Recognition: unknown
COPUS: Co-adaptive Parallelism and Batch Size Selection in Large Language Model Training
Pith reviewed 2026-05-07 11:20 UTC · model grok-4.3
The pith
COPUS shows that the global batch size and 3D parallelism strategy in large language model training must be adapted together because each affects the other's optimum.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
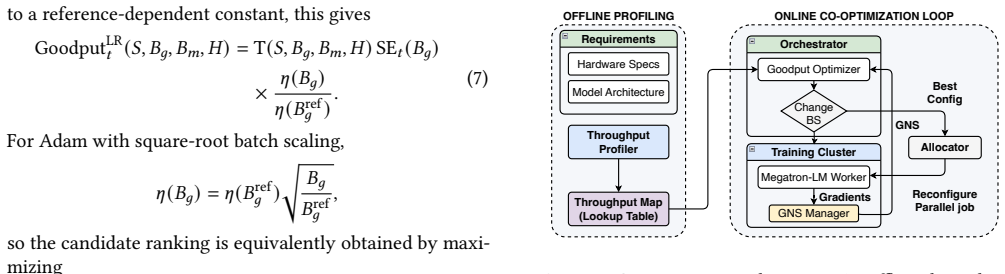
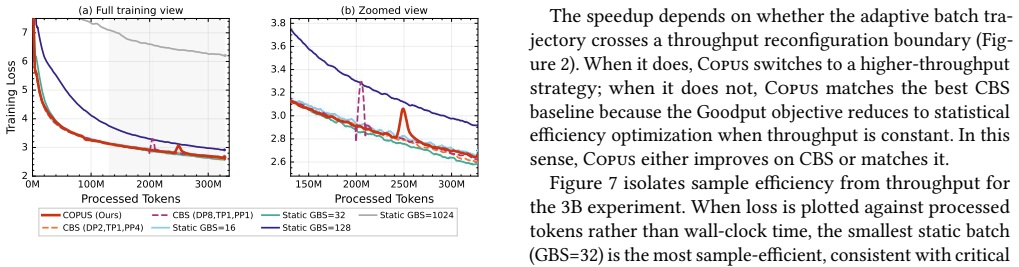
The central claim is that throughput-optimal parallelism shifts with global batch size, so any fixed-parallelism or fixed-batch approach incurs suboptimal performance for part of training; COPUS counters this by continuously evaluating candidate configurations under Goodput, reconfiguring both batch size and parallelism with low overhead, and delivering measured time-to-convergence gains of 3.9-8.0 percent on average (peaks of 11.1 percent) across 3B-32B models on 1-4 nodes of H100 and MI210 GPUs.
What carries the argument
Goodput, the product of hardware throughput and statistical efficiency estimated from online gradient noise scale under 3D parallelism, which ranks candidate (batch-size, parallelism) pairs by useful convergence per wall-clock second.
If this is right
- Periodic re-evaluation of parallelism as batch size increases keeps the training run on the joint throughput-efficiency frontier rather than drifting into suboptimal regions.
- Online noise-scale estimation under 3D parallelism supplies a cheap proxy for statistical efficiency that can be computed without halting training.
- Support for low-overhead batch-size and parallelism reconfiguration enables the system to act on Goodput comparisons during a single long run.
- The measured gains hold across model sizes from 3B to 32B and on both NVIDIA H100 and AMD MI210 clusters, indicating the coupling effect is not hardware-specific.
Where Pith is reading between the lines
- Similar co-adaptation could be applied to other interacting choices such as learning-rate schedules and activation checkpointing that also trade statistical and hardware efficiency.
- The observed shift in optimal parallelism implies that static hardware benchmarks taken at a single batch size may underestimate the benefit of dynamic strategies in long training runs.
- Extending the approach to even larger models or multi-node clusters would test whether reconfiguration costs remain negligible relative to the gains.
- Integrating Goodput-guided selection with automated model-parallelism search tools could produce end-to-end systems that optimize both model architecture and runtime configuration together.
Load-bearing premise
That the online gradient noise scale measured under different 3D parallelisms accurately forecasts how a configuration will affect both statistical efficiency and overall convergence speed without adding large reconfiguration costs or instability.
What would settle it
Run the same pre-training workload twice on identical hardware, once with COPUS enabled and once with its adaptation disabled, and measure whether the reported 3.9-8 percent reduction in time to target loss still appears after subtracting all measured reconfiguration overhead.
Figures












read the original abstract
Training large language models requires jointly configuring two interdependent aspects of the system: the global batch size, which governs statistical efficiency, and the 3D parallelism strategy, which governs hardware throughput. Existing approaches make these decisions independently: optimization work adapts the batch size to track the evolving critical batch size while keeping parallelism fixed, and systems work selects the fastest parallelism for a given fixed batch size without anticipating that the optimal batch size could change. We show that these decisions are tightly coupled: the throughput-optimal parallelism strategy may shift as the global batch size changes, so any method that fixes one while adapting the other operates with a suboptimal configuration for part of the training run. We present COPUS, a system that adaptively tunes the global batch size, parallelism strategy, and micro-batch size as training evolves. COPUS is guided by Goodput, the product of throughput and statistical efficiency, which models both hardware and statistical effects jointly and directly measures useful convergence per unit of wall-clock time. The system combines online gradient noise scale estimation under 3D parallelism with throughput-aware evaluation of candidate configurations, and supports efficient reconfiguration of both batch size and parallelism during training. We evaluate COPUS on LLM pre-training workloads across 1-4 nodes of 8xH100 and 8xMI210 GPUs and model sizes from 3B to 32B parameters, demonstrating average time-to-convergence speedups of 3.9-8.0% over the fastest baseline across four configurations, with peak gains up to 11.1%, including system overheads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that global batch size and 3D parallelism (data/tensor/pipeline) are tightly coupled in LLM training because the throughput-optimal parallelism can shift as batch size changes during training. It introduces COPUS, a system that jointly adapts global batch size, parallelism strategy, and micro-batch size guided by Goodput (throughput multiplied by statistical efficiency from online gradient noise scale estimation). The system supports efficient reconfigurations and is evaluated on 3B-32B models across 1-4 nodes of H100/MI210 GPUs, reporting 3.9-8.0% average time-to-convergence speedups (peaks to 11.1%) over the fastest fixed-parallelism or fixed-batch baselines, including overheads.
Significance. If the central coupling observation and Goodput-based co-adaptation hold, the work provides a practical method to avoid suboptimal fixed configurations during long training runs, yielding measurable wall-clock gains even after reconfiguration costs. The empirical results across multiple model sizes and hardware are a strength, as is the inclusion of system overheads in the reported speedups. However, the modest magnitude of gains (under 10% on average) limits immediate broad impact unless the method scales to larger clusters or is shown to compound over very long runs.
major comments (2)
- [§3.2] §3.2 (Goodput definition and noise-scale estimator): The central claim that online gradient noise scale estimation under the current 3D parallelism can reliably rank candidate (batch-size, parallelism, micro-batch) tuples by true wall-clock convergence rate requires that the estimator's bias and variance are invariant to changes in data-parallel, tensor-parallel, or pipeline-parallel degree. No derivation or controlled experiment demonstrates this invariance; if the estimator shifts when parallelism is reconfigured, the Goodput ranking can select configurations whose measured Goodput is high but whose actual time-to-target-loss is no better than the fixed-parallelism baseline.
- [§4.3] §4.3 (Evaluation of reconfiguration overhead and statistical-efficiency term): The reported speedups include system overheads, yet the manuscript provides no breakdown of how much of the 3.9-8% gain survives after subtracting optimizer-state migration, pipeline flushing, and any transient increase in gradient noise immediately after a parallelism change. Without this, it is unclear whether the co-adaptive policy actually improves net convergence rate or merely redistributes time between throughput and statistical-efficiency phases.
minor comments (2)
- [Abstract / §1] The abstract and §1 state that Goodput is 'the product of throughput and statistical efficiency' but never give the precise formula used for statistical efficiency (e.g., whether it is 1/noise-scale, a fitted scaling law, or another quantity). Adding the explicit expression would clarify how the online estimator is turned into a scalar efficiency term.
- [§4.1] Table 1 (or equivalent configuration table) lists four evaluation setups but does not report the number of independent runs or error bars on the time-to-convergence numbers. Adding these would strengthen the claim that the observed speedups are statistically distinguishable from baseline variance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Goodput definition and noise-scale estimator): The central claim that online gradient noise scale estimation under the current 3D parallelism can reliably rank candidate (batch-size, parallelism, micro-batch) tuples by true wall-clock convergence rate requires that the estimator's bias and variance are invariant to changes in data-parallel, tensor-parallel, or pipeline-parallel degree. No derivation or controlled experiment demonstrates this invariance; if the estimator shifts when parallelism is reconfigured, the Goodput ranking can select configurations whose measured Goodput is high but whose actual time-to-target-loss is no better than the fixed-parallelism baseline.
Authors: The gradient noise scale estimator follows the standard formulation from prior critical-batch-size literature and is a statistical property of the loss surface and data distribution. When global batch size is held constant, changes in DP/TP/PP degree affect only the partitioning and aggregation of gradients, not the underlying per-sample gradient variance that determines noise scale. We will add a controlled experiment to the revised §3.2 that fixes batch size and micro-batch size while varying parallelism degree, confirming that noise-scale estimates remain consistent within measurement noise. revision: yes
-
Referee: [§4.3] §4.3 (Evaluation of reconfiguration overhead and statistical-efficiency term): The reported speedups include system overheads, yet the manuscript provides no breakdown of how much of the 3.9-8% gain survives after subtracting optimizer-state migration, pipeline flushing, and any transient increase in gradient noise immediately after a parallelism change. Without this, it is unclear whether the co-adaptive policy actually improves net convergence rate or merely redistributes time between throughput and statistical-efficiency phases.
Authors: All reported speedups are net wall-clock gains after every reconfiguration cost. We will augment §4.3 with a per-run breakdown (new table and timeline plots) that isolates time spent on optimizer migration, pipeline flush, and any post-reconfiguration gradient-noise transient, together with the cumulative loss curves before and after each change. This will show that selected reconfigurations produce sustained goodput improvements that exceed the one-time costs. revision: yes
Circularity Check
No circularity: Goodput definition and empirical speedups are modeling choices with independent validation
full rationale
The paper presents Goodput as an explicit modeling choice (product of measured throughput and statistical efficiency via gradient noise scale estimation) to jointly capture hardware and convergence effects, rather than deriving it tautologically from its own equations or inputs. The claimed coupling between batch size and 3D parallelism is argued from observable shifts in optimal configurations and validated through wall-clock measurements against baselines, with no step reducing a 'prediction' to a fitted parameter by construction. No self-citation is load-bearing for the central claim, and the derivation chain relies on external empirical evaluation rather than renaming or self-referential definitions. This is the common case of a self-contained systems paper whose results do not collapse to its own fitted quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhiwei Bai, Zhangchen Zhou, Jiajie Zhao, Xiaolong Li, Zhiyu Li, Feiyu Xiong, Hongkang Yang, Yaoyu Zhang, and Zhi-Qin John Xu. 2025. Adaptive Preconditioners Trigger Loss Spikes in Adam. arXiv:2506.04805 doi:10.48550/arXiv.2506.04805
-
[2]
Lukas Balles, Javier Romero, and Philipp Hennig. 2017. Coupling Adaptive Batch Sizes with Learning Rates. InProceedings of the Thirty- Third Conference on Uncertainty in Artificial Intelligence, UAI 2017, Sydney, Australia, August 11-15, 2017, Gal Elidan, Kristian Kersting, and Alexander T. Ihler (Eds.). AUAI Press.https://auai.org/uai2017/ proceedings/pa...
2017
-
[3]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. PaLM: Scaling Lan- guage Modeling with Pathways.Journal of Machine Learning Research 24, 240 (2023), 1–113.https://jmlr.org/papers/v24/22-1144.html
2023
-
[4]
Aditya Devarakonda, Maxim Naumov, and Michael Garland. 2017. AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks. arXiv:1712.02029 doi:10.48550/arXiv.1712.02029
-
[5]
Talfan Evans, Nikhil Parthasarathy, Hamza Merzić, and Olivier J. Hé- naff. 2024. Data curation via joint example selection further accelerates multimodal learning. InAdvances in Neural Information Processing Sys- tems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tom- czak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 141240– 1412...
-
[6]
Simin Fan and Martin Jaggi. 2023. Irreducible Curriculum for Language Model Pretraining. arXiv:2310.15389 doi:10.48550/arXiv.2310.15389
-
[7]
Oleg Filatov, Jan Ebert, Jiangtao Wang, and Stefan Kesselheim. 2024. Time Transfer: On Optimal Learning Rate and Batch Size In The Infinite Data Limit. arXiv:2410.05838 doi:10.48550/arXiv.2410.05838
-
[8]
Hao Ge, Fangcheng Fu, Haoyang Li, Xuanyu Wang, Sheng Lin, Yujie Wang, Xiaonan Nie, Hailin Zhang, Xupeng Miao, and Bin Cui. 2024. Enabling Parallelism Hot Switching for Efficient Training of Large Language Models. InProceedings of the ACM SIGOPS 30th Sympo- sium on Operating Systems Principles(Austin, TX, USA)(SOSP ’24). Association for Computing Machinery...
-
[9]
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. 2017. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv:1706.02677 doi:10.48550/arXiv.1706.02677
work page internal anchor Pith review doi:10.48550/arxiv.1706.02677 2017
-
[10]
Gavia Gray, Anshul Samar, and Joel Hestness. 2023. Efficient and Approximate Per-Example Gradient Norms for Gradient Noise Scale. InWorkshop on Advancing Neural Network Training at 37th Conference on Neural Information Processing Systems (W ANT@NeurIPS 2023).https: //openreview.net/forum?id=xINTMAvPQA
2023
-
[11]
Gavia Gray, Aman Tiwari, Shane Bergsma, and Joel Hestness. 2024. Normalization Layer Per-Example Gradients are Sufficient to Predict Gradient Noise Scale in Transformers. InAdvances in Neural Informa- tion Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 93510–9...
-
[12]
Dirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnus- son, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yul- ing Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik,...
-
[13]
Zhihao Jia, Matei Zaharia, and Alex Aiken. 2019. Beyond Data and Model Parallelism for Deep Neural Networks. InProceedings of Machine Learning and Systems 2019, MLSys 2019, Stanford, CA, USA, March 31 - April 2, 2019, Ameet Talwalkar, Virginia Smith, and Matei Zaharia (Eds.). mlsys.org.https://proceedings.mlsys.org/paper_files/paper/ 2019/hash/b422680f3db...
2019
-
[14]
Johnson, Pulkit Agrawal, Haijie Gu, and Carlos Guestrin
Tyler B. Johnson, Pulkit Agrawal, Haijie Gu, and Carlos Guestrin. 2020. AdaScale SGD: A User-Friendly Algorithm for Distributed Training. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event (Proceedings of Machine Learning Research, Vol. 119). PMLR, 4911–4920.https://proceedings. mlr.press/v11...
2020
-
[15]
K2 Team, Zhengzhong Liu, Liping Tang, Linghao Jin, Haonan Li, Nikhil Ranjan, Desai Fan, Shaurya Rohatgi, Richard Fan, Omkar Pangarkar, Huijuan Wang, Zhoujun Cheng, Suqi Sun, Seungwook Han, Bowen Tan, Gurpreet Gosal, Xudong Han, Varad Pimpalkhute, Shibo Hao, Ming Shan Hee, Joel Hestness, Haolong Jia, Liqun Ma, Aaryamonvikram Singh, Daria Soboleva, Natalia ...
-
[16]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Ben- jamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Mod- els. arXiv:2001.08361 doi:10.48550/arXiv.2001.08361
work page internal anchor Pith review doi:10.48550/arxiv.2001.08361 2020
-
[17]
Zhiquan Lai, Shengwei Li, Xudong Tang, Keshi Ge, Weijie Liu, Yabo Duan, Linbo Qiao, and Dongsheng Li. 2023. Merak: An Efficient Distributed DNN Training Framework With Automated 3D Parallelism for Giant Foundation Models.IEEE Trans. Parallel Distributed Syst.34, 5 (2023), 1466–1478. doi:10.1109/TPDS.2023.3247001
-
[18]
Tim Tsz-Kit Lau, Han Liu, and Mladen Kolar. 2024. AdAda- Grad: Adaptive Batch Size Schemes for Adaptive Gradient Methods. arXiv:2402.11215 doi:10.48550/arXiv.2402.11215
-
[19]
Mingzhen Li, Wencong Xiao, Hailong Yang, Biao Sun, Hanyu Zhao, Shiru Ren, Zhongzhi Luan, Xianyan Jia, Yi Liu, Yong Li, Wei Lin, and Depei Qian. 2023. EasyScale: Elastic Training with Consistent Accuracy and Improved Utilization on GPUs. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC 2023,...
-
[20]
Shuaipeng Li, Penghao Zhao, Hailin Zhang, Xingwu Sun, Hao Wu, Dian Jiao, Weiyan Wang, Chengjun Liu, Zheng Fang, Jinbao Xue, Yangyu Tao, Bin Cui, and Di Wang. 2024. Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C...
-
[21]
Xinyu Lian, Sam Ade Jacobs, Lev Kurilenko, Masahiro Tanaka, Stas Bekman, Olatunji Ruwase, and Minjia Zhang. 2025. Universal Check- pointing: A Flexible and Efficient Distributed Checkpointing System for Large-Scale DNN Training with Reconfigurable Parallelism. In 2025 USENIX Annual Technical Conference (USENIX ATC ’25). USENIX Association, 1519–1534.https...
2025
-
[22]
Zhiqi Lin, Youshan Miao, Quanlu Zhang, Fan Yang, Yi Zhu, Cheng Li, Saeed Maleki, Xu Cao, Ning Shang, Yilei Yang, Weijiang Xu, Mao Yang, Lintao Zhang, and Lidong Zhou. 2024. nnScaler: Constraint-Guided Parallelization Plan Generation for Deep Learning Training. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). USENIX Associ...
2024
-
[23]
Qian Liu, Xiaosen Zheng, Niklas Muennighoff, Guangtao Zeng, Longxu Dou, Tianyu Pang, Jing Jiang, and Min Lin. 2025. RegMix: Data Mixture as Regression for Language Model Pre-training. InThe Thir- teenth International Conference on Learning Representations.https: //openreview.net/forum?id=5BjQOUXq7i
2025
-
[24]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. In7th International Conference on Learning Representa- tions, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[25]
Hwang, Luca Soldaini, Akshita Bhagia, Jiacheng Liu, Dirk Groen- eveld, Oyvind Tafjord, Noah A
Ian Magnusson, Nguyen Tai, Ben Bogin, David Heineman, Jena D. Hwang, Luca Soldaini, Akshita Bhagia, Jiacheng Liu, Dirk Groen- eveld, Oyvind Tafjord, Noah A. Smith, Pang Wei Koh, and Jesse Dodge. 2025. DataDecide: How to Predict Best Pretraining Data with Small Experiments. InProceedings of the 42nd International Confer- ence on Machine Learning (Proceedin...
2025
-
[26]
Sadhika Malladi, Kaifeng Lyu, Abhishek Panigrahi, and Sanjeev Arora
-
[27]
On the SDEs and Scaling Rules for Adaptive Gradient Algo- rithms. InAdvances in Neural Information Processing Systems 35: An- nual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh (Eds.).https://proceeding...
2022
-
[28]
Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team
-
[29]
An Empirical Model of Large-Batch Training
An Empirical Model of Large-Batch Training. arXiv:1812.06162 doi:10.48550/arXiv.1812.06162
-
[30]
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher
-
[31]
In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings
Pointer Sentinel Mixture Models. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net.https://openreview. net/forum?id=Byj72udxe
2017
-
[32]
William Merrill, Shane Arora, Dirk Groeneveld, and Hannaneh Ha- jishirzi. 2025. Critical Batch Size Revisited: A Simple Empirical Approach to Large-Batch Language Model Training. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=XUKUx7Xu89
2025
-
[33]
Meta. 2024. Llama 3.2 Model Card. [https://github.com/meta-llama/ llama-models/blob/main/models/llama3_2/MODEL_CARD.md]. https://github.com/meta-llama/llama-models/blob/main/models/ llama3_2/MODEL_CARD.md
2024
-
[34]
Xupeng Miao, Yujie Wang, Youhe Jiang, Chunan Shi, Xiaonan Nie, Hailin Zhang, and Bin Cui. 2022. Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism.Proc. VLDB Endow.16, 3 (2022), 470–479. doi:10.14778/3570690.3570697
-
[35]
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. 2019. PipeDream: generalized pipeline parallelism for DNN training. InProceedings of the 27th ACM Symposium on Operating Systems Principles, SOSP 2019, Huntsville, ON, Canada, October 27-30, 2019, Tim Brecht and Ca...
-
[36]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGres- ley, Mostofa Patwary, Vijay Anand Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phan- ishayee, and Matei Zaharia. 2021. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. InInternational Conference for High Performanc...
-
[37]
Petr Ostroukhov, Aigerim Zhumabayeva, Chulu Xiang, Alexander Gasnikov, Martin Takáč, and Dmitry Kamzolov. 2025. AdaBatchGrad: Combining Adaptive Batch Size and Adaptive Step Size.IMA J. Numer. Anal.(2025), draf081. doi:10.1093/imanum/draf081
-
[38]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Brad- bury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, Hi...
2019
-
[39]
Ganger, and Eric P
Aurick Qiao, Sang Keun Choe, Suhas Jayaram Subramanya, Willie Neiswanger, Qirong Ho, Hao Zhang, Gregory R. Ganger, and Eric P. Xing. 2021. Pollux: Co-adaptive Cluster Scheduling for Goodput- Optimized Deep Learning. InProceedings of the 15th USENIX Sym- posium on Operating Systems Design and Implementation.https: //www.usenix.org/conference/osdi21/present...
2021
-
[40]
Heyang Qin, Samyam Rajbhandari, Olatunji Ruwase, Feng Yan, Lei Yang, and Yuxiong He. 2021. SimiGrad: Fine-Grained Adaptive Batch- ing for Large Scale Training using Gradient Similarity Measurement. InAdvances in Neural Information Processing Systems 34: Annual Con- ference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, v...
2021
-
[41]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[42]
Generalized Slow Roll for Tensors
ZeRO: memory optimizations toward training trillion parameter models. InProceedings of the International Conference for High Perfor- mance Computing, Networking, Storage and Analysis(Atlanta, Georgia) (SC ’20). IEEE Press, Article 20, 16 pages. doi:10.1109/SC41405.2020. 00024
-
[43]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He
-
[44]
DeepSpeed: System Optimizations Enable Training Deep Learn- ing Models with Over 100 Billion Parameters. InKDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Min- ing, Virtual Event, CA, USA, August 23-27, 2020, Rajesh Gupta, Yan Liu, Jiliang Tang, and B. Aditya Prakash (Eds.). ACM, 3505–3506. doi:10.1145/3394486.3406703
-
[45]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. Hybrid- Flow: A Flexible and Efficient RLHF Framework. InProceedings of the Twentieth European Conference on Computer Systems(Rotterdam, Netherlands)(EuroSys ’25). Association for Computing Machinery, New York, NY, USA, 1279–1297. doi:1...
-
[46]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv:1909.08053 doi:10.48550/arXiv.1909.08053
work page internal anchor Pith review doi:10.48550/arxiv.1909.08053 2019
-
[47]
Smith, Pieter-Jan Kindermans, Chris Ying, and Quoc V
Samuel L. Smith, Pieter-Jan Kindermans, Chris Ying, and Quoc V. Le
-
[48]
In6th International Conference on Learning Representations, ICLR 2018, Van- couver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings
Don’t Decay the Learning Rate, Increase the Batch Size. In6th International Conference on Learning Representations, ICLR 2018, Van- couver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net.https://openreview.net/forum?id=B1Yy1BxCZ
2018
-
[49]
Sho Takase, Shun Kiyono, Sosuke Kobayashi, and Jun Suzuki. 2025. Spike No More: Stabilizing the Pre-training of Large Language Models. InSecond Conference on Language Modeling.https://openreview.net/ forum?id=52YBEzcI0l
2025
-
[50]
Gemini Team. 2023. Gemini: A Family of Highly Capable Multimodal Models. arXiv:2312.11805 doi:10.48550/arXiv.2312.11805
-
[51]
Llama Team. 2023. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288 doi:10.48550/arXiv.2307.09288
work page internal anchor Pith review doi:10.48550/arxiv.2307.09288 2023
-
[52]
Llama Team. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 doi:10.48550/arXiv.2407.21783
work page internal anchor Pith review doi:10.48550/arxiv.2407.21783 2024
-
[53]
Qwen Team. 2024. Qwen2.5 Technical Report. arXiv:2412.15115 doi:10. 48550/arXiv.2412.15115
work page internal anchor Pith review arXiv 2024
-
[54]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie- Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971 doi:10.48550/arXiv. 2302.13971
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[55]
Colin Unger, Zhihao Jia, Wei Wu, Sina Lin, Mandeep Baines, Carlos Efrain Quintero Narvaez, Vinay Ramakrishnaiah, Nirmal Prajapati, Pat McCormick, Jamaludin Mohd-Yusof, Xi Luo, Dheevatsa Mudigere, Jongsoo Park, Misha Smelyanskiy, and Alex Aiken. 2022. Unity: Ac- celerating DNN Training Through Joint Optimization of Algebraic Transformations and Paralleliza...
2022
-
[56]
Borui Wan, Mingji Han, Yiyao Sheng, Yanghua Peng, Haibin Lin, Mo- fan Zhang, Zhichao Lai, Menghan Yu, Junda Zhang, Zuquan Song, Xin Liu, and Chuan Wu. 2025. ByteCheckpoint: A Unified Check- pointing System for Large Foundation Model Development. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI ’25). USENIX Association, 559–578....
2025
-
[57]
Wencong Xiao, Romil Bhardwaj, Ramachandran Ramjee, Muthian Si- vathanu, Nipun Kwatra, Zhenhua Han, Pratyush Patel, Xuan Peng, Hanyu Zhao, Quanlu Zhang, Fan Yang, and Lidong Zhou. 2018. Gan- diva: Introspective Cluster Scheduling for Deep Learning. In13th USENIX Symposium on Operating Systems Design and Implementa- tion (OSDI 18). USENIX Association, Carls...
2018
-
[58]
Wencong Xiao, Shiru Ren, Yong Li, Yang Zhang, Pengyang Hou, Zhi Li, Yihui Feng, Wei Lin, and Yangqing Jia. 2020. AntMan: Dynamic Scaling on GPU Clusters for Deep Learning. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). USENIX Association, 533–548.https://www.usenix.org/conference/osdi20/ presentation/xiao
2020
-
[59]
Le, Tengyu Ma, and Adams Wei Yu
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanx- iao Liu, Yifeng Lu, Percy Liang, Quoc V. Le, Tengyu Ma, and Adams Wei Yu. 2023. DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining. InAdvances in Neural Infor- mation Processing Systems 36: Annual Conference on Neural In- formation Processing Systems 2023, NeurIPS 2023, New Orleans...
2023
-
[60]
Gspmd: general and scalable parallelization for ml computation graphs
Yuanzhong Xu, HyoukJoong Lee, Dehao Chen, Blake A. Hechtman, Yanping Huang, Rahul Joshi, Maxim Krikun, Dmitry Lepikhin, Andy 15 Ly, Marcello Maggioni, Ruoming Pang, Noam Shazeer, Shibo Wang, Tao Wang, Yonghui Wu, and Zhifeng Chen. 2021. GSPMD: General and Scalable Parallelization for ML Computation Graphs. arXiv:2105.04663 doi:10.48550/arXiv.2105.04663
-
[61]
Hanlin Zhang, Depen Morwani, Nikhil Vyas, Jingfeng Wu, Di- fan Zou, Udaya Ghai, Dean Foster, and Sham Kakade. 2025. How Does Critical Batch Size Scale in Pre-training?. InIn- ternational Conference on Learning Representations, Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (Eds.), Vol. 2025. 66756– 66782.https://proceedings.iclr.cc/paper_files/paper/2025/fil...
2025
-
[62]
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. 2022. OPT: Open Pre-trained Transformer Language Models. arXiv:2205.01068 doi:10....
work page internal anchor Pith review doi:10.48550/arxiv.2205.01068 2022
-
[63]
Xinyi Zhang, Hanyu Zhao, Wencong Xiao, Xianyan Jia, Fei Xu, Yong Li, Wei Lin, and Fangming Liu. 2025. Rubick: Exploiting Job Recon- figurability for Deep Learning Cluster Scheduling. InProceedings of Machine Learning and Systems, M. Zaharia, G. Joshi, and Y. Lin (Eds.), Vol. 7. MLSys.https://proceedings.mlsys.org/paper_files/paper/2025/ file/270339c997293...
2025
-
[64]
Xing, Joseph E
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. 2022. Alpa: Au- tomating Inter- and Intra-Operator Parallelism for Distributed Deep Learning. InProceedings of the 16th USENIX Symposium on Operat- ing Systems Design and Implementation...
2022
-
[65]
Extract the source shards of the current model weights and optimizer state
-
[66]
Stage those shards in host memory and release the current model/optimizer GPU state
-
[67]
Destroy the old process groups and reconstruct the groups for the target topology
-
[68]
Rebuild the model and optimizer under the new groups
-
[69]
Load the staged state into the target shard layout and resume training. 17 Host-memory staging is necessary because the source shard data must survive the process-group reconstruction gap, but keeping both the old and new layouts resident on GPU would exceed the memory budget of a single active configuration. Using CPU memory as the transient staging laye...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.