Recognition: unknown
SAGE: A Strategy-Aware Graph-Enhanced Generation Framework For Online Counseling
Pith reviewed 2026-05-07 13:28 UTC · model grok-4.3
The pith
SAGE framework integrates a heterogeneous graph of psychological knowledge with conversation dynamics to guide LLMs in selecting and generating appropriate therapeutic strategies for online counseling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
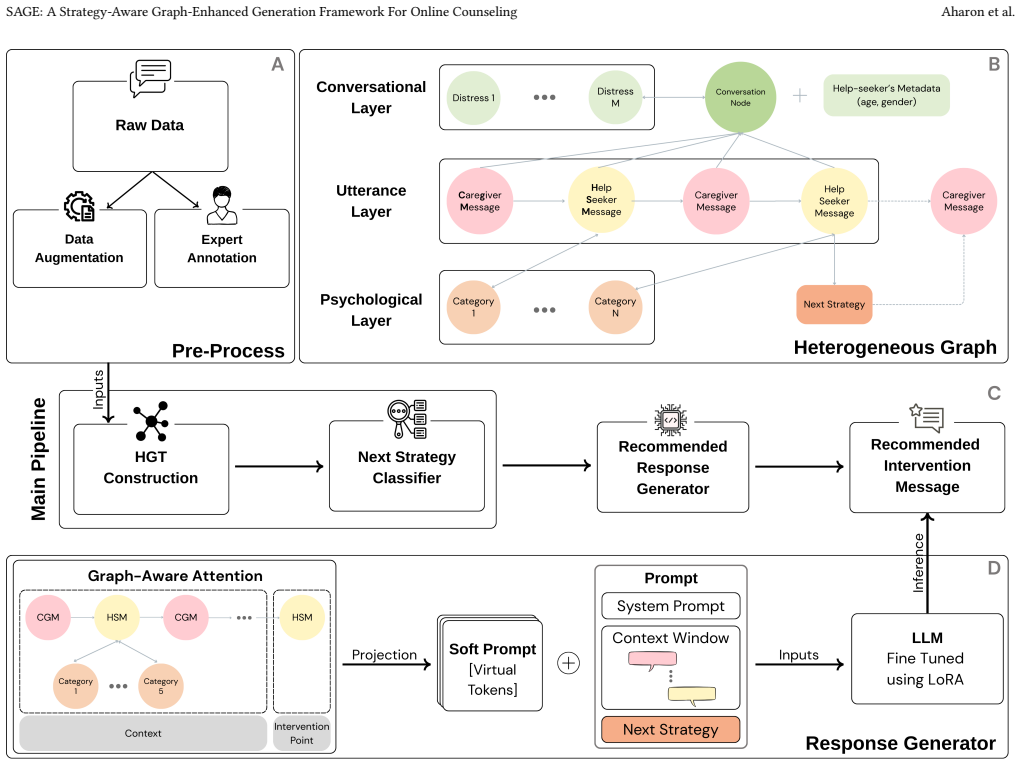
SAGE constructs a heterogeneous graph that unifies conversational dynamics with a psychologically grounded layer, explicitly anchoring interactions in a theory-driven lexicon. The architecture first employs a Next Strategy Classifier to identify the optimal therapeutic intervention. A Graph-Aware Attention mechanism then projects graph-derived structural signals into soft prompts that condition the LLM to generate responses maintaining clinical depth. Validated through automated metrics and expert human evaluation, SAGE outperforms baselines in strategy prediction and recommended response quality, serving as a decision-support tool for high-stakes crisis counseling.
What carries the argument
The heterogeneous graph unifying conversational dynamics with a psychologically grounded lexicon, paired with the Next Strategy Classifier and Graph-Aware Attention to condition LLM generation.
If this is right
- The framework improves accuracy in predicting the next therapeutic strategy over baseline methods.
- Generated response recommendations receive higher quality ratings from clinical experts.
- The system functions as a real-time decision-support aid that augments rather than replaces human counselors.
- Both automated metrics and human evaluation confirm gains in strategy prediction and response quality.
Where Pith is reading between the lines
- The same graph-plus-classifier pattern could be tested in other regulated dialogue domains such as legal intake or educational advising where strategy selection matters.
- Explicit anchoring to a theory lexicon may reduce certain forms of hallucination in safety-critical generation tasks.
- Live deployment trials could measure whether counselor response time or burnout decreases when SAGE suggestions are available as optional prompts.
Load-bearing premise
The heterogeneous graph and next strategy classifier can reliably capture and apply clinical reasoning in real-time distress scenarios without introducing bias or unsafe suggestions.
What would settle it
Expert human raters score SAGE responses as less safe or less therapeutically appropriate than either standard LLM outputs or actual human counselor replies when both are tested on the same set of simulated crisis dialogues.
Figures


read the original abstract
Effective mental health counseling is a complex, theory-driven process requiring the simultaneous integration of psychological frameworks, real-time distress signals, and strategic intervention planning. This level of clinical reasoning is critical for safety and therapeutic effectiveness but is often missing in general-purpose Large Language Models (LLMs). We introduce SAGE (Strategy-Aware Graph-Enhanced), a novel framework designed to bridge the gap between structured clinical knowledge and generative AI. SAGE constructs a heterogeneous graph that unifies conversational dynamics with a psychologically grounded layer, explicitly anchoring interactions in a theory-driven lexicon. Our architecture first employs a Next Strategy Classifier to identify the optimal therapeutic intervention. Subsequently, a Graph-Aware Attention mechanism projects graph-derived structural signals into soft prompts, conditioning the LLM to generate responses that maintain clinical depth. Validated through both automated metrics and expert human evaluation, SAGE outperforms baselines in strategy prediction and recommended response quality. By providing actionable intervention recommendations, SAGE serves as a cutting-edge decision-support tool designed to augment human expertise in high-stakes crisis counseling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAGE, a framework for online counseling that constructs a heterogeneous graph unifying conversational dynamics with a psychologically grounded lexicon. It employs a Next Strategy Classifier to predict the optimal therapeutic intervention and a Graph-Aware Attention mechanism to project graph signals as soft prompts conditioning an LLM for response generation. The authors claim that SAGE outperforms baselines on automated metrics for strategy prediction and on expert human evaluation for response quality, positioning it as a decision-support tool for crisis counseling.
Significance. If the empirical claims hold under rigorous validation, the work would be significant for computational linguistics and AI applications in mental health by demonstrating how graph-structured clinical knowledge can be integrated into LLM generation to improve strategy adherence and safety. The explicit anchoring in theory-driven lexicons and the two-stage classifier-plus-attention design offer a concrete path beyond generic prompting, with potential for reproducible decision-support systems if the generalization properties are established.
major comments (3)
- [§4] §4 (Experiments): The manuscript reports outperformance on strategy prediction and response quality but provides no details on dataset construction, annotation protocol, train/test split criteria, or statistical significance testing. Without these, it is impossible to assess whether the Next Strategy Classifier generalizes beyond the training distribution to unseen distress patterns, which is load-bearing for the central claim that the framework reliably maps real-time dynamics onto clinically grounded interventions.
- [§3.2] §3.2 (Next Strategy Classifier): The description of the classifier does not specify its training objective, feature set, or whether strategy labels were derived from the same annotated dialogues later used in evaluation. This raises a risk that performance gains are partly circular, as the Graph-Aware Attention would then condition the LLM on predictions that are not independently validated against held-out clinical scenarios.
- [§3.1] §3.1 (Heterogeneous Graph Construction): The paper asserts that the graph explicitly anchors interactions in a theory-driven lexicon, yet no ablation is reported that isolates the contribution of the psychological layer versus purely conversational edges. If the lexicon component is not load-bearing, the claimed advantage over standard graph-augmented LLMs would be overstated.
minor comments (2)
- [§3.3] The abstract and introduction use the term 'soft prompts' without clarifying whether these are learned embeddings, attention-weighted node features, or prompt tokens; a short formal definition in §3.3 would improve clarity.
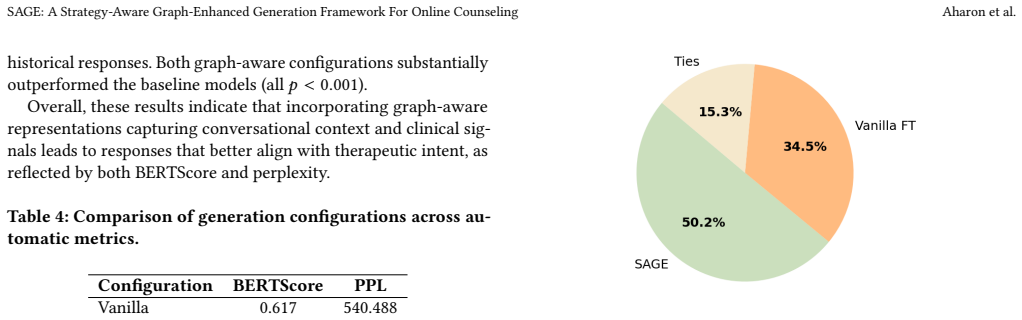
- [Figure 1] Figure 1 (architecture diagram) and Table 2 (metric results) are referenced but the caption text does not list the exact baselines or the number of expert raters; adding these details would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our submission. We provide point-by-point responses to the major comments below, indicating where revisions will be made to address the concerns raised.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The manuscript reports outperformance on strategy prediction and response quality but provides no details on dataset construction, annotation protocol, train/test split criteria, or statistical significance testing. Without these, it is impossible to assess whether the Next Strategy Classifier generalizes beyond the training distribution to unseen distress patterns, which is load-bearing for the central claim that the framework reliably maps real-time dynamics onto clinically grounded interventions.
Authors: We acknowledge the need for greater transparency in the experimental setup. In the revised manuscript, we will expand Section 4 to include full details on dataset construction from anonymized online counseling dialogues, the annotation protocol conducted by domain experts using the theory-driven lexicon, the criteria for train/test splits (ensuring temporal and thematic separation for generalization testing), and statistical significance testing via bootstrap resampling and paired tests. These additions will directly address concerns about generalization to unseen distress patterns. revision: yes
-
Referee: [§3.2] §3.2 (Next Strategy Classifier): The description of the classifier does not specify its training objective, feature set, or whether strategy labels were derived from the same annotated dialogues later used in evaluation. This raises a risk that performance gains are partly circular, as the Graph-Aware Attention would then condition the LLM on predictions that are not independently validated against held-out clinical scenarios.
Authors: To clarify, the Next Strategy Classifier employs a cross-entropy loss objective and integrates features from both dialogue embeddings and graph node representations. Strategy labels originate from the annotated dialogues, but we maintain a strict held-out test set for final evaluation of the classifier and the downstream generation, separate from any data used in attention conditioning. We will revise §3.2 to explicitly document the training objective, feature set, and data separation protocol to rule out circularity concerns. revision: yes
-
Referee: [§3.1] §3.1 (Heterogeneous Graph Construction): The paper asserts that the graph explicitly anchors interactions in a theory-driven lexicon, yet no ablation is reported that isolates the contribution of the psychological layer versus purely conversational edges. If the lexicon component is not load-bearing, the claimed advantage over standard graph-augmented LLMs would be overstated.
Authors: We agree that an ablation study would better isolate the value of the psychologically grounded lexicon. Although the current manuscript highlights its role in anchoring the graph, we will add an ablation analysis in the experiments section of the revised version. This will compare the full heterogeneous graph against a conversational-edges-only variant, reporting impacts on both strategy prediction and response quality to substantiate the lexicon's contribution. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents SAGE as a composite framework that first trains a Next Strategy Classifier on annotated dialogues and then uses graph-derived signals as soft prompts for an LLM. No equations, self-citations, or training procedures are shown that reduce the reported strategy predictions or response-quality gains to the input labels by construction. The claimed outperformance rests on separate automated metrics and expert human evaluation, which constitute independent evidence rather than a renaming or refitting of the training data itself. The derivation chain therefore remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conversational dynamics and psychological frameworks can be unified in a single heterogeneous graph that anchors interactions in a theory-driven lexicon
invented entities (2)
-
Next Strategy Classifier
no independent evidence
-
Graph-Aware Attention mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tim Althoff, Kevin Clark, and Jure Leskovec. 2016. Large-scale analysis of counseling conversations: An application of natural language processing to mental health.Transactions of the Association for Computational Linguistics4 (2016), 463–476
2016
-
[2]
Amir Bialer, Daniel Izmaylov, Avi Segal, Oren Tsur, Yossi Levi-Belz, and Kobi Gal
-
[3]
InProceedings-International Conference on Computational Linguistics, COLING, Vol
Detecting Suicide Risk in Online Counseling Services: A Study in a Low- Resource Language. InProceedings-International Conference on Computational Linguistics, COLING, Vol. 29. 4241–4250
-
[4]
Yang Deng, Lizi Liao, Wenqiang Lei, Grace Hui Yang, Wai Lam, and Tat-Seng Chua
-
[5]
Proactive conversational ai: A comprehensive survey of advancements and opportunities.ACM Transactions on Information Systems43, 3 (2025), 1–45
2025
-
[6]
Yang Deng, Wenxuan Zhang, Yifei Yuan, and Wai Lam. 2023. Knowledge- enhanced Mixed-initiative Dialogue System for Emotional Support Conversations. InThe 61st Annual Meeting Of The Association For Computational Linguistics
2023
-
[7]
Changzeng Fu, Yikai Su, Kaifeng Su, Yinghao Liu, Jiaqi Shi, Bowen Wu, Chaoran Liu, Carlos Toshinori Ishi, and Hiroshi Ishiguro. 2025. HAM-GNN: A hierarchical attention-based multi-dimensional edge graph neural network for dialogue act classification.Expert Systems with Applications261 (2025), 125459
2025
-
[8]
Chris Gaskell, Melanie Simmonds-Buckley, Stephen Kellett, C Stockton, Erin Somerville, Emily Rogerson, and Jaime Delgadillo. 2023. The effectiveness of psychological interventions delivered in routine practice: systematic review and meta-analysis.Administration and Policy in Mental Health and Mental Health Services Research50, 1 (2023), 43–57
2023
-
[9]
Meytal Grimland, Joy Benatov, Hadas Yeshayahu, Daniel Izmaylov, Avi Segal, Kobi Gal, and Yossi Levi-Belz. 2024. Predicting suicide risk in real-time crisis hotline chats integrating machine learning with psychological factors: Exploring the black box.Suicide and Life-Threatening Behavior54, 3 (2024), 416–424
2024
-
[10]
Zhijun Guo, Alvina Lai, Johan H Thygesen, Joseph Farrington, Thomas Keen, Kezhi Li, et al . 2024. Large language models for mental health applications: systematic review.JMIR mental health11, 1 (2024), e57400
2024
-
[11]
Thomas F Heston. 2023. Safety of large language models in addressing depression. Cureus15, 12 (2023)
2023
-
[12]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[13]
Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. 2020. Heterogeneous graph transformer. InProceedings of the web conference 2020. 2704–2710
2020
-
[14]
Daniel Izmaylov, Avi Segal, Kobi Gal, Meytal Grimland, and Yossi Levi-Belz
-
[15]
InFindings of the Association for Computational Linguistics: EACL 2023
Combining psychological theory with language models for suicide risk detection. InFindings of the Association for Computational Linguistics: EACL 2023. 2430–2438
2023
-
[16]
Dongjin Kang, Sunghwan Mac Kim, Taeyoon Kwon, Seungjun Moon, Hyunsouk Cho, Youngjae Yu, Dongha Lee, and Jinyoung Yeo. 2024. Can large language models be good emotional supporter? mitigating preference bias on emotional support conversation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1...
2024
-
[17]
Kurt Kroenke, Robert L Spitzer, and Janet BW Williams. 2001. The PHQ-9: validity of a brief depression severity measure.Journal of general internal medicine16, 9 (2001), 606–613
2001
-
[18]
Yossi Levi-Belz, Meytal Grimland, Yael Segal-Elbak, Noam Munz, Hadas Yeshayahu, Joy Benatov, Avi Segal, Loona Ben Dayan, Inbar Shenfeld, and Kobi Gal. 2025. Predicting imminent suicide risk in a crisis hotline chat using machine learning.Scientific Reports15, 1 (2025), 44742
2025
-
[19]
Siyang Liu, Chujie Zheng, Orianna Demasi, Sahand Sabour, Yu Li, Zhou Yu, Yong Jiang, and Minlie Huang. 2021. Towards Emotional Support Dialog Systems. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Pro- cessing (Volume 1: Long Papers), Chengqing Zong...
-
[20]
Ganeshan Malhotra, Abdul Waheed, Aseem Srivastava, Md Shad Akhtar, and Tanmoy Chakraborty. 2022. Speaker and time-aware joint contextual learning for dialogue-act classification in counselling conversations. InProceedings of the fifteenth ACM international conference on web search and data mining. 735–745
2022
-
[21]
Yang Ni and Fanli Jia. 2025. A scoping review of AI-Driven digital interventions in mental health care: mapping applications across screening, support, monitoring, prevention, and clinical education. InHealthcare, Vol. 13. MDPI, 1205
2025
- [22]
-
[23]
K Posner. 2008. Columbia-Suicide Severity Rating Scale (C-SSRS).Columbia University Medical Center(2008)
2008
-
[24]
Amit Seker, Elron Bandel, Dan Bareket, Idan Brusilovsky, Refael Greenfeld, and Reut Tsarfaty. 2022. AlephBERT: Language model pre-training and evaluation from sub-word to sentence level. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 46–56
2022
-
[25]
Giuseppe Spillo, Francesco Bottalico, Cataldo Musto, Marco De Gemmis, Pasquale Lops, and Giovanni Semeraro. 2024. Evaluating Content-based Pre-Training Strategies for a Knowledge-aware Recommender System based on Graph Neural Networks. InProceedings of the 32nd ACM Conference on User Modeling, Adaptation and Personalization. 165–171
2024
- [26]
-
[27]
Chen Tang, Hongbo Zhang, Tyler Loakman, Bohao Yang, Stefan Goetze, and Chenghua Lin. 2024. CADGE: Context-Aware Dialogue Generation Enhanced with Graph-Structured Knowledge Aggregation. InProceedings of the 17th Inter- national Natural Language Generation Conference, Saad Mahamood, Nguyen Le Minh, and Daphne Ippolito (Eds.). Association for Computational ...
-
[28]
Gemma Team. 2025. Gemma 3. (2025). https://goo.gle/Gemma3Report
2025
-
[29]
Yijun Tian, Huan Song, Zichen Wang, Haozhu Wang, Ziqing Hu, Fang Wang, Nitesh V Chawla, and Panpan Xu. 2024. Graph neural prompting with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19080–19088
2024
-
[30]
Chris Van der Lee, Albert Gatt, Emiel Van Miltenburg, and Emiel Krahmer. 2021. Human evaluation of automatically generated text: Current trends and best practice guidelines.Computer Speech & Language67 (2021), 101151
2021
-
[31]
Kimberly A Van Orden, Kelly C Cukrowicz, Tracy K Witte, and Thomas E Joiner Jr
-
[32]
Psychological assessment24, 1 (2012), 197
Thwarted belongingness and perceived burdensomeness: construct va- lidity and psychometric properties of the Interpersonal Needs Questionnaire. Psychological assessment24, 1 (2012), 197
2012
-
[33]
Hongru Wang, Rui Wang, Fei Mi, Yang Deng, Zezhong Wang, Bin Liang, Ruifeng Xu, and Kam-Fai Wong. 2023. Cue-CoT: Chain-of-thought Prompting for Re- sponding to In-depth Dialogue Questions with LLMs. InFindings of the Associ- ation for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Ling...
-
[34]
Anuradha Welivita and Pearl Pu. 2022. Heal: A knowledge graph for distress management conversations. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 11459–11467
2022
-
[35]
Haojie Xie, Yirong Chen, Xiaofen Xing, Jingkai Lin, and Xiangmin Xu. 2025. Psydt: Using llms to construct the digital twin of psychological counselor with personalized counseling style for psychological counseling. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1081–1115
2025
-
[36]
Zhongzhi Xu, Yucan Xu, Florence Cheung, Mabel Cheng, Daniel Lung, Yik Wa Law, Byron Chiang, Qingpeng Zhang, and Paul SF Yip. 2021. Detecting suicide risk using knowledge-aware natural language processing and counseling service data.Social science & medicine283 (2021), 114176
2021
-
[37]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675(2019)
work page internal anchor Pith review arXiv 2019
-
[38]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2023. A Survey of Large Language Models.arXiv preprint arXiv:2303.18223(2023...
work page internal anchor Pith review arXiv 2023
- [39]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.