Recognition: unknown
RepoDoc: A Knowledge Graph-Based Framework to Automatic Documentation Generation and Incremental Updates
Pith reviewed 2026-05-07 11:29 UTC · model grok-4.3
The pith
RepoDoc builds a repository knowledge graph to generate structured documentation and target updates only to changed code sections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
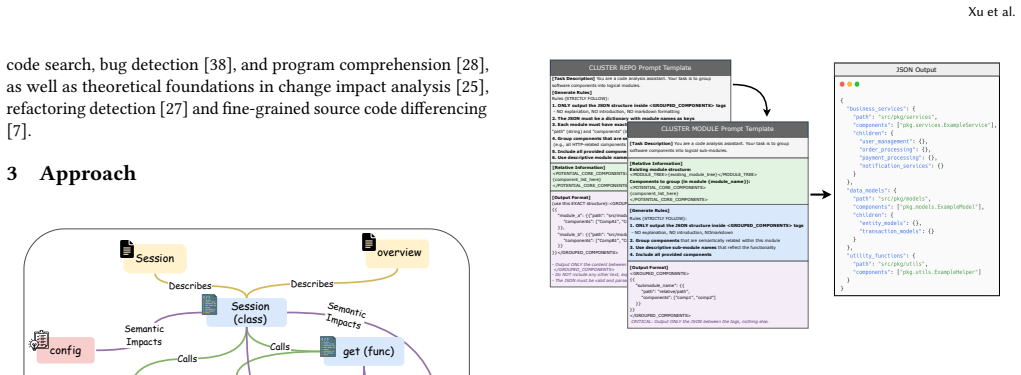
RepoDoc extracts code entities and relationships into a repository knowledge graph, clusters related modules hierarchically, and deploys agents to produce modular, cross-referenced documentation with Mermaid diagrams. For updates, a bidirectional semantic impact propagation mechanism identifies every affected documentation fragment so that regeneration stays selective. On 24 repositories spanning eight languages, this yields 32.5 percent higher API coverage, 10.4 percent better completeness, three-times faster generation, and 85 percent fewer tokens than prior methods, with similar gains in update speed and recall.
What carries the argument
The repository knowledge graph (RepoKG) that extracts code entities and relationships, then supplies structured queries for module clustering, agent-based generation, and bidirectional change propagation.
If this is right
- Generated documentation includes explicit cross-references and diagrams derived directly from the graph structure.
- Only documentation tied to changed code paths needs regeneration, cutting update time by 73 percent and token use by 77 percent.
- API coverage rises by 32.5 percent and overall completeness by 10.4 percent compared with existing LLM-based tools.
- The same graph supports documentation tasks across eight programming languages without language-specific rewriting.
- Update recall improves by 10.2 percent because propagation follows actual semantic dependencies rather than simple file diffs.
Where Pith is reading between the lines
- The graph could serve as a reusable index for other repository tasks such as code search or impact analysis beyond documentation.
- Projects using continuous integration could trigger targeted doc regeneration on every commit that touches the graph.
- If extraction misses certain implicit relationships, such as runtime plugin loading, documentation gaps would persist even after updates.
- Long-term maintenance of the graph itself may become a new cost center once the initial documentation is produced.
Load-bearing premise
The knowledge graph extracted from source code accurately and completely represents all semantically important entities and their dependencies.
What would settle it
Apply a code change that adds or removes a cross-module dependency not captured by the graph extraction step and observe whether the update mechanism still regenerates every affected documentation section.
Figures





read the original abstract
Maintaining up-to-date, comprehensive documentation for large codebases is a persistent challenge. Recent progress in automated documentation has moved from template-based rules to large language models (LLMs), yet existing tools still process source code as flat fragments, producing isolated documents that lack semantic structure. This design also leads to excessive token consumption and slow generation, while failing to capture how code changes propagate across dependencies. We propose RepoDoc, a system that uses a repository knowledge graph (RepoKG) as the semantic foundation for the entire documentation lifecycle. Our framework consists of three stages: (1) RepoKG construction, which extracts code entities and their relationships; (2) module clustering, which groups code into functionally cohesive, hierarchical units; and (3) skillful agent-based generation, which queries the graph to create modular, cross-referenced documentation with auto-generated Mermaid diagrams. For incremental maintenance, a semantic impact propagation mechanism navigates the RepoKG bidirectionally to pinpoint all affected parts, allowing selective, targeted regeneration. Evaluated on 24 repositories across 8 programming languages, RepoDoc substantially outperforms state-of-the-art alternatives. It improves API coverage by 32.5% and completeness by 10.4%, while generating documentation 3x faster with 85% fewer tokens. For incremental updates, it cuts update time by 73% and token usage by 77%, and achieves 10.2% higher update recall, more accurately reflecting code changes in the regenerated documentation. The source code and experimental artifacts are available at https://github.com/SYSUSELab/RepoDoc.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RepoDoc, a framework that constructs a repository knowledge graph (RepoKG) to support the full documentation lifecycle. It proceeds in three stages—RepoKG extraction of entities and relations, hierarchical module clustering, and agent-based generation that produces cross-referenced documents with Mermaid diagrams—plus a bidirectional semantic impact propagation mechanism for incremental updates. On 24 repositories spanning 8 languages the system is reported to improve API coverage by 32.5 % and completeness by 10.4 %, generate documentation 3× faster with 85 % fewer tokens, and for updates reduce time by 73 %, token usage by 77 %, and raise recall by 10.2 %.
Significance. If the empirical results hold under rigorous controls, the work offers a concrete, graph-centric alternative to flat LLM prompting for documentation tasks. The public release of code and artifacts is a clear strength that enables direct inspection of the extraction, clustering, and propagation components.
major comments (3)
- [§4] §4 (Evaluation): The abstract and results section report aggregate improvements over “state-of-the-art alternatives” but provide no explicit list of the chosen baselines, their versions, or the rationale for their selection. Without this information the 32.5 % coverage and 10.4 % completeness gains cannot be interpreted as a fair comparison.
- [§4.2] §4.2 (Incremental-update experiments): The 73 % time and 77 % token reductions are presented without statistical significance tests, confidence intervals, or controls for repository size and language. The 10.2 % recall improvement is therefore difficult to assess for robustness.
- [§3.1] §3.1 (RepoKG construction): The claim that the extracted graph “accurately and completely captures all semantically relevant code entities” is central to both generation and propagation claims, yet no quantitative validation (e.g., precision/recall against a manually annotated gold graph) is reported.
minor comments (2)
- [§3.3] Figure 3 and the accompanying text use “semantic impact propagation” without a formal definition or pseudocode; a concise algorithm box would improve clarity.
- [§3.3] The paper states that documentation is generated “with auto-generated Mermaid diagrams” but does not report any metric for diagram correctness or readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to improve the clarity and rigor of our evaluation and claims. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): The abstract and results section report aggregate improvements over “state-of-the-art alternatives” but provide no explicit list of the chosen baselines, their versions, or the rationale for their selection. Without this information the 32.5 % coverage and 10.4 % completeness gains cannot be interpreted as a fair comparison.
Authors: We agree that explicit details on the baselines are necessary for a fair and reproducible comparison. In the revised manuscript we will add a dedicated paragraph in §4 that enumerates the specific state-of-the-art alternatives, their versions, and the selection rationale (prominence in recent LLM-based documentation work and relevance to flat-prompting approaches). A summary table will also be included to facilitate direct assessment of the reported 32.5 % coverage and 10.4 % completeness gains. revision: yes
-
Referee: [§4.2] §4.2 (Incremental-update experiments): The 73 % time and 77 % token reductions are presented without statistical significance tests, confidence intervals, or controls for repository size and language. The 10.2 % recall improvement is therefore difficult to assess for robustness.
Authors: We acknowledge the lack of statistical controls in the incremental-update results. We will extend §4.2 to report paired statistical significance tests with p-values, 95 % confidence intervals for all key metrics, and additional subgroup analyses stratified by repository size and language. These additions will strengthen the evidence for the 73 % time reduction, 77 % token savings, and 10.2 % recall improvement. revision: yes
-
Referee: [§3.1] §3.1 (RepoKG construction): The claim that the extracted graph “accurately and completely captures all semantically relevant code entities” is central to both generation and propagation claims, yet no quantitative validation (e.g., precision/recall against a manually annotated gold graph) is reported.
Authors: We recognize that a direct precision/recall evaluation against a manually annotated gold graph would be desirable. However, constructing such gold standards for 24 repositories spanning eight languages and thousands of entities is not practically feasible. We will revise §3.1 to moderate the claim, explicitly stating that graph quality is supported indirectly by the consistent downstream gains in documentation coverage, completeness, and update recall. This indirect validation is standard when exhaustive component-level annotation is intractable. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external evaluation
full rationale
The paper proposes a three-stage framework (RepoKG construction, module clustering, agent-based generation) plus an incremental propagation mechanism, then reports concrete performance deltas from running the system on 24 repositories across 8 languages. No equations, fitted parameters, or first-principles derivations are presented whose outputs are shown to be equivalent to their inputs by construction. The central claims are statistical comparisons against external baselines; the released code and artifacts make the evaluation independently inspectable. No self-citation is invoked as a load-bearing uniqueness theorem or ansatz. This is the normal, non-circular case for an applied systems paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Code entities and their relationships can be reliably extracted from source code to form a complete repository knowledge graph.
- domain assumption Module clustering produces functionally cohesive hierarchical units suitable for modular documentation.
invented entities (2)
-
RepoKG
no independent evidence
-
semantic impact propagation mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang
-
[2]
arXiv:2005.00653 [cs.SE] https://arxiv.org/abs/2005.00653
A Transformer-based Approach for Source Code Summarization. arXiv:2005.00653 [cs.SE] https://arxiv.org/abs/2005.00653
-
[3]
Barr, Premkumar Devanbu, and Charles Sut- ton
Miltiadis Allamanis, Earl T. Barr, Premkumar Devanbu, and Charles Sut- ton. 2018. A Survey of Machine Learning for Big Code and Naturalness. arXiv:1709.06182 [cs.SE] https://arxiv.org/abs/1709.06182
- [4]
-
[5]
Egor Bogomolov, Aleksandra Eliseeva, Timur Galimzyanov, Evgeniy Glukhov, Anton Shapkin, Maria Tigina, Yaroslav Golubev, Alexander Kovrigin, Arie van Deursen, Maliheh Izadi, and Timofey Bryksin. 2024. Long Code Arena: a Set of Benchmarks for Long-Context Code Models. arXiv:2406.11612 [cs.LG] https: //arxiv.org/abs/2406.11612
-
[6]
Yujia Chen, Xiaoxue Ren, Cuiyun Gao, Yun Peng, Xin Xia, and Michael R. Lyu
-
[7]
arXiv:2208.01971 [cs.SE] https://arxiv.org/abs/2208.01971
API Usage Recommendation via Multi-View Heterogeneous Graph Repre- sentation Learning. arXiv:2208.01971 [cs.SE] https://arxiv.org/abs/2208.01971
-
[8]
Giuseppe Crupi, Rosalia Tufano, Alejandro Velasco, Antonio Mastropaolo, Denys Poshyvanyk, and Gabriele Bavota. 2024. On the Effectiveness of LLM-as-a- Judge for Code Generation and Summarization.IEEE Transactions on Software Engineering(2024)
2024
-
[9]
J. R. Falleri, F. Morandat, X. Blanc, M. Martinez, and M. Monperrus. 2014. Fine- grained and accurate source code differencing. (2014), 313–324
2014
-
[10]
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, and M. Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. arXiv:2002.08155
work page internal anchor Pith review arXiv 2020
-
[11]
Retrieval-Augmented Generation for Large Language Models: A Survey
L. Gao and et al. 2023. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997
work page internal anchor Pith review arXiv 2023
-
[12]
Xiaodong Gu, Hongyu Zhang, and Sunghun Kim. 2018. Deep code search. In Proceedings of the 40th International Conference on Software Engineering(Gothen- burg, Sweden)(ICSE ’18). Association for Computing Machinery, New York, NY, USA, 933–944. doi:10.1145/3180155.3180167
-
[13]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou. 2021. GraphCodeBERT: Pre-training Code Representations with Data Flow. arXiv:2009.08366 [cs.SE] https://arxiv.org/abs/2009.08366
work page internal anchor Pith review arXiv 2021
-
[14]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Pro- gramming – The Rise of Code Intelligence. arXiv:2401.14196 [cs.SE] https: //arxiv.org/abs/2401.14196
work page internal anchor Pith review arXiv 2024
-
[15]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. arXiv:2308.00352 [cs.AI] https://arxiv.org/abs/2308.00352
work page internal anchor Pith review arXiv 2024
- [16]
-
[17]
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2020. CodeSearchNet Challenge: Evaluating the State of Semantic Code Search. arXiv:1909.09436 [cs.LG] https://arxiv.org/abs/1909.09436
work page internal anchor Pith review arXiv 2020
-
[18]
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2016. Summarizing Source Code using a Neural Attention Model. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Katrin Erk and Noah A. Smith (Eds.). Association for Computational Linguistics, Berlin, Germany, 2073–2083. do...
-
[19]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2026. A Survey on Large Language Models for Code Generation. 35, 2, Article 58 (Jan. 2026), 72 pages. doi:10.1145/3747588
-
[20]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Loge...
work page internal anchor Pith review arXiv 2023
-
[21]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, and Shujie Liu. 2021. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understan...
-
[22]
Qinyu Luo, Yining Ye, Shihao Liang, Zhong Zhang, Yujia Qin, Yaxi Lu, Yesai Wu, Xin Cong, Yankai Lin, Yingli Zhang, Xiaoyin Che, Zhiyuan Liu, and Maosong Sun
-
[23]
RepoAgent: An LLM-Powered Open-Source Framework for Repository- level Code Documentation Generation. arXiv:2402.16667 [cs.CL] https://arxiv. org/abs/2402.16667
-
[24]
CodeWiki: Evaluating AI's Ability to Generate Holistic Documentation for Large-Scale Codebases
V. Makharev and V. Ivanov. 2025. CodeWiki: Evaluating AI’s Ability to Generate Holistic Documentation for Large-Scale Codebases. arXiv:2510.24428
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Tung Thanh Nguyen, Hoan Anh Nguyen, Nam H. Pham, Jafar M. Al-Kofahi, and Tien N. Nguyen. 2009. Graph-based mining of multiple object usage patterns. InProceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on The Foundations of Software Engineering(Amsterdam, The Netherlands)(ESEC/FSE ’09). Assoc...
-
[26]
Xin Peng, Yifan Zhao, Mingwei Liu, Fengyi Zhang, Yang Liu, Xin Wang, and Zhenchang Xing. 2018. Automatic Generation of API Documentations for Open- Source Projects. 7–8. doi:10.1109/DySDoc3.2018.00010
-
[27]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084 [cs.CL] https://arxiv.org/abs/ 1908.10084
work page internal anchor Pith review arXiv 2019
-
[28]
B. G. Ryder and F. Tip. 2001. Change impact analysis for object-oriented programs. (2001), 46–53
2001
-
[29]
Giriprasad Sridhara, Emily Hill, Divya Muppaneni, Lori Pollock, and K. Vijay- Shanker. 2010. Towards automatically generating summary comments for Java methods. InProceedings of the 25th IEEE/ACM International Conference on Au- tomated Software Engineering(Antwerp, Belgium)(ASE ’10). Association for Computing Machinery, New York, NY, USA, 43–52. doi:10.11...
-
[30]
Eshkevari, Davood Mazinanian, and Danny Dig
Nikolaos Tsantalis, Matin Mansouri, Laleh M. Eshkevari, Davood Mazinanian, and Danny Dig. 2018. Accurate and efficient refactoring detection in commit history. InProceedings of the 40th International Conference on Software Engineering (Gothenburg, Sweden)(ICSE ’18). Association for Computing Machinery, New York, NY, USA, 483–494. doi:10.1145/3180155.3180206
-
[31]
F. Wang, J. Liu, B. Liu, T. Qian, Y. Xiao, and Z. Peng. 2020. Survey on construction of code knowledge graph and intelligent software development.Journal of Software31, 1 (2020), 47–66
2020
- [32]
-
[33]
X. Xia, L. Bao, D. Lo, Z. Xing, A. E. Hassan, and S. Li. 2017. Measuring program comprehension: A large-scale field study with professionals.IEEE Transactions on Software Engineering44, 10 (2017), 951–976
2017
-
[34]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer In- terfaces Enable Automated Software Engineering. arXiv:2405.15793 [cs.SE] https://arxiv.org/abs/2405.15793
work page internal anchor Pith review arXiv 2024
-
[35]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL] https://arxiv.org/abs/2210.03629
work page internal anchor Pith review arXiv 2023
-
[36]
Chunyan Zhang, Junchao Wang, Qinglei Zhou, Ting Xu, Ke Tang, Hairen Gui, and Fudong Liu. 2022. A Survey of Automatic Source Code Summarization. Symmetry14, 3 (2022). doi:10.3390/sym14030471
- [37]
- [38]
-
[39]
Yuwei Zhao, Ziyang Luo, Yuchen Tian, Weixiang Yan, Annan Li, and Jing Ma
-
[40]
InFindings of the Association for Computational Linguistics: ACL 2024
CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?. InFindings of the Association for Computational Linguistics: ACL 2024
2024
-
[41]
Xing, et al
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, et al . 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
- [42]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.