Recognition: unknown
Laplace Approximation for Bayesian Tensor Network Kernel Machines
Pith reviewed 2026-05-07 12:41 UTC · model grok-4.3
The pith
A linearized Laplace approximation enables principled Bayesian inference for tensor network kernel machines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that a linearized Laplace approximation can be applied directly to the weight-space formulation of tensor network kernel machines, producing a Gaussian posterior approximation that yields both point predictions and uncertainty estimates. Experiments across multiple UCI regression datasets demonstrate that this LA-TNKM method achieves predictive performance and uncertainty calibration at least as good as Gaussian processes and Bayesian neural networks.
What carries the argument
The linearized Laplace approximation, which locally approximates the non-Gaussian posterior induced by the tensor network decomposition as a Gaussian distribution around the mode for uncertainty quantification.
If this is right
- Tensor network kernel machines become usable for tasks that require calibrated uncertainty without reverting to full Gaussian process computations.
- The method offers a scalable Bayesian alternative when dataset size exceeds what standard Gaussian processes can handle comfortably.
- Bayesian inference becomes feasible for other kernel formulations that use low-rank or tensor decompositions.
- Practitioners can apply the same Laplace machinery to tensor network models in settings where Gaussian process kernels are currently preferred for their uncertainty properties.
Where Pith is reading between the lines
- The approach could be tested on classification tasks or out-of-distribution detection to see whether the uncertainty estimates transfer beyond regression.
- Combining this Laplace step with variational inference might further improve scalability on very large datasets while retaining tensor network efficiency.
- If the approximation quality holds, tensor networks could serve as a middle ground between the exact but slow kernels and the flexible but harder-to-calibrate neural networks in Bayesian settings.
Load-bearing premise
The Laplace approximation remains sufficiently accurate for uncertainty estimates even after the tensor network structure has broken Gaussianity in the weight space.
What would settle it
If repeated experiments on the same UCI regression tasks show that LA-TNKM produces systematically worse negative log predictive density or poorer uncertainty calibration than exact Gaussian processes, the claim that the method matches or surpasses them would be falsified.
Figures
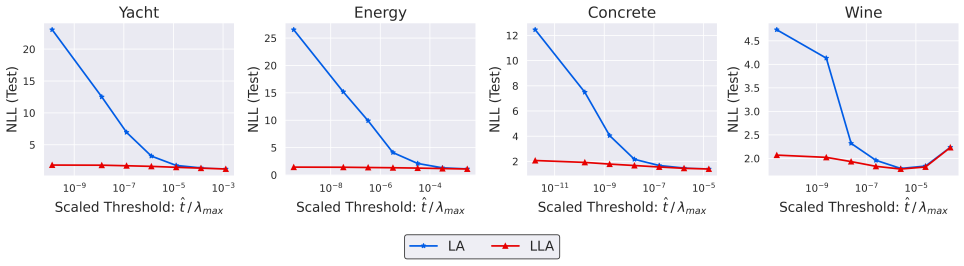

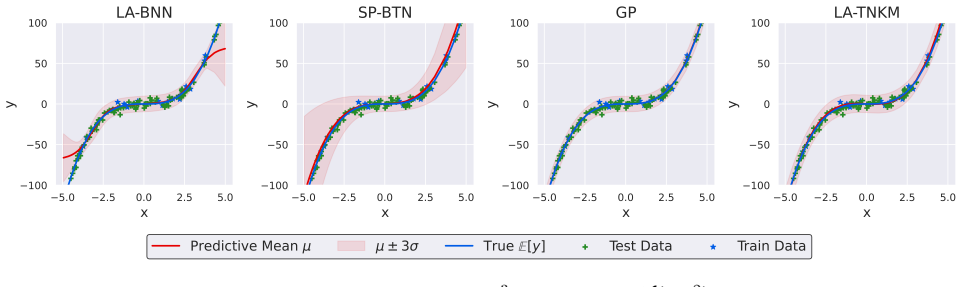
read the original abstract
Uncertainty estimation is essential for robust decision-making in the presence of ambiguous or out-of-distribution inputs. Gaussian Processes (GPs) are classical kernel-based models that offer principled uncertainty quantification and perform well on small- to medium-scale datasets. Alternatively, formulating the weight space learning problem under tensor network assumptions yields scalable tensor network kernel machines. However, these assumptions break Gaussianity, complicating standard probabilistic inference. This raises a fundamental question: how can tensor network kernel machines provide principled uncertainty estimates? We propose a novel Bayesian Tensor Network Kernel Machine (LA-TNKM) that employs a (linearized) Laplace approximation for Bayesian inference. A comprehensive set of numerical experiments shows that the proposed method consistently matches or surpasses Gaussian Processes and Bayesian Neural Networks (BNNs) across diverse UCI regression benchmarks, highlighting both its effectiveness and practical relevance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Bayesian Tensor Network Kernel Machine (LA-TNKM) that employs a linearized Laplace approximation for Bayesian inference in tensor network kernel machines. These models break Gaussianity in the weight-space formulation, which complicates standard probabilistic inference; the paper claims the approximation addresses this and, via experiments on UCI regression benchmarks, consistently matches or surpasses Gaussian Processes and Bayesian Neural Networks.
Significance. If the linearized Laplace approximation can be shown to yield reliable posterior covariances despite the non-Gaussianity induced by the tensor-network weight-space formulation, the work would provide a scalable route to principled uncertainty quantification for kernel machines. The empirical parity with GPs and BNNs on standard benchmarks indicates practical utility, but the absence of isolated tests for the approximation's validity limits the strength of this assessment.
major comments (3)
- [Abstract] Abstract: The motivating difficulty is explicitly that tensor-network assumptions break Gaussianity, yet the claim that a linearized Laplace approximation restores usable posterior uncertainty estimates is asserted without any derivation, error bound, or first-order analysis showing that the quadratic approximation around the mode remains controlled.
- [Method] Method (presumed §3): The central claim requires that the approximation remains reliable after the tensor-network formulation has already broken the Gaussianity on which standard Laplace relies; no diagnostic (Hessian positive-definiteness, predictive calibration on held-out data, or comparison to exact marginals on toy cases) is provided to confirm the approximation error is controlled.
- [Experiments] Experiments (presumed §4): The numerical results are summarized at high level without specifics on baselines, metrics, statistical significance, or how uncertainty estimates themselves (as opposed to point predictions) are evaluated, so the data cannot be assessed for support of the claim that the method provides principled uncertainty estimates.
minor comments (1)
- [Abstract] Abstract: The parenthetical '(linearized)' in the description of the Laplace approximation is not explained; clarify whether this is the standard first-order linearization or a distinct variant.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that will strengthen the presentation of the approximation and the experimental evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The motivating difficulty is explicitly that tensor-network assumptions break Gaussianity, yet the claim that a linearized Laplace approximation restores usable posterior uncertainty estimates is asserted without any derivation, error bound, or first-order analysis showing that the quadratic approximation around the mode remains controlled.
Authors: We agree the abstract states the claim concisely. The linearized Laplace approximation is obtained by a second-order Taylor expansion of the log-posterior around the MAP point, with the tensor-network kernel entering the resulting quadratic form; this is standard for non-Gaussian weight-space models. In the revision we will shorten the abstract slightly and add an explicit pointer to the derivation and error-control argument now placed in Section 3. revision: yes
-
Referee: [Method] Method (presumed §3): The central claim requires that the approximation remains reliable after the tensor-network formulation has already broken the Gaussianity on which standard Laplace relies; no diagnostic (Hessian positive-definiteness, predictive calibration on held-out data, or comparison to exact marginals on toy cases) is provided to confirm the approximation error is controlled.
Authors: The observation is correct. The submitted manuscript applies the linearized Laplace procedure but does not report the requested diagnostics. We will add a short subsection that (i) verifies positive-definiteness of the Hessian at the mode for the UCI tasks, (ii) shows predictive calibration plots, and (iii) includes a small-scale synthetic example where exact marginals can be computed for direct comparison. revision: yes
-
Referee: [Experiments] Experiments (presumed §4): The numerical results are summarized at high level without specifics on baselines, metrics, statistical significance, or how uncertainty estimates themselves (as opposed to point predictions) are evaluated, so the data cannot be assessed for support of the claim that the method provides principled uncertainty estimates.
Authors: The experiments already compare against GPs and BNNs on UCI regression tasks and report averaged performance over repeated splits. To make the uncertainty evaluation explicit we will enlarge the section with full tables, negative log predictive density as an uncertainty-specific metric, and a short paragraph separating point-prediction accuracy from calibration of the posterior predictive. revision: yes
Circularity Check
No circularity; claims rest on empirical benchmarks independent of any self-referential derivation
full rationale
The paper proposes LA-TNKM by applying a linearized Laplace approximation to address the loss of Gaussianity induced by tensor-network weight-space assumptions. No equations, parameter fits, or self-citations are exhibited in the provided text that reduce the central claim (accurate posterior uncertainty) to a redefinition or refit of the inputs themselves. Validation consists of direct numerical comparisons against GPs and BNNs on held-out UCI regression tasks, which constitute external falsifiable evidence rather than a closed loop. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ISSN 1935-8245. doi: 10.1561/2200000059. Tristan Cinquin, Marvin Pförtner, Vincent Fortuin, Philipp Hennig, and Robert Bamler. Fsp-Laplace: function-space priors for the Laplace approximation in Bayesian deep learning. InProceedings of the 38th International Con- ference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2025. Curran ...
-
[2]
Adam: A Method for Stochastic Optimization
URL http://proceedings.mlr.press/ v130/immer21a.html. Mohammad Emtiyaz Khan, Alexander Immer, Ehsan Abedi, and Maciej Korzepa. Approximate inference turns deep networks into Gaussian processes. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 32. Curran ...
work page internal anchor Pith review arXiv 2019
-
[3]
doi: 10.1137/07070111X. Kriton Konstantinidis, Yao Lei Xu, Qibin Zhao, and Danilo P. Mandic. Variational Bayesian tensor networks with structured posteriors. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP), pages 3638–3642, 2022. doi: 10.1109/ICASSP43922.2022.9747861. Agustinus Kristiadi, Matthias H...
-
[4]
ISSN 0167-8655. doi: https://doi.org/10.1016/j. patrec.2024.09.011. V olodymyr Kuleshov, Nathan Fenner, and Stefano Ermon. Accurate uncertainties for deep learning using calibrated regression. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Ma- chine Learning, volume 80 ofProceedings of Machine Learning Rese...
work page doi:10.1016/j 2024
-
[5]
URL https://proceedings.mlr.press/ v80/kuleshov18a.html. Yingzhen Li and Yarin Gal. Dropout inference in Bayesian neural networks with alpha-divergences. InProceedings of the 34th International Conference on Machine Learn- ing - Volume 70, ICML’17, page 2052–2061. JMLR.org, 2017. Yiping Li, Jianwen Chen, and Ling Feng. Dealing with uncertainty: A survey o...
-
[6]
URL https://proceedings.mlr.press/ v258/miani25a.html. Kevin P. Murphy.Probabilistic Machine Learning: An introduction. MIT Press, 2022. URL http://probml. github.io/book1. Wongyung Nam and Beakcheol Jang. A survey on multi- modal bidirectional machine learning translation of image and natural language processing.Expert Systems with Applications, 235:1211...
-
[7]
Deepjyoti Roy and Mala Dutta
ISBN 026218253X. Deepjyoti Roy and Mala Dutta. A systematic review and research perspective on recommender systems.Journal of Big Data, 9(1):59, 2022. Albert Saiapin and Kim Batselier. Tensor network based feature learning model. In Yingzhen Li, Stephan Mandt, Shipra Agrawal, and Emtiyaz Khan, editors,Proceedings of The 28th International Conference on Ar...
2022
-
[8]
John Shawe-Taylor and Nello Cristianini.Kernel Methods for Pattern Analysis
URL https://proceedings.mlr.press/ v206/sharma23a.html. John Shawe-Taylor and Nello Cristianini.Kernel Methods for Pattern Analysis. Cambridge University Press, 2004. Mohammad Shehab, Laith Abualigah, Qusai Shambour, Muhannad A. Abu-Hashem, Mohd Khaled Yousef Sham- bour, Ahmed Izzat Alsalibi, and Amir H. Gandomi. Ma- chine learning in medical applications...
-
[9]
Statistics and Computing , author =
doi: 10.1007/s11222-019-09886-w. Edwin Stoudenmire and David J Schwab. Supervised learn- ing with tensor networks. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016. André Uschmajew. Local convergence of the alternating least squares algorithm f...
-
[10]
URL https://proceedings.mlr.press/ v238/wesel24a.html. Veit D. Wild, Robert Hu, and Dino Sejdinovic. General- ized variational inference in function spaces: Gaussian measures meet Bayesian deep learning. InProceedings of the 36th International Conference on Neural Informa- tion Processing Systems, NIPS ’22, Red Hook, NY , USA,
-
[11]
ISBN 9781713871088
Curran Associates Inc. ISBN 9781713871088. Daiwei Zhang, Tianci Liu, and Jian Kang. Den- sity regression and uncertainty quantification with Bayesian deep noise neural networks.Stat, 12(1),
-
[12]
doi: https://doi.org/10.1002/sta4.604. URL https://onlinelibrary.wiley.com/doi/ abs/10.1002/sta4.604. Laplace Approximation for Bayesian Tensor Network Kernel Machines (Supplementary Material) Albert Saiapin1 Kim Batselier1 1Delft Center for Systems and Control, Delft University of Technology A BAYESIAN TENSOR NETWORK KERNEL MACHINES A.1 HESSIAN MATRIX AP...
-
[13]
βA pkqJApkq `γI. (32) Using Equation (31), the general form of the second derivative with respect tov pmq can be expressed as: B2J BpvpmqqJBv pkq “β B
(30) The first derivative of theℓ 2-regularized linear regression loss function is given by: BJ Bv pkq “β ´ ApkqJApkqvpkq ´A pkqJy ¯ `γv pkq. (31) The second derivative w.r.t the same vectorvpkq can be computed as follows: B2J BpvpkqqJBv pkq “βA pkqJApkq `γI. (32) Using Equation (31), the general form of the second derivative with respect tov pmq can be e...
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.