Recognition: unknown
FunFace: Feature Utility and Norm Estimation for Face Recognition
Pith reviewed 2026-05-07 10:49 UTC · model grok-4.3
The pith
FunFace integrates biometric utility estimates via the Certainty Ratio into adaptive margin losses to train face recognition models that match state-of-the-art performance on high-quality data while outperforming it on low-quality data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that incorporating the Certainty Ratio as a measure of biometric utility into the adaptive margin, alongside feature norm information, produces a loss function that yields face recognition models competitive with current state-of-the-art methods on high-quality benchmarks while surpassing them on low-quality benchmarks.
What carries the argument
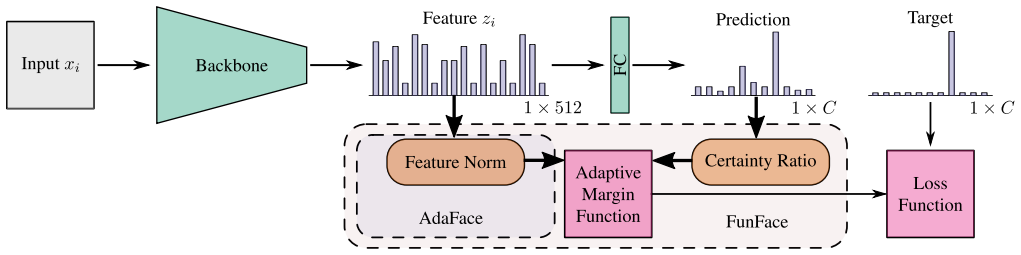
The Certainty Ratio estimator of biometric utility, integrated directly into the adaptive margin of the loss function in addition to feature norms.
If this is right
- Models trained this way maintain high accuracy on clean data while gaining on samples with reduced resolution, blur, or lighting.
- The separation of utility from norm-based quality allows the loss to use information that current proxies miss.
- Performance advantages appear most clearly on benchmarks designed to test degraded inputs.
- Training no longer needs separate quality labels because the Certainty Ratio supplies the utility signal during optimization.
Where Pith is reading between the lines
- The same utility integration could be tested in other vision tasks where sample usefulness varies independently of visual clarity.
- Real-time video systems might benefit if margins were adjusted on the fly using running Certainty Ratio estimates.
- Combining the Certainty Ratio with additional quality signals could create even stronger training objectives for future models.
Load-bearing premise
The Certainty Ratio must supply an accurate, independent estimate of biometric utility that improves the margin without causing training instabilities or new biases.
What would settle it
Train models using FunFace and directly compare their accuracy against AdaFace and similar baselines on multiple established low-quality face recognition benchmarks; failure to surpass the baselines on those sets would disprove the benefit of the utility addition.
Figures



read the original abstract
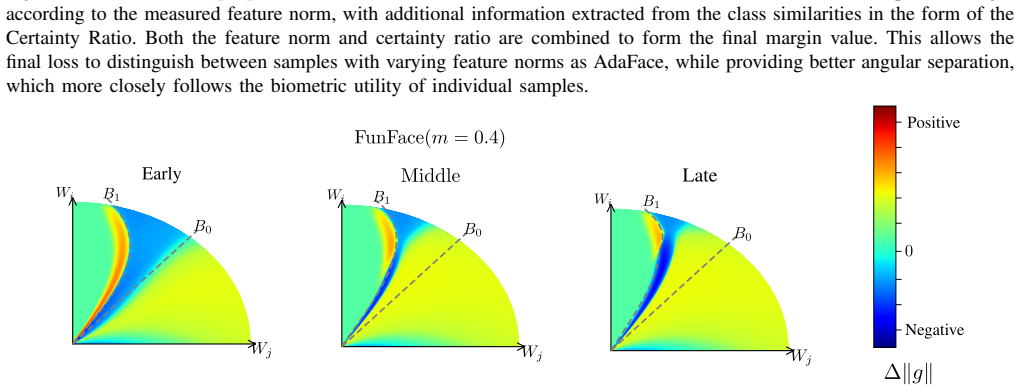
Face Recognition (FR) is used in a variety of application domains, from entertainment and banking to security and surveillance. Such applications rely on the FR model to be robust and perform well in a variety of settings. To achieve this, state-of-the-art FR models typically use expressive adaptive margin loss functions, which tie the feature norm to concepts related to sample quality, such as recognizability and perceptual image quality. Recently, through the development of Face Image Quality Assessment (FIQA) techniques, biometric utility has become the preferred measure of face-image quality and has been shown to be a better predictor of the usefulness of samples for face recognition compared to more human-centric aspects, such as resolution, blur, and lighting, tied to general image quality. While image quality expressed through feature norms exhibits a certain level of correlation with biometric utility, it does not fully encapsulate all aspects of utility. To address this point, we propose a new adaptive margin loss, FunFace (Face Recognition Through Utility and Norm Estimation), which incorporates biometric utility, estimated by the Certainty Ratio, into the adaptive margin, taking inspiration from AdaFace. We show that FunFace (when used to train a face recognition model) achieves competitive results to other state-of-the-art FR models on benchmarks containing high-quality samples, while surpassing them on low quality benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FunFace, a new adaptive margin loss for face recognition training that incorporates an estimate of biometric utility (via a Certainty Ratio) into the margin term, extending the AdaFace approach. The central claim is that models trained with FunFace achieve competitive results against state-of-the-art FR models on high-quality benchmarks while surpassing them on low-quality benchmarks.
Significance. If the performance claims are substantiated with quantitative results and ablations, the work could contribute to more robust FR training by addressing limitations of feature-norm-based quality signals, potentially improving generalization on real-world low-quality imagery. The approach builds on established adaptive-margin ideas and FIQA concepts, but its novelty hinges on demonstrating that the utility term provides an independent, beneficial signal.
major comments (3)
- [Abstract] Abstract: The central performance claim (competitive on high-quality benchmarks, superior on low-quality) is stated without any quantitative numbers, error bars, dataset names, or baseline comparisons. This absence is load-bearing because the abstract is the only evidence provided for the result; without these details the claim cannot be evaluated.
- [Method] Method (Certainty Ratio definition): The manuscript does not supply a derivation, formula, or correlation analysis showing that the Certainty Ratio is independent of the backbone feature norms and training dynamics. If the ratio is computed from the same model features or post-hoc on the test distribution, the reported gains could arise from implicit margin scaling or data selection rather than genuine utility estimation (directly addressing the circularity concern).
- [Experiments] Experiments: No ablation isolating the utility term from other training choices (e.g., margin scaling alone, data filtering) is described, nor are specific low-quality benchmarks, metrics (e.g., TAR@FAR), or statistical significance tests reported. This omission prevents verification that the utility incorporation produces the claimed gains without instabilities.
minor comments (1)
- [Abstract] The abstract refers to 'benchmarks containing high-quality samples' and 'low quality benchmarks' without naming them or citing prior work; adding explicit dataset references would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment in detail below and indicate where revisions will be made to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim (competitive on high-quality benchmarks, superior on low-quality) is stated without any quantitative numbers, error bars, dataset names, or baseline comparisons. This absence is load-bearing because the abstract is the only evidence provided for the result; without these details the claim cannot be evaluated.
Authors: We agree that incorporating specific quantitative details would strengthen the abstract and facilitate evaluation. In the revised manuscript, we will update the abstract to reference key results from the experiments, including verification rates on high-quality benchmarks such as LFW and CFP-FP, improvements on low-quality benchmarks, and direct comparisons to baselines including AdaFace, while preserving conciseness. revision: yes
-
Referee: [Method] Method (Certainty Ratio definition): The manuscript does not supply a derivation, formula, or correlation analysis showing that the Certainty Ratio is independent of the backbone feature norms and training dynamics. If the ratio is computed from the same model features or post-hoc on the test distribution, the reported gains could arise from implicit margin scaling or data selection rather than genuine utility estimation (directly addressing the circularity concern).
Authors: We will expand the Method section to include the explicit formula and derivation of the Certainty Ratio. We will also add a correlation analysis between the Certainty Ratio and feature norms computed across multiple backbones and training epochs. This analysis will show that the Certainty Ratio captures biometric utility aspects not fully explained by norms, addressing potential circularity by demonstrating its independent contribution to the adaptive margin. revision: yes
-
Referee: [Experiments] Experiments: No ablation isolating the utility term from other training choices (e.g., margin scaling alone, data filtering) is described, nor are specific low-quality benchmarks, metrics (e.g., TAR@FAR), or statistical significance tests reported. This omission prevents verification that the utility incorporation produces the claimed gains without instabilities.
Authors: We acknowledge this gap and will revise the Experiments section to include targeted ablations that isolate the utility term by comparing FunFace to a norm-only margin variant and a data-filtering baseline. We will explicitly identify the low-quality benchmarks (quality-stratified subsets of IJB-C and similar real-world datasets), report metrics such as TAR at low FAR thresholds, and add error bars with statistical significance testing to confirm stability and attribute gains to the utility component. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The provided abstract and context describe FunFace as an adaptive margin loss that incorporates an independently motivated biometric-utility estimate (Certainty Ratio) into an AdaFace-style formulation. No equations, definitions, or derivation steps are supplied that reduce the utility term to the feature norms, training dynamics, or fitted parameters of the model being trained. The claim of improved low-quality performance is presented as an empirical outcome rather than a mathematical identity. Absent explicit self-referential definitions or load-bearing self-citations that collapse the central premise, the derivation chain does not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Biometric utility estimated by the Certainty Ratio is a better predictor of sample usefulness for face recognition than general image quality measures.
Reference graph
Works this paper leans on
-
[1]
X. An, X. Zhu, Y . Gao, Y . Xiao, Y . Zhao, Z. Feng, L. Wu, B. Qin, M. Zhang, D. Zhang, et al. Partial FC: Training 10 Million Identities on a Single Machine. InProceedings of the CVF/IEEE International Conference on Computer Vision (ICCV), pages 1445–1449, 2021
2021
- [2]
-
[3]
Babnik, P
ˇZ. Babnik, P. Peer, and V . ˇStruc. FaceQAN: Face Image Quality Assessment through Adversarial Noise Exploration. InProceedings of the IAPR International Conference on Pattern Recognition (ICPR), pages 748–754, 2022
2022
-
[4]
Babnik, P
ˇZ. Babnik, P. Peer, and V . ˇStruc. eDifFIQA: Towards Efficient Face Image Quality Assessment Based on Denoising Diffusion Probabilistic Models.IEEE Transactions on Biometrics, Behavior, and Identity Science (TBIOM), 6(4):458–474, 2024
2024
-
[5]
Boutros, N
F. Boutros, N. Damer, F. Kirchbuchner, and A. Kuijper. ElasticFace: Elastic Margin Loss for Deep Face Recognition. InProceedings of the CVF/IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2022
2022
-
[6]
Boutros, M
F. Boutros, M. Fang, M. Klemt, B. Fu, and N. Damer. CR-FIQA: Face Image Quality Assessment by Learning Sample Relative Classi- fiability. InProceedings of the CVF/IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[7]
Cheng, X
Z. Cheng, X. Zhu, and S. Gong. Low-Resolution Face Recognition. InProceedings of the Asian Conference on Computer Vision (ACCV), pages 605–621. Springer, 2018
2018
- [8]
-
[9]
Cornett, J
D. Cornett, J. Brogan, N. Barber, D. Aykac, S. Baird, N. Burchfield, C. Dukes, A. Duncan, R. Ferrell, J. Goddard, et al. Expanding Accurate Person Recognition to New Altitudes and Ranges: The Briar Dataset. InProceedings of the CVF/IEEE Winter Conference on Applications of Computer Vision (WACV), pages 593–602, 2023
2023
-
[10]
J. Deng, J. Guo, E. Ververas, I. Kotsia, and S. Zafeiriou. RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. InProceedings of the CVF/IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pages 5203–5212, 2020
2020
-
[11]
J. Deng, J. Guo, N. Xue, and S. Zafeiriou. Arcface: Additive Angular Margin Loss for Deep Face Recognition. InProceedings of the CVF/IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pages 4690–4699, 2019
2019
-
[12]
J. Deng, J. Guo, J. Yang, A. Lattas, and S. Zafeiriou. Variational Prototype Learning for Deep Face Recognition. InProceedings of the CVF/IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 11906–11915, 2021
2021
-
[13]
J. Deng, J. Guo, D. Zhang, Y . Deng, X. Lu, and S. Shi. Lightweight Face Recognition Challenge. InProceedings of the CVF/IEEE International Conference on Computer Vision Workshops (ICCVW), pages 0–0, 2019
2019
-
[14]
H. Du, H. Shi, D. Zeng, X.-P. Zhang, and T. Mei. The Elements of End-to-End Deep Face Recognition: A Survey of Recent Advances. ACM computing surveys (CSUR), 54(10s):1–42, 2022
2022
-
[15]
Y . Guo, L. Zhang, Y . Hu, X. He, and J. Gao. MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition. InProceedings of the European Conference on Computer Vision (ECCV), pages 87–102. Springer, 2016
2016
-
[16]
K. He, X. Zhang, S. Ren, and J. Sun. Deep Residual Learning for Image Recognition. InProceedings of the CVF/IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
2016
-
[17]
Hernandez-Ortega, J
J. Hernandez-Ortega, J. Galbally, J. Fierrez, R. Haraksim, and L. Beslay. FaceQnet: Quality Assessment for Face Recognition Based on Deep Learning. InProceedings of the IAPR International Conference on Biometrics (ICB), pages 1–8, 2019
2019
-
[18]
G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. Technical Report 07-49, University of Massachusetts, Amherst, October 2007
2007
-
[19]
Huang, Y
Y . Huang, Y . Wang, Y . Tai, X. Liu, P. Shen, S. Li, J. Li, and F. Huang. CurricularFace: Adaptive Curriculum Learning Loss for Deep Face Recognition. InProceedings of the CVF/IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pages 5901–5910, 2020
2020
-
[20]
Standard, Interna- tional Organization for Standardization (ISO), 2022
ISO/IEC DIS 29794-1, Biometric Sample Quality. Standard, Interna- tional Organization for Standardization (ISO), 2022
2022
-
[21]
Kalra, M
I. Kalra, M. Singh, S. Nagpal, R. Singh, M. Vatsa, and P. Sujit. DroneSURF: Benchmark Dataset for Drone-Based Face Recognition. InProceedings of the IEEE International Conference on Automatic Face & Gesture Recognition (FG), pages 1–7. IEEE, 2019
2019
-
[22]
M. Kim, A. K. Jain, and X. Liu. AdaFace: Quality Adaptive Margin for Face Recognition. InProceedings of the CVF/IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pages 18750–18759, 2022
2022
-
[23]
Y . Kim, W. Park, and J. Shin. BroadFace: Looking at Tens of Thousands of People at Once for Face Recognition. InProceedings of the European Conference on Computer Vision (ECCV), pages 536–
-
[24]
Knoche, S
M. Knoche, S. Hormann, and G. Rigoll. Cross-Quality LFW: A Database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments. InProceedings of the IEEE Interna- tional Conference on Automatic Face and Gesture Recognition (FG), pages 1–5, 2021
2021
-
[25]
W. Liu, Y . Wen, Z. Yu, M. Li, B. Raj, and L. Song. Sphereface: Deep Hypersphere Embedding for Face Recognition. InProceedings of the CVF/IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 212–220, 2017
2017
-
[26]
X. Liu, J. Van De Weijer, and A. D. Bagdanov. RankIQA: Learning from Rankings for No-Reference Image Quality Assessment. In Proceedings of the CVF/IEEE International Conference on Computer Vision (ICCV), pages 1040–1049, 2017
2017
-
[27]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo. SWIN Transformer: Hierarchical Vision Transformer Using Shifted Windows. InProceedings of the CVF/IEEE International Conference on Computer Vision, pages 10012–10022, 2021
2021
-
[28]
B. Maze, J. Adams, J. A. Duncan, N. Kalka, T. Miller, C. Otto, A. K. Jain, W. T. Niggel, J. Anderson, J. Cheney, et al. IARPA Janus Benchmark-C: Face Dataset and Protocol. InProceedings of the International Conference on Biometrics (ICB), pages 158–165, 2018
2018
-
[29]
Q. Meng, S. Zhao, Z. Huang, and F. Zhou. MagFace: A Universal Representation for Face Recognition and Quality Assessment. In Proceedings of the CVF/IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pages 14225–14234, 2021
2021
-
[30]
Mittal, A
A. Mittal, A. K. Moorthy, and A. C. Bovik. No-Reference Image Quality Assessment in the Spatial Domain.IEEE Transactions on Image Processing (TIP), 21(12):4695–4708, 2012
2012
-
[31]
Completely Blind
A. Mittal, R. Soundararajan, and A. C. Bovik. Making a “Completely Blind” Image Quality Analyzer.IEEE Signal Processing Letters (SPL), 20(3):209–212, 2012
2012
-
[32]
Moschoglou, A
S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia, and S. Zafeiriou. AgeDB: the First Manually Collected, in-the-Wild Age Database. InProceedings of the CVF/IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 51–59, 2017
2017
-
[33]
Narayan, N
K. Narayan, N. G. Nair, J. Xu, R. Chellappa, and V . M. Patel. PetalFace: Parameter Efficient Transfer Learning for Low-Resolution Face Recognition. InProceedings of the CVF/IEEE Winter Conference on Applications of Computer Vision (WACV), pages 804–814. IEEE, 2025
2025
-
[34]
F.-Z. Ou, X. Chen, R. Zhang, Y . Huang, S. Li, J. Li, Y . Li, L. Cao, and Y .-G. Wang. SDD-FIQA: Unsupervised Face Image Quality Assessment with Similarity Distribution Distance. InProceedings of the CVF/IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pages 7670–7679, 2021
2021
-
[35]
F.-Z. Ou, C. Li, S. Wang, and S. Kwong. CLIB-FIQA: Face Image Quality Assessment with Confidence Calibration. InProceedings of the CVF/IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 1694–1704, 2024
2024
-
[36]
Schlett, C
T. Schlett, C. Rathgeb, O. Henniger, J. Galbally, J. Fierrez, and C. Busch. Face Image Quality Assessment: A Literature Survey.ACM Computing Surveys (CSUR), 54(10s):1–49, 2022
2022
-
[37]
T. Schlett, C. Rathgeb, J. Tapia, and C. Busch. Considerations on the Evaluation of Biometric Quality Assessment Algorithms.arXiv preprint arXiv:2303.13294, 2023
-
[38]
Schroff, D
F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A Unified Embedding for Face Recognition and Clustering. InProceedings of the CVF/IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 815–823, 2015
2015
-
[39]
Sengupta, J
S. Sengupta, J. C. Cheng, C. D. Castillo, V . M. Patel, R. Chellappa, and D. W. Jacobs. Frontal to Profile Face Verification in the Wild. InProceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), 2016
2016
-
[40]
Y . Shi, X. Yu, K. Sohn, M. Chandraker, and A. K. Jain. Towards Universal Representation Learning for Deep Face Recognition. In Proceedings of the CVF/IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6817–6826, 2020
2020
-
[41]
Terhorst, J
P. Terhorst, J. N. Kolf, N. Damer, F. Kirchbuchner, and A. Kuijper. SER-FIQ: Unsupervised Estimation of Face Image Quality Based on Stochastic Embedding Robustness. InProceedings of the CVF/IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pages 5651–5660, 2020
2020
-
[42]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is All You Need. Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
2017
-
[43]
H. Wang, Y . Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu. CosFace: Large Margin Cosine Loss for Deep Face Recognition. In Proceedings of the CVF/IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pages 5265–5274, 2018
2018
-
[44]
X. Wang, S. Zhang, S. Wang, T. Fu, H. Shi, and T. Mei. Mis-classified Vector Guided Softmax Loss for Face Recognition. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 12241–12248, 2020
2020
-
[45]
Xiang and G
J. Xiang and G. Zhu. Joint Face Detection and Facial Expression Recognition with MTCNN. In2017 4th International Conference on Information Science and Control Engineering (ICISCE), pages 424–
-
[46]
Zheng and W
T. Zheng and W. Deng. Cross-Pose LFW: A Database for Studying Cross-Pose Face Recognition in Unconstrained Environments. Techni- cal Report 18-01, Beijing University of Posts and Telecommunications, February 2018
2018
-
[47]
Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environments
T. Zheng, W. Deng, and J. Hu. Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environ- ments.CoRR, abs/1708.08197, 2017
work page Pith review arXiv 2017
-
[48]
Z. Zhu, G. Huang, J. Deng, Y . Ye, J. Huang, X. Chen, J. Zhu, T. Yang, J. Lu, D. Du, et al. WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition. InProceedings of the CVF/IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 10492–10502, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.