Recognition: unknown
GIFGuard: Proactive Forensics against Deepfakes in Facial GIFs via Spatiotemporal Watermarking
Pith reviewed 2026-05-07 11:50 UTC · model grok-4.3
The pith
GIFGuard embeds watermarks in facial GIFs using 3D convolutions that remain detectable even after deepfake alterations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GIFGuard is the first spatiotemporal watermarking framework tailored for proactive forensics against deepfakes in facial GIFs. It uses the Spatiotemporal Adaptive Residual Encoder (STARE) with a 3D convolutional backbone and adaptive channel recalibration to embed watermarks that capture globally coherent temporal dependencies, and the Deep Integrity Restoration Decoder (DIRD) with a spatiotemporal hourglass architecture and 3D attention to restore latent features for accurate watermark extraction even under severe facial manipulation. The authors also construct the GIFfaces benchmark dataset to enable systematic research in this area, with results indicating high visual fidelity and strong
What carries the argument
The Spatiotemporal Adaptive Residual Encoder (STARE) with 3D convolutions and adaptive channel recalibration for embedding, paired with the Deep Integrity Restoration Decoder (DIRD) using a spatiotemporal hourglass and 3D attention for extraction under manipulation.
If this is right
- Watermarked GIFs can be checked for authenticity after potential deepfake processing on social networks.
- The method supports proactive defense by adding verifiable signals before any tampering occurs.
- A new benchmark dataset of facial GIFs enables direct comparison of future temporal forensics techniques.
- Original GIF visual quality stays high while the added watermark provides tamper evidence.
- Robustness holds across multiple deepfake techniques that target facial content and expressions.
Where Pith is reading between the lines
- The same spatiotemporal embedding strategy could extend to other short-form video formats beyond GIFs.
- Widespread use might encourage platforms to require watermark checks on user-uploaded animated clips.
- Further tests on non-facial content would clarify how much the approach depends on facial structure.
- Pairing the watermark with existing verification systems could create layered checks for animated media.
Load-bearing premise
That 3D convolutional networks with adaptive recalibration and attention-based restoration can reliably recover the embedded watermark signal after deepfake models have made major semantic changes to facial features and motion in the GIF.
What would settle it
A test set of watermarked facial GIFs that are then altered by standard deepfake tools, where the decoder either fails to extract any signal or extracts one that does not match the original embedded pattern.
Figures


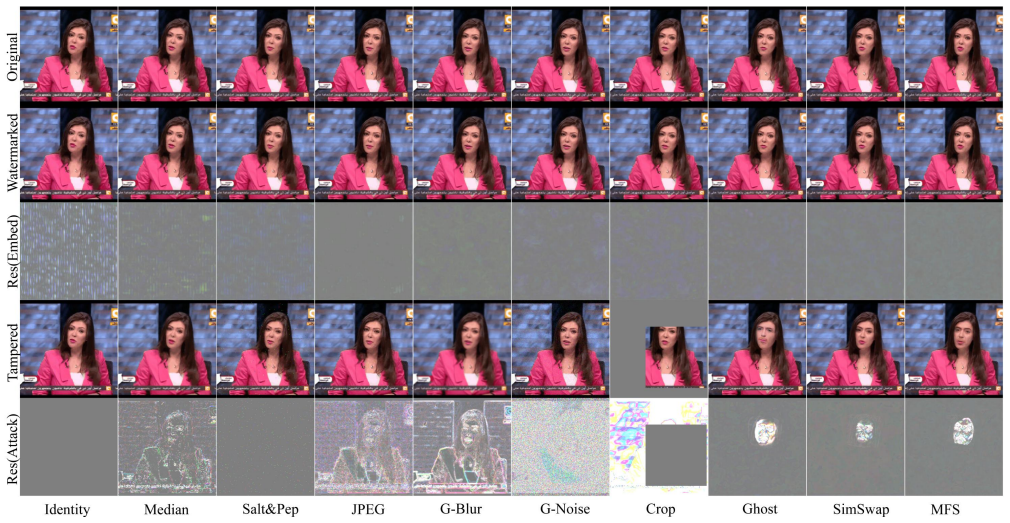
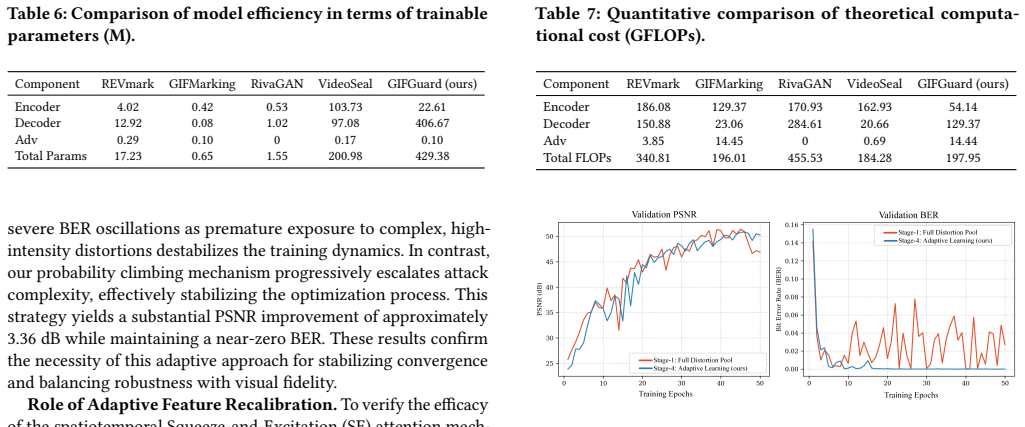
read the original abstract
The rapid evolution of deepfake technology poses an unprecedented threat to the authenticity of Graphics Interchange Format (GIF) imagery, which serves as a representative of short-loop temporal media in social networks. However, existing proactive forensics works are designed for static images, which limits their applicability to animated GIFs. To bridge this gap, we propose GIFGuard, the first spatiotemporal watermarking framework tailored for deepfake proactive forensics in GIFs. In the embedding stage, we propose the Spatiotemporal Adaptive Residual Encoder (STARE) to ensure robustness against high-level semantic tampering. It employs a 3D convolutional backbone with adaptive channel recalibration to capture globally coherent temporal dependencies. In the extraction stage, we design the Deep Integrity Restoration Decoder (DIRD). It utilizes a spatiotemporal hourglass architecture equipped with 3D attention to restore latent features, allowing for the accurate extraction of watermark signals even under severe facial manipulation. Furthermore, we construct GIFfaces, the first large-scale benchmark dataset curated for GIF proactive forensics to facilitate research in this domain. Extensive results show that GIFGuard achieves high-fidelity visual quality and remarkable robustness performance against deepfakes. Related code and dataset will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GIFGuard, the first spatiotemporal watermarking framework for proactive deepfake forensics on facial GIFs. It proposes the Spatiotemporal Adaptive Residual Encoder (STARE) that uses a 3D convolutional backbone with adaptive channel recalibration to embed watermarks while capturing temporal dependencies, and the Deep Integrity Restoration Decoder (DIRD) that employs a spatiotemporal hourglass architecture with 3D attention to restore features and extract watermarks under manipulation. The authors also release the GIFfaces benchmark dataset and report high visual quality plus remarkable robustness against deepfakes.
Significance. If the robustness claims hold under rigorous evaluation, the work would be a meaningful contribution by addressing the gap in proactive forensics for short-loop temporal media such as GIFs, which are common on social platforms. The release of the GIFfaces dataset and associated code is a clear strength that could enable reproducible follow-on research.
major comments (2)
- [Method (DIRD subsection) / Experiments] The headline robustness claim rests on DIRD (described in the extraction-stage section). The abstract and method description provide no concrete attack models (e.g., specific face-swap or reenactment pipelines), training distributions, or post-manipulation extraction metrics such as bit-error rate or detection accuracy. Without these, it is impossible to assess whether the 3D attention mechanism actually recovers watermark signals after high-level semantic changes that break temporal coherence.
- [Experiments / Results] The experimental section asserts 'extensive results' and 'remarkable robustness' but, consistent with the absence of quantitative tables or ablation studies in the visible material, offers no numbers, baselines, or controls that would allow attribution of performance to the spatiotemporal components versus simpler 2D adaptations of existing image watermarkers.
minor comments (2)
- [Abstract / Conclusion] The abstract states that 'related code and dataset will be released' but does not specify the license, exact repository location, or reproducibility instructions (e.g., random seeds, exact training hyperparameters).
- [Method] Notation for the adaptive channel recalibration block and the 3D attention layers is introduced without an accompanying diagram or equation reference, making the architectural description harder to follow.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments identify important areas where additional clarity and quantitative support are needed to strengthen the robustness claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Method (DIRD subsection) / Experiments] The headline robustness claim rests on DIRD (described in the extraction-stage section). The abstract and method description provide no concrete attack models (e.g., specific face-swap or reenactment pipelines), training distributions, or post-manipulation extraction metrics such as bit-error rate or detection accuracy. Without these, it is impossible to assess whether the 3D attention mechanism actually recovers watermark signals after high-level semantic changes that break temporal coherence.
Authors: We agree that explicit details on the attack models and metrics are necessary for a rigorous evaluation of DIRD. In the revised manuscript, we will expand the method and experiments sections to specify the concrete pipelines used (including FaceSwap, SimSwap, and First-Order Motion Model for reenactment), the training distributions of the deepfake generators, and the post-manipulation extraction metrics (bit-error rate, detection accuracy, and AUC). These additions will directly demonstrate how the 3D attention restores watermark signals under temporal disruptions. revision: yes
-
Referee: [Experiments / Results] The experimental section asserts 'extensive results' and 'remarkable robustness' but, consistent with the absence of quantitative tables or ablation studies in the visible material, offers no numbers, baselines, or controls that would allow attribution of performance to the spatiotemporal components versus simpler 2D adaptations of existing image watermarkers.
Authors: We acknowledge that the current presentation of results lacks the detailed tables, numerical values, and ablation studies required for clear attribution. Although the manuscript references extensive experiments, we will revise the experimental section to include quantitative tables reporting PSNR, SSIM, bit-error rates, and detection accuracies, along with baselines (2D adaptations of HiDDeN and StegaStamp) and ablation studies isolating the 3D convolutional backbone, adaptive recalibration, and attention modules. This will enable direct comparison and attribution of gains to the spatiotemporal design. revision: yes
Circularity Check
No circularity detected; engineering proposal with no self-referential derivations
full rationale
The paper introduces GIFGuard as an applied neural architecture (STARE encoder with 3D convolutions and DIRD decoder with 3D attention) for watermark embedding and extraction in GIFs. No equations, fitted parameters renamed as predictions, self-citations invoked as uniqueness theorems, or ansatzes smuggled via prior work appear in the abstract or description. The central claims rest on empirical robustness results from the proposed models rather than any reduction to inputs by construction. The framework is self-contained as a design contribution without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Irene Amerini, Mauro Barni, Sebastiano Battiato, Paolo Bestagini, Giulia Boato, Vittoria Bruni, Roberto Caldelli, Francesco De Natale, Rocco De Nicola, Luca Guarnera, et al. 2025. Deepfake media forensics: Status and future challenges. Journal of Imaging11, 3 (2025), 73
2025
-
[2]
Luan Chen, Chengyou Wang, Xiao Zhou, and Zhiliang Qin. 2024. Robust and compatible video watermarking via spatio-temporal enhancement and multiscale pyramid attention.IEEE Transactions on Circuits and Systems for Video Technology (2024)
2024
-
[3]
Renwang Chen, Xuanhong Chen, Bingbing Ni, and Yanhao Ge. 2020. Simswap: An efficient framework for high fidelity face swapping. InProceedings of the 28th ACM international conference on multimedia. 2003–2011
2020
-
[4]
Zhilin Chen and Jiaohua Qin. 2025. Reversible data hiding in encrypted images based on histogram shifting and prediction error block coding.International Journal of Autonomous and Adaptive Communications Systems18, 1 (2025), 45–66
2025
-
[5]
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. 2020. Stargan v2: Diverse image synthesis for multiple domains. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8188–8197
2020
-
[6]
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. 2020. The deepfake detection challenge (dfdc) dataset.arXiv preprint arXiv:2006.07397(2020)
work page internal anchor Pith review arXiv 2020
-
[7]
Han Fang, Zhaoyang Jia, Yupeng Qiu, Jiyi Zhang, Weiming Zhang, and Ee-Chien Chang. 2022. De-END: Decoder-driven watermarking network.IEEE Transactions on Multimedia25 (2022), 7571–7581
2022
-
[8]
Pierre Fernandez, Guillaume Couairon, Hervé Jégou, Matthijs Douze, and Teddy Furon. 2023. The stable signature: Rooting watermarks in latent diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision. 22466–22477
2023
-
[9]
Zeki Yalniz, and Alexandre Mourachko
Pierre Fernandez, Hady Elsahar, I. Zeki Yalniz, and Alexandre Mourachko
- [10]
-
[11]
Robert W Floyd. 1976. An adaptive algorithm for spatial gray-scale. InProc. Soc. Inf. Disp., Vol. 17. 75–77
1976
-
[12]
Alexander Groshev, Anastasia Maltseva, Daniil Chesakov, Andrey Kuznetsov, and Denis Dimitrov. 2022. GHOST—a new face swap approach for image and video domains.IEEE Access10 (2022), 83452–83462
2022
-
[13]
Ziyuan He, Zhiqing Guo, Liejun Wang, Gaobo Yang, Yunfeng Diao, and Dan Ma
-
[14]
doi:10.1109/TCSVT.2025.3628951
WaveGuard: Robust Deepfake Detection and Source Tracing via Dual-Tree Complex Wavelet and Graph Neural Networks.IEEE Transactions on Circuits and Systems for Video Technology(2025), 1–1. doi:10.1109/TCSVT.2025.3628951
-
[15]
Lixin Jia, Haiyang Sun, Zhiqing Guo, Yunfeng Diao, Dan Ma, and Gaobo Yang
-
[16]
InProceedings of the AAAI Conference on Artificial Intelligence
Uncovering and Mitigating Destructive Multi-Embedding Attacks in Deep- fake Proactive Forensics. InProceedings of the AAAI Conference on Artificial Intelligence
-
[17]
Zhaoyang Jia, Han Fang, and Weiming Zhang. 2021. Mbrs: Enhancing robustness of dnn-based watermarking by mini-batch of real and simulated jpeg compres- sion. InProceedings of the 29th ACM international conference on multimedia. 41–49
2021
-
[18]
Xingxun Jiang, Yuan Zong, Wenming Zheng, Chuangao Tang, Wanchuang Xia, Cheng Lu, and Jiateng Liu. 2020. DFEW: A Large-Scale Database for Recognizing Dynamic Facial Expressions in the Wild. InProceedings of the 28th ACM International Conference on Multimedia(Seattle, WA, USA)(MM ’20). Association for Computing Machinery, New York, NY, USA, 2881–2889. doi:1...
-
[19]
Sara Kopelman. 2026. The look of “Aww”: Emotional transcoding in GIF reposito- ries on digital media platforms.new media & society(2026), 14614448251413708
2026
-
[20]
Jiyoung Lee, Seungryong Kim, Sunok Kim, Jungin Park, and Kwanghoon Sohn
-
[21]
InProceedings of the IEEE/CVF international conference on computer vision
Context-aware emotion recognition networks. InProceedings of the IEEE/CVF international conference on computer vision. 10143–10152
-
[22]
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. 2020. Celeb-df: A large-scale challenging dataset for deepfake forensics. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3207–3216
2020
-
[23]
Xin Liao, Jing Peng, and Yun Cao. 2021. GIFMarking: The robust watermarking for animated GIF based deep learning.Journal of Visual Communication and Image Representation79 (2021), 103244
2021
-
[24]
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. 2015. Deep learning face attributes in the wild. InProceedings of the IEEE international conference on computer vision. 3730–3738
2015
-
[25]
Xiyang Luo, Yinxiao Li, Huiwen Chang, Ce Liu, Peyman Milanfar, and Feng Yang. 2023. Dvmark: a deep multiscale framework for video watermarking.IEEE Transactions on Image Processing(2023)
2023
-
[26]
Souha Mansour, Saoussen Ben Jabra, and Ezzeddine Zagrouba. 2025. A compre- hensive overview of deep learning based video watermarking: Current works, challenges and future trends.Multimedia Tools and Applications84, 24 (2025), 28013–28060
2025
-
[27]
Paarth Neekhara, Shehzeen Hussain, Xinqiao Zhang, Ke Huang, Julian McAuley, and Farinaz Koushanfar. 2024. FaceSigns: Semi-fragile Watermarks for Media Authentication.ACM Trans. Multimedia Comput. Commun. Appl.20, 11, Article 337 (Sept. 2024), 21 pages. doi:10.1145/3640466
-
[28]
Hong-Hanh Nguyen-Le, Van-Tuan Tran, Thuc Nguyen, and Nhien-An Le-Khac
-
[29]
A Survey on Proactive Deepfake Defense: Disruption and Watermarking. Comput. Surveys(2025)
2025
-
[30]
Jia Peng, Jiaohua Qin, Xuyu Xiang, Yun Tan, and Dashan Qing. 2025. Robust watermarking algorithm for screen-shooting images based on pattern complexity JND model.International Journal of Autonomous and Adaptive Communications Systems18, 2 (2025), 139–158
2025
-
[31]
Albert Pumarola, Antonio Agudo, Aleix M Martinez, Alberto Sanfeliu, and Francesc Moreno-Noguer. 2018. Ganimation: Anatomically-aware facial anima- tion from a single image. InProceedings of the European conference on computer vision (ECCV). 818–833
2018
-
[32]
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. 2019. Faceforensics++: Learning to detect manipulated facial images. InProceedings of the IEEE/CVF international conference on computer vision. 1–11
2019
-
[33]
Chen Sun, Haiyang Sun, Zhiqing Guo, Yunfeng Diao, Liejun Wang, Dan Ma, Gaobo Yang, and Keqin Li. 2026. DiffMark: Diffusion-based robust watermark against Deepfakes.Information Fusion127 (2026), 103801. doi:10.1016/j.inffus. 2025.103801
-
[34]
Run Wang, Felix Juefei-Xu, Meng Luo, Yang Liu, and Lina Wang. 2021. Faketagger: Robust safeguards against deepfake dissemination via provenance tracking. In Proceedings of the 29th ACM international conference on multimedia. 3546–3555
2021
-
[35]
Tianyi Wang, Mengxiao Huang, Harry Cheng, Xiao Zhang, and Zhiqi Shen
-
[36]
InProceedings of the 32nd ACM International Conference on Multimedia
Lampmark: Proactive deepfake detection via training-free landmark per- ceptual watermarks. InProceedings of the 32nd ACM International Conference on Multimedia. 10515–10524
-
[37]
Yuxin Wen, John Jain, John Kirchenbauer, Jonas Goldi, Jonas Geiping, and Tom Goldstein. 2023. Tree-Ring Watermarks: Fingerprints for Diffusion Images that are Invisible and Robust. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[38]
Junjiang Wu, Liejun Wang, and Zhiqing Guo. 2026. All in One: Unifying Deepfake Detection, Tampering Localization, and Source Tracing with a Robust Landmark- Identity Watermark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2026
-
[39]
Xiaoshuai Wu, Xin Liao, and Bo Ou. 2023. Sepmark: Deep separable watermark- ing for unified source tracing and deepfake detection. InProceedings of the 31st ACM International Conference on Multimedia. 1190–1201
2023
-
[40]
Xiaoshuai Wu, Xin Liao, Bo Ou, Yuling Liu, and Zheng Qin. 2024. Are Watermarks Bugs for Deepfake Detectors? Rethinking Proactive Forensics. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI- 24, Kate Larson (Ed.). International Joint Conferences on Artificial Intelligence Organization, 6089–6097. doi:10.249...
-
[41]
Zhiliang Xu, Zhibin Hong, Changxing Ding, Zhen Zhu, Junyu Han, Jingtuo Liu, and Errui Ding. 2022. Mobilefaceswap: A lightweight framework for video face swapping. InProceedings of the AAAI Conference on Artificial Intelligence. 2973–2981
2022
-
[42]
Zijin Yang, Kai Zeng, Kejiang Chen, Han Fang, Weiming Zhang, and Nenghai Yu
-
[43]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gaussian shading: Provable performance-lossless image watermarking for diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12162–12171
- [44]
-
[45]
Xuanyu Zhang, Runyi Li, Jiwen Yu, Youmin Xu, Weiqi Li, and Jian Zhang. 2024. Editguard: Versatile image watermarking for tamper localization and copyright protection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11964–11974
2024
-
[46]
Yulin Zhang, Jiangqun Ni, Wenkang Su, and Xin Liao. 2023. A novel deep video watermarking framework with enhanced robustness to H. 264/AVC compression. InProceedings of the 31st ACM International Conference on Multimedia. 8095– 8104
2023
-
[47]
Hongrui Zheng, Yuezun Li, Liejun Wang, Yunfeng Diao, and Zhiqing Guo. 2026. Boosting Active Defense Persistence: A Two-Stage Defense Framework Com- bining Interruption and Poisoning Against Deepfake.IEEE Transactions on Information Forensics and Security(2026)
2026
-
[48]
Jiren Zhu, Russell Kaplan, Justin Johnson, and Li Fei-Fei. 2018. Hidden: Hiding data with deep networks. InProceedings of the European conference on computer vision (ECCV). 657–672. 9
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.