Recognition: unknown
STARRY: Spatial-Temporal Action-Centric World Modeling for Robotic Manipulation
Pith reviewed 2026-05-07 11:22 UTC · model grok-4.3
The pith
STARRY couples future scene prediction directly to action outputs by jointly denoising spatial-temporal latents and controls in one diffusion process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
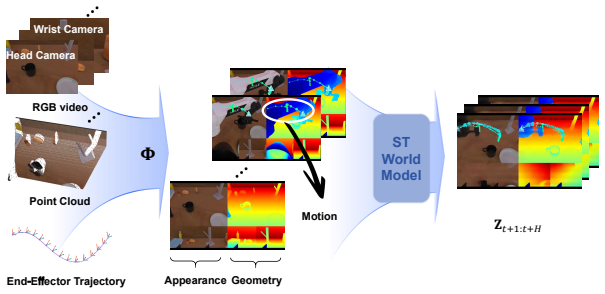
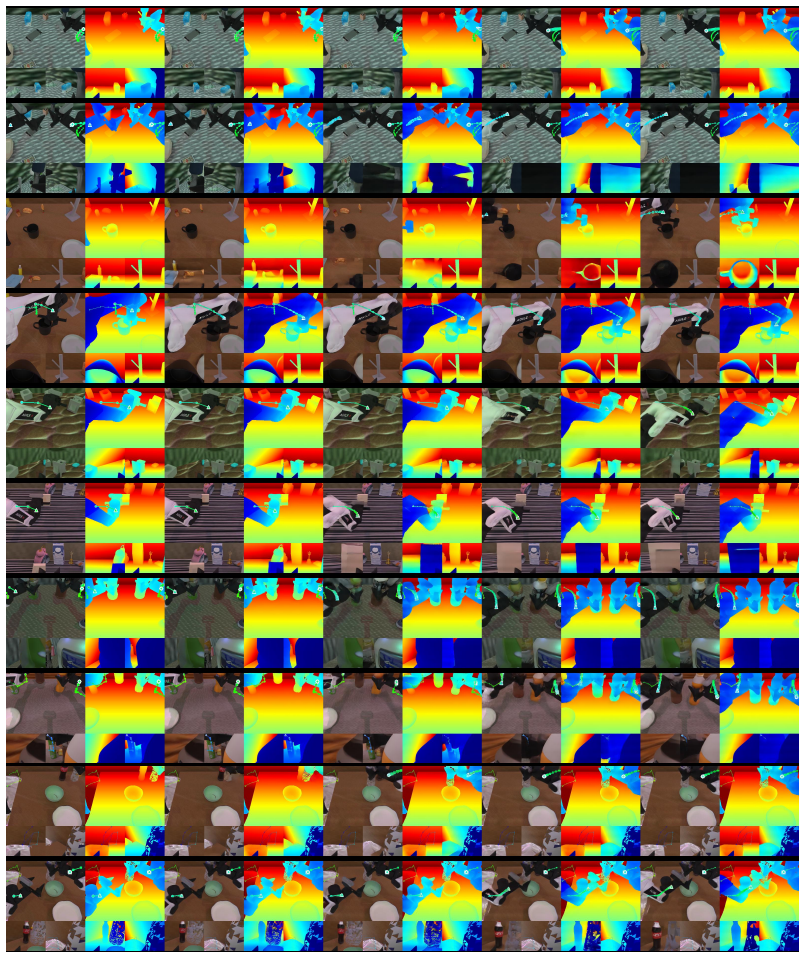
STARRY shows that a unified diffusion process can simultaneously generate future spatial-temporal latents and corresponding actions, with Geometry-Aware Selective Attention Modulation converting predicted depth and end-effector geometry into token-specific attention weights that align 2D observations with 3D control commands. This produces policies that reach 93.82 percent and 93.30 percent average success under clean and randomized conditions on RoboTwin 2.0 across fifty bimanual tasks and raise real-world average success from 42.5 percent to 70.8 percent relative to a prior vision-language-action policy.
What carries the argument
A single diffusion process that jointly denoises future spatial-temporal latents and actions, combined with Geometry-Aware Selective Attention Modulation that turns predicted depth and end-effector geometry into token-aligned attention weights for action generation.
If this is right
- Bimanual tasks that require simultaneous spatial coordination become solvable without separate motion planners.
- Policy performance remains high when visual conditions are randomized, suggesting robustness to real-world variation.
- Simulation-to-real transfer improves because the same latent space serves both prediction and control.
- Longer-horizon manipulation sequences can be executed with fewer compounding errors from decoupled prediction and action modules.
Where Pith is reading between the lines
- The same joint-denoising structure could be tested on single-arm or mobile manipulation benchmarks to check whether the gains generalize beyond bimanual settings.
- If the geometry modulation proves critical, similar selective attention mechanisms might be added to other diffusion-based policies without retraining the entire world model.
- Replacing the current visual encoder with a larger foundation model could further improve the quality of the predicted latents that feed into action generation.
Load-bearing premise
The assumption that jointly denoising future spatial-temporal latents and actions in one diffusion process plus geometry-aware attention modulation will reliably bridge 2D visual tokens to 3D metric control and produce the measured gains on spatially demanding tasks.
What would settle it
An ablation that removes the joint denoising step or the Geometry-Aware Selective Attention Modulation and measures whether average success on the fifty randomized bimanual tasks falls substantially below the reported 93.30 percent.
Figures





read the original abstract
Robotic manipulation requires reasoning about future spatial-temporal interactions and geometric constraints, yet existing Vision-Language-Action (VLA) policies often leave predictive representation weakly coupled with action execution, causing failures in tasks requiring precise spatial-temporal coordination. We propose STARRY, a world-model-enhanced action-generation policy that aligns spatial-temporal prediction and action generation by jointly denoising future spatial-temporal latents and actions through a unified diffusion process. To bridge 2D visual tokens and 3D metric control, STARRY introduces Geometry-Aware Selective Attention Modulation (GASAM), which converts predicted depth and end-effector geometry into token-aligned weights for selective action-attention modulation. On RoboTwin 2.0, STARRY achieves 93.82% / 93.30% average success under Clean and Randomized settings across 50 bimanual tasks. Real-world experiments show that STARRY improves average success from 42.5% to 70.8% compared with $\pi_{0.5}$. These results demonstrate the effectiveness of action-centric spatial-temporal world modeling for spatially and temporally demanding robotic manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes STARRY, a world-model-enhanced action-generation policy for robotic manipulation that aligns spatial-temporal prediction and action generation by jointly denoising future spatial-temporal latents and actions through a unified diffusion process. It introduces Geometry-Aware Selective Attention Modulation (GASAM) to bridge 2D visual tokens and 3D metric control by converting predicted depth and end-effector geometry into token-aligned weights for selective action-attention modulation. On the RoboTwin 2.0 benchmark, STARRY reports 93.82% / 93.30% average success under Clean and Randomized settings across 50 bimanual tasks, and real-world experiments show improvement from 42.5% to 70.8% average success compared with the π_{0.5} baseline.
Significance. If the empirical claims hold under detailed scrutiny, this work could meaningfully advance vision-language-action policies by strengthening the coupling between predictive world modeling and action execution, particularly for bimanual tasks with high spatial-temporal demands. The GASAM mechanism offers a concrete mechanism for incorporating geometric information into attention, which may prove useful beyond the specific diffusion setup.
major comments (2)
- [Abstract] Abstract: The performance numbers (93.82%/93.30% on RoboTwin 2.0 and real-world lift from 42.5% to 70.8%) are stated without any accompanying experimental details, baselines, number of trials, error bars, statistical tests, or ablation studies. This information is load-bearing for the central claim that the unified diffusion process and GASAM produce the reported gains.
- [Proposed Approach] Method description: The joint denoising of future spatial-temporal latents and actions via a unified diffusion process, together with the conversion of depth and end-effector geometry into token-aligned weights in GASAM, is described only at a high level. No equations, pseudocode, or implementation specifics are supplied to show how 2D tokens are mapped to 3D metric control or how the modulation is applied during denoising.
minor comments (1)
- [Abstract] The baseline notation π_{0.5} is used without definition or citation in the abstract; it should be clarified in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We will revise the manuscript to strengthen the abstract with additional experimental context and to provide more detailed equations and implementation specifics for the proposed approach.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance numbers (93.82%/93.30% on RoboTwin 2.0 and real-world lift from 42.5% to 70.8%) are stated without any accompanying experimental details, baselines, number of trials, error bars, statistical tests, or ablation studies. This information is load-bearing for the central claim that the unified diffusion process and GASAM produce the reported gains.
Authors: We agree that the abstract would be improved by including more context on the experimental setup. In the revised version, we will expand the abstract to note the evaluation across 50 bimanual tasks on RoboTwin 2.0 under Clean and Randomized settings, the comparison against the π_{0.5} baseline, and that full results including error bars, statistical significance, and ablations appear in the Experiments section. This addresses the concern while respecting abstract length constraints. revision: yes
-
Referee: [Proposed Approach] Method description: The joint denoising of future spatial-temporal latents and actions via a unified diffusion process, together with the conversion of depth and end-effector geometry into token-aligned weights in GASAM, is described only at a high level. No equations, pseudocode, or implementation specifics are supplied to show how 2D tokens are mapped to 3D metric control or how the modulation is applied during denoising.
Authors: We acknowledge the description is currently high-level. We will revise the Proposed Approach section to include the full mathematical formulation of the unified diffusion objective for joint denoising of spatial-temporal latents and actions, along with pseudocode for GASAM. This will explicitly detail the mapping from predicted depth and end-effector geometry to token-aligned attention weights and how modulation is applied at each denoising step, improving reproducibility. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The abstract describes STARRY as a world-model-enhanced policy using a unified diffusion process for joint denoising of spatial-temporal latents and actions, plus GASAM for bridging 2D tokens to 3D control, and reports empirical success rates (93.82%/93.30% on RoboTwin 2.0, real-world lift from 42.5% to 70.8%). No equations, fitted parameters presented as predictions, self-citations, or ansatzes are visible in the provided text. The performance claims are experimental outcomes rather than derivations that reduce to inputs by construction. The central design choices are presented as independent contributions leading to measured gains, with no load-bearing step that is self-definitional or renames a known result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Geometry-Aware Selective Attention Modulation (GASAM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AgiBot-World-Contributors, Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Do as i can, not as i say: Grounding language in robotic affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, et al. Do as i can, not as i say: Grounding language in robotic affordances. InProceedings of the Conference on Robot Learning (CoRL), 2022
2022
-
[3]
Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. InProceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[4]
Revisiting feature prediction for learning visual repre- sentations from video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual repre- sentations from video. InTransactions on Machine Learning Research (TMLR), 2024
2024
-
[5]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
Galliker, et al.π0.5: A vision- language-action model with open-world generalization
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, et al.π0.5: A vision- language-action model with open-world generalization. InProceedings of the 9th Conference on Robot Learning (CoRL), Proceedings of Machine Learning Research, 2025
2025
-
[7]
π0: A vision-language-action flow model for general robot control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. InProceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[8]
Rt-1: Robotics transformer for real-world control at scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[9]
WorldVLA: Towards Autoregressive Action World Model
Jiahao Cen, Zhenyu Yu, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, Weiliang Deng, Yubin Guo, Tian Nian, Xuanbing Xie, Qiangyu Chen, Kailun Su, Tianling Xu, Guodong Liu, Mengkang Hu, Huan-ang Gao, Kaixuan 10 Wang, Zhixuan Liang, Yusen Qin, Xiaokang Yang, Ping Luo, and Yao Mu. Robotwin 2.0: A scalabl...
work page internal anchor Pith review arXiv 2025
-
[11]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 2024
2024
-
[12]
arXiv preprint arXiv:2509.22642 (2025)
Xiaowei Chi, Peidong Jia, Chun-Kai Fan, Xiaozhu Ju, et al. Wow: Towards a world-omniscient world model through embodied interaction.arXiv preprint arXiv:2509.22642, 2025
- [13]
-
[14]
Zibin Dong, Fei Ni, Yifu Yuan, Yinchuan Li, and Jianye Hao. Embodiedmae: A unified 3d multi-modal representation for robot manipulation.arXiv preprint arXiv:2505.10105, 2025
-
[15]
arXiv preprint arXiv:2602.06949 , year=
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, et al. Dream- dojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
-
[16]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[17]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[18]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[19]
Internvla-a1: Unifying understanding, generation and action for robotic manipulation, 2026
InternVLA-A1 Team. Internvla-a1: Unifying understanding, generation and action for robotic manipulation.arXiv preprint arXiv:2601.02456, 2026
-
[20]
Vima: General robot manipulation with multimodal prompts
Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. Vima: General robot manipulation with multimodal prompts. InProceedings of the International Conference on Machine Learning (ICML), 2023
2023
-
[21]
Droid: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Yuke Zhu, et al. Droid: A large-scale in-the-wild robot manipulation dataset. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[22]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control. arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review arXiv 2026
-
[23]
A comprehensive survey on world models for embodied AI.arXiv preprintarXiv:2510.16732, 2025
Xinqing Li, Xin He, Le Zhang, and Yun Liu. A comprehensive survey on world models for embodied ai.arXiv preprint arXiv:2510.16732, 2025
-
[24]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InProceedings of the International Conference on Learning Representations (ICLR), 2023
2023
-
[25]
Qi Lv, Weijie Kong, Hao Li, Jia Zeng, Zherui Qiu, Delin Qu, Haoming Song, Qizhi Chen, Xiang Deng, and Jiangmiao Pang. F1: A vision-language-action model bridging understanding and generation to actions.arXiv preprint arXiv:2509.06951, 2025
-
[26]
Robomimic: A benchmark for robot learning from demonstration
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. Robomimic: A benchmark for robot learning from demonstration. InProceedings of the Conference on Robot Learning (CoRL), 2021. 11
2021
-
[27]
Open x-embodiment: Robotic learning datasets and rt-x models
Open X-Embodiment Collaboration. Open x-embodiment: Robotic learning datasets and rt-x models. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2024
2024
-
[28]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[29]
GeoPredict: Leveraging Predictive Kinematics and 3D Gaussian Geometry for Precise VLA Manipulation
Jingjing Qian, Boyao Han, Chen Shi, Lei Xiao, Long Yang, Shaoshuai Shi, and Li Jiang. Geopre- dict: Leveraging predictive kinematics and 3d gaussian geometry for precise vla manipulation. arXiv preprint arXiv:2512.16811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[31]
arXiv preprint arXiv:2602.08971 (2026)
Yu Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Lei Jin, Xin Zhang, Yinzhou Tang, Haisheng Su, et al. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world models.arXiv preprint arXiv:2602.08971, 2026
-
[32]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[33]
Bridgedata v2: A dataset for robot learning at scale
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, et al. Bridgedata v2: A dataset for robot learning at scale. InProceedings of the Conference on Robot Learning (CoRL), 2023
2023
-
[34]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
arXiv preprint arXiv:2511.19861 (2025)
Angen Ye, Boyuan Wang, et al. Gigaworld-0: World models as data engine to empower embodied ai.arXiv preprint arXiv:2511.19861, 2025
-
[36]
HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
Xumin Yu et al. Hy-embodied-0.5: Embodied foundation models for real-world agents.arXiv preprint arXiv:2604.07430, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Up-vla: A unified understanding and prediction model for embodied agent
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent. InProceedings of the International Conference on Machine Learning (ICML), 2025
2025
-
[38]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video,
X. Zhang et al. Egodex: Learning dexterous manipulation from egocentric human demonstra- tions.arXiv preprint arXiv:2505.11709, 2025
-
[39]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[40]
Learning 4d embodied world models
Haoyu Zhen, Qiao Sun, Hongxin Zhang, Junyan Li, Siyuan Zhou, Yilun Du, and Chuang Gan. Learning 4d embodied world models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[41]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review arXiv 2025
-
[42]
Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. InProceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[43]
Wmpo: World model-based policy optimization for vision-language-action models, 2025
F. Zhu et al. Wmpo: World model-based policy optimization for vision-language-action models. arXiv preprint arXiv:2511.09515, 2025
-
[44]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InProceedings of the Conference on Robot Learning (CoRL), pages 2165–2183. PMLR, 2023. 12 A Additional details and pseudocode A.1 Hyperparameters W...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.