Recognition: unknown
When Model Editing Meets Service Evolution: A Knowledge-Update Perspective for Service Recommendation
Pith reviewed 2026-05-07 11:26 UTC · model grok-4.3
The pith
Locate-then-edit model editing plus automata-constrained decoding lets LLMs insert updated service facts and generate only valid non-duplicate recommendations as services evolve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EVOREC applies a locate-then-edit paradigm to insert updated service facts into the LLM without costly retraining, keeping the model aligned with evolving ecosystems, while a Finite Automata-based constrained decoding step with deduplication enforces structural validity and removes repeated services from the output.
What carries the argument
The locate-then-edit model editing step for inserting new service facts together with the Finite Automata constrained decoding mechanism that enforces validity and eliminates duplicates.
If this is right
- Updated service facts are incorporated without full model retraining, keeping recommendations aligned with current ecosystems.
- Invalid and redundant service suggestions are automatically blocked by the decoding constraints.
- Average relative improvement reaches 25.9 percent in Recall@5 over existing baselines on real-world service datasets.
- In evolving service scenarios the approach outperforms model fine-tuning by 22.3 percent.
Where Pith is reading between the lines
- The approach could cut the compute cost of keeping recommendation systems current in industries with frequent service changes.
- Similar editing-plus-constraint techniques might transfer to other LLM tasks that suffer from knowledge drift, such as product or content recommendation.
- Direct comparison of edit precision across different LLM sizes would test whether the gains scale beyond the models used in the experiments.
Load-bearing premise
The locate-then-edit edits can reliably add new service facts without side effects on unrelated knowledge and the automata constraints will always produce only valid unique outputs.
What would settle it
Run the edited model on a fresh set of evolving services and check whether it still outputs outdated facts or invalid duplicate recommendations; repeated failures on this test would falsify the claim.
Figures










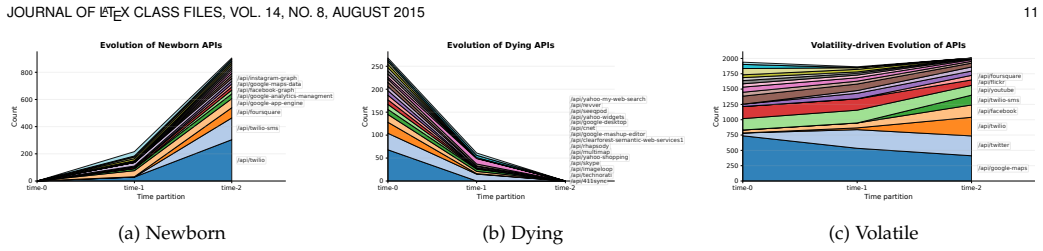


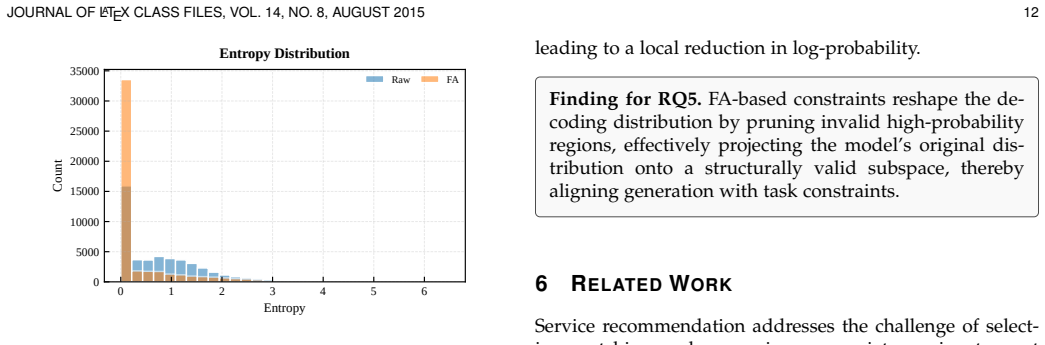
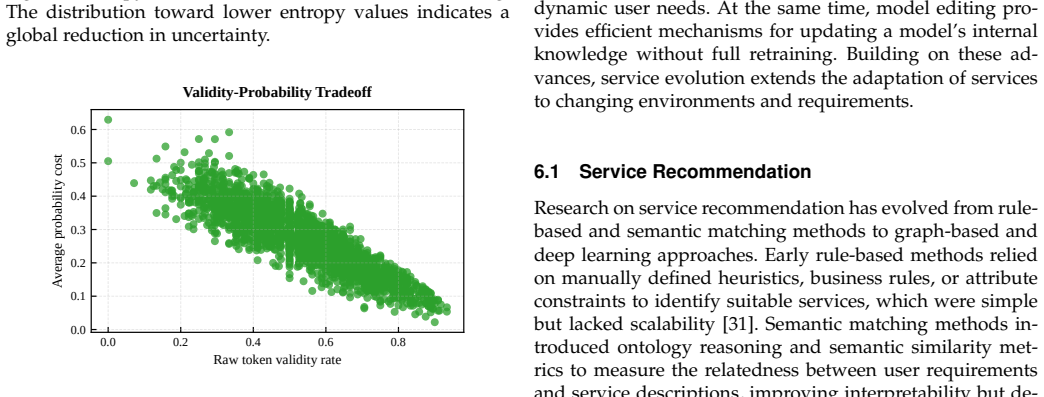
read the original abstract
The rapid evolution of software services poses substantial challenges to the design and implementation of effective recommendation systems. Traditional service recommendation approaches often rely on static representations and historical usage data, which are insufficient for adapting to the dynamic and evolving nature of service ecosystems. Recently, large language models (LLMs) have shown strong potential to overcome these limitations by leveraging rich contextual understanding. However, their practical use faces two major challenges: outdated service facts and invalid or redundant services. To address these issues, we propose EVOREC, an evolution-aware framework for service recommendation that leverages model editing in a locate-then-edit paradigm to incorporate updated service facts without costly retraining efficiently. This allows the model to remain aligned with evolving service ecosystems. To address invalid service issues, we introduce a Finite Automata (FA)-based constrained decoding mechanism with deduplication, which enforces structural and semantic validity while eliminating repeated services. Experiments on real-world service datasets demonstrate that our framework consistently outperforms existing baselines, e.g., achieving an average relative improvement of 25.9% in Recall@5. Moreover, under evolving service scenarios, our approach outperforms model fine-tuning approaches by 22.3%, demonstrating strong adaptability to service evolution and providing a practical solution for service recommendation in dynamic ecosystems
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EVOREC, a framework for service recommendation that applies locate-then-edit model editing to update outdated service facts in LLMs without full retraining, combined with a finite-automata constrained decoding mechanism that enforces structural validity and deduplication to avoid invalid or redundant outputs. Experiments on real-world service datasets are reported to show an average 25.9% relative improvement in Recall@5 over baselines and a 22.3% advantage over fine-tuning under evolving service scenarios.
Significance. If the empirical gains hold after addressing side-effect controls, the work would demonstrate a practical, low-cost path for keeping LLM-based recommenders aligned with dynamic service ecosystems, which is a recurring challenge in service-oriented computing. The locate-then-edit plus constrained-decoding combination is a targeted response to both knowledge staleness and output validity, and the reported margins over fine-tuning suggest efficiency advantages worth further validation.
major comments (1)
- The headline claims (25.9% Recall@5 lift and 22.3% over fine-tuning) rest on the assumption that locate-then-edit editing inserts updated service facts while leaving unrelated knowledge intact, yet the experiments section reports only aggregate recommendation metrics with no ablation or auxiliary evaluation of performance degradation on non-evolved services or previously correct facts after editing.
minor comments (1)
- The abstract sentence describing the editing step contains a misplaced adverb ('without costly retraining efficiently'), which should be rephrased for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will revise the paper to incorporate the suggested evaluation.
read point-by-point responses
-
Referee: The headline claims (25.9% Recall@5 lift and 22.3% over fine-tuning) rest on the assumption that locate-then-edit editing inserts updated service facts while leaving unrelated knowledge intact, yet the experiments section reports only aggregate recommendation metrics with no ablation or auxiliary evaluation of performance degradation on non-evolved services or previously correct facts after editing.
Authors: We agree that the current experiments focus on aggregate metrics in evolving scenarios and do not include explicit auxiliary evaluations of editing locality. While the locate-then-edit paradigm is intended to perform targeted updates with limited side effects (consistent with the method's design in prior literature), we acknowledge that direct evidence on non-evolved services and previously correct facts would strengthen the headline claims. In the revised manuscript we will add before-and-after comparisons on static (non-evolved) service recommendation tasks together with metrics quantifying any degradation on previously accurate facts. These additions will be reported alongside the existing results. revision: yes
Circularity Check
No circularity; empirical results independent of inputs
full rationale
The paper proposes EVOREC, a framework that applies locate-then-edit model editing to update service facts in LLMs and adds finite-automata constrained decoding for validity and deduplication. All reported results (25.9% Recall@5 lift, 22.3% over fine-tuning) are obtained from direct experimental comparisons on real-world service datasets against baselines. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The evaluation is externally falsifiable through replication on the same datasets and therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can be edited via a locate-then-edit process to incorporate new service facts without full retraining or catastrophic forgetting of prior knowledge.
- domain assumption A finite-automata-based decoder can simultaneously enforce structural validity, semantic validity, and deduplication during generation.
invented entities (1)
-
EVOREC framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Service computing for industry 4.0: State of the art, challenges, and research opportunities,
F. Siqueira and J. G. Davis, “Service computing for industry 4.0: State of the art, challenges, and research opportunities,”ACM Computing Surveys (CSUR), vol. 54, no. 9, pp. 1–38, 2021
2021
-
[2]
Service recommendations for mashup based on generation model,
G. Fan, S. Chen, Q. He, H. Wu, J. Li, X. Xue, and Z. Feng, “Service recommendations for mashup based on generation model,”IEEE Transactions on Services Computing, vol. 17, no. 4, pp. 1820–1834, 2023
2023
-
[3]
User feedback driven generative models-based methodology for service construction,
G. Fan, S. Chen, and L. Zhang, “User feedback driven generative models-based methodology for service construction,”IEEE Inter- net Computing, 2025
2025
-
[4]
Data correction and evolution analysis of the programmableweb service ecosystem,
M. Liu, Z. Tu, Y. Zhu, X. Xu, Z. Wang, and Q. Z. Sheng, “Data correction and evolution analysis of the programmableweb service ecosystem,”Journal of Systems and Software, vol. 182, p. 111066, 2021
2021
-
[5]
A rule-based service customization strategy for smart home context-aware automation,
Z. Meng and J. Lu, “A rule-based service customization strategy for smart home context-aware automation,”IEEE Transactions on Mobile Computing, vol. 15, no. 3, pp. 558–571, 2015
2015
-
[6]
Collaborative filtering service rec- ommendation based on a novel similarity computation method,
X. Wu, B. Cheng, and J. Chen, “Collaborative filtering service rec- ommendation based on a novel similarity computation method,” IEEE Transactions on Services Computing, vol. 10, no. 3, pp. 352–365, 2015
2015
-
[7]
Building the semantic relations-based web services registry through services mining,
S. Chen, Z. Feng, H. Wang, and T. Wang, “Building the semantic relations-based web services registry through services mining,” in2009 Eighth IEEE/ACIS International Conference on Computer and Information Science. IEEE, 2009, pp. 736–743
2009
-
[8]
Servicebert: A pre-trained model for web service tagging and recommen- dation,
X. Wang, P . Zhou, Y. Wang, X. Liu, J. Liu, and H. Wu, “Servicebert: A pre-trained model for web service tagging and recommen- dation,” inInternational Conference on Service-Oriented Computing. Springer, 2021, pp. 464–478
2021
-
[9]
Dysr: A dynamic graph neural network based service bundle recommendation model for mashup creation,
M. Liu, Z. Tu, H. Xu, X. Xu, and Z. Wang, “Dysr: A dynamic graph neural network based service bundle recommendation model for mashup creation,”IEEE Transactions on Services Computing, vol. 16, no. 4, pp. 2592–2605, 2023
2023
-
[10]
Representation learning with large language models for recommendation,
X. Ren, W. Wei, L. Xia, L. Su, S. Cheng, J. Wang, D. Yin, and C. Huang, “Representation learning with large language models for recommendation,” inProceedings of the ACM web conference 2024, 2024, pp. 3464–3475
2024
-
[11]
A study on semantic understanding of large language models from the perspective of ambiguity resolution,
S. Yang, F. Chen, Y. Yang, and Z. Zhu, “A study on semantic understanding of large language models from the perspective of ambiguity resolution,” inProceedings of the 2023 International Joint Conference on Robotics and Artificial Intelligence, 2023, pp. 165–170
2023
-
[12]
Lawyer gpt: A legal large language model with enhanced domain knowledge and reasoning capabilities,
S. Yao, Q. Ke, Q. Wang, K. Li, and J. Hu, “Lawyer gpt: A legal large language model with enhanced domain knowledge and reasoning capabilities,” inProceedings of the 2024 3rd International Symposium on Robotics, Artificial Intelligence and Information Engineering, 2024, pp. 108–112
2024
-
[13]
A self-iteration code generation method based on large language models,
T. Chang, S. Chen, G. Fan, and Z. Feng, “A self-iteration code generation method based on large language models,” in2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICP ADS). IEEE, 2023, pp. 275–281
2023
-
[14]
S. Wu, Y. Xiong, Y. Cui, H. Wu, C. Chen, Y. Yuan, L. Huang, X. Liu, T.-W. Kuo, N. Guanet al., “Retrieval-augmented gener- ation for natural language processing: A survey,”arXiv preprint arXiv:2407.13193, 2024
-
[15]
Parameter-efficient fine-tuning of large- scale pre-trained language models,
N. Ding, Y. Qin, G. Yang, F. Wei, Z. Yang, Y. Su, S. Hu, Y. Chen, C.- M. Chan, W. Chenet al., “Parameter-efficient fine-tuning of large- scale pre-trained language models,”Nature machine intelligence, vol. 5, no. 3, pp. 220–235, 2023
2023
-
[16]
A survey on in-context learning,
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, B. Changet al., “A survey on in-context learning,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 1107–1128
2024
-
[17]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[18]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess`ı, R. Raileanu, M. Lomeli, E. Ham- bro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in neural information processing systems, vol. 36, pp. 68 539–68 551, 2023
2023
-
[19]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning repre- sentations, 2022
2022
-
[20]
Gorilla: Large language model connected with massive apis,
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez, “Gorilla: Large language model connected with massive apis,”Advances in Neural Information Processing Systems, vol. 37, pp. 126 544–126 565, 2024
2024
-
[21]
Retrieval is not enough: Enhancing rag through test-time critique and optimization,
J. Wei, H. Zhou, X. Zhang, D. Zhang, Z. Qiu, N. Wei, J. Li, W. Ouyang, and S. Sun, “Retrieval is not enough: Enhancing rag through test-time critique and optimization,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[22]
Learning from models beyond fine-tuning,
H. Zheng, L. Shen, A. Tang, Y. Luo, H. Hu, B. Du, Y. Wen, and D. Tao, “Learning from models beyond fine-tuning,”Nature Machine Intelligence, vol. 7, no. 1, pp. 6–17, 2025
2025
-
[23]
C. Gao, G. Fan, C. Y. Chong, S. Chen, C. Liu, D. Lo, Z. Zheng, and Q. Liao, “A systematic literature review of code hallucinations in llms: Characterization, mitigation methods, challenges, and future directions for reliable ai,”arXiv preprint arXiv:2511.00776, 2025
-
[24]
Locating and editing factual associations in gpt,
K. Meng, D. Bau, A. Andonian, and Y. Belinkov, “Locating and editing factual associations in gpt,”Advances in neural information processing systems, vol. 35, pp. 17 359–17 372, 2022. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 16
2022
-
[25]
arXiv preprint arXiv:2401.01286 (2024)
N. Zhang, Y. Yao, B. Tian, P . Wang, S. Deng, M. Wang, Z. Xi, S. Mao, J. Zhang, Y. Niet al., “A comprehensive study of knowledge edit- ing for large language models,”arXiv preprint arXiv:2401.01286, 2024
-
[26]
Revisiting, benchmarking and exploring api recommendation: How far are we?
Y. Peng, S. Li, W. Gu, Y. Li, W. Wang, C. Gao, and M. R. Lyu, “Revisiting, benchmarking and exploring api recommendation: How far are we?”IEEE Transactions on Software Engineering, vol. 49, no. 4, pp. 1876–1897, 2023
2023
-
[27]
aixcoder-7b: A lightweight and effective large language model for code processing,
S. Jiang, J. Li, H. Zong, H. Liu, H. Zhu, S. Hu, E. Li, J. Ding, Y. Han, W. Ninget al., “aixcoder-7b: A lightweight and effective large language model for code processing,” in2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engi- neering in Practice (ICSE-SEIP). IEEE, 2025, pp. 215–226
2025
-
[28]
Mashup-oriented web api recommendation via multi-model fusion and multi-task learning,
H. Wu, Y. Duan, K. Yue, and L. Zhang, “Mashup-oriented web api recommendation via multi-model fusion and multi-task learning,” IEEE Transactions on Services Computing, vol. 15, no. 6, pp. 3330– 3343, 2021
2021
-
[29]
Llamafactory: Unified efficient fine-tuning of 100+ language models,
Y. Zheng, R. Zhang, J. Zhang, Y. Ye, Z. Luo, Z. Feng, and Y. Ma, “Llamafactory: Unified efficient fine-tuning of 100+ language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). Bangkok, Thailand: Association for Computational Linguistics,
-
[30]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
[Online]. Available: http://arxiv.org/abs/2403.13372
work page internal anchor Pith review arXiv
-
[31]
A systematic evaluation of large code models in api suggestion: When, which, and how,
C. Wang, S. Gao, C. Gao, W. Wang, C. Y. Chong, S. Gao, and M. R. Lyu, “A systematic evaluation of large code models in api suggestion: When, which, and how,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ser. ASE ’24. New York, NY, USA: Association for Computing Machinery, 2024, p. 281–293. [Online]. Availa...
-
[32]
Pre-joined semantic indexing graph for qos-aware service composition,
J. Li, G. Fan, M. Zhu, and Y. Yan, “Pre-joined semantic indexing graph for qos-aware service composition,” in2019 IEEE Interna- tional Conference on Web Services (ICWS). IEEE, 2019, pp. 116–120
2019
-
[33]
A systematic evaluation of large code models in api sugges- tion: When, which, and how,
C. Wang, S. Gao, C. Gao, W. Wang, C. Y. Chong, S. Gao, and M. R. Lyu, “A systematic evaluation of large code models in api sugges- tion: When, which, and how,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, 2024, pp. 281–293
2024
-
[34]
Llms- based decision making for service recommendations and process automation under evolving ecosystem,
G. Fan, S. Chen, H. Wu, C. Gao, J. Wang, and Z. Feng, “Llms- based decision making for service recommendations and process automation under evolving ecosystem,”Automated Software Engi- neering, vol. 33, no. 2, p. 57, 2026
2026
-
[35]
Api-bank: A comprehensive benchmark for tool-augmented llms,
M. Li, Y. Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y. Li, “Api-bank: A comprehensive benchmark for tool-augmented llms,” inProceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 3102–3116
2023
-
[36]
Stabletoolbench: Towards stable large-scale bench- marking on tool learning of large language models,
Z. Guo, S. Cheng, H. Wang, S. Liang, Y. Qin, P . Li, Z. Liu, M. Sun, and Y. Liu, “Stabletoolbench: Towards stable large-scale bench- marking on tool learning of large language models,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 11 143–11 156
2024
-
[37]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real- world github issues?”arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review arXiv 2023
-
[38]
Benchmarking ai models in software engineering: A review, search tool, and uni- fied approach for elevating benchmark quality,
R. Koohestani, P . de Bekker, B. Koc ¸, and M. Izadi, “Benchmarking ai models in software engineering: A review, search tool, and uni- fied approach for elevating benchmark quality,”IEEE Transactions on Software Engineering, 2025
2025
-
[39]
Hug- ginggpt: Solving ai tasks with chatgpt and its friends in hugging face,
Y. Shen, K. Song, X. Tan, D. Li, W. Lu, and Y. Zhuang, “Hug- ginggpt: Solving ai tasks with chatgpt and its friends in hugging face,”Advances in Neural Information Processing Systems, vol. 36, pp. 38 154–38 180, 2023
2023
-
[40]
Agentic context engineering: Learning comprehensive contexts for self-improving language models,
Q. Zhang, C. Hu, S. Upasani, B. Ma, F. Hong, V . Kamanuru, J. Rainton, C. Wu, M. Ji, H. Liet al., “Agentic context engineering: Learning comprehensive contexts for self-improving language models,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[41]
Harnessing large language models for virtual reality exploration testing: a case study,
Z. Qi, H. Li, H. Qin, K. Peng, S. He, and X. Qin, “Harnessing large language models for virtual reality exploration testing: a case study,”Automated Software Engineering, vol. 33, no. 1, p. 7, 2026
2026
-
[42]
OpenClaw-RL: Train Any Agent Simply by Talking
Y. Wang, X. Chen, X. Jin, M. Wang, and L. Yang, “Openclaw- rl: Train any agent simply by talking,”arXiv preprint arXiv:2603.10165, 2026
work page internal anchor Pith review arXiv 2026
-
[43]
Coe: Chain-of- explanation via automatic visual concept circuit description and polysemanticity quantification,
W. Yu, Q. Wang, C. Liu, D. Li, and Q. Hu, “Coe: Chain-of- explanation via automatic visual concept circuit description and polysemanticity quantification,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 4364–4374
2025
-
[44]
Fine-tuning or retrieval? comparing knowledge injection in llms,
O. Ovadia, M. Brief, M. Mishaeli, and O. Elisha, “Fine-tuning or retrieval? comparing knowledge injection in llms,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 237–250
2024
-
[45]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y. Shen, P . Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.”ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[46]
Fast model editing at scale,
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning, “Fast model editing at scale,” inInternational Conference on Learning Representations
-
[47]
Can we edit factual knowledge by in-context learning?
C. Zheng, L. Li, Q. Dong, Y. Fan, Z. Wu, J. Xu, and B. Chang, “Can we edit factual knowledge by in-context learning?” inThe 2023 Conference on Empirical Methods in Natural Language Processing
2023
-
[48]
K. Meng, A. S. Sharma, A. Andonian, Y. Belinkov, and D. Bau, “Mass-editing memory in a transformer,”arXiv preprint arXiv:2210.07229, 2022
-
[49]
Wise: Rethinking the knowledge memory for lifelong model editing of large language models,
P . Wang, Z. Li, N. Zhang, Z. Xu, Y. Yao, Y. Jiang, P . Xie, F. Huang, and H. Chen, “Wise: Rethinking the knowledge memory for lifelong model editing of large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 53 764–53 797, 2024
2024
-
[50]
Towards change impact analysis in microservices-based system evolution,
T. Cerny, G. Goulis, and A. S. Abdelfattah, “Towards change impact analysis in microservices-based system evolution,” in2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 2025, pp. 159–169
2025
-
[51]
Service mesh: Architectures, applications, and implementations,
B. Farkiani and R. Jain, “Service mesh: Architectures, applications, and implementations,”arXiv preprint arXiv:2405.13333, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.