Recognition: unknown
Distributed Multi-View Vision-Only RSSI Estimation
Pith reviewed 2026-05-07 10:59 UTC · model grok-4.3
The pith
Transformer fusion of distributed camera views estimates wireless signal strength from vision alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors propose MulViT-TF, a vision-only RSSI estimation framework that exploits distributed multi-view observations through Transformer-based fusion, achieving complementary spatial coverage without any auxiliary sensing inputs. Experimental results across two distinct indoor scenes demonstrate that MulViT-TF achieves RMSE reductions of up to 26.3% and improves the 3dB error coverage by up to 13.8 percentage points over the best-performing single-view baseline, while using fewer FLOPs and parameters.
What carries the argument
MulViT-TF, a Transformer-based fusion module that integrates features from multiple distributed camera views to produce a single RSSI estimate.
If this is right
- Wireless systems can manage links proactively without waiting for uplink feedback.
- Indoor deployments gain spatial diversity for RSSI prediction using only existing cameras.
- Computational cost drops relative to single-view baselines while accuracy rises.
- No additional hardware or sensing modalities are required for the estimation task.
Where Pith is reading between the lines
- The same multi-view fusion pattern could be tested on moving cameras or outdoor scenes where coverage changes over time.
- If the approach generalizes, it opens the possibility of replacing dedicated signal-strength feedback with vision-derived estimates in dense networks.
- Combining the RSSI output with other vision tasks performed on the same cameras could yield shared sensing infrastructure.
Load-bearing premise
Distributed camera views will always supply enough complementary angles to overcome line-of-sight blockages that affect any one camera.
What would settle it
A controlled test in which all cameras share the same blockage geometry and the multi-view fusion shows no accuracy gain over the single best view.
Figures


read the original abstract
Received Signal Strength Indicator (RSSI) estimation is essential for wireless link management, yet conventional feedback-based approaches incur uplink overhead, suffer from measurement instability, and are subject to inherent feedback loop latency, rendering proactive adaptation infeasible. Although vision-based approaches have been explored, existing methods remain limited by hardware dependency or auxiliary inputs, and lack the spatial diversity needed to resolve camera-side NLoS conditions. To address these limitations, we propose MulViT-TF, a vision-only RSSI estimation framework that exploits distributed multi-view observations through Transformer-based fusion, achieving complementary spatial coverage without any auxiliary sensing inputs. Experimental results across two distinct indoor scenes demonstrate that MulViT-TF achieves RMSE reductions of up to 26.3% and improves the 3dB error coverage by up to 13.8 percentage points over the best-performing single-view baseline, while using fewer FLOPs and parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MulViT-TF, a vision-only RSSI estimation framework that fuses distributed multi-view camera observations using a Transformer architecture to achieve complementary spatial coverage without auxiliary sensing inputs or hardware dependencies. It reports empirical results from two indoor scenes showing RMSE reductions of up to 26.3% and 3dB error coverage improvements of up to 13.8 percentage points over the best single-view baseline, along with reduced FLOPs and parameter counts.
Significance. If the results hold, the work would be significant for enabling low-latency, feedback-free RSSI prediction in wireless systems by leveraging only vision-based multi-view observations to mitigate NLoS issues. It extends prior vision-based RSSI methods by incorporating spatial diversity through distributed cameras and efficient Transformer fusion, while demonstrating computational efficiency gains. The empirical comparisons to single-view baselines provide a clear baseline for assessing the multi-view contribution.
major comments (2)
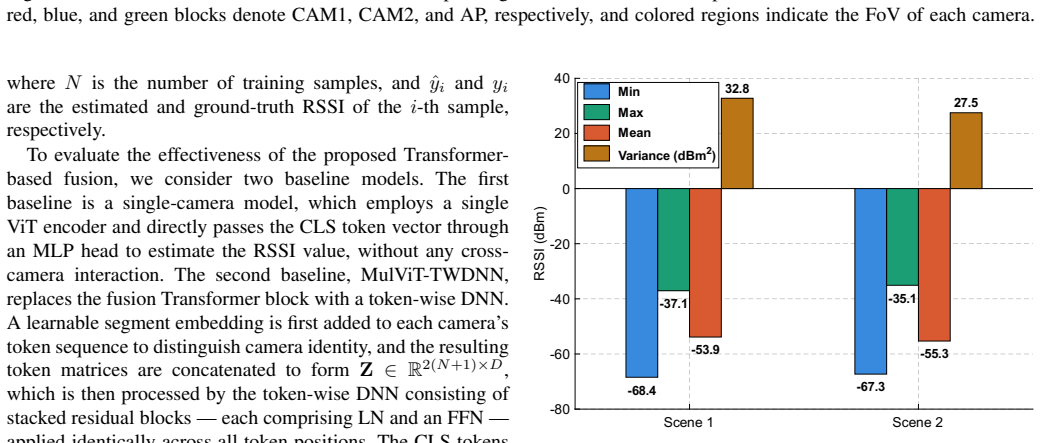
- [Experimental evaluation] The reported gains (26.3% RMSE reduction and 13.8 pp 3dB coverage improvement) lack supporting details on dataset sizes, training procedures, statistical significance tests, or error bars, which are required to assess robustness against scene-specific biases or overfitting in the two indoor environments.
- [Method and results] No ablation studies or controlled experiments (such as selectively blocking views to isolate NLoS conditions) are presented to confirm that the Transformer-based fusion exploits genuinely complementary spatial information from multiple views, as opposed to simply benefiting from increased total pixel data or learned scene correlations.
minor comments (1)
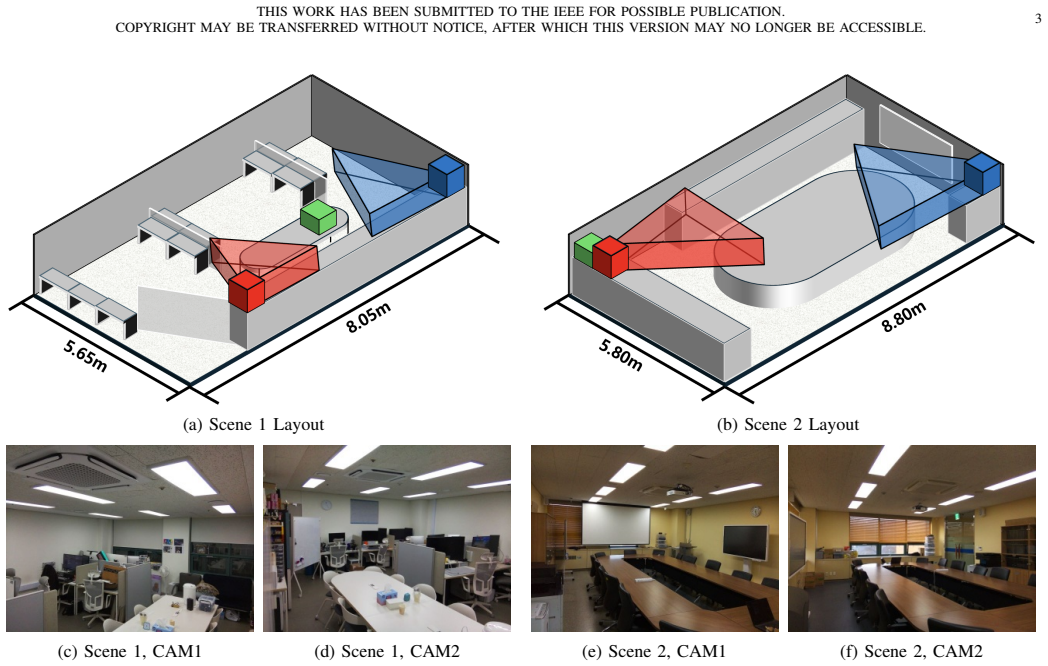
- [Abstract] The abstract and introduction would benefit from a brief description of the two indoor scenes' characteristics (e.g., size, layout, or differences) to better contextualize the generalizability of the findings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments below and will incorporate revisions to strengthen the experimental evaluation and provide additional supporting analyses.
read point-by-point responses
-
Referee: [Experimental evaluation] The reported gains (26.3% RMSE reduction and 13.8 pp 3dB coverage improvement) lack supporting details on dataset sizes, training procedures, statistical significance tests, or error bars, which are required to assess robustness against scene-specific biases or overfitting in the two indoor environments.
Authors: We agree that additional details are required to allow readers to fully assess robustness. In the revised manuscript, we will expand Section IV (Experimental Results) to report: exact dataset sizes (training, validation, and test sample counts per scene), complete training procedures (hyperparameters, optimizer settings, loss function, batch size, and number of epochs), error bars computed over multiple independent runs with different random seeds, and statistical significance tests (e.g., paired t-tests with p-values) between MulViT-TF and the single-view baselines. These additions will directly address concerns about scene-specific biases or overfitting. revision: yes
-
Referee: [Method and results] No ablation studies or controlled experiments (such as selectively blocking views to isolate NLoS conditions) are presented to confirm that the Transformer-based fusion exploits genuinely complementary spatial information from multiple views, as opposed to simply benefiting from increased total pixel data or learned scene correlations.
Authors: We acknowledge that the current single-view versus multi-view comparisons, while demonstrating overall gains, do not fully isolate the contribution of complementary spatial information. In the revised manuscript, we will add a dedicated ablation subsection. This will include: (i) controlled experiments that selectively mask or block individual camera views to simulate NLoS conditions and quantify the resulting performance degradation, and (ii) comparisons against alternative fusion strategies (e.g., feature concatenation or averaging) to show that the Transformer architecture specifically leverages spatial diversity rather than merely increasing input data volume. These studies will be performed on the same two indoor scenes. revision: yes
Circularity Check
No circularity; empirical claims rest on direct baseline comparisons
full rationale
The paper presents MulViT-TF as a proposed architecture for multi-view vision-based RSSI estimation and supports its claims solely through experimental RMSE and coverage metrics on two indoor scenes versus single-view baselines. No derivation chain, equations, or first-principles results are offered that reduce by construction to fitted inputs, self-citations, or renamed empirical patterns. The reported gains are framed as outcomes of the method's design and training, not as tautological predictions. Self-contained empirical evaluation with no load-bearing self-referential steps yields a non-circular finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
QoE-based reduction of handover delay for multimedia application in IEEE 802.11 networks,
H. Zhang, Z. Lu, X. Wen, and Z. Hu, “QoE-based reduction of handover delay for multimedia application in IEEE 802.11 networks,”IEEE Commun. Lett., vol. 19, no. 11, pp. 1873–1876, Nov. 2015
2015
-
[2]
In- telligent distributed beam selection for cell-free massive MIMO hybrid precoding,
C. Zhang, X. Zhang, L. Wei, Q. Xu, Y . Huang, and W. Zhang, “In- telligent distributed beam selection for cell-free massive MIMO hybrid precoding,”IEEE Commun. Lett., vol. 27, no. 11, pp. 2973–2977, Nov. 2023
2023
-
[3]
Implementation of a grey prediction system based on fuzzy inference for transmission power control in IoT edge sensor nodes,
G. Moreno, G. Mujica, J. Portilla, and J.-S. Lee, “Implementation of a grey prediction system based on fuzzy inference for transmission power control in IoT edge sensor nodes,”IEEE Internet Things J., vol. 11, no. 11, pp. 20404–20420, Jun. 2024
2024
-
[4]
Millimeter- wave communication with out-of-band information,
N. Gonz ´alez-Prelcic, A. Ali, V . Va, and R. W. Heath Jr., “Millimeter- wave communication with out-of-band information,”IEEE Commun. Mag., vol. 55, no. 12, pp. 140–146, Dec. 2017
2017
-
[5]
Role of sensing and computer vision in 6G wireless communications,
S. Kim, J. Moon, J. Kim, Y . Ahn, D. Kim, and S. Kim, “Role of sensing and computer vision in 6G wireless communications,”IEEE Wireless Commun., vol. 31, no. 5, pp. 264–271, Oct. 2024
2024
-
[6]
Distributed multimodal 2.4 GHz Wi-Fi received signal strength indicator prediction for wireless resilient robot operation,
K. N. Nguyen, K. Takizawa, and T. Nara, “Distributed multimodal 2.4 GHz Wi-Fi received signal strength indicator prediction for wireless resilient robot operation,”IEEE Access, 2025
2025
-
[7]
Reading radio from camera: Visually-grounded, lightweight, and interpretable RSSI prediction,
S. Yan, T. Hu, B. Mefgouda, S. Lasaulce, and M. Debbah, “Reading radio from camera: Visually-grounded, lightweight, and interpretable RSSI prediction,”arXiv preprint arXiv:2510.25936, 2025
-
[8]
Vision aided channel prediction for vehicular communications: A case study of received power prediction using RGB images,
X. Zhang, R. He, M. Yang, Z. Zhang, Z. Qi, and B. Ai, “Vision aided channel prediction for vehicular communications: A case study of received power prediction using RGB images,”IEEE Trans. V eh. Technol., vol. 74, no. 11, pp. 17531–17544, Nov. 2025
2025
-
[9]
Proactive received power prediction using machine learning and depth images for mmWave networks,
T. Nishioet al., “Proactive received power prediction using machine learning and depth images for mmWave networks,”IEEE J. Sel. Areas Commun., vol. 37, no. 11, pp. 2413–2427, Nov. 2019
2019
-
[10]
Vision-aided 6G wireless communications: Blockage prediction and proactive handoff,
G. Charan, M. Alrabeiah, and A. Alkhateeb, “Vision-aided 6G wireless communications: Blockage prediction and proactive handoff,”IEEE Trans. V eh. Technol., vol. 70, no. 10, pp. 10193–10208, Oct. 2021
2021
-
[11]
Vision-assisted near-field channel estimation for XL-MIMO systems,
Q. Zhang, Z. Zhou, Q. Liu, and L. Yang, “Vision-assisted near-field channel estimation for XL-MIMO systems,”IEEE Trans. Cogn. Com- mun. Netw., 2025
2025
-
[12]
Vision and causal learning based channel estimation for THz communications,
K. Kim, Y . K. Tun, M. S. Munir, C. K. Thomas, W. Saad, and C. S. Hong, “Vision and causal learning based channel estimation for THz communications,”IEEE Trans. Mobile Comput., 2026
2026
-
[13]
Can wireless environment information decrease pilot overhead: A channel prediction example,
L. Shi, J. Zhang, L. Yu, Y . Zhang, Z. Zhang, and Y . Cai, “Can wireless environment information decrease pilot overhead: A channel prediction example,”IEEE Wireless Commun. Lett., vol. 14, no. 3, pp. 861–865, Mar. 2025
2025
-
[14]
Computer vision aided mmWave beam alignment in V2X communications,
W. Xu, F. Gao, X. Tao, J. Zhang, and A. Alkhateeb, “Computer vision aided mmWave beam alignment in V2X communications,”IEEE Trans. Wireless Commun., vol. 22, no. 4, pp. 2699–2714, Apr. 2022
2022
-
[15]
Toward intelligent millimeter and terahertz communication for 6G: Computer vision-aided beamforming,
Y . Ahn, J. Kim, S. Kim, K. Shim, J. Kim, and S. Kim, “Toward intelligent millimeter and terahertz communication for 6G: Computer vision-aided beamforming,”IEEE Wireless Commun., vol. 30, no. 5, pp. 179–186, Oct. 2022
2022
-
[16]
Out-of-band modality synergy based multi-user beam prediction and proactive BS selection with zero pilot overhead,
K. Li, B. Zhou, J. Guo, F. Gao, G. Yang, and S. Ma, “Out-of-band modality synergy based multi-user beam prediction and proactive BS selection with zero pilot overhead,”IEEE Trans. Commun., 2026
2026
-
[17]
Computer vision aided codebook design for MIMO communications systems,
J. Chen, F. Gao, X. Tao, G. Liu, C. Pan, and A. Alkhateeb, “Computer vision aided codebook design for MIMO communications systems,” IEEE Trans. Wireless Commun., vol. 22, no. 5, pp. 3341–3354, May 2022
2022
-
[18]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review arXiv 2010
-
[19]
Attention is all you need,
A. Vaswaniet al., “Attention is all you need,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2017, pp. 5998–6008
2017
-
[20]
Places: A 10 million image database for scene recognition,
B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 6, pp. 1452–1464, Jun. 2018
2018
-
[21]
Training data-efficient image transformers & distillation through atten- tion,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrol `es, and H. J´egou, “Training data-efficient image transformers & distillation through atten- tion,” inProc. Int. Conf. Mach. Learn. (ICML), 2021, pp. 10347–10357
2021
-
[22]
SGDR: Stochastic gradient descent with warm restarts,
I. Loshchilov and F. Hutter, “SGDR: Stochastic gradient descent with warm restarts,” inProc. Int. Conf. Learn. Represent. (ICLR), 2017
2017
-
[23]
Internet time synchronization: The network time protocol,
D. L. Mills, “Internet time synchronization: The network time protocol,” IEEE Trans. Commun., vol. 39, no. 10, pp. 1482–1493, Oct. 1991
1991
-
[24]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. Int. Conf. Learn. Represent. (ICLR), 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.