Recognition: unknown
From Hypotheses to Factors: Constrained LLM Agents in Cryptocurrency Markets
Pith reviewed 2026-05-07 12:29 UTC · model grok-4.3
The pith
Constrained LLM agents discover cryptocurrency factors that achieve 44.55 percent annualized returns out of sample.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
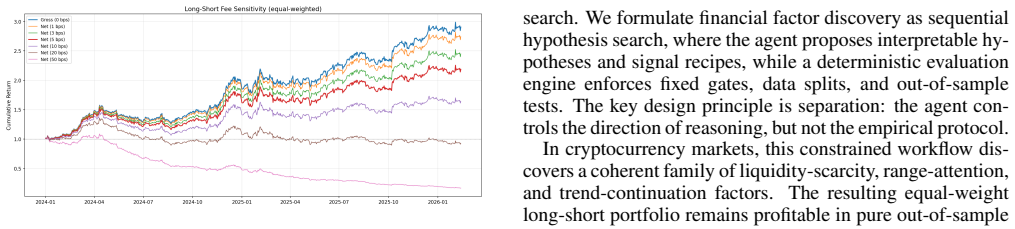
The central claim is that LLM agents, when restricted to proposing hypotheses through a fixed point-in-time domain-specific language and paired with a deterministic engine that enforces append-only traces, selection gates, and transaction costs, can generate cryptocurrency factors whose ridge-combined portfolio produces 44.55 percent annualized returns and a Sharpe ratio of 1.55 in pure out-of-sample trading from 2024 to 2026 after costs, using only 2020-2022 training data.
What carries the argument
The sequential hypothesis search protocol that pairs an LLM agent with a deterministic engine enforcing fixed rules, data splits, and a restricted factor DSL for auditable proposals.
If this is right
- All proposed hypotheses, successful or failed, remain traceable through the experiment trace.
- The deterministic engine removes selection bias by fixing proposal and testing rules outside the language model.
- Portfolios trained solely on early data maintain performance in later periods after accounting for trading costs.
- The approach turns open-ended LLM search into a reproducible process for empirical factor discovery.
Where Pith is reading between the lines
- The protocol suggests LLMs can assist idea generation in finance when gated to prevent data leakage or overfitting.
- Similar constrained search could be tested on equity or futures markets to check if the performance edge generalizes.
- The reported returns might indicate that cryptocurrency markets contain more persistent, exploitable patterns than many traditional assets.
- Extending trace length or testing alternative combination methods could further raise the Sharpe ratio.
Load-bearing premise
The LLM-generated factor hypotheses remain genuinely out-of-sample and are not influenced by patterns the model may have encountered in its pre-training data or through the sequential trace, and that the deterministic engine fully eliminates selection bias during hypothesis proposal.
What would settle it
Rerunning the agent on the identical initial trace and checking whether it proposes exactly the same factors, or testing the discovered factors on post-2026 data and seeing whether the reported returns persist, would directly test the claim.
Figures


read the original abstract
LLM agents are promising tools for empirical discovery, but their flexibility can also turn discovery into uncontrolled search. We study how to use agents under a reproducible protocol through cryptocurrency factor discovery. Our framework casts the task as sequential hypothesis search: an agent reads an append-only experiment trace, proposes falsifiable factor hypotheses, and maps them to executable recipes, while a deterministic engine enforces fixed data splits, selection gates, transaction costs, and portfolio tests. Candidate actions are restricted to a point-in-time factor DSL, making both successful and failed hypotheses auditable. A ridge-combined portfolio trained only on 2020--2022 data achieves a 44.55% annualized return and Sharpe ratio of 1.55 in the 2024--2026 pure out-of-sample period after a 5 basis point one-way trading cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for cryptocurrency factor discovery using constrained LLM agents. It frames the task as sequential hypothesis search with an append-only trace to ensure reproducibility, where the agent proposes hypotheses mapped to a point-in-time factor DSL, enforced by a deterministic engine for splits, gates, costs, and tests. The main empirical finding is that a ridge-combined portfolio trained on 2020-2022 data delivers 44.55% annualized returns and a Sharpe ratio of 1.55 in the pure out-of-sample 2024-2026 period after 5 bp one-way costs.
Significance. This approach offers a structured way to leverage LLMs for discovery while maintaining auditability and reducing bias through constraints, which is a notable strength for the field. The use of fixed protocols and DSL makes both positive and negative results verifiable. If the performance holds without contamination from pre-training data, it could open avenues for AI-assisted factor research in finance, particularly in data-rich but noisy domains like crypto.
major comments (2)
- Abstract: The headline result is presented without accompanying details on the number of hypotheses tested, the specific factors discovered, any error bars or statistical tests, or explicit checks that the LLM did not leak future information through its pre-trained knowledge. This lack of information leaves the central claim difficult to assess.
- LLM Agent Framework (protocol description): Although the protocol uses an append-only trace stopping at 2022 and a deterministic engine, there is no discussion or audit of the LLM's pre-training cutoff date. This raises the risk that hypotheses incorporate post-2022 patterns from the model's training corpus, making the 2024-2026 OOS performance potentially non-prospective.
minor comments (1)
- Consider adding a table or appendix listing the proposed and selected factor hypotheses for better transparency and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [—] Abstract: The headline result is presented without accompanying details on the number of hypotheses tested, the specific factors discovered, any error bars or statistical tests, or explicit checks that the LLM did not leak future information through its pre-trained knowledge. This lack of information leaves the central claim difficult to assess.
Authors: We agree that the abstract's brevity limits the inclusion of supporting details. The main text provides information on the hypothesis search process, the factors discovered, error bars in the performance figures, and the statistical tests applied to the portfolio results. We will revise the abstract to briefly reference the scale of the search and the out-of-sample validation protocol. The pre-training leakage concern is addressed in the response to the second comment. revision: yes
-
Referee: [—] LLM Agent Framework (protocol description): Although the protocol uses an append-only trace stopping at 2022 and a deterministic engine, there is no discussion or audit of the LLM's pre-training cutoff date. This raises the risk that hypotheses incorporate post-2022 patterns from the model's training corpus, making the 2024-2026 OOS performance potentially non-prospective.
Authors: We acknowledge this concern. In the revised manuscript we will add a discussion within the LLM Agent Framework section specifying the model employed and its training cutoff date, together with an explanation of how the append-only trace (limited to 2022), the point-in-time DSL, and the deterministic engine together prevent the use of any post-2022 information in hypothesis generation or evaluation. This design keeps the 2024-2026 results strictly prospective. revision: yes
- Complete independent audit of the LLM's proprietary pre-training corpus to confirm the total absence of any post-2022 information.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an empirical protocol in which an LLM agent generates factor hypotheses from an append-only trace limited to 2020-2022, maps them via a point-in-time DSL, and feeds them to a deterministic engine that fixes data splits, gates, costs, and tests. The reported result is a ridge portfolio explicitly trained only on the 2020-2022 window and evaluated on the 2024-2026 period. No equation, definition, or selection step is shown to reduce the out-of-sample return or Sharpe ratio to a quantity fitted on the test data, to a self-referential definition, or to a load-bearing self-citation. The structure therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Ridge regression produces stable factor combinations without excessive overfitting
- domain assumption Fixed data splits and transaction costs fully prevent look-ahead bias
Reference graph
Works this paper leans on
-
[1]
Empirical crypto asset pricing.arXiv preprint arXiv:2405.15716,
Adam Baybutt. Empirical crypto asset pricing.arXiv preprint arXiv:2405.15716,
-
[2]
Jian Chen, Guohao Tang, Guofu Zhou, and Wu Zhu. Chat- GPT and DeepSeek: Can they predict the stock market and macroeconomy?arXiv preprint arXiv:2502.10008,
-
[3]
Chanyeol Choi, Yoon Kim, Yu Yu, Young Cha, V Zach Golkhou, Igor Halperin, Georgios Papaioannou, Minkyu Kim, Zhangyang Wang, Jihoon Kwon, et al. From text to alpha: Can LLMs track evolving signals in corporate dis- closures?arXiv preprint arXiv:2510.03195,
-
[4]
Chronologically consistent large language models.arXiv preprint arXiv:2502.21206,
Songrun He, Linying Lv, Asaf Manela, and Jimmy Wu. Chronologically consistent large language models.arXiv preprint arXiv:2502.21206,
-
[5]
Beyond Prompting: An Autonomous Framework for Systematic Factor Investing via Agentic AI
Allen Yikuan Huang and Zheqi Fan. Beyond prompting: An autonomous framework for systematic factor investing via agentic ai.arXiv preprint arXiv:2603.14288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Cross-Stock Predictability via LLM-Augmented Semantic Networks
Yikuan Huang, Zheqi Fan, Kaiqi Hu, and Yifan Ye. Cross- stock predictability via llm-augmented semantic networks. arXiv preprint arXiv:2604.19476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Alejandro Lopez-Lira and Yuehua Tang. Can ChatGPT fore- cast stock price movements? return predictability and large language models.arXiv preprint arXiv:2304.07619,
-
[8]
BloombergGPT: A Large Language Model for Finance
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. BloombergGPT: A large language model for finance.arXiv preprint arXiv:2303.17564,
work page internal anchor Pith review arXiv
-
[9]
Qianqian Xie, Weiguang Han, Xiao Zhang, Yanzhao Lai, Min Peng, Alejandro Lopez-Lira, and Jimin Huang. Pixiu: A large language model, instruction data and evaluation benchmark for finance.arXiv preprint arXiv:2306.05443,
-
[10]
Behavioral anomalies in cryptocurrency mar- kets.Available at SSRN 3174421, 2019
Hanlin Yang. Behavioral anomalies in cryptocurrency mar- kets.Available at SSRN 3174421, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.