVPR, pages 15750--15758, 2021
2021
-
[17]
Richemond, Elena Buchatskaya, Carl Doersch, Bernardo \' A vila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, R \' e mi Munos, and Michal Valko
Jean - Bastien Grill, Florian Strub, Florent Altch \' e , Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo \' A vila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, R \' e mi Munos, and Michal Valko. Bootstrap your own latent - A new approach to self-supervised learning. In NeurIPS, 2020
2020
-
[18]
Rabbat, Yann LeCun, and Nicolas Ballas
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael G. Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In CVPR, pages 15619--15629, 2023
2023
-
[19]
BEiT : BERT pre-training of image transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BEiT : BERT pre-training of image transformers. In ICLR, 2022
2022
-
[20]
Yuille, and Tao Kong
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan L. Yuille, and Tao Kong. Image BERT pre-training with online tokenizer. In ICLR, 2022
2022
-
[21]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, volume 139, pages 8748--8763, 2021
2021
-
[22]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In ICCV, pages 11941--11952, 2023
2023
-
[23]
Michael Tschannen, Alexey A. Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier J. H \' e naff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. SigLIP 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense f...
work page internal anchor Pith review arXiv 2025
-
[24]
AM-RADIO : Agglomerative vision foundation model reduce all domains into one
Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. AM-RADIO : Agglomerative vision foundation model reduce all domains into one. In CVPR, pages 12490--12500, 2024
2024
-
[25]
Pinheiro, Amjad Almahairi, Ryan Y
Pedro O. Pinheiro, Amjad Almahairi, Ryan Y. Benmalek, Florian Golemo, and Aaron C. Courville. Unsupervised learning of dense visual representations. In NeurIPS, 2020
2020
-
[26]
H \' e naff, Skanda Koppula, Evan Shelhamer, Daniel Zoran, Andrew Jaegle, Andrew Zisserman, Jo \ a o Carreira, and Relja Arandjelovic
Olivier J. H \' e naff, Skanda Koppula, Evan Shelhamer, Daniel Zoran, Andrew Jaegle, Andrew Zisserman, Jo \ a o Carreira, and Relja Arandjelovic. Object discovery and representation networks. In ECCV, volume 13687, pages 123--143, 2022
2022
-
[27]
CrIBo : Self-supervised learning via cross-image object-level bootstrapping
Tim Lebailly, Thomas Stegm \" u ller, Behzad Bozorgtabar, Jean - Philippe Thiran, and Tinne Tuytelaars. CrIBo : Self-supervised learning via cross-image object-level bootstrapping. In ICLR, 2024
2024
-
[28]
Unsupervised learning of visual representations by solving jigsaw puzzles
Mehdi Noroozi and Paolo Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles. In ECCV, volume 9910, pages 69--84, 2016
2016
-
[29]
Location-aware self-supervised transformers for semantic segmentation
Mathilde Caron, Neil Houlsby, and Cordelia Schmid. Location-aware self-supervised transformers for semantic segmentation. In WACV, pages 116--126, 2024
2024
-
[30]
Richard Zhang, Phillip Isola, and Alexei A. Efros. Colorful image colorization. In ECCV, volume 9907, pages 649--666, 2016
2016
-
[31]
Colorization as a proxy task for visual understanding
Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Colorization as a proxy task for visual understanding. In CVPR, pages 840--849, 2017
2017
-
[32]
CroCo : Self-supervised pre-training for 3D vision tasks by cross-view completion
Philippe Weinzaepfel, Vincent Leroy, Thomas Lucas, Romain Br \' e gier, Yohann Cabon, Vaibhav Arora, Leonid Antsfeld, Boris Chidlovskii, Gabriela Csurka, and J \' e r \^ o me Revaud. CroCo : Self-supervised pre-training for 3D vision tasks by cross-view completion. In NeurIPS, 2022
2022
-
[33]
Allan Jabri, Andrew Owens, and Alexei A. Efros. Space-time correspondence as a contrastive random walk. In Hugo Larochelle, Marc'Aurelio Ranzato, Raia Hadsell, Maria - Florina Balcan, and Hsuan - Tien Lin, editors, NeurIPS, 2020
2020
-
[34]
Dense unsupervised learning for video segmentation
Nikita Araslanov, Simone Schaub - Meyer, and Stefan Roth. Dense unsupervised learning for video segmentation. In NeurIPS, pages 25308--25319, 2021
2021
-
[35]
Nikhil Parthasarathy, S. M. Ali Eslami, Jo \ a o Carreira, and Olivier J. H \' e naff. Self-supervised video pretraining yields robust and more human-aligned visual representations. In NeurIPS, 2023
2023
-
[36]
Self-supervised representation learning from flow equivariance
Yuwen Xiong, Mengye Ren, Wenyuan Zeng, and Raquel Urtasun. Self-supervised representation learning from flow equivariance. In ICCV, pages 10171--10180, 2021
2021
-
[37]
Wang, Christopher Hoang, Yuwen Xiong, Yann LeCun, and Mengye Ren
Alex N. Wang, Christopher Hoang, Yuwen Xiong, Yann LeCun, and Mengye Ren. PooDLe : Pooled and dense self-supervised learning from naturalistic videos. In ICLR, 2025
2025
-
[38]
Asano, and Yannis Avrithis
Shashanka Venkataramanan, Mamshad Nayeem Rizve, Jo \ a o Carreira, Yuki M. Asano, and Yannis Avrithis. Is ImageNet worth 1 video? L earning strong image encoders from 1 long unlabelled video. In ICLR, 2024
2024
-
[39]
Elsayed, Aravindh Mahendran, Sjoerd van Steenkiste, Klaus Greff, Michael C
Gamaleldin F. Elsayed, Aravindh Mahendran, Sjoerd van Steenkiste, Klaus Greff, Michael C. Mozer, and Thomas Kipf. SAVi++ : Towards end-to-end object-centric learning from real-world videos. In NeurIPS, 2022
2022
-
[40]
Zoedepth: Zero-shot transfer by combining relative and metric depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias M \" u ller. ZoeDepth : Zero-shot transfer by combining relative and metric depth. arXiv:2302.12288 [cs.CV], 2023
-
[41]
Vision transformers for dense prediction
Ren \' e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. In ICCV, pages 12159--12168, 2021
2021
-
[42]
Single-stage semantic segmentation from image labels
Nikita Araslanov and Stefan Roth. Single-stage semantic segmentation from image labels. In CVPR, pages 4252--4261, 2020
2020
-
[43]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2019
2019
- [44]
-
[45]
The Kinetics Human Action Video Dataset
Will Kay, Jo \ a o Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. The Kinetics human action video dataset. arXiv:1705.06950 [cs.CV], 2017
work page internal anchor Pith review arXiv 2017
-
[46]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbel\'aez, Alexander Sorkine-Hornung, and Luc Van Gool . The 2017 DAVIS challenge on video object segmentation. arXiv:1704.00675 [cs.CV], 2017
work page internal anchor Pith review arXiv 2017
-
[47]
Holger Caesar, Jasper R. R. Uijlings, and Vittorio Ferrari. COCO-Stuff : Thing and stuff classes in context. In CVPR, pages 1209--1218, 2018
2018
-
[48]
Indoor segmentation and support inference from RGBD images
Pushmeet Kohli Nathan Silberman, Derek Hoiem and Rob Fergus. Indoor segmentation and support inference from RGBD images. In ECCV, pages 746--760, 2012
2012
-
[49]
Guibas, Justin Johnson, and Varun Jampani
Mohamed El Banani, Amit Raj, Kevis - Kokitsi Maninis, Abhishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun, Leonidas J. Guibas, Justin Johnson, and Varun Jampani. Probing the 3D awareness of visual foundation models. In CVPR, pages 21795--21806, 2024
2024
-
[50]
Scene parsing through ADE20K dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ADE20K dataset. In CVPR, pages 5122--5130, 2017
2017
-
[51]
SEA-RAFT : Simple, efficient, accurate RAFT for optical flow
Yihan Wang, Lahav Lipson, and Jia Deng. SEA-RAFT : Simple, efficient, accurate RAFT for optical flow. In ECCV, pages 36--54, 2024
2024
-
[52]
Depth anything V2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything V2 . In NeurIPS, 2024
2024
-
[53]
Vision transformers need registers
Timoth \' e e Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. In ICLR, 2024
2024
-
[54]
Semantic projection network for zero- and few-label semantic segmentation
Yongqin Xian, Subhabrata Choudhury, Yang He, Bernt Schiele, and Zeynep Akata. Semantic projection network for zero- and few-label semantic segmentation. In CVPR, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.