Recognition: unknown
FaaSMoE: A Serverless Framework for Multi-Tenant Mixture-of-Experts Serving
Pith reviewed 2026-05-07 10:28 UTC · model grok-4.3
The pith
FaaSMoE runs Mixture-of-Experts models by invoking only the active experts as stateless serverless functions, using under one third the resources of a full-model baseline in multi-tenant settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
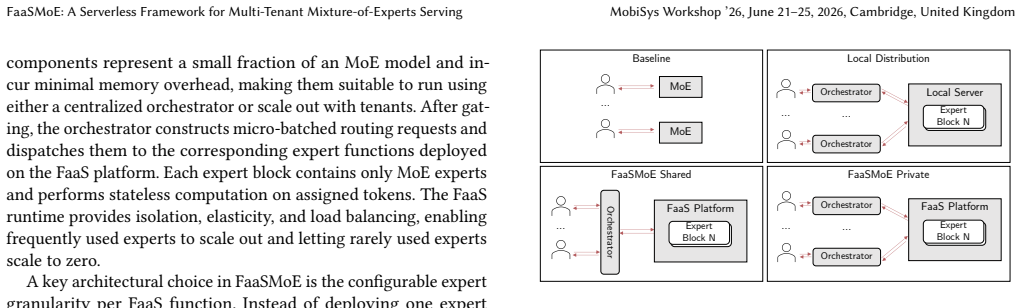
FaaSMoE decouples the control and execution planes of MoE by deploying experts as stateless FaaS functions, enabling on-demand and scale-to-zero expert invocation across tenants. It further supports configurable expert granularity within functions, trading off per-expert elasticity for reduced invocation overhead. A prototype built on an open-source edge-oriented FaaS platform and tested with Qwen1.5-moe-2.7B under multi-tenant workloads uses less than one third of the resources required by a full-model baseline.
What carries the argument
Stateless FaaS functions that host individual experts or small groups of experts, invoked on demand with scale-to-zero behavior and configurable grouping to control invocation frequency.
If this is right
- Only the experts that activate for a given input consume memory and compute, so idle capacity can be reclaimed immediately.
- Multiple tenants can share the same pool of functions without each tenant provisioning a full copy of the model.
- Operators can choose expert grouping size inside each function to balance invocation cost against the ability to scale individual experts independently.
- The system supports scale-to-zero for inactive experts, which is especially useful when request patterns are bursty or sparse across tenants.
Where Pith is reading between the lines
- The same decomposition into stateless functions could be applied to other sparsely activated neural architectures beyond standard MoE.
- In memory-constrained edge or IoT deployments the approach might allow models that exceed device RAM when fully loaded.
- Routing logic that decides which experts to call could itself be moved into the FaaS control plane to avoid maintaining a central model copy.
Load-bearing premise
The added latency and overhead of launching FaaS functions for each expert or group stays small enough that the resource savings are not erased under realistic patterns of multi-tenant requests.
What would settle it
An experiment that measures total memory and CPU hours across many concurrent tenants while logging per-request latency and finds that end-to-end response time rises enough to offset the measured reduction below one-third resource use.
Figures


read the original abstract
Mixture-of-Experts (MoE) models offer high capacity with efficient inference cost by activating a small subset of expert models per input. However, deploying MoE models requires all experts to reside in memory, creating a gap between the resource used by activated experts and the provisioned resources. This underutilization is further pronounced in multi-tenant scenarios. In this paper, we propose FaaSMoE, a multi-tenant MoE serving architecture built on Function-as-a-Service (FaaS) platforms. FaaSMoE decouples the control and execution planes of MoE by deploying experts as stateless FaaS functions, enabling on-demand and scale-to-zero expert invocation across tenants. FaaSMoE further supports configurable expert granularity within functions, trading off per-expert elasticity for reduced invocation overhead. We implement a prototype with an open-source edge-oriented FaaS platform and evaluate it using Qwen1.5-moe-2.7B under multi-tenant workloads. Compared to a full-model baseline, FaaSMoE uses less than one third of the resources, demonstrating a practical and resource-efficient path towards scalable MoE serving in a multi-tenant environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FaaSMoE, a serverless multi-tenant MoE serving architecture that decouples control and execution by deploying experts as stateless FaaS functions with configurable granularity. A prototype is implemented on an open-source edge-oriented FaaS platform and evaluated with Qwen1.5-moe-2.7B under multi-tenant workloads, claiming resource consumption less than one third of a full-model baseline.
Significance. If the resource savings are robust, the work demonstrates a practical serverless approach to mitigating memory underutilization in MoE models, especially valuable in multi-tenant settings. The configurable granularity mechanism and explicit separation of planes are useful design contributions that could inform scalable inference systems.
major comments (2)
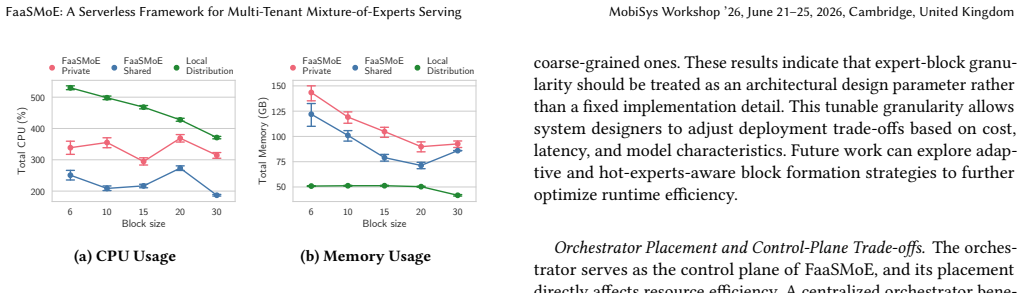
- [Evaluation] Evaluation section: the central claim that FaaSMoE uses less than one third of the resources versus the full-model baseline is presented without details on the resource metric (memory, CPU, or aggregate), baseline implementation, workload generation and characteristics, number of trials, or statistical reporting. This absence prevents verification of the result and directly undermines the soundness of the empirical contribution.
- [§3] Architecture and overhead discussion (around §3): the paper does not quantify or bound the invocation overheads (cold starts, activation transfer, routing without full model residency) under the multi-tenant patterns used in the evaluation. Because the <1/3 savings claim requires these costs to remain below the memory reduction threshold, the lack of such analysis is load-bearing for the main result.
minor comments (1)
- [Abstract and Implementation] The abstract and implementation section should explicitly name the open-source FaaS platform used for the prototype to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional detail will improve the verifiability and soundness of our empirical claims. We address each major comment below and will incorporate the requested information in the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central claim that FaaSMoE uses less than one third of the resources versus the full-model baseline is presented without details on the resource metric (memory, CPU, or aggregate), baseline implementation, workload generation and characteristics, number of trials, or statistical reporting. This absence prevents verification of the result and directly undermines the soundness of the empirical contribution.
Authors: We agree that the evaluation section requires substantially more detail to support the central <1/3 resource claim. The current manuscript reports aggregate results from the prototype but omits the requested specifics. In the revision we will expand the evaluation section to explicitly define the primary resource metric (peak resident memory with secondary CPU utilization), describe the full-model baseline (all experts kept resident with no FaaS invocation), detail workload generation (multi-tenant request traces with varying tenant counts, Poisson arrivals, and Qwen-compatible input sequences), state the number of trials (10 independent runs per configuration), and include statistical reporting (means, standard deviations, and 95% confidence intervals). These additions will enable readers to reproduce and assess the robustness of the reported savings. revision: yes
-
Referee: [§3] Architecture and overhead discussion (around §3): the paper does not quantify or bound the invocation overheads (cold starts, activation transfer, routing without full model residency) under the multi-tenant patterns used in the evaluation. Because the <1/3 savings claim requires these costs to remain below the memory reduction threshold, the lack of such analysis is load-bearing for the main result.
Authors: We acknowledge that the absence of quantitative overhead analysis is a limitation that affects the strength of the main result. While §3 describes the design choices (stateless FaaS experts, configurable granularity, and plane separation) intended to keep invocation costs low, it does not provide measured bounds under the multi-tenant workloads. In the revision we will add a dedicated overhead subsection with empirical measurements of cold-start latency, activation transfer time, and routing cost for the evaluated workloads. We will also present a net-resource analysis showing that these overheads remain below the memory savings threshold, thereby supporting the <1/3 claim. If the existing prototype logs are insufficient, we will conduct additional targeted experiments. revision: yes
Circularity Check
No circularity; empirical system evaluation independent of self-referential inputs
full rationale
The paper is a systems proposal describing FaaSMoE architecture, prototype implementation on an edge FaaS platform, and direct empirical comparison of resource usage against a full-model baseline using Qwen1.5-moe-2.7B under multi-tenant workloads. No equations, parameter fits, predictions, or derivation steps appear. Claims rest on measured outcomes rather than any self-definition, fitted-input renaming, or self-citation chain that reduces the central result to its own inputs by construction. This is the expected non-finding for an implementation-and-evaluation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption FaaS platforms can invoke stateless expert functions with sufficiently low latency and overhead to maintain MoE inference benefits
invented entities (1)
-
FaaSMoE architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amazon Web Services. [n. d.]. AWS Lambda Pricing. https://aws.amazon.com/ lambda/pricing/
-
[2]
Ioana Baldini, Paul Castro, Kerry Chang, Perry Cheng, Stephen Fink, Vatche Ishakian, Nick Mitchel, Vinod Muthusamy, Rodric Rabbah, Aleksander Slominski, and Philippe Suter. 2017. Serverless Computing: Current Trends and Open Problems. InResearch Advances in Cloud Computing. Springer
2017
-
[3]
David Bermbach, Abhishek Chandra, Chandra Krintz, Aniruddha Gokhale, Alek- sander Slominski, Lauritz Thamsen, Everton Cavalcante, Tian Guo, Ivona Brandic, and Rich Wolski. 2021. On the Future of Cloud Engineering. InProceedings of the 9th IEEE International Conference on Cloud Engineering (IC2E ’21). 264–275
2021
-
[4]
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, et al. 2024. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models.arXiv preprint arXiv:2401.06066(2024)
work page internal anchor Pith review arXiv 2024
-
[5]
Databricks on AWS. 2025. Serverless GPU Compute on Databricks. https: //docs.databricks.com/aws/en/compute/serverless/gpu
2025
-
[6]
Umesh Deshpande, Travis Janssen, Mudhakar Srivatsa, and Swaminathan Sun- dararaman. 2024. MoEsaic: Shared Mixture of Experts. InProceedings of the 2024 ACM Symposium on Cloud Computing. 434–442
2024
-
[7]
Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al
-
[8]
In International conference on machine learning
Glam: Efficient scaling of language models with mixture-of-experts. In International conference on machine learning. PMLR, 5547–5569
-
[9]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
2022
- [10]
-
[11]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al . 2024. Mixtral of experts.arXiv preprint arXiv:2401.04088(2024)
work page internal anchor Pith review arXiv 2024
-
[12]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668(2020)
work page internal anchor Pith review arXiv 2020
-
[13]
Mengfan Liu, Wei Wang, and Chuan Wu. 2025. Optimizing distributed deploy- ment of mixture-of-experts model inference in serverless computing. InIEEE INFOCOM 2025-IEEE Conference on Computer Communications. IEEE, 1–10
2025
- [14]
-
[15]
Tobias Pfandzelter and David Bermbach. 2020. tinyFaaS: A Lightweight FaaS Platform for Edge Environments. InProceedings of the Second IEEE International Conference on Fog Computing (ICFC). IEEE
2020
-
[16]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Am- inabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. 2022. Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale. InInternational conference on machine learning. PMLR, 18332–18346
2022
-
[17]
Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. 2021. Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning. InProceedings of the international conference for high performance com- puting, networking, storage and analysis. 1–14
2021
-
[18]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deep- speed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 3505–3506
2020
-
[19]
Trever Schirmer and David Bermbach. 2025. Towards a Testbed for Scalable FaaS Platforms. InProceedings of the 13th IEEE International Conference on Cloud Engineering. IEEE
2025
-
[20]
Trever Schirmer, Nils Japke, Sofia Greten, Tobias Pfandzelter, and David Bermbach. 2023. The Night Shift: Understanding Performance Variability of Cloud Serverless Platforms. InProceedings of the 1st Workshop on SErverless Systems, Applications and MEthodologies. ACM
2023
-
[21]
Mohammad Shahrad, Rodrigo Fonseca, Inigo Goiri, Gohar Chaudhry, Paul Ba- tum, Jason Cooke, Eduardo Laureano, Colby Tresness, Mark Russinovich, and Ricardo Bianchini. 2020. Serverless in the wild: Characterizing and optimizing the serverless workload at a large cloud provider. In2020 USENIX annual technical conference (USENIX ATC 20). 205–218
2020
-
[22]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538(2017)
work page internal anchor Pith review arXiv 2017
-
[23]
Qwen Team et al. 2024. Qwen2 technical report.arXiv preprint arXiv:2407.10671 2, 3 (2024)
work page internal anchor Pith review arXiv 2024
-
[24]
Minghe Wang, Trever Schirmer, Tobias Pfandzelter, and David Bermbach. 2023. Lotus: Serverless In-Transit Data Processing for Edge-based Pub/Sub. InProceed- ings of the 4th International Workshop on Edge Systems, Analytics and Networking (Rome, Italy)(EdgeSys ’23). Association for Computing Machinery (ACM), New York, NY, USA. doi:10.1145/3578354.3592869
-
[25]
Nan Xue, Yaping Sun, Zhiyong Chen, Meixia Tao, Xiaodong Xu, Liang Qian, Shuguang Cui, Wenjun Zhang, and Ping Zhang. 2025. WDMoE: Wireless dis- tributed mixture of experts for large language models.IEEE Transactions on Wireless Communications(2025)
2025
- [26]
- [27]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.