Recognition: unknown
DenseStep2M: A Scalable, Training-Free Pipeline for Dense Instructional Video Annotation
Pith reviewed 2026-05-07 13:45 UTC · model grok-4.3
The pith
A training-free pipeline segments instructional videos and uses multimodal models to generate 2 million temporally grounded procedural steps from 100K videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
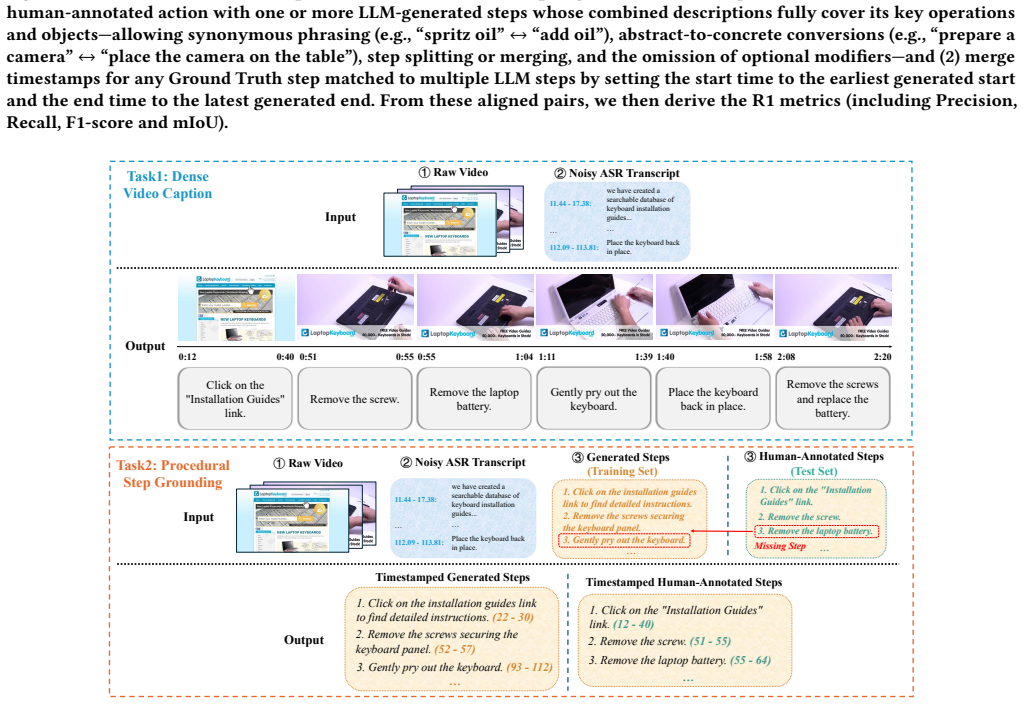
We introduce a scalable, training-free pipeline that segments in-the-wild instructional videos into shots, applies alignment filtering, and leverages Qwen2.5-VL together with DeepSeek-R1 to output dense, temporally grounded procedural steps, yielding the DenseStep2M dataset of roughly 100K videos and 2M steps that supports measurable gains on dense captioning, procedural grounding, and cross-modal retrieval while maintaining zero-shot robustness across egocentric, exocentric, and mixed views.
What carries the argument
The training-free pipeline of shot segmentation followed by alignment filtering and structured generation from Qwen2.5-VL and DeepSeek-R1, which converts raw video-plus-narration into temporally accurate procedural steps.
If this is right
- Models fine-tuned on DenseStep2M produce higher-quality dense captions and more precise temporal localization of procedural steps.
- The same models exhibit robust zero-shot generalization to egocentric, exocentric, and mixed-perspective videos.
- The dataset enables stronger performance on cross-modal retrieval and long-term activity reasoning without task-specific retraining.
- A new human-written benchmark, DenseCaption100, confirms close alignment between the auto-generated steps and expert annotations.
Where Pith is reading between the lines
- The same segmentation-plus-generation approach could be applied to non-instructional video domains such as sports or surveillance to create large-scale temporal annotations without manual labeling.
- Combining the dataset with existing narration-only corpora might further reduce reliance on ASR noise in long-form video pretraining.
- If the pipeline scales to additional video sources, it could support training of models that follow real-world procedures in robotics or educational settings.
Load-bearing premise
Off-the-shelf Qwen2.5-VL and DeepSeek-R1 models, combined with the shot segmentation and filtering steps, generate temporally accurate and semantically correct procedural annotations at scale without substantial hallucinations or systematic biases.
What would settle it
A human audit of several thousand generated steps that finds frequent temporal misalignment with visual actions or semantic inaccuracies, or downstream models that show no measurable improvement on captioning and localization benchmarks after fine-tuning on the dataset.
Figures
















read the original abstract
Long-term video understanding requires interpreting complex temporal events and reasoning over procedural activities. While instructional video corpora, like HowTo100M, offer rich resources for model training, they present significant challenges, including noisy ASR transcripts and inconsistent temporal alignments between narration and visual content. In this work, we introduce an automated, training-free pipeline to extract high-quality procedural annotations from in-the-wild instructional videos. Our approach segments videos into coherent shots, filters poorly aligned content, and leverages state-of-the-art multimodal and large language models (Qwen2.5-VL and DeepSeek-R1) to generate structured, temporally grounded procedural steps. This pipeline yields DenseStep2M, a large-scale dataset comprising approximately 100K videos and 2M detailed instructional steps, designed to support comprehensive long-form video understanding. To rigorously evaluate our pipeline, we curate DenseCaption100, a benchmark of high-quality, human-written captions. Evaluations demonstrate strong alignment between our auto-generated steps and human annotations. Furthermore, we validate the utility of DenseStep2M across three core downstream tasks: dense video captioning, procedural step grounding, and cross-modal retrieval. Models fine-tuned on DenseStep2M achieve substantial gains in captioning quality and temporal localization, while exhibiting robust zero-shot generalization across egocentric, exocentric, and mixed-perspective domains. These results underscore the effectiveness of DenseStep2M in facilitating advanced multimodal alignment and long-term activity reasoning. Our dataset is available at https://huggingface.co/datasets/mingjige/DenseStep2M.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DenseStep2M, a dataset of ~2M dense procedural steps from 100K instructional videos, generated via a training-free pipeline that segments videos into shots, applies alignment filtering, and uses off-the-shelf Qwen2.5-VL and DeepSeek-R1 models to produce temporally grounded annotations. It curates DenseCaption100 as a human-annotated benchmark to show alignment with auto-generated steps, and reports downstream improvements in dense video captioning, procedural step grounding, and cross-modal retrieval when models are fine-tuned on DenseStep2M, with claimed robust zero-shot generalization across egocentric, exocentric, and mixed domains.
Significance. If the pipeline produces temporally accurate and semantically reliable steps at scale, DenseStep2M would be a valuable addition to instructional video resources, addressing noisy alignments in datasets like HowTo100M through scalable, training-free extraction. Strengths include the dataset release, multi-task downstream validation, and emphasis on cross-perspective generalization. However, the absence of quantified error rates for hallucinations or misalignments limits claims about quality and attribution of gains.
major comments (3)
- [Abstract] Abstract: The claims of 'strong alignment' with human annotations on DenseCaption100 and 'substantial gains' in captioning quality and temporal localization are unsupported by any quantitative metrics, error bars, ablation results, or statistical tests. This is load-bearing for the central claim that the pipeline yields high-quality annotations suitable for model training.
- [Methods/Evaluation] Pipeline and evaluation sections: No large-scale audit quantifies hallucination rates, factual errors, or temporal misalignment fractions (e.g., steps with offset > threshold) from Qwen2.5-VL + DeepSeek-R1 after filtering, across the full 2M-step distribution. Known VLM limitations on long procedural videos could propagate, undermining both dataset quality and attribution of downstream gains to DenseStep2M rather than data volume.
- [Evaluation] DenseCaption100 benchmark: Insufficient details on curation (video selection criteria, annotation protocol, inter-annotator agreement, size, and diversity) and baseline selection, raising risks of selection bias that could inflate reported alignment and generalization results.
minor comments (2)
- [Related Work] Add explicit references to prior work on instructional video datasets (e.g., HowTo100M limitations) and VLM hallucination mitigation techniques in the related work section.
- [Methods] Clarify the exact criteria and thresholds used in the 'alignment filtering' stage, including any hyperparameters, to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify areas where additional rigor and transparency will strengthen the presentation of our results. We address each major point below and commit to revisions that improve the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 'strong alignment' with human annotations on DenseCaption100 and 'substantial gains' in captioning quality and temporal localization are unsupported by any quantitative metrics, error bars, ablation results, or statistical tests. This is load-bearing for the central claim that the pipeline yields high-quality annotations suitable for model training.
Authors: The body of the manuscript reports quantitative alignment metrics (e.g., step-level precision/recall/F1 on DenseCaption100) and downstream gains with baseline comparisons in Sections 4 and 5. We agree the abstract would be stronger with explicit numbers. In revision we will insert the key quantitative results, reference the ablations, and note where error bars or significance tests appear in the main text. revision: yes
-
Referee: [Methods/Evaluation] Pipeline and evaluation sections: No large-scale audit quantifies hallucination rates, factual errors, or temporal misalignment fractions (e.g., steps with offset > threshold) from Qwen2.5-VL + DeepSeek-R1 after filtering, across the full 2M-step distribution. Known VLM limitations on long procedural videos could propagate, undermining both dataset quality and attribution of downstream gains to DenseStep2M rather than data volume.
Authors: A full audit of all 2M steps is not present in the current manuscript and would require prohibitive human effort. We will add a limitations paragraph acknowledging VLM error modes on long videos and describing how the alignment filter reduces (but does not eliminate) misalignment. We will also expand the attribution discussion by highlighting the controlled volume-matched comparisons already present in the experiments. A complete large-scale audit remains outside the scope of this work. revision: partial
-
Referee: [Evaluation] DenseCaption100 benchmark: Insufficient details on curation (video selection criteria, annotation protocol, inter-annotator agreement, size, and diversity) and baseline selection, raising risks of selection bias that could inflate reported alignment and generalization results.
Authors: We will expand the DenseCaption100 description in the revised manuscript to specify video selection criteria (domain and perspective diversity, no overlap with training data), the annotation protocol and guidelines, inter-annotator agreement statistics, exact size, and category coverage. Baseline selection will be justified with references to standard methods in the literature. These additions will reduce ambiguity around potential bias. revision: yes
- A complete large-scale human audit of hallucination and temporal misalignment rates across the entire 2M-step dataset
Circularity Check
No significant circularity; pipeline and evaluations are externally grounded
full rationale
The paper describes a training-free pipeline that applies off-the-shelf Qwen2.5-VL and DeepSeek-R1 models after shot segmentation and alignment filtering to produce the DenseStep2M dataset. Quality is assessed against an independently curated human benchmark (DenseCaption100) and downstream gains are measured on separate tasks with zero-shot generalization tests. No equations, fitted parameters, or self-citations are invoked in a manner that reduces any claimed result to the inputs by construction; the central claims rest on external models and human annotations rather than self-referential fitting or renaming.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Qwen2.5-VL and DeepSeek-R1 can generate accurate, temporally grounded procedural steps from video frames and narration without task-specific fine-tuning.
- domain assumption Standard video shot segmentation and alignment filtering can reliably separate well-aligned from poorly aligned content in instructional videos.
invented entities (1)
-
DenseStep2M dataset
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Triantafyllos Afouras, Effrosyni Mavroudi, Tushar Nagarajan, Huiyu Wang, and Lorenzo Torresani. 2023. Ht-step: Aligning instructional articles with how-to videos.Advances in Neural Information Processing Systems36 (2023), 50310–50326
2023
-
[3]
Jean-Baptiste Alayrac, Piotr Bojanowski, Nishant Agrawal, Josef Sivic, Ivan Laptev, and Simon Lacoste-Julien. 2016. Unsupervised learning from narrated instruction videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4575–4583
2016
-
[4]
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. 2017. Localizing moments in video with natural language. In Proceedings of the IEEE international conference on computer vision. 5803–5812
2017
-
[5]
Anthropic. 2024. The Claude 3 Model Family: Opus, Sonnet, Haiku. https: //www.anthropic.com. https://www.anthropic.com
2024
-
[6]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review arXiv 2023
-
[7]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review arXiv 2025
-
[8]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. 2025. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review arXiv 2025
-
[9]
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. 2023. WhisperX: Time-Accurate Speech Transcription of Long-Form Audio.INTERSPEECH 2023 (2023)
2023
-
[10]
Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. 2021. Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval. InProceedings of the IEEE/CVF International Conference on Computer Vision
2021
-
[11]
Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. 2021. Frozen in time: A joint video and image encoder for end-to-end retrieval. InProceedings of the IEEE/CVF international conference on computer vision. 1728–1738
2021
-
[12]
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. InProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization. 65–72
2005
-
[13]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. 2023. Rt-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818(2023)
work page internal anchor Pith review arXiv 2023
-
[14]
Keshigeyan Chandrasegaran, Agrim Gupta, Lea M Hadzic, Taran Kota, Jimming He, Cristóbal Eyzaguirre, Zane Durante, Manling Li, Jiajun Wu, and Fei-Fei Li
-
[15]
Hourvideo: 1-hour video-language understanding.Advances in Neural Information Processing Systems37 (2024), 53168–53197
2024
-
[16]
Chien-Yi Chang, De-An Huang, Danfei Xu, Ehsan Adeli, Li Fei-Fei, and Juan Car- los Niebles. 2020. Procedure planning in instructional videos. InEuropean Con- ference on Computer Vision. Springer, 334–350
2020
-
[17]
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. 2024. Gr-2: A generative video- language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158(2024)
work page internal anchor Pith review arXiv 2024
-
[18]
David Chen and William B Dolan. 2011. Collecting highly parallel data for paraphrase evaluation. InProceedings of the 49th annual meeting of the association for computational linguistics: human language technologies. 190–200
2011
-
[19]
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Zhenyu Tang, Li Yuan, et al. 2024. Sharegpt4video: Im- proving video understanding and generation with better captions.Advances in Neural Information Processing Systems37 (2024), 19472–19495
2024
-
[20]
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming- Hsuan Yang, et al . 2024. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13320–13331
2024
-
[21]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al . 2024. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271(2024)
work page internal anchor Pith review arXiv 2024
-
[22]
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. 2024. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences67, 12 (2024), 220101
2024
-
[23]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al . 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24185–24198
2024
-
[24]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. 2024. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476(2024)
work page internal anchor Pith review arXiv 2024
-
[25]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review arXiv 2025
-
[26]
Tri Dao. 2024. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. InInternational Conference on Learning Representations (ICLR)
2024
-
[27]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. (2024). arXiv:2401.08281 [cs.LG]
work page internal anchor Pith review arXiv 2024
-
[28]
Nikita Dvornik, Isma Hadji, Ran Zhang, Konstantinos G Derpanis, Richard P Wildes, and Allan D Jepson. 2023. Stepformer: Self-supervised step discovery and localization in instructional videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18952–18961
2023
-
[29]
Soichiro Fujita, Tsutomu Hirao, Hidetaka Kamigaito, Manabu Okumura, and Masaaki Nagata. 2020. Soda: Story oriented dense video captioning evaluation framework. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16. Springer, 517–531
2020
-
[30]
Deepti Ghadiyaram, Du Tran, and Dhruv Mahajan. 2019. Large-scale weakly- supervised pre-training for video action recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12046–12055
2019
-
[31]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. 2022. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 18995–19012
2022
-
[32]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review arXiv 2025
-
[33]
Tengda Han, Weidi Xie, and Andrew Zisserman. 2022. Temporal alignment networks for long-term video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2906–2916
2022
- [34]
-
[35]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[36]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review arXiv 2024
-
[37]
Minkuk Kim, Hyeon Bae Kim, Jinyoung Moon, Jinwoo Choi, and Seong Tae Kim
-
[38]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Do you remember? dense video captioning with cross-modal memory retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13894–13904
-
[39]
Minkuk Kim, Hyeon Bae Kim, Jinyoung Moon, Jinwoo Choi, and Seong Tae Kim. 2025. HiCM 2: Hierarchical Compact Memory Modeling for Dense Video Captioning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 4293–4301
2025
-
[40]
Hilde Kuehne, Ali Arslan, and Thomas Serre. 2014. The language of actions: Recovering the syntax and semantics of goal-directed human activities. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 780–787
2014
-
[41]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. 2024. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22195–22206
2024
-
[42]
Linjie Li, Yen-Chun Chen, Yu Cheng, Zhe Gan, Licheng Yu, and Jingjing Liu
-
[43]
InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
HERO: Hierarchical Encoder for Video+ Language Omni-representation Pre-training. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2046–2065
2020
-
[44]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al . 2026. Qwen3-VL- Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking.arXiv preprint arXiv:2601.04720(2026)
work page internal anchor Pith review arXiv 2026
-
[45]
Zeqian Li, Qirui Chen, Tengda Han, Ya Zhang, Yanfeng Wang, and Weidi Xie
-
[46]
InEuropean Conference on Computer Vision
Multi-Sentence Grounding for Long-term Instructional Video. InEuropean Conference on Computer Vision. 200–216
-
[47]
Kevin Qinghong Lin, Jinpeng Wang, Mattia Soldan, Michael Wray, Rui Yan, Eric Z Xu, Difei Gao, Rong-Cheng Tu, Wenzhe Zhao, Weijie Kong, et al. 2022. Egocentric 9 video-language pretraining.Advances in Neural Information Processing Systems 35 (2022), 7575–7586
2022
-
[48]
Yikun Liu, Yajie Zhang, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. 2025. Lamra: Large multimodal model as your advanced retrieval assistant. InProceedings of the Computer Vision and Pattern Recognition Conference. 4015–4025
2025
-
[49]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review arXiv 2017
-
[50]
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. 2023. Egoschema: A diagnostic benchmark for very long-form video language un- derstanding.Advances in Neural Information Processing Systems36 (2023), 46212– 46244
2023
-
[51]
Effrosyni Mavroudi, Triantafyllos Afouras, and Lorenzo Torresani. 2023. Learning to ground instructional articles in videos through narrations. InProceedings of the IEEE/CVF International Conference on Computer Vision. 15201–15213
2023
- [52]
-
[53]
Sachit Menon, Ishan Misra, and Rohit Girdhar. 2024. Generating illustrated instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6274–6284
2024
-
[54]
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. 2019. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. InProceedings of the IEEE/CVF International Conference on Computer Vision. 2630–2640
2019
-
[55]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748(2018)
work page internal anchor Pith review arXiv 2018
-
[56]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deep- speed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 3505–3506
2020
-
[57]
Michaela Regneri, Marcus Rohrbach, Dominikus Wetzel, Stefan Thater, Bernt Schiele, and Manfred Pinkal. 2013. Grounding action descriptions in videos. Transactions of the Association for Computational Linguistics1 (2013), 25–36
2013
- [58]
-
[59]
Nina Shvetsova, Anna Kukleva, Xudong Hong, Christian Rupprecht, Bernt Schiele, and Hilde Kuehne. 2024. Howtocaption: Prompting llms to transform video annotations at scale. InEuropean Conference on Computer Vision. 1–18
2024
- [60]
-
[61]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al
-
[62]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Yale Song, Eugene Byrne, Tushar Nagarajan, Huiyu Wang, Miguel Martin, and Lorenzo Torresani. 2023. Ego4d goal-step: Toward hierarchical understanding of procedural activities.Advances in Neural Information Processing Systems36 (2023), 38863–38886
2023
-
[64]
Tomáš Souček, Dima Damen, Michael Wray, Ivan Laptev, and Josef Sivic. 2024. Genhowto: Learning to generate actions and state transformations from instruc- tional videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6561–6571
2024
- [65]
-
[66]
Tomáš Souček, Prajwal Gatti, Michael Wray, Ivan Laptev, Dima Damen, and Josef Sivic. 2025. ShowHowTo: Generating Scene-Conditioned Step-by-Step Visual Instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2025
-
[67]
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. 2019. Coin: A large-scale dataset for comprehensive in- structional video analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1207–1216
2019
-
[68]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review arXiv 2023
-
[69]
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. 2015. Cider: Consensus-based image description evaluation. InProceedings of the IEEE confer- ence on computer vision and pattern recognition. 4566–4575
2015
-
[70]
Hanlin Wang, Yilu Wu, Sheng Guo, and Limin Wang. 2023. Pdpp: Projected diffusion for procedure planning in instructional videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14836–14845
2023
-
[71]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review arXiv 2024
-
[72]
Teng Wang, Ruimao Zhang, Zhichao Lu, Feng Zheng, Ran Cheng, and Ping Luo
-
[73]
InProceedings of the IEEE/CVF International Conference on Computer Vision
End-to-end dense video captioning with parallel decoding. InProceedings of the IEEE/CVF International Conference on Computer Vision. 6847–6857
- [74]
-
[75]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. 2024. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Information Processing Systems37 (2024), 28828–28857
2024
-
[76]
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, and Weidi Xie. 2024. Retrieval-augmented egocentric video captioning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13525–13536
2024
-
[77]
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. 2016. Msr-vtt: A large video description dataset for bridging video and language. InProceedings of the IEEE conference on computer vision and pattern recognition. 5288–5296
2016
-
[78]
Hongwei Xue, Tiankai Hang, Yanhong Zeng, Yuchong Sun, Bei Liu, Huan Yang, Jianlong Fu, and Baining Guo. 2022. Advancing high-resolution video- language representation with large-scale video transcriptions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5036–5045
2022
-
[79]
Zihui Xue, Kumar Ashutosh, and Kristen Grauman. 2024. Learning object state changes in videos: An open-world perspective. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18493–18503
2024
-
[80]
Semih Yagcioglu, Aykut Erdem, Erkut Erdem, and Nazli Ikizler-Cinbis. 2018. RecipeQA: A Challenge Dataset for Multimodal Comprehension of Cooking Recipes. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 1358–1368
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.