Recognition: unknown
SEAL: Semantic-aware Single-image Sticker Personalization with a Large-scale Sticker-tag Dataset
Pith reviewed 2026-05-07 13:35 UTC · model grok-4.3
The pith
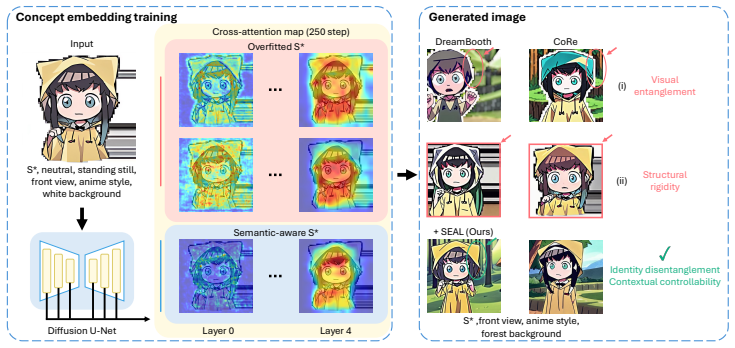
SEAL applies semantic spatial attention, token splitting, and layer restrictions during adaptation to prevent overfitting and maintain controllability in single-image sticker personalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating Semantic-guided Spatial Attention Loss, Split-merge Token Strategy, and Structure-aware Layer Restriction into test-time adaptation, SEAL enables diffusion models to learn a sticker concept from one image without entangling it with reference-specific backgrounds or structures. This preserves the target's identity across varied prompts while supporting attribute-level control through the structured tags in StickerBench.
What carries the argument
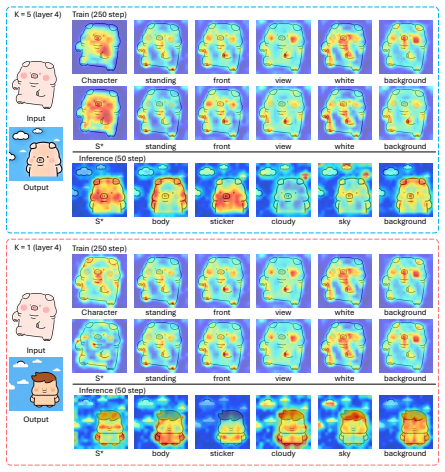
SEAL, a plug-and-play module consisting of Semantic-guided Spatial Attention Loss to enforce semantic focus, Split-merge Token Strategy for adaptable token handling, and Structure-aware Layer Restriction to limit structural changes during fine-tuning.
If this is right
- Identity preservation improves without sacrificing prompt controllability for sticker attributes.
- The method works as a plug-and-play addition to various diffusion-based personalization approaches without changing the U-Net backbone.
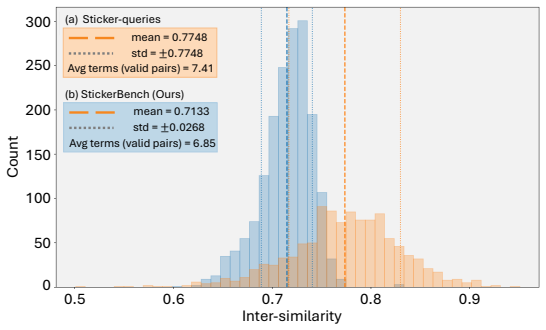
- StickerBench provides a benchmark for evaluating disentanglement using its six-attribute tag schema covering appearance, emotion, action, composition, style, and background.
- Explicit spatial and structural constraints during adaptation reduce visual entanglement and structural rigidity.
Where Pith is reading between the lines
- The method could extend to other domains requiring precise identity control, like product design or character animation.
- Relying on structured datasets like StickerBench may encourage similar tagged benchmarks for other personalization tasks.
- Layer restrictions highlight that not all parts of the model need updating, suggesting potential for more efficient adaptation strategies.
Load-bearing premise
The three components improve disentanglement without reducing overall image quality or introducing new artifacts, and the attribute tags sufficiently capture disentanglement.
What would settle it
Observing that models using SEAL produce images with more artifacts or lower identity similarity scores on StickerBench test cases than standard test-time fine-tuning would disprove the effectiveness of the approach.
Figures











read the original abstract
Synthesizing a target concept from a single reference image is challenging in diffusion-based personalized text-to-image generation, particularly for sticker personalization where prompts often require explicit attribute edits. With only one reference, test-time fine-tuning (TTF) methods tend to overfit, producing \textit{visual entanglement}, where background artifacts are absorbed into the learned concept, and \textit{structural rigidity}, where the model memorizes reference-specific spatial configurations and loses contextual controllability. To address these issues, we introduce \textbf{SE}mantic-aware single-image sticker person\textbf{AL}ization (\textbf{SEAL}), a plug-and-play, architecture-agnostic adaptation module that integrates into existing personalization pipelines without modifying their U-Net-based diffusion backbones. SEAL applies three components during embedding adaptation: (1) a Semantic-guided Spatial Attention Loss, (2) a Split-merge Token Strategy, and (3) Structure-aware Layer Restriction. To support sticker-domain personalization with attribute-level control, we present StickerBench, a large-scale sticker image dataset with structured tags under a six-attribute schema (Appearance, Emotion, Action, Camera Composition, Style, Background). These annotations provide a consistent interface for varying context while keeping target identity fixed, enabling systematic evaluation of identity disentanglement and contextual controllability. Experiments show that SEAL consistently improves identity preservation while maintaining contextual controllability, highlighting the importance of explicit spatial and structural constraints during test-time adaptation. The code, StickerBench, and project page will be publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SEAL, a plug-and-play, architecture-agnostic adaptation module for single-image sticker personalization in diffusion-based text-to-image generation. It addresses overfitting issues (visual entanglement and structural rigidity) during test-time fine-tuning via three components: Semantic-guided Spatial Attention Loss, Split-merge Token Strategy, and Structure-aware Layer Restriction. The work also contributes StickerBench, a large-scale dataset with structured tags under a six-attribute schema (Appearance, Emotion, Action, Camera Composition, Style, Background) to support systematic evaluation of identity disentanglement and contextual controllability. Experiments are reported to show consistent gains in identity preservation while preserving controllability.
Significance. If the results hold, the contribution is significant for personalized generation in the sticker domain, where prompts demand explicit attribute control from limited references. The architecture-agnostic design, explicit spatial/structural constraints, and public release of code, StickerBench, and the project page support reproducibility and further research on disentangled personalization. The structured six-attribute schema provides a concrete interface for testing controllability that is stronger than generic benchmarks.
minor comments (4)
- Abstract: the terms 'visual entanglement' and 'structural rigidity' are introduced without a brief definition or illustrative example; a short parenthetical or footnote would improve accessibility for readers outside the immediate subfield.
- Method section: while the three components are described as plug-and-play, explicit integration pseudocode or a diagram showing how they attach to an existing TTF pipeline (without U-Net modification) would clarify the 'architecture-agnostic' claim.
- Dataset section: the six-attribute schema is listed, but an example table or figure row showing a sticker image with its tag annotations would make the evaluation protocol more concrete and help readers assess whether the schema captures true disentanglement.
- Experiments: the abstract states 'consistent improvement' and 'highlighting the importance'; the full experimental section should include a summary table of quantitative metrics (e.g., identity similarity, controllability scores) across the six attributes with standard deviations or statistical tests.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of SEAL and StickerBench, including recognition of the architecture-agnostic design, the three explicit constraints for mitigating overfitting in test-time adaptation, and the structured six-attribute schema for systematic evaluation. The recommendation for minor revision is noted, and we will incorporate improvements to enhance clarity and presentation.
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical, plug-and-play adaptation method (SEAL) consisting of three components and introduces the StickerBench dataset with a six-attribute schema. No mathematical derivations, equations, or first-principles predictions are presented that could reduce to fitted inputs or self-definitions by construction. Claims of improved identity preservation and contextual controllability rest on reported experiments, ablations, and quantitative metrics that are externally testable and independent of any internal tautology. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the method description or evaluation protocol.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al., 2021
Diffusers: State-of-the-art diffusion models.https://github.com/ huggingface/diffusers. Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al., 2021. Learning trans- ferable visual models from natural language supervision, in: International Conference on Machine Learning, pp. 8748–8763...
2021
-
[2]
Denoising Diffusion Implicit Models
DreamBooth: Finetuningtext-to-imagediffusionmodelsforsubject- driven generation, in: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pp. 22500–22510. Shi, J., Xiong, W., Lin, Z., Jung, H.J., 2024. Instantbooth: Personalized text-to-image generation without test-time finetuning, in: Proceedings of the IEEE/CVF Conferenc...
work page internal anchor Pith review arXiv 2024
-
[3]
8377–8385
Core: Context-regularized text embedding learning for text-to-image personalization, in: Proceedings of the AAAI Conference on Artificial In- telligence, pp. 8377–8385. Xie, C., Zou, H., Yu, R., Zhang, Y., Zhan, Z., 2025. Serialgen: Personalized image generation by first standardization then personalization, in: Pro- ceedings of the Computer Vision and Pa...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.