Recognition: unknown
Bridge: Basis-Driven Causal Inference Marries VFMs for Domain Generalization
Pith reviewed 2026-05-07 13:34 UTC · model grok-4.3
The pith
Bridge learns low-rank bases for front-door adjustment to block domain confounders and improve object detection generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Bridge learns low-rank bases for front-door adjustment from source-domain data. These bases block the causal paths through which confounders reach the output, thereby removing spurious correlations that degrade generalization. The same bases simultaneously filter redundant and task-irrelevant information from the representations. When the resulting adjustment is combined with vision foundation models, the detector achieves higher performance on cross-domain benchmarks including Cross-Camera, Adverse Weather, Real-to-Artistic, and the new Diverse Weather DroneVehicle dataset.
What carries the argument
Low-rank bases that approximate the front-door adjustment operator, blocking confounder paths while refining representations.
If this is right
- Object detectors become less reliant on source-specific confounders such as lighting or co-occurrence patterns.
- Representations are automatically cleaned of redundant components without extra supervision.
- The same causal mechanism works with both discriminative and generative vision foundation models.
- Performance gains appear across multiple distribution-shift scenarios including weather, camera, and artistic style changes.
- A new real-world UAV benchmark demonstrates practical gains under diverse weather conditions.
Where Pith is reading between the lines
- The same low-rank causal adjustment could be applied to other dense prediction tasks such as segmentation or depth estimation.
- Because the bases are low-rank, the method may scale more efficiently to very large foundation models than full causal-graph methods.
- If the bases capture stable causal structure, they might be reused across multiple target domains without relearning.
- Extending the framework to multi-source settings could test whether the low-rank approximation remains sufficient when more source variation is available.
Load-bearing premise
Low-rank bases learned only from source data can faithfully approximate the front-door adjustment operator and remove all relevant confounders in the unseen target domain.
What would settle it
Training a detector with the learned bases on source data and then testing it on a held-out target domain where performance does not exceed standard fine-tuning or even drops would show that the bases fail to perform the intended adjustment.
Figures

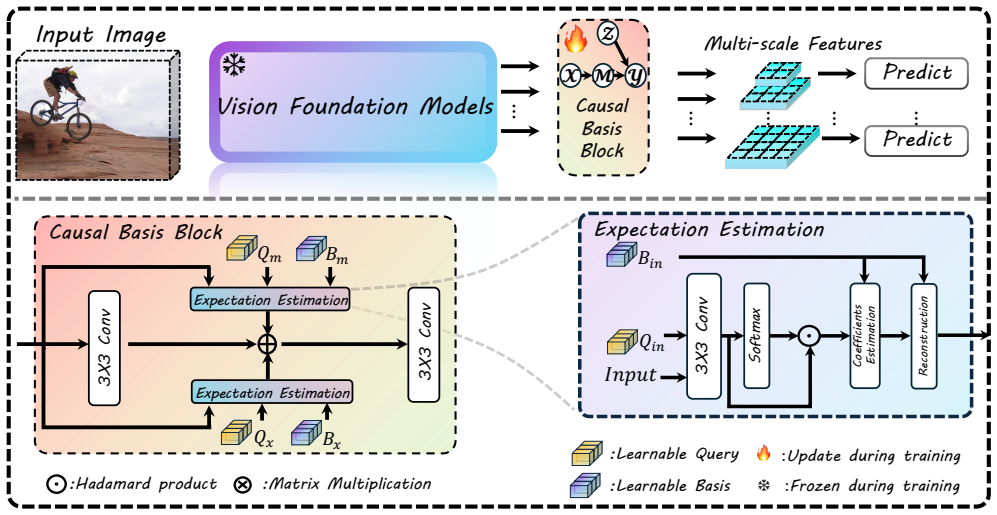
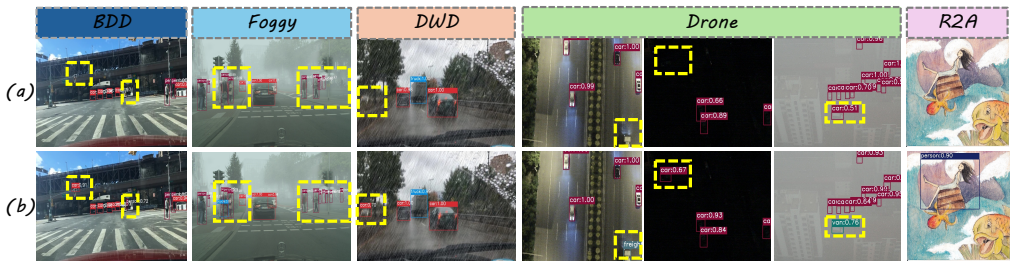

read the original abstract
Detectors often suffer from degraded performance, primarily due to the distributional gap between the source and target domains. This issue is especially evident in single-source domains with limited data, as models tend to rely on confounders (e.g., illumination, co-occurrence, and style) from the source domain, leading to spurious correlations that hinder generalization. To this end, this paper proposes a novel Basis-driven framework for domain generalization, namely \textbf{\textit{Bridge}}, that incorporates causal inference into object detection. By learning the low-rank bases for front-door adjustment, \textbf{\textit{Bridge}} blocks confounders' effects to mitigate spurious correlations, while simultaneously refining representations by filtering redundant and task-irrelevant components. \textbf{\textit{Bridge}} can be seamlessly integrated with both discriminative (e.g., DINOv2/3, SAM) and generative (e.g., Stable Diffusion) Vision Foundation Models (VFMs). Extensive experiments across multiple domain generalization object detection datasets, i.e., Cross-Camera, Adverse Weather, Real-to-Artistic, Diverse Weather Datasets, and Diverse Weather DroneVehicle (our newly augmented real-world UAV-based benchmark), underscore the superiority of our proposed method over previous state-of-the-art approaches. The project page is available at: https://mingbohong.github.io/Bridge/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Bridge, a basis-driven causal inference framework for domain generalization in object detection. It learns low-rank bases from source data to perform front-door adjustment, aiming to block effects of confounders (illumination, co-occurrence, style) that cause spurious correlations, while refining VFM representations by removing redundant components. The method integrates with both discriminative (DINOv2/3, SAM) and generative (Stable Diffusion) vision foundation models and reports superior performance over prior SOTA on five DG detection benchmarks, including a newly introduced UAV-based Diverse Weather DroneVehicle dataset.
Significance. If the low-rank bases provably implement a valid front-door adjustment that remains effective under target shifts, the work would offer a principled way to inject causal structure into VFM-based detectors for improved generalization. The dual use of discriminative and generative VFMs and the release of a new real-world benchmark are concrete strengths that could influence follow-on research in causal DG.
major comments (2)
- [§3] §3 (Method): The low-rank factorization used to obtain the bases is defined only on source-domain features; the manuscript provides no derivation or empirical check that these bases satisfy the two front-door identifiability conditions (no back-door path from treatment X to mediator M, and M intercepts every directed path from X to Y) once the distribution of confounders changes in the target domain. This is load-bearing for the central claim that spurious correlations are blocked.
- [§4] §4 (Experiments) and Table 1–5: Superiority is asserted across five datasets, yet the reported results lack error bars, statistical significance tests, and ablations that isolate the contribution of the front-door bases versus the VFM backbone or the low-rank rank hyper-parameter. Without these, the data cannot yet be said to support the superiority claim at the level stated in the abstract.
minor comments (2)
- [§3.1] Notation for the basis matrix and the front-door operator is introduced without an explicit equation linking them to the standard front-door formula; adding this would improve traceability.
- [§4.3] The new DroneVehicle benchmark is described only briefly; a short table summarizing its domain-shift statistics (camera, weather, altitude) relative to existing datasets would help readers assess its novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify both the theoretical foundations and experimental presentation of our work. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3] §3 (Method): The low-rank factorization used to obtain the bases is defined only on source-domain features; the manuscript provides no derivation or empirical check that these bases satisfy the two front-door identifiability conditions (no back-door path from treatment X to mediator M, and M intercepts every directed path from X to Y) once the distribution of confounders changes in the target domain. This is load-bearing for the central claim that spurious correlations are blocked.
Authors: We agree that a formal derivation of identifiability under target-domain shifts is absent from the current manuscript and is necessary to support the central claim. The low-rank bases are constructed to capture domain-invariant mediators by decomposing source features into components that approximate the front-door paths, under the modeling assumption that spurious confounders (illumination, style, co-occurrence) lie in the orthogonal complement of this low-rank subspace. In the revision we will add a dedicated subsection in §3 that (i) states the two front-door conditions explicitly, (ii) derives the conditions under which source-learned bases remain valid when only the confounder distribution changes (leveraging the invariance of the causal mediator), and (iii) provides a controlled synthetic experiment that varies confounder strength while holding the causal structure fixed. This addition will make the load-bearing argument explicit. revision: yes
-
Referee: [§4] §4 (Experiments) and Table 1–5: Superiority is asserted across five datasets, yet the reported results lack error bars, statistical significance tests, and ablations that isolate the contribution of the front-door bases versus the VFM backbone or the low-rank rank hyper-parameter. Without these, the data cannot yet be said to support the superiority claim at the level stated in the abstract.
Authors: We concur that the experimental section requires additional statistical rigor and component-wise ablations to substantiate the superiority claims. The current tables report single-run results, which is insufficient for strong assertions. In the revised manuscript we will: (1) rerun all experiments with at least five random seeds and report mean ± standard deviation (error bars) in Tables 1–5; (2) add paired statistical significance tests (Wilcoxon signed-rank) against the strongest baselines; (3) introduce a new ablation table that isolates the front-door adjustment by comparing (a) VFM backbone alone, (b) VFM + low-rank factorization without causal adjustment, and (c) full Bridge, while also sweeping the rank hyper-parameter. These changes will be placed in §4 and will directly address the referee’s concern about isolating contributions. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces Bridge as a basis-driven causal framework that learns low-rank bases from source features to approximate front-door adjustment for blocking confounders in domain generalization. No equations or self-citations are exhibited that reduce the claimed front-door operator or the generalization benefit to a definitional fit, a renamed empirical pattern, or a load-bearing self-citation chain. The low-rank construction is presented as an independent modeling choice whose validity rests on empirical performance across datasets rather than on any internal reduction to the inputs by construction. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- basis rank
axioms (1)
- domain assumption Front-door adjustment can be realized by learning low-rank bases from source-domain data
invented entities (1)
-
low-rank bases for front-door adjustment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Generalizing to unseen domains via distribution matching.arXiv preprint arXiv:1911.00804, 2019
Isabela Albuquerque, Jo ˜ao Monteiro, Mohammad Darvishi, Tiago H Falk, and Ioannis Mitliagkas. Generalizing to unseen domains via distribution matching.arXiv preprint arXiv:1911.00804, 2019. 1, 2
-
[2]
Metareg: Towards domain generalization using meta- regularization.Advances in Neural Information Processing Systems, 31, 2018
Yogesh Balaji, Swami Sankaranarayanan, and Rama Chel- lappa. Metareg: Towards domain generalization using meta- regularization.Advances in Neural Information Processing Systems, 31, 2018. 2
2018
-
[3]
General- izing from several related classification tasks to a new unla- beled sample.Advances in Neural Information Processing Systems, 24, 2011
Gilles Blanchard, Gyemin Lee, and Clayton Scott. General- izing from several related classification tasks to a new unla- beled sample.Advances in Neural Information Processing Systems, 24, 2011. 1, 2
2011
-
[4]
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. InProceedings of the European Conference on Computer Vision, pages 213–229. Springer, 2020. 4
2020
-
[5]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021. 2
2021
-
[6]
Visual causal feature learning.arXiv preprint arXiv:1412.2309, 2014
Krzysztof Chalupka, Pietro Perona, and Frederick Eber- hardt. Visual causal feature learning.arXiv preprint arXiv:1412.2309, 2014. 3
-
[7]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al. Mmdetection: Open mmlab detection tool- box and benchmark.arXiv preprint arXiv:1906.07155, 2019. 5
work page Pith review arXiv 1906
-
[8]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1290–1299, 2022. 4
2022
-
[9]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3213–3223, 2016. 2, 5
2016
-
[10]
Improving single domain-generalized object detection: A focus on diversification and alignment
Muhammad Sohail Danish, Muhammad Haris Khan, Muhammad Akhtar Munir, M Saquib Sarfraz, and Mohsen Ali. Improving single domain-generalized object detection: A focus on diversification and alignment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17732–17742, 2024. 6
2024
-
[11]
Zhun Deng, Frances Ding, Cynthia Dwork, Rachel Hong, Giovanni Parmigiani, Prasad Patil, and Pragya Sur. Repre- sentation via representations: Domain generalization via ad- versarially learned invariant representations.arXiv preprint arXiv:2006.11478, 2020. 1
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 2
work page internal anchor Pith review arXiv 2010
-
[13]
The pascal visual object classes (voc) challenge.International Journal of Computer Vision, 88(2):303–338, 2010
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.International Journal of Computer Vision, 88(2):303–338, 2010. 2, 5
2010
-
[14]
Tood: Task-aligned one-stage object detec- tion
Chengjian Feng, Yujie Zhong, Yu Gao, Matthew R Scott, and Weilin Huang. Tood: Task-aligned one-stage object detec- tion. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 3490–3499. IEEE Computer Society, 2021. 8
2021
-
[15]
Dif- fusion domain teacher: Diffusion guided domain adaptive object detector
Boyong He, Yuxiang Ji, Zhuoyue Tan, and Liaoni Wu. Dif- fusion domain teacher: Diffusion guided domain adaptive object detector. InProceedings of the 32nd ACM Interna- tional Conference on Multimedia, pages 3284–3293, 2024. 2, 5, 6
2024
-
[16]
Boosting domain generalized and adaptive detection with diffusion models: Fitness, generalization, and transferabil- ity
Boyong He, Yuxiang Ji, Zhuoyue Tan, and Liaoni Wu. Boosting domain generalized and adaptive detection with diffusion models: Fitness, generalization, and transferabil- ity. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 1912–1923, 2025. 1, 5, 6
1912
-
[17]
Generalized diffusion detector: Mining ro- bust features from diffusion models for domain-generalized detection
Boyong He, Yuxiang Ji, Qianwen Ye, Zhuoyue Tan, and Liaoni Wu. Generalized diffusion detector: Mining ro- bust features from diffusion models for domain-generalized detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9921– 9932, 2025. 1, 2, 5, 6
2025
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. 5
2016
-
[19]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000– 16009, 2022. 2
2022
-
[20]
Single-domain generalized ob- ject detection by balancing domain diversity and invariance
Zhenwei He and Hongsu Ni. Single-domain generalized ob- ject detection by balancing domain diversity and invariance. arXiv preprint arXiv:2502.03835, 2025. 6
-
[21]
Learn- ing with side information through modality hallucination
Judy Hoffman, Saurabh Gupta, and Trevor Darrell. Learn- ing with side information through modality hallucination. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 826–834, 2016. 2
2016
-
[22]
Fsdr: Frequency space domain randomization for domain generalization
Jiaxing Huang, Dayan Guan, Aoran Xiao, and Shijian Lu. Fsdr: Frequency space domain randomization for domain generalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6891– 6902, 2021. 6
2021
-
[23]
Cross-domain weakly-supervised object de- tection through progressive domain adaptation
Naoto Inoue, Ryosuke Furuta, Toshihiko Yamasaki, and Kiy- oharu Aizawa. Cross-domain weakly-supervised object de- tection through progressive domain adaptation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5001–5009, 2018. 2, 5, 6, 8
2018
-
[24]
Undoing the damage of dataset bias
Aditya Khosla, Tinghui Zhou, Tomasz Malisiewicz, Alexei A Efros, and Antonio Torralba. Undoing the damage of dataset bias. InProceedings of the European Conference on Computer Vision, pages 158–171. Springer, 2012. 2
2012
-
[25]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 4015–4026, 2023. 2
2023
-
[26]
Object-aware domain generalization for object detection
Wooju Lee, Dasol Hong, Hyungtae Lim, and Hyun Myung. Object-aware domain generalization for object detection. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 2947–2955, 2024. 5, 6
2024
-
[27]
Deeper, broader and artier domain generaliza- tion
Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M Hospedales. Deeper, broader and artier domain generaliza- tion. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 5542–5550, 2017. 2
2017
-
[28]
Learning to generalize: Meta-learning for do- main generalization
Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy Hospedales. Learning to generalize: Meta-learning for do- main generalization. InProceedings of the AAAI Conference on Artificial Intelligence, 2018. 2
2018
-
[29]
Prompt-driven dynamic object-centric learning for single do- main generalization
Deng Li, Aming Wu, Yaowei Wang, and Yahong Han. Prompt-driven dynamic object-centric learning for single do- main generalization. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 17606–17615, 2024. 6
2024
-
[30]
Deep domain generaliza- tion via conditional invariant adversarial networks
Ya Li, Xinmei Tian, Mingming Gong, Yajing Liu, Tongliang Liu, Kun Zhang, and Dacheng Tao. Deep domain generaliza- tion via conditional invariant adversarial networks. InPro- ceedings of the European Conference on Computer Vision, pages 624–639, 2018. 1, 2
2018
-
[31]
Feature-critic networks for heterogeneous do- main generalization
Yiying Li, Yongxin Yang, Wei Zhou, and Timothy Hospedales. Feature-critic networks for heterogeneous do- main generalization. InInternational Conference on Ma- chine Learning, pages 3915–3924. PMLR, 2019. 2
2019
-
[32]
Cross-domain adaptive teacher for object detection
Yu-Jhe Li, Xiaoliang Dai, Chih-Yao Ma, Yen-Cheng Liu, Kan Chen, Bichen Wu, Zijian He, Kris Kitani, and Peter Vajda. Cross-domain adaptive teacher for object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7581–7590, 2022. 5
2022
-
[33]
De-confounded gaze estimation
Ziyang Liang, Yiwei Bao, and Feng Lu. De-confounded gaze estimation. InProceedings of the European conference on computer vision, pages 219–235. Springer, 2024. 2
2024
-
[34]
Domain-invariant disentan- gled network for generalizable object detection
Chuang Lin, Zehuan Yuan, Sicheng Zhao, Peize Sun, Changhu Wang, and Jianfei Cai. Domain-invariant disentan- gled network for generalizable object detection. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 8771–8780, 2021. 6
2021
-
[35]
Feature pyra- mid networks for object detection
Tsung-Yi Lin, Piotr Doll ´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyra- mid networks for object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2117–2125, 2017. 5
2017
-
[36]
Shape-aware meta-learning for generalizing prostate mri segmentation to unseen domains
Quande Liu, Qi Dou, and Pheng-Ann Heng. Shape-aware meta-learning for generalizing prostate mri segmentation to unseen domains. InInternational Conference on Medi- cal Image Computing and Computer-Assisted Intervention, pages 475–485. Springer, 2020. 2
2020
-
[37]
Ms- net: multi-site network for improving prostate segmentation with heterogeneous mri data.IEEE Transactions on Medical Imaging, 39(9):2713–2724, 2020
Quande Liu, Qi Dou, Lequan Yu, and Pheng Ann Heng. Ms- net: multi-site network for improving prostate segmentation with heterogeneous mri data.IEEE Transactions on Medical Imaging, 39(9):2713–2724, 2020. 2
2020
-
[38]
Cross-modal causal relational reasoning for event-level visual question answer- ing.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10):11624–11641, 2023
Yang Liu, Guanbin Li, and Liang Lin. Cross-modal causal relational reasoning for event-level visual question answer- ing.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10):11624–11641, 2023. 3
2023
-
[39]
Unbiased faster r-cnn for single- source domain generalized object detection
Yajing Liu, Shijun Zhou, Xiyao Liu, Chunhui Hao, Baojie Fan, and Jiandong Tian. Unbiased faster r-cnn for single- source domain generalized object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 28838–28847, 2024. 6
2024
-
[40]
Discovering causal signals in images
David Lopez-Paz, Robert Nishihara, Soumith Chintala, Bernhard Scholkopf, and L ´eon Bottou. Discovering causal signals in images. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6979–6987, 2017. 3
2017
-
[41]
Ensemble of exemplar-svms for object detection and beyond
Tomasz Malisiewicz, Abhinav Gupta, and Alexei A Efros. Ensemble of exemplar-svms for object detection and beyond. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 89–96. IEEE, 2011. 2
2011
-
[42]
A survey on bias and fairness in machine learning.ACM computing surveys, 54(6):1–35,
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. A survey on bias and fairness in machine learning.ACM computing surveys, 54(6):1–35,
-
[43]
Causality: models, reasoning, and inference, by judea pearl, cambridge university press, 2000
Leland Gerson Neuberg. Causality: models, reasoning, and inference, by judea pearl, cambridge university press, 2000. Econometric Theory, 19(4):675–685, 2003. 2, 3
2000
-
[44]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 1, 2
work page internal anchor Pith review arXiv 2023
-
[45]
Basic books, 2018
Judea Pearl and Dana Mackenzie.The book of why: the new science of cause and effect. Basic books, 2018. 2, 3
2018
-
[46]
Causal inference in statistics: A primer
Judea Pearl, Madelyn Glymour, and Nicholas P Jewell. Causal inference in statistics: A primer. John Wiley & Sons,
-
[47]
Sim-to-real transfer of robotic control with dynamics randomization
Xue Bin Peng, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. In2018 IEEE international conference on robotics and automation, pages 3803–3810. IEEE, 2018. 1
2018
-
[48]
Correlation-aware adver- sarial domain adaptation and generalization.Pattern Recog- nition, 100:107124, 2020
Mohammad Mahfujur Rahman, Clinton Fookes, Mahsa Bak- tashmotlagh, and Sridha Sridharan. Correlation-aware adver- sarial domain adaptation and generalization.Pattern Recog- nition, 100:107124, 2020. 1, 2
2020
-
[49]
Srcd: Semantic reasoning with com- pound domains for single-domain generalized object detec- tion.IEEE Transactions on Neural Networks and Learning Systems, 2024
Zhijie Rao, Jingcai Guo, Luyao Tang, Yue Huang, Xinghao Ding, and Song Guo. Srcd: Semantic reasoning with com- pound domains for single-domain generalized object detec- tion.IEEE Transactions on Neural Networks and Learning Systems, 2024. 5, 6
2024
-
[50]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:...
work page internal anchor Pith review arXiv 2024
-
[51]
Faster r-cnn: Towards real-time object detection with region proposal networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6):1137–1149, 2016
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6):1137–1149, 2016. 5
2016
-
[52]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 2, 5
2022
-
[53]
Strong-weak distribution alignment for adaptive ob- ject detection
Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, and Kate Saenko. Strong-weak distribution alignment for adaptive ob- ject detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6956– 6965, 2019. 5
2019
-
[54]
Seman- tic foggy scene understanding with synthetic data.Interna- tional Journal of Computer Vision, 126(9):973–992, 2018
Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Seman- tic foggy scene understanding with synthetic data.Interna- tional Journal of Computer Vision, 126(9):973–992, 2018. 2, 5, 8
2018
-
[55]
Improving weakly supervised object localization via causal intervention
Feifei Shao, Yawei Luo, Li Zhang, Lu Ye, Siliang Tang, Yi Yang, and Jun Xiao. Improving weakly supervised object localization via causal intervention. InProceedings of the 29th ACM International Conference on Multimedia, pages 3321–3329, 2021. 2, 3
2021
-
[56]
Towards universal representa- tion learning for deep face recognition
Yichun Shi, Xiang Yu, Kihyuk Sohn, Manmohan Chan- draker, and Anil K Jain. Towards universal representa- tion learning for deep face recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6817–6826, 2020. 2
2020
-
[57]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[58]
Sparse r-cnn: End-to-end ob- ject detection with learnable proposals
Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chen- feng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, et al. Sparse r-cnn: End-to-end ob- ject detection with learnable proposals. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14454–14463, 2021. 8
2021
-
[59]
Drone-based rgb-infrared cross-modality vehicle detection via uncertainty-aware learning.IEEE Transactions on Cir- cuits and Systems for Video Technology, 32(10):6700–6713,
Yiming Sun, Bing Cao, Pengfei Zhu, and Qinghua Hu. Drone-based rgb-infrared cross-modality vehicle detection via uncertainty-aware learning.IEEE Transactions on Cir- cuits and Systems for Video Technology, 32(10):6700–6713,
-
[60]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Woj- ciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIEEE/RSJ International Conference on Intel- ligent Robots and Systems, pages 23–30. IEEE, 2017. 1
2017
-
[61]
Dictionary learning.IEEE Signal Processing Magazine, 28(2):27–38, 2011
Ivana To ˇsi´c and Pascal Frossard. Dictionary learning.IEEE Signal Processing Magazine, 28(2):27–38, 2011. 3
2011
-
[62]
Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017. 7
2017
-
[63]
Clip the gap: A single domain generalization approach for ob- ject detection
Vidit Vidit, Martin Engilberge, and Mathieu Salzmann. Clip the gap: A single domain generalization approach for ob- ject detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3219– 3229, 2023. 6
2023
-
[64]
Addressing model vul- nerability to distributional shifts over image transformation sets
Riccardo V olpi and Vittorio Murino. Addressing model vul- nerability to distributional shifts over image transformation sets. InProceedings of the IEEE/CVF International Con- ference on Computer Vision and Pattern Recognition, pages 7980–7989, 2019. 2
2019
-
[65]
Crosskd: Cross-head knowledge distillation for object detection
Jiabao Wang, Yuming Chen, Zhaohui Zheng, Xiang Li, Ming-Ming Cheng, and Qibin Hou. Crosskd: Cross-head knowledge distillation for object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 16520–16530, 2024. 5, 6
2024
-
[66]
Vision-and-language naviga- tion via causal learning
Liuyi Wang, Zongtao He, Ronghao Dang, Mengjiao Shen, Chengju Liu, and Qijun Chen. Vision-and-language naviga- tion via causal learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13139–13150, 2024. 2, 3, 7, 8
2024
-
[67]
Visual commonsense r-cnn
Tan Wang, Jianqiang Huang, Hanwang Zhang, and Qianru Sun. Visual commonsense r-cnn. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10760–10770, 2020. 2, 3
2020
-
[68]
Stronger fewer & superior: Harnessing vision foundation models for domain generalized semantic segmentation
Zhixiang Wei, Lin Chen, Yi Jin, Xiaoxiao Ma, Tianle Liu, Pengyang Ling, Ben Wang, Huaian Chen, and Jinjin Zheng. Stronger fewer & superior: Harnessing vision foundation models for domain generalized semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 28619–28630, 2024. 1, 2
2024
-
[69]
Single-domain generalized object detection in urban scene via cyclic-disentangled self- distillation
Aming Wu and Cheng Deng. Single-domain generalized object detection in urban scene via cyclic-disentangled self- distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 847–856,
-
[70]
G-nas: Generalizable neu- ral architecture search for single domain generalization ob- ject detection
Fan Wu, Jinling Gao, Lanqing Hong, Xinbing Wang, Chenghu Zhou, and Nanyang Ye. G-nas: Generalizable neu- ral architecture search for single domain generalization ob- ject detection. InProceedings of the AAAI Conference on Artificial Intelligence, pages 5958–5966, 2024. 6
2024
-
[71]
Show, attend and tell: Neural image caption gen- eration with visual attention
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption gen- eration with visual attention. InInternational Conference on Machine Learning, pages 2048–2057. PMLR, 2015. 3
2048
-
[72]
Multi-view adversarial discriminator: Mine the non-causal factors for object detection in unseen domains
Mingjun Xu, Lingyun Qin, Weijie Chen, Shiliang Pu, and Lei Zhang. Multi-view adversarial discriminator: Mine the non-causal factors for object detection in unseen domains. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8103–8112, 2023. 5, 6
2023
-
[73]
A fourier-based framework for domain generaliza- tion
Qinwei Xu, Ruipeng Zhang, Ya Zhang, Yanfeng Wang, and Qi Tian. A fourier-based framework for domain generaliza- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 14383–14392,
-
[74]
Xiaoran Xu, Jiangang Yang, Wenhui Shi, Siyuan Ding, Luqing Luo, and Jian Liu. Physaug: A physical-guided and frequency-based data augmentation for single-domain gen- eralized object detection.arXiv preprint arXiv:2412.11807,
-
[75]
Deconfounded image captioning: A causal retrospect.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 45(11): 12996–13010, 2021
Xu Yang, Hanwang Zhang, and Jianfei Cai. Deconfounded image captioning: A causal retrospect.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 45(11): 12996–13010, 2021. 3, 8
2021
-
[76]
Bdd100k: A diverse driving dataset for heterogeneous multitask learning
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Dar- rell. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 2636–2645, 2020. 2, 5, 8
2020
-
[77]
Domain randomization and pyramid consistency: Simulation-to-real generalization without accessing target domain data
Xiangyu Yue, Yang Zhang, Sicheng Zhao, Alberto Sangiovanni-Vincentelli, Kurt Keutzer, and Boqing Gong. Domain randomization and pyramid consistency: Simulation-to-real generalization without accessing target domain data. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2100–2110, 2019. 2
2019
-
[78]
Soma: Singular value decomposed minor components adaptation for domain generalizable representation learning
Seokju Yun, Seunghye Chae, Dongheon Lee, and Youngmin Ro. Soma: Singular value decomposed minor components adaptation for domain generalizable representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25602–25612, 2025. 1, 2
2025
-
[79]
Causal intervention for weakly- supervised semantic segmentation.Advances in Neural In- formation Processing Systems, 33:655–666, 2020
Dong Zhang, Hanwang Zhang, Jinhui Tang, Xian-Sheng Hua, and Qianru Sun. Causal intervention for weakly- supervised semantic segmentation.Advances in Neural In- formation Processing Systems, 33:655–666, 2020. 2, 3
2020
-
[80]
Multiple adverse weather conditions adaptation for object detection via causal intervention.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(3):1742– 1756, 2022
Hua Zhang, Liqiang Xiao, Xiaochun Cao, and Hassan Foroosh. Multiple adverse weather conditions adaptation for object detection via causal intervention.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(3):1742– 1756, 2022. 2, 3
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.