Recognition: unknown
What Makes Software Bugs Escape Testing? Evidence from a Large-Scale Empirical Study
Pith reviewed 2026-05-07 13:13 UTC · model grok-4.3
The pith
Post-release defects concentrate in older, high-churn code components and take longer, more complex fixes than pre-release ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Residual faults that escape testing and surface post-release are concentrated in older, frequently modified, and high-churn components, and they typically require longer and more complex fixes than pre-release defects. These arise more from evolutionary and process dynamics than from code structure alone.
What carries the argument
Broad suite of software metrics on complexity, size, structure, and development history used to classify and compare pre- versus post-release defects across large systems.
If this is right
- Testing should prioritize mature, high-churn regions over uniform structural checks.
- Post-release repair effort is systematically higher, affecting maintenance planning.
- Process factors such as modification frequency drive residual defects more than static code properties.
- Defect prediction models gain accuracy by weighting age and churn alongside traditional complexity measures.
Where Pith is reading between the lines
- Continuous monitoring of churn in older modules could reduce escaped defects in ongoing projects.
- Regression test selection might improve by weighting test cases toward high-churn files.
- Similar patterns may appear in closed-source systems if the same classification and metric approach is applied.
Load-bearing premise
Defects can be reliably labeled pre-release or post-release from commit and issue timestamps, and the chosen metrics capture the main influences without large unmeasured confounders.
What would settle it
A large collection of post-release defects appearing in newly added, low-churn components with short fix times would contradict the observed concentration pattern.
Figures


read the original abstract
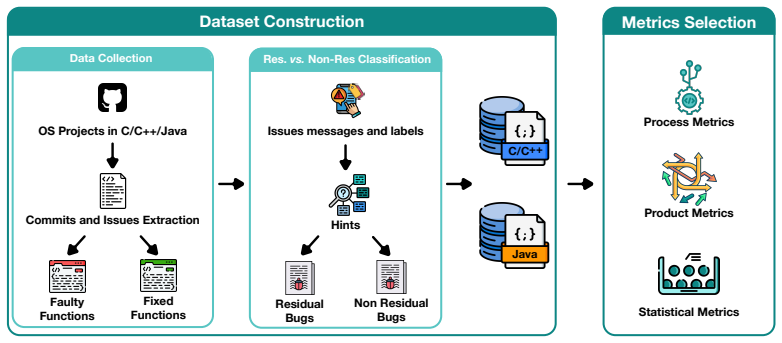
Understanding how software defects manifest and evolve in production environments is critical for improving reliability. While previous research has largely focused on pre-release defects, the nature of residual faults, i.e., those escaping testing and surfacing post-release, remains poorly understood. This paper presents a large-scale characterization of pre- and post-release defects across C/C++ and Java systems, encompassing over 14k defects mined from open-source projects. We employ a broad suite of software metrics to capture diverse code attributes such as complexity, size, structure, and development history. Results show that post-release defects are concentrated in older, frequently modified, and high-churn components, typically requiring longer and more complex fixes than pre-release ones. These findings highlight that residual defects arise more from evolutionary and process dynamics than code structure alone, suggesting that reliability engineering should prioritize targeted testing in mature and complex code regions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a large-scale empirical characterization of over 14,000 pre- and post-release defects mined from C/C++ and Java open-source projects. Using a suite of metrics capturing code complexity, size, structure, and development history, it reports that post-release defects concentrate in older, frequently modified, high-churn components and require longer, more complex fixes than pre-release defects, attributing residual faults primarily to evolutionary and process dynamics rather than static code properties.
Significance. If the central findings hold after addressing classification validity, the work provides a valuable large-scale observational baseline on defect escape in OSS systems. It strengthens the case for prioritizing testing resources on mature, high-churn code regions and adds empirical weight to process-oriented reliability engineering over purely structural approaches.
major comments (2)
- [Data collection and defect classification section] The pre- versus post-release defect classification (described in the data collection and labeling procedure) relies on unvalidated heuristics using commit timestamps, issue dates, and release tags. Without manual validation, sensitivity analysis, or checks for reporting latency and incomplete commit-issue links, mislabeling of even 15-20% of cases could confound the reported differences in component age, modification frequency, churn, and fix complexity—these differences are load-bearing for the headline claim.
- [Results and analysis section] The results section reports directional differences but provides insufficient detail on statistical controls (e.g., project fixed effects, multiple-comparison correction) and data exclusion criteria. This limits verification of whether the observed concentration in high-churn components is robust or driven by unmeasured confounders.
minor comments (2)
- [Abstract] The abstract states 'a broad suite of software metrics' without enumerating them; listing the specific metrics (e.g., in a table) would improve clarity.
- [Discussion] Consider adding explicit threats-to-validity discussion addressing OSS project selection bias and the generalizability of findings beyond the studied C/C++ and Java systems.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to strengthen the validity of our defect classification and the transparency of our statistical analyses.
read point-by-point responses
-
Referee: [Data collection and defect classification section] The pre- versus post-release defect classification (described in the data collection and labeling procedure) relies on unvalidated heuristics using commit timestamps, issue dates, and release tags. Without manual validation, sensitivity analysis, or checks for reporting latency and incomplete commit-issue links, mislabeling of even 15-20% of cases could confound the reported differences in component age, modification frequency, churn, and fix complexity—these differences are load-bearing for the headline claim.
Authors: We acknowledge that our classification procedure relies on heuristics based on commit timestamps, issue dates, and release tags, which is a common approach in large-scale empirical studies of defect escape. To directly address the concern about potential mislabeling, we have added a manual validation step on a stratified random sample of 250 defects (with two independent raters achieving Cohen's kappa of 0.87) and performed sensitivity analyses by varying the pre/post-release time windows by ±7 and ±14 days. The core findings on component age, churn, and fix complexity remain directionally consistent and statistically significant across these checks. We have also added a limitations subsection discussing reporting latency and incomplete links, along with the results of the validation and sensitivity tests. revision: yes
-
Referee: [Results and analysis section] The results section reports directional differences but provides insufficient detail on statistical controls (e.g., project fixed effects, multiple-comparison correction) and data exclusion criteria. This limits verification of whether the observed concentration in high-churn components is robust or driven by unmeasured confounders.
Authors: We agree that additional statistical detail improves verifiability. In the revised manuscript we have expanded the analysis section to explicitly describe: (1) the use of project fixed effects in our regression models to control for unobserved project-level heterogeneity, (2) application of the Benjamini-Hochberg procedure for multiple-comparison correction across the suite of metrics, and (3) precise data exclusion rules (projects with fewer than 50 commits or 10 linked issues were removed; we report the number of excluded cases). We have also included robustness checks that re-run the main analyses after removing the top 5% of high-churn components to assess sensitivity to potential confounders. These additions are now reported with the corresponding model specifications and p-values. revision: yes
Circularity Check
No circularity: purely observational empirical study with no derivations or self-referential reductions
full rationale
The paper is a large-scale empirical characterization of pre- and post-release defects mined from OSS projects, using software metrics on code attributes and development history. Results are presented as direct observational findings (e.g., concentration of post-release defects in older, high-churn components) without any equations, fitted parameters, predictions, or derivations that reduce to the inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing for the central claims. The analysis relies on data mining and statistical comparison, which is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Defects can be accurately labeled pre- or post-release using commit history and issue trackers.
- domain assumption The selected metrics for complexity, size, structure, and history sufficiently represent relevant code attributes.
Reference graph
Works this paper leans on
-
[1]
Ariane 5 flight 501 failure report,
J.-L. Lions and the Inquiry Board, “Ariane 5 flight 501 failure report,” European Space Agency / Arianespace, Tech. Rep., 1996, inquiry Board report on the maiden flight failure, 4 June 1996. [Online]. Available: https://www.esa.int/esamultimedia/esa-x-1819eng.pdf
1996
-
[2]
Mars climate orbiter mishap investigation board phase i report,
N. Mishap Investigation Board, “Mars climate orbiter mishap investigation board phase i report,” National Aeronautics and Space Administration, Tech. Rep., 1999, report on the loss of Mars Climate Orbiter, 23 September 1999. [Online]. Available: https://llis.nasa.gov/llis lib/pdf/1009464main1 0641-mr.pdf
-
[3]
Crowdstrike outage causes financial and op- erational impact: The cost and root cause revealed,
C. Staff, “Crowdstrike outage causes financial and op- erational impact: The cost and root cause revealed,” CNN, July 2024, accessed: 2024-11-21. [Online]. Avail- able: https://www.cnn.com/2024/07/24/tech/crowdstrike-outage-cost- cause/index.html
2024
-
[4]
Software error incident categorizations in aerospace,
L. E. Prokop, “Software error incident categorizations in aerospace,” Journal of Aerospace Information Systems, vol. 21, no. 10, pp. 775– 789, 2024
2024
-
[5]
Magic quadrant for ai code assistants,
Gartner, Inc., “Magic quadrant for ai code assistants,” Gartner, Inc., Tech. Rep., Aug. 2024, strategic Planning Assumptions. [Online]. Available: https://www.gartner.com/en/documents/5682355
-
[6]
From bugs to bench- marks: A comprehensive survey of software defect datasets,
H.-N. Zhu, R. M. Furth, M. Pradel, and C. Rubio-Gonz ´alez, “From bugs to benchmarks: A comprehensive survey of software defect datasets,” arXiv preprint arXiv:2504.17977, 2025
-
[7]
Survey on software defect prediction techniques,
M. K. Thota, F. H. Shajin, P. Rajeshet al., “Survey on software defect prediction techniques,”International Journal of Applied Science and Engineering, vol. 17, no. 4, pp. 331–344, 2020
2020
-
[8]
Anonymous, “Replication Package,” https://doi.org/10.5281/zenodo.19251318
-
[9]
Dependability of computer systems: concepts, limits, improvements,
J.-C. Laprie, “Dependability of computer systems: concepts, limits, improvements,” inProceedings of Sixth International Symposium on Software Reliability Engineering. ISSRE’95, 1995, pp. 2–11
1995
-
[10]
An industrial study on the differences between pre-release and post- release bugs,
R. Rwemalika, M. Kintis, M. Papadakis, Y . Le Traon, and P. Lorrach, “An industrial study on the differences between pre-release and post- release bugs,” in2019 IEEE International Conference on Software Maintenance and Evolution (ICSME), 2019, pp. 92–102
2019
-
[11]
An exploratory study of field failures,
L. Gazzola, L. Mariani, F. Pastore, and M. Pezz `e, “An exploratory study of field failures,” in2017 IEEE 28th International Symposium on Software Reliability Engineering (ISSRE), 2017, pp. 67–77
2017
-
[12]
Nasa study on flight software complexity,
D. Dvorak, “Nasa study on flight software complexity,” inAIAA in- fotech@ aerospace conference and AIAA unmanned... unlimited confer- ence, 2009, p. 1882
2009
-
[13]
Quantitative analysis of faults and failures in a complex software system,
N. E. Fenton and N. Ohlsson, “Quantitative analysis of faults and failures in a complex software system,”IEEE Transactions on Software engineering, vol. 26, no. 8, pp. 797–814, 2002
2002
-
[14]
Explaining failures using software depen- dences and churn metrics,
N. Nagappan and T. Ball, “Explaining failures using software depen- dences and churn metrics,”Microsoft Research, Redmond, WA, 2006
2006
-
[15]
Mining metrics to predict component failures,
N. Nagappan, T. Ball, and A. Zeller, “Mining metrics to predict component failures,” inProceedings of the 28th international conference on Software engineering, 2006, pp. 452–461
2006
-
[16]
Which code construct metrics are symptoms of post release failures?
M. Nagappan, B. Murphy, and M. V ouk, “Which code construct metrics are symptoms of post release failures?” inProceedings of the 2nd International Workshop on Emerging Trends in Software Metrics, 2011, pp. 65–68
2011
-
[17]
Predicting defects for eclipse,
T. Zimmermann, R. Premraj, and A. Zeller, “Predicting defects for eclipse,” inThird international workshop on predictor models in soft- ware engineering (PROMISE’07: ICSE workshops 2007). IEEE, 2007, pp. 9–9
2007
-
[18]
Software fault prediction metrics: A systematic literature review,
D. Radjenovi ´c, M. Heri ˇcko, R. Torkar, and A. ˇZivkoviˇc, “Software fault prediction metrics: A systematic literature review,”Information and software technology, vol. 55, no. 8, pp. 1397–1418, 2013
2013
-
[19]
Are slice-based cohesion metrics actually useful in effort- aware post-release fault-proneness prediction? an empirical study,
Y . Yang, Y . Zhou, H. Lu, L. Chen, Z. Chen, B. Xu, H. Leung, and Z. Zhang, “Are slice-based cohesion metrics actually useful in effort- aware post-release fault-proneness prediction? an empirical study,”IEEE Transactions on Software Engineering, vol. 41, no. 4, pp. 331–357, 2014
2014
-
[20]
Do code review measures explain the incidence of post-release defects? case study replications and bayesian networks,
A. Krutauz, T. Dey, P. C. Rigby, and A. Mockus, “Do code review measures explain the incidence of post-release defects? case study replications and bayesian networks,”Empirical Software Engineering, vol. 25, no. 5, pp. 3323–3356, 2020
2020
-
[21]
Software defects and their impact on system availability-a study of field failures in operating systems,
M. Sullivan and R. Chillarege, “Software defects and their impact on system availability-a study of field failures in operating systems,” in Digest of Papers. Fault-Tolerant Computing: The Twenty-First Interna- tional Symposium. IEEE Computer Society, 1991, pp. 2–3
1991
-
[22]
Emulation of software faults: A field data study and a practical approach,
J. A. Duraes and H. S. Madeira, “Emulation of software faults: A field data study and a practical approach,”Ieee transactions on software engineering, vol. 32, no. 11, pp. 849–867, 2006
2006
-
[23]
On fault representativeness of software fault injection,
R. Natella, D. Cotroneo, J. A. Duraes, and H. S. Madeira, “On fault representativeness of software fault injection,”IEEE Transactions on Software Engineering, vol. 39, no. 1, pp. 80–96, 2013
2013
-
[24]
Pyresbugs: A dataset of residual python bugs for natural language-driven fault injection,
D. Cotroneo, G. De Rosa, and P. Liguori, “Pyresbugs: A dataset of residual python bugs for natural language-driven fault injection,” in2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge), 2025, pp. 146–150
2025
-
[25]
Orthogonal defect classification- a concept for in-process measurements,
R. Chillarege, I. S. Bhandari, J. K. Chaar, M. J. Halliday, D. S. Moebus, B. K. Ray, and M.-Y . Wong, “Orthogonal defect classification- a concept for in-process measurements,”IEEE Transactions on software Engineering, vol. 18, no. 11, pp. 943–956, 1992
1992
-
[26]
Defects4j: a database of existing faults to enable controlled testing studies for java programs,
R. Just, D. Jalali, and M. D. Ernst, “Defects4j: a database of existing faults to enable controlled testing studies for java programs,” in Proceedings of the 2014 International Symposium on Software Testing and Analysis, ser. ISSTA 2014. New York, NY , USA: Association for Computing Machinery, 2014, p. 437–440. [Online]. Available: https://doi.org/10.1145...
-
[27]
The manybugs and introclass benchmarks for automated repair of c programs,
C. Le Goues, N. Holtschulte, E. K. Smith, Y . Brun, P. Devanbu, S. Forrest, and W. Weimer, “The manybugs and introclass benchmarks for automated repair of c programs,”IEEE Transactions on Software Engineering, vol. 41, no. 12, pp. 1236–1256, 2015
2015
-
[28]
Bugs.jar: a large-scale, diverse dataset of real-world java bugs,
R. K. Saha, Y . Lyu, W. Lam, H. Yoshida, and M. R. Prasad, “Bugs.jar: a large-scale, diverse dataset of real-world java bugs,” in Proceedings of the 15th International Conference on Mining Software Repositories, ser. MSR ’18. New York, NY , USA: Association for Computing Machinery, 2018, p. 10–13. [Online]. Available: https://doi.org/10.1145/3196398.3196473
-
[29]
Bugswarm: Mining and continuously growing a dataset of reproducible failures and fixes,
D. A. Tomassi, N. Dmeiri, Y . Wang, A. Bhowmick, Y .-C. Liu, P. T. Devanbu, B. Vasilescu, and C. Rubio-Gonz ´alez, “Bugswarm: Mining and continuously growing a dataset of reproducible failures and fixes,” in 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), 2019, pp. 339–349
2019
-
[30]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?” 2024. [Online]. Available: https://arxiv.org/abs/2310.06770
work page internal anchor Pith review arXiv 2024
-
[31]
J. Sliwerski, T. Zimmermann, and A. Zeller, “When do changes induce fixes?” inProceedings of the 2005 International Workshop on Mining Software Repositories, ser. MSR ’05. New York, NY , USA: Association for Computing Machinery, 2005, p. 1–5. [Online]. Available: https://doi.org/10.1145/1083142.1083147
-
[32]
Mining historical information to study bug fixes,
E. C. Campos and M. A. Maia, “Mining historical information to study bug fixes,” inInformation Technology-New Generations: 14th International Conference on Information Technology. Springer, 2017, pp. 535–543
2017
-
[33]
Characterizing the usage, evolution and impact of java annotations in practice,
Z. Yu, C. Bai, L. Seinturier, and M. Monperrus, “Characterizing the usage, evolution and impact of java annotations in practice,”IEEE Transactions on Software Engineering, vol. 47, no. 5, pp. 969–986, 2019
2019
-
[34]
Tree-sitter code parser,
M. Brunsfeld, “Tree-sitter code parser,” https://tree-sitter.github.io/tree- sitter/
-
[35]
On learning meaningful code changes via neural machine translation,
M. Tufano, J. Pantiuchina, C. Watson, G. Bavota, and D. Poshyvanyk, “On learning meaningful code changes via neural machine translation,” inProceedings of the 41st International Conference on Software Engineering, ser. ICSE ’19. IEEE Press, 2019, p. 25–36. [Online]. Available: https://doi.org/10.1109/ICSE.2019.00021
-
[36]
An empirical study on learning bug-fixing patches in the wild via neural machine translation,
M. Tufano, C. Watson, G. Bavota, M. D. Penta, M. White, and D. Poshyvanyk, “An empirical study on learning bug-fixing patches in the wild via neural machine translation,”ACM Trans. Softw. Eng. Methodol., vol. 28, no. 4, Sep. 2019. [Online]. Available: https://doi.org/10.1145/3340544
-
[37]
Can github issues help in app review classifications?
Y . Abedini and A. Heydarnoori, “Can github issues help in app review classifications?”ACM Trans. Softw. Eng. Methodol., vol. 33, no. 8, Nov. 2024. [Online]. Available: https://doi.org/10.1145/3678170
-
[38]
On the feasibility of au- tomated prediction of bug and non-bug issues,
S. Herbold, A. Trautsch, and F. Trautsch, “On the feasibility of au- tomated prediction of bug and non-bug issues,”Empirical Software Engineering, vol. 25, no. 6, pp. 5333–5369, 2020
2020
-
[39]
Progress on approaches to software defect prediction,
Z. Li, X.-Y . Jing, and X. Zhu, “Progress on approaches to software defect prediction,”Iet Software, vol. 12, no. 3, pp. 161–175, 2018
2018
-
[40]
Software defect prediction: future directions and challenges,
Z. Li, J. Niu, and X.-Y . Jing, “Software defect prediction: future directions and challenges,”Automated Software Engineering, vol. 31, no. 1, p. 19, 2024
2024
-
[41]
On the naturalness of software,
A. Hindle, E. T. Barr, M. Gabel, Z. Su, and P. Devanbu, “On the naturalness of software,”Communications of the ACM, vol. 59, no. 5, pp. 122–131, 2016
2016
-
[42]
Natural software revisited,
M. Rahman, D. Palani, and P. C. Rigby, “Natural software revisited,” in 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 2019, pp. 37–48
2019
-
[43]
On the” naturalness
B. Ray, V . Hellendoorn, S. Godhane, Z. Tu, A. Bacchelli, and P. De- vanbu, “On the” naturalness” of buggy code,” inProceedings of the 38th International Conference on Software Engineering, 2016, pp. 428–439
2016
-
[44]
An empirical study on the relationship between defects and source code’s unnaturalness,
Y . Jiang, H. Liu, J. Liu, Y . Zhang, W. Ji, H. Zhong, and L. Zhang, “An empirical study on the relationship between defects and source code’s unnaturalness,”ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[45]
C. M. Bishop,Pattern Recognition and Machine Learning. Springer, 2006. [Online]. Available: https://www.microsoft.com/en- us/research/wp-content/uploads/2006/01/Bishop-Pattern-Recognition- and-Machine-Learning-2006.pdf
2006
-
[46]
Understand,
SciTools, “Understand,” https://scitools.com/features
-
[47]
The road ahead for mining software repositories,
A. E. Hassan, “The road ahead for mining software repositories,” in 2008 frontiers of software maintenance. IEEE, 2008, pp. 48–57
2008
-
[48]
Kenlm: Faster and smaller language model queries,
K. Heafield, “Kenlm: Faster and smaller language model queries,” in Proceedings of the sixth workshop on statistical machine translation, 2011, pp. 187–197
2011
-
[49]
Principal component analysis,
H. Abdi and L. J. Williams, “Principal component analysis,”Wiley interdisciplinary reviews: computational statistics, vol. 2, no. 4, pp. 433– 459, 2010
2010
-
[50]
The kolmogorov-smirnov test for goodness of fit,
F. J. Massey Jr, “The kolmogorov-smirnov test for goodness of fit,” Journal of the American statistical Association, vol. 46, no. 253, pp. 68–78, 1951
1951
-
[51]
R. J. Grissom and J. J. Kim,Effect sizes for research: A broad practical approach.Lawrence Erlbaum Associates Publishers, 2005
2005
-
[52]
Xgboost: A scalable tree boosting system,
T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” inProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016, pp. 785–794
2016
-
[53]
Bugs in large language models generated code: An empirical study,
F. Tambon, A. Moradi Dakhel, A. Nikanjam, F. Khomh, M. C. Des- marais, and G. Antoniol, “Bugs in large language models generated code: An empirical study,”arXiv preprint arXiv:2403.08937, 2024
-
[54]
Human-written vs. ai- generated code: A large-scale study of defects, vulnerabilities, and complexity,
D. Cotroneo, C. Improta, and P. Liguori, “Human-written vs. ai- generated code: A large-scale study of defects, vulnerabilities, and complexity,” inProceedings of the IEEE International Symposium on Software Reliability Engineering (ISSRE), 2025
2025
-
[55]
De-hallucinator: Mitigating llm hallucina- tions in code generation tasks via iterative grounding,
A. Eghbali and M. Pradel, “De-hallucinator: Mitigating llm hallucina- tions in code generation tasks via iterative grounding,”arXiv preprint arXiv:2401.01701, 2024
-
[56]
Detecting and correcting hallucinations in llm-generated code via static knowledge validation,
Y . e. a. Chen, “Detecting and correcting hallucinations in llm-generated code via static knowledge validation,”arXiv preprint arXiv:2601.19106, 2026
-
[57]
TIOBE Programming Community Index,
TIOBE, “TIOBE Programming Community Index,” https://www.tiobe.com/tiobe-index/
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.