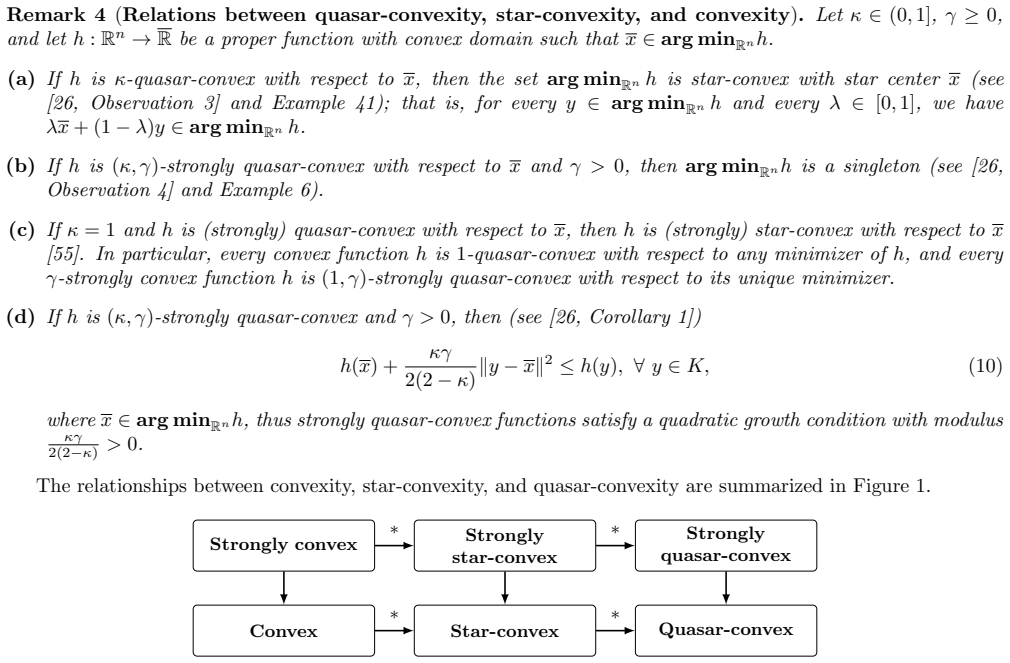
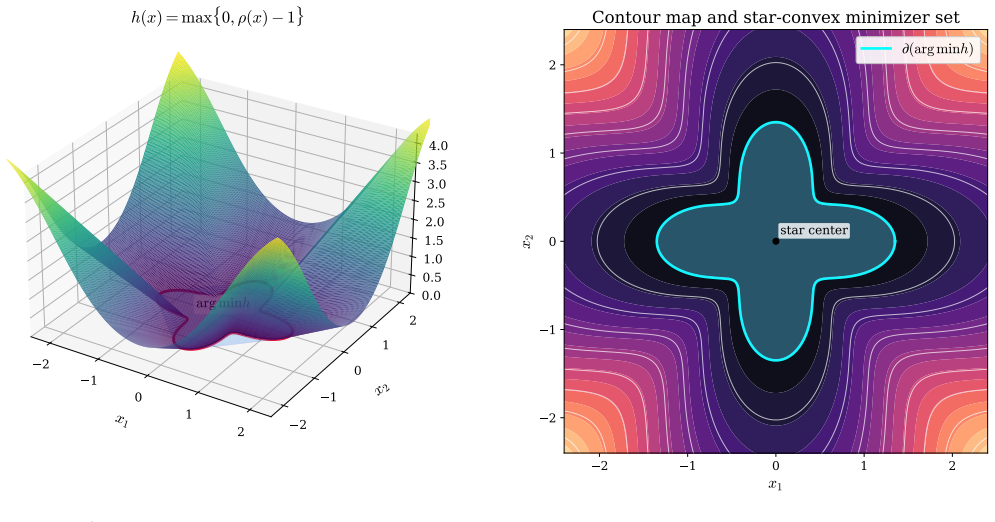
Recognition: unknown
Quasar-Convex Optimization: Fundamental Properties and High-Order Proximal-Point Methods
Pith reviewed 2026-05-07 11:19 UTC · model grok-4.3
The pith
Quasar-convex problems admit high-order proximal-point methods whose convergence jumps from linear to superlinear when the regularization order exceeds 2.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For quasar-convex functions the high-order proximal-point methods converge globally to minimizers. The rate is locally linear with complexity O(log(ε^{-1})) when the regularization order p lies in (1,2), globally linear with the same complexity when p equals 2, and superlinear with complexity O(log log(ε^{-1})) when p exceeds 2.
What carries the argument
The HiPPA family of proximal-point algorithms that regularize the objective with a term of order p greater than 1 and generate the next iterate by minimizing the resulting model.
Where Pith is reading between the lines
- These methods could be applied to non-convex machine learning models if quasar-convexity can be established or promoted during training.
- An adaptive strategy that increases the regularization order p during the run might combine fast early progress with eventual superlinear speedup.
- The same high-order proximal construction may extend to other function classes that share the saddle-free geometry but lack quasar-convexity.
- Stochastic or distributed versions of HiPPA would be a natural next step for large-scale data science problems.
Load-bearing premise
The functions satisfy regularity assumptions sufficient to support the unified convergence analysis and explicit rate derivations.
What would settle it
Numerical computation of the iterates of the method with p equals 3 on a simple quasar-convex test function that shows only linear error reduction rather than superlinear reduction would refute the superlinear convergence claim.
Figures



read the original abstract
We study the optimization of (strongly) quasar-convex functions, a class that arises naturally in many machine learning and data science applications due to its favorable properties. The fundamental properties of this class are first developed, including its stability under standard calculus operations, growth conditions, and the absence of spurious critical points, which together imply a benign global geometry with no saddle points. Motivated by these properties, a class of proximal-point algorithms (HiPPA) with high-order regularization of order $p>1$ is introduced. Conditions are identified under which the iterates converge globally to minimizers, and a unified convergence analysis is provided with explicit rates and iteration complexity bounds under appropriate regularity assumptions. The results reveal a sharp transition in behavior with respect to the order $p$: for $p\in(1,2)$, the method achieves local linear convergence with complexity $\mathcal{O}(\log(\varepsilon^{-1}))$ when initialized sufficiently close to a minimizer; for $p=2$, it attains global linear convergence with the same complexity; and for $p>2$, it exhibits superlinear convergence with complexity $\mathcal{O}(\log\log(\varepsilon^{-1}))$, where $\varepsilon>0$ denotes the target accuracy. The theory is complemented with preliminary numerical experiments on selected machine learning problems, which illustrate the effectiveness of the proposed methods and are consistent with the theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops fundamental properties of (strongly) quasar-convex functions, including stability under standard operations, growth conditions, and absence of spurious critical points implying benign global geometry. It introduces a class of high-order proximal-point algorithms (HiPPA) with regularization order p>1. Under identified conditions and appropriate regularity assumptions, it provides a unified convergence analysis yielding explicit rates and complexity bounds: local linear convergence with O(log(ε^{-1})) for p∈(1,2) when initialized near a minimizer; global linear convergence with the same complexity for p=2; and superlinear convergence with O(log log(ε^{-1})) for p>2. Preliminary numerical experiments on machine learning problems are included to illustrate the results.
Significance. If the rates are shown to apply under conditions that follow from quasar-convexity (or clearly delineated additional assumptions), the work offers a useful unified framework for proximal methods on this class of functions relevant to ML applications. The development of basic properties and the sharp transition in rates with respect to p are strengths; the explicit complexity expressions and numerical support add value.
major comments (1)
- [Abstract and convergence analysis section] Abstract and the unified convergence analysis (around the main theorems on rates): The claimed sharp transition in convergence behavior (local linear for p∈(1,2), global linear for p=2, superlinear O(log log(ε^{-1})) for p>2) is stated to hold under 'appropriate regularity assumptions.' Quasar-convexity ensures no spurious critical points and benign geometry via the growth inequality, but does not automatically imply the higher-order smoothness, Lipschitz continuity of derivatives, or error-bound conditions typically required for high-order proximal-point analyses. If these regularity conditions are additional rather than derived from strong quasar-convexity, the explicit rates apply only to a subclass and the claim that the behavior is characteristic of the quasar-convex class is not fully supported. Please clarify in the theorem statements whether the assumptions follow from the quasar
minor comments (2)
- Ensure consistent use of notation for the target accuracy ε and the order p across theorems and complexity statements.
- The numerical experiments section could benefit from more details on how the test problems satisfy the quasar-convexity and regularity assumptions.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the manuscript. We address the major comment point by point below and will revise the paper to improve clarity on the assumptions.
read point-by-point responses
-
Referee: [Abstract and convergence analysis section] Abstract and the unified convergence analysis (around the main theorems on rates): The claimed sharp transition in convergence behavior (local linear for p∈(1,2), global linear for p=2, superlinear O(log log(ε^{-1})) for p>2) is stated to hold under 'appropriate regularity assumptions.' Quasar-convexity ensures no spurious critical points and benign geometry via the growth inequality, but does not automatically imply the higher-order smoothness, Lipschitz continuity of derivatives, or error-bound conditions typically required for high-order proximal-point analyses. If these regularity conditions are additional rather than derived from strong quasar-convexity, the explicit rates apply only to a subclass and the claim that the behavior is characteristic of the quasar-convex class is not fully supported. Please clarify in the theorem statements是否
Authors: We agree that the higher-order smoothness, Lipschitz continuity of derivatives, and related error-bound conditions do not follow from (strong) quasar-convexity. Quasar-convexity provides the key geometric properties (growth inequality, absence of spurious critical points, and benign global landscape), but the explicit convergence rates for HiPPA require additional regularity to bound the proximal mapping error and establish the stated rates. In the revised manuscript we will: (i) update the abstract to state that the rates hold for quasar-convex functions satisfying the listed regularity assumptions; (ii) revise the statements of the main theorems to list the assumptions explicitly and note that they are independent of quasar-convexity; and (iii) add a short remark after the theorems clarifying that the sharp transition in rates is characteristic of the subclass obeying both quasar-convexity and the regularity conditions. These changes will remove any ambiguity that the rates apply to the entire quasar-convex class without qualification. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper first establishes fundamental properties of quasar-convex functions directly from the given growth inequality definition, including stability under operations and absence of spurious critical points. It then introduces the HiPPA class of proximal-point methods with p-order regularization and derives convergence rates explicitly from the stated regularity assumptions and the quasar-convex geometry. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the explicit complexity bounds (local linear for p in (1,2), global linear for p=2, superlinear for p>2) follow from the unified analysis under the listed conditions rather than tautological renaming or imported uniqueness. The derivation remains self-contained against the paper's own assumptions and external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Quasar-convex functions have no spurious critical points and benign global geometry
- domain assumption Appropriate regularity assumptions hold to obtain explicit convergence rates
Reference graph
Works this paper leans on
-
[1]
[1]M. Ahookhosh, A. Iusem, A. Kabgani, and F. Lara,Asymptotic convergence analysis of high-order proximal-point methods beyond sublinear rates, arXiv:2505.20484, (2025),https://doi.org/10.48550/arXiv. 2505.20484. [2]M. Ahookhosh and Y. Nesterov,High-order methods beyond the classical complexity bounds: Inexact high-order proximal-point methods with segmen...
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[2]
[7]A. Bodard, M. Ahookhosh, and P. Patrinos,Second-order methods for provably escaping strict saddle points in composite nonconvex and nonsmooth optimization, arXiv:2506.22332, (2025). [8]J. Bolte, A. Daniilidis, and A. S. Lewis,The Lojasiewicz inequality for nonsmooth subanalytic functions with applications to subgradient dynamical systems, SIAM Journal ...
-
[3]
Extending Linear Convergence of the Proximal Point Algorithm: The Quasar-Convex Case
[11]D. Davis, M. D ´ıaz, and D. Drusvyatskiy,Escaping strict saddle points of the Moreau envelope in nons- mooth optimization, SIAM Journal on Optimization, 32 (2022), pp. 1958–1983. [12]D. Davis and D. Drusvyatskiy,Proximal methods avoid active strict saddles of weakly convex functions, Foundations of Computational Mathematics, 22 (2022), pp. 561–606. [1...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
[16]S.-M. Grad, F. Lara, and R. T. Marcavillaca,Strongly quasiconvex functions: What we know (so far), Journal of Optimization Theory and Applications, 205:38 (2025). [17]B. Grimmer and D. Li,Some primal-dual theory for subgradient methods for strongly convex optimization, Mathematical Programming, (2025), pp. 1–30. [18]G. Gu and J. Yang,Tight sublinear c...
2025
-
[5]
[23]N. Hadjisavvas, F. Lara, R. T. Marcavillaca, and P. T. Vuong,Heavy ball and nesterov accelerations with hessian-driven damping for nonconvex optimization, Applied Mathematics and Optimization, (2026), https://doi.org/10.1007/s00245-026-10406-2. [24]M. Hardt, T. Ma, and B. Recht,Gradient descent learns linear dynamical systems, Journal of Machine Learn...
-
[6]
Numerical Algorithms, DOI: 10.1007/s11075-025-02276-6 , year=
[42]F. Lara and C. Vega,Delayed feedback in online non-convex optimization: a non-stationary approach with applications, Numerical Algorithms, DOI: 10.1007/s11075-025-02276-6, (2025). [43]J. C. Lee and P. Valiant,Optimizing star-convex functions, in 2016 IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS), IEEE, 2016, pp. 603–614. [44]J. ...
-
[7]
Nesterov,Inexact high-order proximal-point methods with auxiliary search procedure, SIAM Journal on Optimization, 31 (2021), pp
[53]Y. Nesterov,Inexact high-order proximal-point methods with auxiliary search procedure, SIAM Journal on Optimization, 31 (2021), pp. 2807–2828. [54]Y. Nesterov,Inexact accelerated high-order proximal-point methods, Mathematical Programming, 197 (2023), pp. 1–26. [55]Y. Nesterov and B. T. Polyak,Cubic regularization of Newton method and its global perfo...
2021
-
[8]
Parikh and S
[57]N. Parikh and S. Boyd,Proximal algorithms, Foundations and Trends ® in Optimization, 1 (2014), pp. 127–
2014
-
[9]
42 [58]R.-A. Poliquin and R.-T. Rockafellar,Prox-regular functions in variational analysis, Transactions of the American Mathematical Society, 348 (1996), pp. 1805–1838. [59]Y.-M. Pun and I. Shames,Online non-stationary stochastic quasar-convex optimization, arXiv preprint arXiv:2407.03601, (2024). [60]R. T. Rockafellar,Monotone operators and the proximal...
-
[10]
[63]R. Vidal, Z. Zhu, and B. D. Haeffele,Optimization landscape of neural networks, in Mathematical Aspects of Deep Learning, P. Grohs and G. Kutyniok, eds., Cambridge University Press, 2022, p. 200–228. [64]E.-V. Vlatakis-Gkaragkounis, L. Flokas, and G. Piliouras,Efficiently avoiding saddle points with zero order methods: No gradients required, Advances ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.