Recognition: unknown
Learning Sparse BRDF Measurement Samples from Image
Pith reviewed 2026-05-07 10:46 UTC · model grok-4.3
The pith
A sampler optimized via gradients from a fixed hypernetwork reconstructor selects sparse BRDF directions that improve low-budget material reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Measurement locations optimized by gradients through a fixed hypernetwork-based BRDF reconstructor and differentiable renderer produce sampling patterns that improve low-budget reconstruction quality, outperforming neural baselines at 8 and 16 samples on the MERL dataset while PCA-based methods remain competitive at higher budgets.
What carries the argument
A trainable sampler that uses gradients from a frozen hypernetwork reconstructor and image-space losses to optimize sparse measurement directions, decoupling sample selection from prior fitting.
If this is right
- The learned sampler produces higher-quality reconstructions than neural baselines at budgets of 8 and 16 measurements on the MERL dataset.
- PCA-based reconstruction methods outperform the proposed sampler at larger measurement budgets.
- Image-space supervision changes the quality of reconstructions for unseen materials compared with BRDF-space losses alone.
- Keeping the reconstructor fixed during sampler training yields different results than co-optimizing both components.
Where Pith is reading between the lines
- The same gradient-driven selection could be applied to other parametric reflectance models if a suitable fixed reconstructor is available.
- Running the trained sampler on real captured images rather than synthetic renders would test whether the image-loss term remains effective outside simulation.
- If the hypernetwork prior is sufficiently general, the selected directions might transfer across different camera and lighting setups without retraining.
Load-bearing premise
The fixed pretrained hypernetwork reconstructor supplies reliable gradients that identify informative measurement directions even for materials outside the distribution used to train the reconstructor.
What would settle it
For a material from the MERL dataset, reconstruction error using the learned 8-sample directions exceeds the error obtained from randomly selected directions of the same count.
Figures




read the original abstract
Accurate BRDF acquisition is important for realistic rendering, but dense gonioreflectometer measurements are slow and expensive. We study how to select a small number of BRDF measurements that are most useful for reconstructing material appearance under a learned reflectance prior. Our method combines a set encoder for sparse coordinate-value observations, a pretrained hypernetwork-based BRDF reconstructor, and a differentiable renderer. During sampler training, the reconstructor is kept fixed and gradients from BRDF-space and rendered-image losses are used to optimize measurement locations. This separates sample selection from prior fitting and encourages the sampler to choose directions that are informative under the learned material distribution. Experiments on the MERL dataset show that the proposed sampler improves low-budget reconstruction quality at 8 and 16 measurements compared with neural reconstruction baselines, while PCA-based methods remain strong at larger budgets. We further analyze the effect of image-space supervision, co-optimization, and image-only latent fitting for unseen materials.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a method to learn sparse BRDF measurement samples by optimizing a sampler network while keeping a pretrained hypernetwork-based reconstructor fixed, using gradients from both BRDF-space losses and a differentiable renderer for image-space supervision. Sample selection is decoupled from prior fitting to encourage selection of directions informative under the learned material distribution. Experiments on the MERL dataset claim that the learned sampler yields better low-budget reconstruction quality at 8 and 16 measurements than neural reconstruction baselines, although PCA-based methods remain competitive at larger budgets; additional analyses examine image-only latent fitting and co-optimization for unseen materials.
Significance. If the central experimental claims hold after addressing generalization concerns, the work would be significant for efficient BRDF acquisition: it shows that separating sampler optimization from reconstructor fitting can produce useful sparse sampling strategies under a learned reflectance prior, and the use of image-space losses via differentiable rendering is a practical strength. The approach avoids circularity by relying on external losses rather than self-referential fitting.
major comments (2)
- [Method and Experiments] The core claim in the abstract and experiments section rests on the fixed pretrained hypernetwork producing reliable gradients for measurement selection on test materials outside its training distribution. Because the hypernetwork encodes a prior over a finite set, its gradient field on out-of-distribution BRDFs may be biased or noisy; the manuscript should add an explicit ablation (e.g., hypernetwork trained on a strict subset of MERL materials, sampler evaluated on held-out materials) to demonstrate that the selected directions actually improve reconstruction for truly unseen BRDFs rather than merely appearing useful under the training distribution.
- [Experiments] Table or figure reporting the 8- and 16-measurement results: the quantitative gains over neural baselines must be accompanied by the precise error metric (BRDF RMSE, image-space PSNR/SSIM, etc.), the number of test materials, and statistical significance or variance across runs. Without these, it is difficult to judge whether the reported improvement at low budgets is robust or sensitive to post-hoc choices in the reconstructor or loss weighting.
minor comments (2)
- [Abstract and Related Work] The abstract mentions 'neural reconstruction baselines' and 'PCA-based methods' without naming the specific architectures or references; add these citations and a brief description in the related-work section.
- [Method] Notation for the set encoder and measurement locations should be introduced once with a clear diagram or equation; repeated re-definition across sections reduces readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the generalization analysis and clarify the experimental reporting.
read point-by-point responses
-
Referee: [Method and Experiments] The core claim in the abstract and experiments section rests on the fixed pretrained hypernetwork producing reliable gradients for measurement selection on test materials outside its training distribution. Because the hypernetwork encodes a prior over a finite set, its gradient field on out-of-distribution BRDFs may be biased or noisy; the manuscript should add an explicit ablation (e.g., hypernetwork trained on a strict subset of MERL materials, sampler evaluated on held-out materials) to demonstrate that the selected directions actually improve reconstruction for truly unseen BRDFs rather than merely appearing useful under the training distribution.
Authors: We agree that an explicit ablation on strictly held-out materials would strengthen the generalization claim. The manuscript already trains the hypernetwork on a random split of MERL and evaluates the sampler on held-out materials (as noted in the unseen-materials analysis), but to directly address the concern we will add a new ablation: the hypernetwork will be retrained on a strict subset (e.g., 70 materials) while the sampler is optimized and evaluated exclusively on the remaining held-out materials. This will confirm that the selected directions remain informative under the learned prior for truly out-of-distribution BRDFs. revision: yes
-
Referee: [Experiments] Table or figure reporting the 8- and 16-measurement results: the quantitative gains over neural baselines must be accompanied by the precise error metric (BRDF RMSE, image-space PSNR/SSIM, etc.), the number of test materials, and statistical significance or variance across runs. Without these, it is difficult to judge whether the reported improvement at low budgets is robust or sensitive to post-hoc choices in the reconstructor or loss weighting.
Authors: We will revise the experiments section, tables, and figures to explicitly report the primary error metric (BRDF RMSE), the exact number of test materials and train/test split from the MERL dataset, and variance (standard deviation) across multiple runs with different random seeds. These additions will make the low-budget improvements transparent and allow readers to assess robustness with respect to reconstructor and loss choices. revision: yes
Circularity Check
No significant circularity; sampler optimization separated from reconstructor fitting
full rationale
The paper keeps the hypernetwork reconstructor fixed during sampler training and optimizes measurement locations using gradients from independent BRDF-space and rendered-image losses plus a differentiable renderer. No equations or claims reduce the reported reconstruction improvements on MERL (at 8/16 samples) to a quantity defined by the fit itself. The central derivation relies on external pretrained priors and standard losses, remaining self-contained against the provided baselines and dataset benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- measurement budget =
8, 16
axioms (2)
- domain assumption A pretrained hypernetwork-based BRDF reconstructor provides a sufficiently accurate prior for material appearance
- domain assumption Gradients from BRDF-space and rendered-image losses can be used to optimize informative measurement locations
Reference graph
Works this paper leans on
-
[1]
L., TORRANCEK
[CT82] COOKR. L., TORRANCEK. E.: A reflectance model for com- puter graphics.ACM Transactions on Graphics (ToG) 1, 1 (1982), 7–24. 2 [Cyb89] CYBENKOG. V.: Approximation by superpositions of a sigmoidal function. vol. 2, pp. 303–314. URL:https://api. semanticscholar.org/CorpusID:3958369. 1 [DAD∗19] DESCHAINTREV., AITTALAM., DURANDF., DRETTAKIS G., BOUSSEAU...
1982
-
[2]
URL:http: //arxiv.org/abs/1906.11557
arXiv:1906.11557 [cs]. URL:http: //arxiv.org/abs/1906.11557. 2 submitted to EUROGRAPHICS
-
[3]
[DJ18] DUPUYJ., JAKOBW.: An adaptive parameterization for effi- cient material acquisition and rendering.ACM Transactions on graphics (TOG) 37, 6 (2018), 1–14
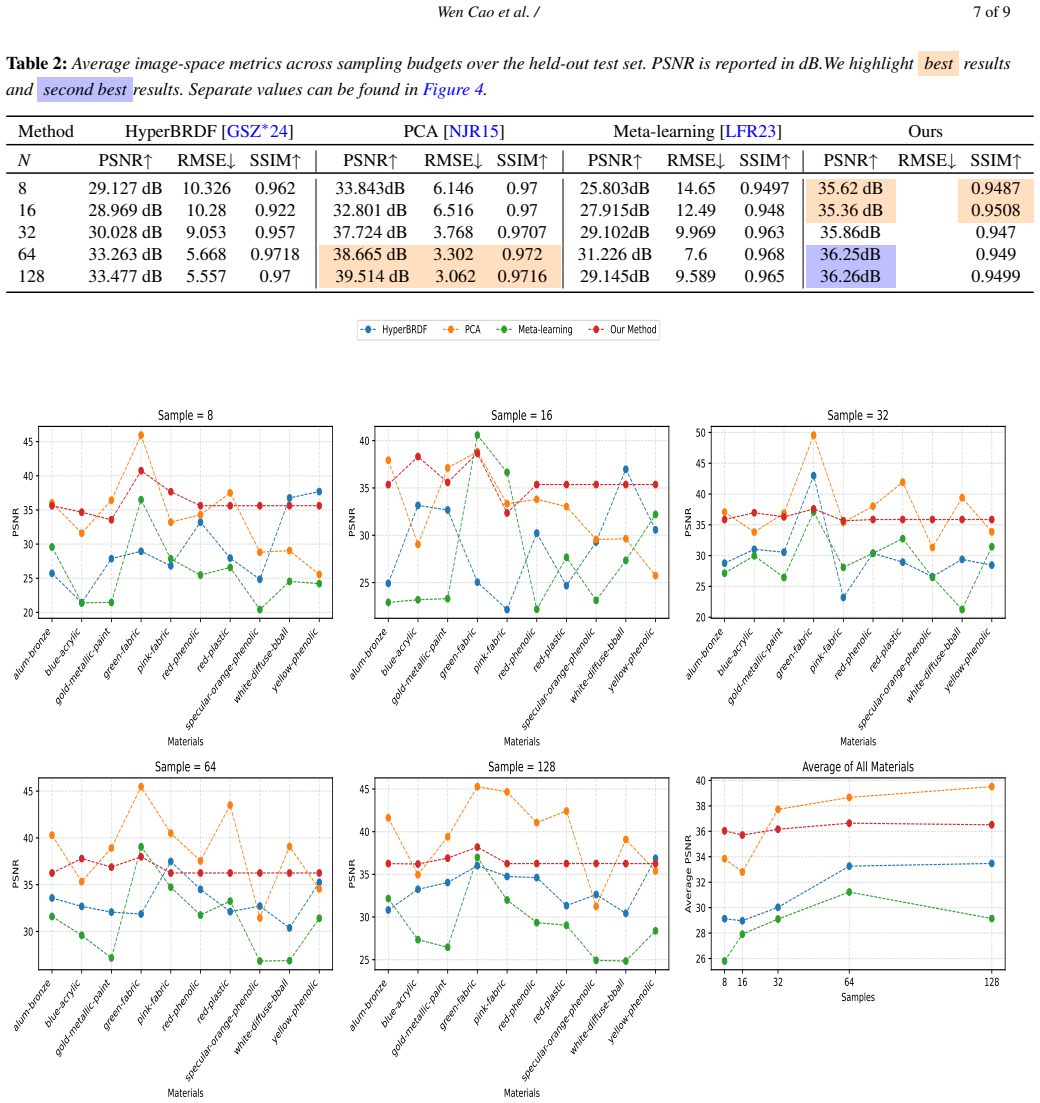
The plots show how reconstruction quality changes as the number of BRDF samples increases for every test material. [DJ18] DUPUYJ., JAKOBW.: An adaptive parameterization for effi- cient material acquisition and rendering.ACM Transactions on graphics (TOG) 37, 6 (2018), 1–14. 2 [F∗97] FOOS. C.,ET AL.:A gonioreflectometer for measuring the bidi- rectional re...
2018
-
[4]
8 of 9Wen Cao et al. / (a) Ground Truth (b) Reconstruction from fittedz ⋆ (c) Reconstruction from sparse samples of learnedz ⋆ Figure 5:Image-space validation on a previously unseen material without dense ground-truth BRDF measurements as (a). We estimate the latent code z ⋆ by minimizing the discrepancy between rendered images and ground truth, while kee...
-
[5]
https://mitsuba-renderer.org. 4 [Kaj86] KAJIYAJ. T.: The rendering equation. InProceedings of the 13th Annual Conference on Computer Graphics and Interactive Tech- niques(New York, NY , USA, 1986), SIGGRAPH ’86, Association for Computing Machinery, pp. 143–150. URL:https://doi.org/10. 1145/15922.15902,doi:10.1145/15922.15902. 3 [KHM∗24] KAVOOSIGHAFIB., HA...
-
[6]
URL:http:// arxiv.org/abs/2210.03510
arXiv:2210.03510 [cs]. URL:http:// arxiv.org/abs/2210.03510. 2, 3, 4, 5, 7 [Mat03] MATUSIKW.:A data-driven reflectance model. PhD thesis, Massachusetts Institute of Technology,
-
[7]
URL:https:// www.merl.com/publications/TR2003-83,doi:10.1145/ 882262.882343
2 [MPBM03] MATUSIKW., PFISTERH., BRANDM., MCMILLAN L.: A data-driven reflectance model.ACM Transactions on Graphics (TOG) 22, 3 (July 2003), 759–769. URL:https:// www.merl.com/publications/TR2003-83,doi:10.1145/ 882262.882343. 4, 6 [MTH∗24] MIANDJIE., TONGBUASIRILAIT., HAJISHARIFS., KAVOOSIGHAFIB., UNGERJ.: FROST-BRDF: A Fast and Ro- bust Optimal Sampling...
-
[8]
arXiv:2401.07283 [cs]. URL:http://arxiv.org/abs/2401. 07283,doi:10.48550/arXiv.2401.07283. 2 [NJR15] NIELSENJ. B., JENSENH. W., RAMAMOORTHIR.: On op- timal, minimal brdf sampling for reflectance acquisition.ACM Trans. Graph. 34, 6 (Nov. 2015). URL:https://doi.org/10.1145/ 2816795.2818085,doi:10.1145/2816795.2818085. 2, 3, 4, 5, 7 [PGM∗19] PASZKEA., GROSSS...
-
[9]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
URL:https://arxiv.org/abs/1912.01703, arXiv:1912.01703. 4 [Pho98] PHONGB. T.: Illumination for computer generated pictures. In Seminal graphics: pioneering efforts that shaped the field(1998), Asso- ciation for Computing Machinery, pp. 95–101. 2 [PJH16] PHARRM., JAKOBW., HUMPHREYSG.:Physically Based Rendering: From Theory to Implementation (3rd ed.), 3rd ...
work page internal anchor Pith review arXiv 1912
-
[10]
M.: A new change of variables for efficient brdf representation
3 [Rus98] RUSINKIEWICZS. M.: A new change of variables for efficient brdf representation. InRendering Techniques ’98(Vienna, 1998), Dret- takis G., Max N., (Eds.), Springer Vienna, pp. 11–22. 2, 4 [TUK17] TONGBUASIRILAIT., UNGERJ., KURTM.: Efficient BRDF Sampling Using Projected Deviation Vector Parameterization. In2017 IEEE International Conference on Co...
-
[11]
2 [WMLT07] WALTERB., MARSCHNERS
URL:https://doi.org/10.1145/142920.134078, doi:10.1145/142920.134078. 2 [WMLT07] WALTERB., MARSCHNERS. R., LIH., TORRANCEK. E.: Microfacet models for refraction through rough surfaces. InProceedings of the 18th Eurographics Conference on Rendering Techniques(Goslar, DEU, 2007), EGSR’07, Eurographics Association, pp. 195–206. 2 [Zen24] ZENGZ.: RGB↔X: Image...
-
[12]
/9 of 9 KALLWEITS., LEFOHNA.: Real-time neural appearance models.ACM Trans
Wen Cao et al. /9 of 9 KALLWEITS., LEFOHNA.: Real-time neural appearance models.ACM Trans. Graph. 43, 3 (June 2024). URL:https://doi.org/10. 1145/3659577,doi:10.1145/3659577. 2 [ZSD∗21] ZHANGX., SRINIVASANP. P., DENGB., DEBEVECP., FREEMANW. T., BARRONJ. T.: NeRFactor: neural factorization of shape and reflectance under an unknown illumination.ACM Trans- a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.