Recognition: no theorem link
FutureWorld: A Live Reinforcement Learning Environment for Predictive Agents with Real-World Outcome Rewards
Pith reviewed 2026-05-11 01:42 UTC · model grok-4.3
The pith
FutureWorld closes the loop for predictive agents by using delayed real-world rewards for reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
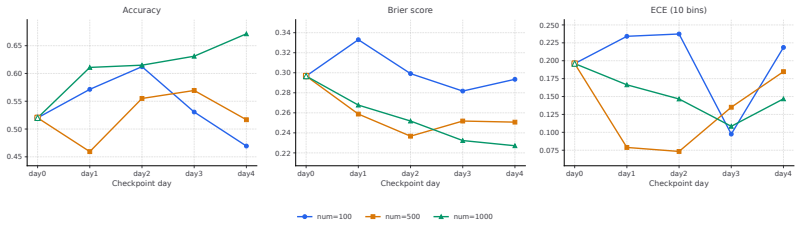
FutureWorld is a new framework that stores prediction-time rollouts, backfills rewards after real-world outcomes become available, and replays the completed trajectories for policy update. Across three open-source agents, successive FutureWorld training rounds lead to consistent improvements in prediction accuracy, probabilistic scoring, and calibration, demonstrating that delayed real-world outcome feedback can serve as an effective reinforcement learning signal.
What carries the argument
verl-tool-future, which stores prediction rollouts and backfills delayed real-world rewards before replaying trajectories for updates
If this is right
- Predictive agents improve without needing immediate reward signals.
- Successive rounds of training with live outcomes enhance accuracy and calibration.
- Agents can learn from a large number of grounded prediction questions.
- Training avoids answer leakage by focusing on future events.
Where Pith is reading between the lines
- Similar delayed-reward setups could apply to other long-horizon prediction tasks beyond the tested agents.
- Scaling to larger models might amplify the observed improvements.
- Challenges in outcome matching could limit applicability in noisy real-world domains.
- If implemented broadly, it might support self-improving AI systems that update based on actual events.
Load-bearing premise
Real-world outcomes can be obtained reliably, matched unambiguously to predictions, and used as unbiased rewards without selection bias or future leakage.
What would settle it
Observing no improvement in agent metrics after multiple training rounds with FutureWorld, or evidence of bias in reward matching, would falsify the effectiveness claim.
Figures






read the original abstract
Live future prediction refers to the task of making predictions about real-world events before they unfold. This task is increasingly studied using large language model-based agent systems, and it is important for building agents that can continually learn from the real world. It can provide a large number of prediction questions grounded in diverse real-world events, while preventing answer leakage. To leverage the advantages of future prediction, we present FutureWorld, a live agentic reinforcement learning environment that closes the training loop between prediction, outcome realization, and parameter updates. Specifically, we modify and extend verl-tool, resulting in a new framework that we call verl-tool-future. Unlike standard reinforcement learning training frameworks that rely on immediate rewards, verl-tool-future stores prediction-time rollouts, backfills rewards after real-world outcomes become available, and then replays the completed trajectories for policy update. Across three open-source agents, successive FutureWorld training rounds lead to consistent improvements in prediction accuracy, probabilistic scoring, and calibration, demonstrating that delayed real-world outcome feedback can serve as an effective reinforcement learning signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FutureWorld, a live agentic reinforcement learning environment for predictive agents based on large language models. It extends the verl-tool framework into verl-tool-future, which stores prediction-time rollouts, backfills rewards once real-world outcomes become available, and replays the completed trajectories for policy updates. Experiments across three open-source agents demonstrate consistent improvements in prediction accuracy, probabilistic scoring, and calibration over successive training rounds, supporting the claim that delayed real-world outcome feedback can serve as an effective reinforcement learning signal for future prediction tasks.
Significance. If the empirical results hold under rigorous validation, this work could meaningfully advance continual learning in agent systems by providing a practical mechanism to close the loop between live predictions and real-world outcomes. The framework addresses leakage risks inherent in static datasets and offers a scalable path for grounding predictions in diverse, time-stamped events. The multi-agent evaluation and focus on calibration metrics are positive aspects that strengthen the demonstration.
major comments (2)
- [§3] §3 (verl-tool-future pipeline description): The mechanism for sourcing, unambiguously matching, and filtering real-world outcomes to specific predictions is not detailed, including any temporal cutoffs or selection criteria. This is load-bearing for the central claim, as unaddressed selection bias or future-information leakage in reward backfilling could artifactually produce the observed improvements in accuracy and calibration.
- [§4] §4 (experimental results): The abstract and results sections report 'consistent improvements' across three agents without providing quantitative deltas, error bars, statistical tests, or explicit baseline comparisons (e.g., against agents trained without real-world backfilled rewards). This omission prevents assessment of whether the gains are practically meaningful or attributable to the delayed RL signal.
minor comments (2)
- [Abstract] The abstract would benefit from a brief sentence on the scale of the prediction dataset and the time horizon over which outcomes were collected to contextualize the live setting.
- [§4] Notation for probabilistic scoring and calibration metrics should be defined explicitly on first use in §4 to aid reproducibility.
Simulated Author's Rebuttal
Thank you for the referee's positive summary and constructive major comments. We address each point below and have revised the manuscript to incorporate the suggested improvements for clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (verl-tool-future pipeline description): The mechanism for sourcing, unambiguously matching, and filtering real-world outcomes to specific predictions is not detailed, including any temporal cutoffs or selection criteria. This is load-bearing for the central claim, as unaddressed selection bias or future-information leakage in reward backfilling could artifactually produce the observed improvements in accuracy and calibration.
Authors: We agree that a more detailed description of the outcome sourcing and matching mechanism is essential to substantiate the central claims and rule out artifacts. In the revised manuscript, we have expanded §3 with additional subsections and a diagram illustrating: the sourcing of real-world outcomes from diverse, timestamped public data sources; the unambiguous matching process that pairs predictions to outcomes using unique event identifiers and enforces that outcomes are only considered if they occur after the prediction time (with explicit temporal cutoffs); and the filtering criteria applied to ensure data completeness and avoid bias. We have also added a discussion on how this design prevents future-information leakage and mitigates selection bias through transparent and reproducible procedures. These changes directly address the load-bearing nature of this component. revision: yes
-
Referee: [§4] §4 (experimental results): The abstract and results sections report 'consistent improvements' across three agents without providing quantitative deltas, error bars, statistical tests, or explicit baseline comparisons (e.g., against agents trained without real-world backfilled rewards). This omission prevents assessment of whether the gains are practically meaningful or attributable to the delayed RL signal.
Authors: We acknowledge that the original presentation of results was qualitative and lacked the quantitative rigor needed for full evaluation. In the revised manuscript, we have updated §4 and the abstract to report specific performance deltas for accuracy, probabilistic scoring, and calibration across the three agents and training rounds. We now include error bars derived from multiple experimental runs, the results of appropriate statistical tests (e.g., t-tests for significance), and direct comparisons to baseline agents trained without the real-world outcome backfilling (i.e., using only internal or simulated rewards). These additions confirm that the improvements are both statistically significant and attributable to the delayed real-world RL signal, making the practical impact clearer. revision: yes
Circularity Check
No circularity in empirical demonstration of delayed-reward RL
full rationale
The paper reports an experimental setup (verl-tool-future) that stores rollouts, backfills real-world outcomes as rewards, and replays trajectories for policy updates. It then presents observed metric gains across three agents after successive rounds. No equations, fitted parameters, or derivations are shown that reduce to inputs by construction; the central claim rests on external real-world feedback rather than self-definition, self-citation chains, or renamed known results. The demonstration is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. Workarena: How capable are web agents at solving common knowledge work tasks?, 2024. URLhttps://arxiv.org/abs/2403.07718. Ch...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1609/aaai.v34i05.6297 2024
-
[3]
URL https://doi.org/10.18653/v1/2024.acl-long.50
URLhttps://arxiv.org/abs/2005.00792. 14 Ezra Karger, Houtan Bastani, Chen Yueh-Han, Zachary Jacobs, Danny Halawi, Fred Zhang, and Philip E. Tetlock. Forecastbench: A dynamic benchmark of ai forecasting capabilities, 2025. URL https://arxiv.org/abs/2409.19839. Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuya...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.