Recognition: unknown
World2VLM: Distilling World Model Imagination into VLMs for Dynamic Spatial Reasoning
Pith reviewed 2026-05-07 09:15 UTC · model grok-4.3
The pith
Distilling future views from a view-consistent world model into a VLM lets it internalize dynamic spatial reasoning without test-time generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
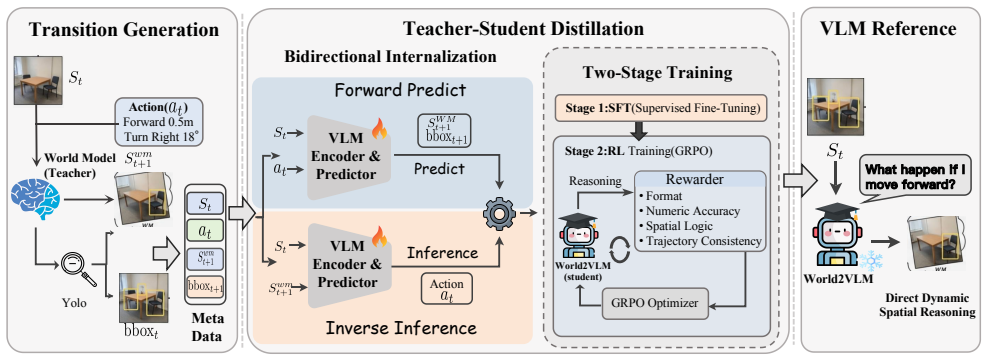
World2VLM distills spatial imagination from a generative world model into a vision-language model. Given an initial observation and a parameterized camera trajectory, a view-consistent world model synthesizes geometrically aligned future views. Structured supervision is derived for forward (action-to-outcome) and inverse (outcome-to-action) spatial reasoning. The VLM receives a two-stage post-training recipe on the resulting compact dataset. This produces consistent gains over the base model on SAT-Real, SAT-Synthesized, VSI-Bench, and MindCube while outperforming test-time world-model-coupled approaches and removing their inference-time cost.
What carries the argument
The view-consistent world model that synthesizes future views and supplies forward and inverse supervision signals for the two-stage post-training of the VLM.
If this is right
- VLMs show measurable gains on SAT-Real, SAT-Synthesized, VSI-Bench, and MindCube after the distillation process.
- Performance exceeds that of methods that attach a world model only at inference time.
- The computational expense of generating world-model outputs during deployment is eliminated.
- Spatial imagination becomes an internalized capability rather than an external add-on.
Where Pith is reading between the lines
- The same distillation pattern could be applied to teach VLMs other forms of predictive reasoning that currently require separate generative modules.
- Lower inference cost could make these models more practical for real-time egocentric tasks such as navigation or manipulation.
- The two-stage recipe might be reused with different world models or motion parameterizations to target new scene dynamics.
Load-bearing premise
The future views produced by the world model are geometrically accurate enough for the derived supervision to improve the VLM without introducing distribution shift or label noise.
What would settle it
If the post-trained VLM shows no gains or worse results on the spatial benchmarks when the world model's synthesized views are replaced by lower-fidelity or randomly altered images, the claim that accurate geometric supervision is what drives the improvement would be undermined.
Figures

read the original abstract
Vision-language models (VLMs) have shown strong performance on static visual understanding, yet they still struggle with dynamic spatial reasoning that requires imagining how scenes evolve under egocentric motion. Recent efforts address this limitation either by scaling spatial supervision with synthetic data or by coupling VLMs with world models at inference time. However, the former often lacks explicit modeling of motion-conditioned state transitions, while the latter incurs substantial computational overhead. In this work, we propose World2VLM, a training framework that distills spatial imagination from a generative world model into a vision-language model. Given an initial observation and a parameterized camera trajectory, we use a view-consistent world model to synthesize geometrically aligned future views and derive structured supervision for both forward (action-to-outcome) and inverse (outcome-to-action) spatial reasoning. We post-train the VLM with a two-stage recipe on a compact dataset generated by this pipeline and evaluate it on multiple spatial reasoning benchmarks. World2VLM delivers consistent improvements over the base model across diverse benchmarks, including SAT-Real, SAT-Synthesized, VSI-Bench, and MindCube. It also outperforms the test-time world-model-coupled methods while eliminating the need for expensive inference-time generation. Our results suggest that world models can serve not only as inference-time tools, but also as effective training-time teachers, enabling VLMs to internalize spatial imagination in a scalable and efficient manner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces World2VLM, a training framework that distills dynamic spatial reasoning capabilities from a generative world model into a vision-language model. Given an initial observation and parameterized camera trajectory, a view-consistent world model synthesizes geometrically aligned future views; forward (action-to-outcome) and inverse (outcome-to-action) supervision signals are then derived from these views. The VLM undergoes two-stage post-training on the resulting compact dataset. The paper claims consistent performance gains over the base VLM on SAT-Real, SAT-Synthesized, VSI-Bench, and MindCube, while also outperforming test-time world-model-coupled baselines without incurring their inference-time generation costs.
Significance. If the empirical claims are substantiated and the synthesized supervision proves high-fidelity, the work would offer a meaningful advance by showing that world models can serve as efficient training-time teachers rather than runtime components. This could reduce inference overhead for spatially aware VLMs and provide a scalable path to internalizing motion-conditioned scene evolution, with potential impact on embodied AI and dynamic visual reasoning tasks.
major comments (2)
- [Abstract] Abstract: the central claim of 'consistent improvements' and superiority over test-time methods is asserted without any quantitative deltas, baseline details, ablation results, or error analysis, preventing verification of the reported gains on SAT-Real, VSI-Bench, etc.
- [Method] Method description (world model synthesis and supervision derivation): no quantitative validation of synthesis fidelity (e.g., PSNR, depth error, or view-consistency scores on held-out real trajectories) is reported, nor is there an ablation replacing synthesized views with ground-truth frames. This is load-bearing because residual geometric or appearance errors would directly introduce noise into the forward and inverse supervision used for the two-stage post-training, undermining the transfer assumption.
minor comments (1)
- [Training recipe] The description of the two-stage post-training recipe would benefit from explicit equations or pseudocode showing how forward and inverse losses are combined and scheduled.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent improvements' and superiority over test-time methods is asserted without any quantitative deltas, baseline details, ablation results, or error analysis, preventing verification of the reported gains on SAT-Real, VSI-Bench, etc.
Authors: We agree that the abstract is high-level and could more explicitly reference the quantitative evidence. The manuscript reports detailed performance metrics, deltas relative to the base VLM and test-time baselines, ablation studies, and error analyses in Section 4 (Experiments) and the associated tables for SAT-Real, SAT-Synthesized, VSI-Bench, and MindCube. To improve verifiability, we will revise the abstract to incorporate key quantitative highlights while preserving its length constraints. revision: yes
-
Referee: [Method] Method description (world model synthesis and supervision derivation): no quantitative validation of synthesis fidelity (e.g., PSNR, depth error, or view-consistency scores on held-out real trajectories) is reported, nor is there an ablation replacing synthesized views with ground-truth frames. This is load-bearing because residual geometric or appearance errors would directly introduce noise into the forward and inverse supervision used for the two-stage post-training, undermining the transfer assumption.
Authors: This is a substantive and valid concern, as the fidelity of the synthesized views underpins the quality of the forward and inverse supervision signals. Our pipeline relies on a view-consistent generative world model, with qualitative demonstrations of geometric alignment provided in the main paper and supplementary material. However, we did not include quantitative fidelity metrics (such as PSNR or depth error on held-out real trajectories) or an ablation substituting ground-truth frames for synthesized views. We will add these evaluations and the requested ablation in the revised manuscript to directly address the transfer assumption. revision: yes
Circularity Check
No circularity: empirical pipeline with external world model and benchmark evaluation
full rationale
The paper presents an empirical training framework that uses an external generative world model to synthesize views and generate supervision signals for post-training a VLM, followed by evaluation on independent benchmarks (SAT-Real, VSI-Bench, etc.). No derivation chain, equation, or claimed prediction reduces to its own inputs by construction, nor does any central result depend on a self-citation loop or fitted parameter renamed as output. The method is self-contained against external data generation and standard test sets, with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Walk through paintings: Egocentric world models from internet priors, 2026
Anurag Bagchi, Zhipeng Bao, Homanga Bharadhwaj, Yu- Xiong Wang, Pavel Tokmakov, and Martial Hebert. Walk through paintings: Egocentric world models from internet priors, 2026. 3
2026
-
[2]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,...
2025
-
[3]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luh- man, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024. 3
2024
-
[4]
Ge- nie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Ge- nie: Generative interactive environments. InInternational Conference on Machine Learning, 2024. 3
2024
-
[5]
Cookbench: A long-horizon embodied planning benchmark for complex cooking scenarios, 2025
Muzhen Cai, Xiubo Chen, Yining An, Jiaxin Zhang, Xuesong Wang, Wang Xu, Weinan Zhang, and Ting Liu. Cookbench: A long-horizon embodied planning benchmark for complex cooking scenarios, 2025. 1
2025
-
[6]
Meng Cao, Xingyu Li, Xue Liu, Ian Reid, and Xiaodan Liang. Spatialdreamer: Incentivizing spatial reasoning via active mental imagery.arXiv preprint arXiv:2512.07733,
-
[7]
Guibas, and Fei Xia
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Danny Driess, Pete Florence, Dorsa Sadigh, Leonidas J. Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities.IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14455–14465, 2024. 2
2024
-
[8]
Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas
Shiqi Chen, Tongyao Zhu, Ruochen Zhou, Jinghan Zhang, Siyang Gao, Juan Carlos Niebles, Mor Geva, Junxian He, Jiajun Wu, and Manling Li. Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas. InProceedings of the International Conference on Machine Learning, 2025. 3
2025
-
[9]
Embodiedeval: Evaluate multi- modal llms as embodied agents
Zhili Cheng, Yuge Tu, Ran Li, Shiqi Dai, Jinyi Hu, Shengding Hu, Jiahao Li, Yang Shi, Tianyu Yu, Weize Chen, Lei Shi, and Maosong Sun. Embodiedeval: Evaluate multi- modal llms as embodied agents. InThe Annual Meeting of the Association for Computational Linguistics, 2025. 1
2025
-
[10]
Assess- ing the value of visual input: A benchmark of multimodal large language models for robotic path planning, 2025
Jacinto Colan, Ana Davila, and Yasuhisa Hasegawa. Assess- ing the value of visual input: A benchmark of multimodal large language models for robotic path planning, 2025. 1
2025
-
[11]
Chang, M
Angela Dai, Angel X. Chang, M. Savva, Maciej Halber, T. Funkhouser, and M. Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes.IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 2432– 2443, 2017. 6
2017
-
[12]
Mm-spatial: Exploring 3d spatial understanding in multimodal llms
Erik Daxberger, Nina Wenzel, David Griffiths, Haiming Gang, Justin Lazarow, Gefen Kohavi, Kai Kang, Marcin Eichner, Yinfei Yang, Afshin Dehghan, and Peter Grasch. Mm-spatial: Exploring 3d spatial understanding in multi- modal llms.arXiv preprint arXiv:2503.13111, 2025. 2
-
[13]
EmbSpatial-bench: Benchmarking spatial un- derstanding for embodied tasks with large vision-language models
Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei. EmbSpatial-bench: Benchmarking spatial un- derstanding for embodied tasks with large vision-language models. InProceedings of the Annual Meeting of the Associ- ation for Computational Linguistics, pages 346–355, 2024. 1
2024
-
[14]
Liveworld: Simulating out-of- sight dynamics in generative video world models, 2026
Zicheng Duan, Jiatong Xia, Zeyu Zhang, Wenbo Zhang, Gengze Zhou, Chenhui Gou, Yefei He, Feng Chen, Xinyu Zhang, and Lingqiao Liu. Liveworld: Simulating out-of- sight dynamics in generative video world models, 2026. 3
2026
-
[15]
Video-of-thought: Step-by-step video reasoning from perception to cognition
Hao Fei, Shengqiong Wu, Wei Ji, Hanwang Zhang, Meishan Zhang, Mong-Li Lee, and Wynne Hsu. Video-of-thought: Step-by-step video reasoning from perception to cognition. InProceedings of the International Conference on Machine Learning, 2024. 2, 3
2024
-
[16]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Com- puter Vision, pages 148–166. Springer, 2024. 2
2024
-
[17]
MLLM-bench: Evaluating multimodal LLMs with per-sample criteria
Wentao Ge, Shunian Chen, Hardy Chen, Nuo Chen, Juny- ing Chen, Zhihong Chen, Wenya Xie, Shuo Yan, Chenghao Zhu, Ziyue Lin, Dingjie Song, Xidong Wang, Anningzhe Gao, Zhang Zhiyi, Jianquan Li, Xiang Wan, and Benyou Wang. MLLM-bench: Evaluating multimodal LLMs with per-sample criteria. InProceedings of the Conference of the Nations of the Americas Chapter of...
2025
-
[18]
Spatial reasoning with vision-language models in ego-centric multi-view scenes, 2025
Mohsen Gholami, Ahmad Rezaei, Zhou Weimin, Sitong Mao, Shunbo Zhou, Yong Zhang, and Mohammad Akbari. Spatial reasoning with vision-language models in ego-centric multi-view scenes, 2025. 2
2025
-
[19]
Peiqi He, Zhenhao Zhang, Yixiang Zhang, Xiongjun Zhao, and Shaoliang Peng. Spatial-ormllm: Improve spatial rela- tion understanding in the operating room with multimodal large language model.arXiv preprint arXiv:2508.08199,
-
[20]
Lora: Low-rank adaptation of large language models.In- ternational Conference on Learning Representations, 1(2): 3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.In- ternational Conference on Learning Representations, 1(2): 3, 2022. 7
2022
-
[21]
Unleashing spatial reasoning in multimodal large language models via textual representation guided reasoning, 2026
Jiacheng Hua, Yishu Yin, Yuhang Wu, Tai Wang, Yifei Huang, and Miao Liu. Unleashing spatial reasoning in multimodal large language models via textual representation guided reasoning, 2026. 3
2026
-
[22]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 1
work page internal anchor Pith review arXiv 2024
-
[23]
Omnispatial: Towards comprehensive spatial reasoning benchmark for vi- sion language models, 2025
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vi- sion language models, 2025. 2
2025
-
[24]
10 Wpt: World-to-policy transfer via online world model distil- lation, 2026
Guangfeng Jiang, Yueru Luo, Jun Liu, Yi Huang, Yiyao Zhu, Zhan Qu, Dave Zhenyu Chen, Bingbing Liu, and Xu Yan. 10 Wpt: World-to-policy transfer via online world model distil- lation, 2026. 3
2026
-
[25]
What’s “up” with vision-language models? investigating their strug- gle with spatial reasoning
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s “up” with vision-language models? investigating their strug- gle with spatial reasoning. InProceedings of the Confer- ence on Empirical Methods in Natural Language Processing, pages 9161–9175, 2023. 2
2023
-
[26]
Plummer, Rose Hendrix, Kuo-Hao Zeng, Reuben Tan, and Arijit Ray
Ranjay Krishna, Jiafei Duan, Kiana Ehsani, Kate Saenko, Aniruddha Kembhavi, Dina Bashkirova, Bryan A. Plummer, Rose Hendrix, Kuo-Hao Zeng, Reuben Tan, and Arijit Ray. Sat: Spatial aptitude training for multimodal language mod- els, 2024. 2
2024
-
[27]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 1
work page internal anchor Pith review arXiv 2024
-
[28]
Imag- ine while reasoning in space: Multimodal visualization-of- thought
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vuli´c, and Furu Wei. Imag- ine while reasoning in space: Multimodal visualization-of- thought. InProceedings of the International Conference on Machine Learning, 2025. 2, 3
2025
-
[29]
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progressive train- ing for spatial reasoning in vision-language models.arXiv preprint arXiv:2510.08531, 2025. 2
-
[30]
Spatialladder: Progressive training for spatial reasoning in vision-language models
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progressive training for spatial reasoning in vision-language models. In The International Conference on Learning Representations,
-
[31]
Manipllm: Embodied multimodal large language model for object-centric robotic manipulation, 2023
Xiaoqi Li, Mingxu Zhang, Yiran Geng, Haoran Geng, Yux- ing Long, Yan Shen, Renrui Zhang, Jiaming Liu, and Hao Dong. Manipllm: Embodied multimodal large language model for object-centric robotic manipulation, 2023. 1
2023
-
[32]
Thinking with camera: A unified multimodal model for camera-centric understanding and generation
Kang Liao, Size Wu, Zhonghua Wu, Linyi Jin, Chao Wang, Yikai Wang, Fei Wang, Wei Li, and Chen Change Loy. Thinking with camera: A unified multimodal model for camera-centric understanding and generation. InThe Inter- national Conference on Learning Representations, 2026. 2
2026
-
[33]
World model on million-length video and language with blockwise ringattention
Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with ringattention.arXiv preprint arXiv:2402.08268, 2024. 1
-
[34]
Spatialcot: Advancing spatial reason- ing through coordinate alignment and chain-of-thought for embodied task planning, 2025
Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhanguang Zhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, Helong Huang, Guangjian Tian, Weichao Qiu, Xingyue Quan, Jianye Hao, and Yuzheng Zhuang. Spatialcot: Advancing spatial reason- ing through coordinate alignment and chain-of-thought for embodied task planning, 2025. 2, 3
2025
-
[35]
3dsrbench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 6924–6934, 2025. 2
2025
-
[36]
Spatial- reasoner: Towards explicit and generalizable 3d spatial rea- soning
Wufei Ma, Yu-Cheng Chou, Qihao Liu, Xingrui Wang, Celso M de Melo, Jianwen Xie, and Alan Yuille. Spatial- reasoner: Towards explicit and generalizable 3d spatial rea- soning. InThe Annual Conference on Neural Information Processing Systems, 2025. 3
2025
-
[37]
Mmiu: Multimodal multi-image understanding for evaluating large vision-language models
Fanqing Meng, Jin Wang, Chuanhao Li, Quanfeng Lu, Hao Tian, Jiaqi Liao, Xizhou Zhu, Jifeng Dai, Yu Qiao, Ping Luo, et al. Mmiu: Multimodal multi-image understanding for evaluating large vision-language models. InThe Interna- tional Conference on Learning Representations, 2025. 2
2025
-
[38]
Spare: Enhancing spatial rea- soning in vision-language models with synthetic data
Michael Ogezi and Freda Shi. Spare: Enhancing spatial rea- soning in vision-language models with synthetic data. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7855–7875, 2025. 2
2025
-
[39]
Yuan Qi et al. Beyond semantics: Rediscovering spa- tial awareness in vision-language models.arXiv preprint arXiv:2503.17349, 2025. 3
-
[40]
Towards grounded visual spatial reasoning in multi-modal vision language models
Reza Rajabi et al. Towards grounded visual spatial reasoning in multi-modal vision language models. InICLR Workshop,
-
[41]
Sat: Dynamic spatial aptitude training for multimodal language models
Arijit Ray, Jiafei Duan, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kembhavi, Bryan A Plummer, Ranjay Krishna, Kuo-Hao Zeng, et al. Sat: Spa- tial aptitude training for multimodal language models.arXiv preprint arXiv:2412.07755, 3, 2024. 6
-
[42]
Gen3c: 3d-informed world-consistent video generation with precise camera con- trol
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas M ¨uller, Alexan- der Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera con- trol. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2025. 3
2025
-
[43]
Mackey, David J
Rishabh Sharma, Gijs Hogervorst, Wayne E. Mackey, David J. Heeger, and Stefano Martiniani. Cross-view world models, 2026. 3
2026
-
[44]
From reactive to cognitive: brain-inspired spatial intelligence for embodied agents, 2025
Hang Su, Songming Liu, Liyuan Wang, Xingxing Wei, Caixin Kang, Shouwei Ruan, and Qihui Zhu. From reactive to cognitive: brain-inspired spatial intelligence for embodied agents, 2025. 1
2025
-
[45]
Hunyuanvideo: A systematic frame- work for large video generative models, 2025
Qi Tian, Songtao Liu, Di Wang, Yangyu Tao, Yang Li, Fang Yang, Yuanbo Peng, Jinbao Xue, Xin Li, Hongfa Wang, An- dong Wang, Zunnan Xu, Shuai Li, Yi Chen, Yanxin Long, Hao Tan, Junkun Yuan, Qin Lin, Kai Wang, Bo Wu, Jie Jiang, Weiyan Wang, Zijian Zhang, Zuozhuo Dai, Changlin Li, Jianwei Zhang, Yuhong Liu, Yong Yang, Hongmei Wang, Yutao Cui, Jiawang Bai, Ji...
2025
-
[46]
Site: towards spatial intelligence thorough evaluation
Wenqi Wang, Reuben Tan, Pengyue Zhu, Jianwei Yang, Zhengyuan Yang, Lijuan Wang, Andrey Kolobov, Jianfeng Gao, and Boqing Gong. Site: towards spatial intelligence thorough evaluation. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 9058–9069,
-
[47]
Anchorweave: World-consistent video generation with retrieved local spatial memories, 2026
Zun Wang, Han Lin, Jaehong Yoon, Jaemin Cho, Yue Zhang, 11 and Mohit Bansal. Anchorweave: World-consistent video generation with retrieved local spatial memories, 2026. 3
2026
-
[48]
Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence, 2025
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence, 2025. 3
2025
-
[49]
SpatialScore: Towards Comprehensive Evaluation for Spatial Intelligence
Haoning Wu, Xiao Huang, Yaohui Chen, Ya Zhang, Yanfeng Wang, and Weidi Xie. Spatialscore: Towards unified evalu- ation for multimodal spatial understanding.arXiv preprint arXiv:2505.17012, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Camreasoner: Reinforcing camera movement understanding via structured spatial rea- soning, 2026
Hang Wu, Yujun Cai, Zehao Li, Haonan Ge, Bowen Sun, Junsong Yuan, and Yiwei Wang. Camreasoner: Reinforcing camera movement understanding via structured spatial rea- soning, 2026. 3
2026
-
[51]
Reinforcing spatial reasoning in vision-language models with interwoven think- ing and visual drawing, 2025
Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, and Tieniu Tan. Reinforcing spatial reasoning in vision-language models with interwoven think- ing and visual drawing, 2025. 3
2025
-
[52]
Grounded chain-of-thought for multimodal large language models,
Qiong Wu, Xiangcong Yang, Yiyi Zhou, Chenxin Fang, Baiyang Song, Xiaoshuai Sun, and Rongrong Ji. Grounded chain-of-thought for multimodal large language models,
-
[53]
Spatial mental modeling from limited views, 2025
Saining Xie, Han Liu, Ranjay Krishna, Li Fei-Fei, Jiajun Wu, Zihan Wang, Manling Li, Jieyu Zhang, Jianshu Zhang, Qineng Wang, Kangrui Wang, Keshigeyan Chandrasegaran, Baiqiao Yin, and Pingyue Zhang. Spatial mental modeling from limited views, 2025. 2, 3, 6
2025
-
[54]
Lingling Xu, Haoran Xie, Si-Zhao Joe Qin, Xiaohui Tao, and Fu Lee Wang. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assess- ment.arXiv preprint arXiv:2312.12148, 2023. 7
-
[55]
Mind- journey: Test-time scaling with world models for spatial rea- soning, 2025
Jianwei Yang, Yilun Du, Chuang Gan, Siyuan Zhou, Reuben Tan, Yuncong Yang, Zheyuan Zhang, and Jiageng Liu. Mind- journey: Test-time scaling with world models for spatial rea- soning, 2025. 2, 3, 6, 7, 19
2025
-
[56]
Thinking in space: How mul- timodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How mul- timodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025. 2, 6
2025
-
[57]
Mmsi-bench: A benchmark for multi-image spatial intelligence.arXiv preprint arXiv:2505.23764, 2025
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, et al. Mmsi-bench: A benchmark for multi- image spatial intelligence.arXiv preprint arXiv:2505.23764,
-
[58]
Cambrian-S: Towards Spatial Supersensing in Video.arXiv preprint arXiv:2511.04670, 2025
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis Brown, Zi- hao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-s: Towards spatial supersens- ing in video.arXiv preprint arXiv:2511.04670, 2025. 3
-
[59]
Yuxue Yang, Lue Fan, Ziqi Shi, Junran Peng, Feng Wang, and Zhaoxiang Zhang. Neoverse: Enhancing 4d world model with in-the-wild monocular videos.arXiv preprint arXiv:2601.00393, 2026. 3
-
[60]
Seeing from another per- spective: Evaluating multi-view understanding in mllms
Chun-Hsiao Yeh, Chenyu Wang, Shengbang Tong, Ta-Ying Cheng, Ruoyu Wang, Tianzhe Chu, Yuexiang Zhai, Yubei Chen, Shenghua Gao, and Yi Ma. Seeing from another per- spective: Evaluating multi-view understanding in mllms. In Neural Information Processing Systems, 2025. 2
2025
-
[61]
Songsong Yu, Yuxin Chen, Hao Ju, Lianjie Jia, Fuxi Zhang, Shaofei Huang, Yuhan Wu, Rundi Cui, Binghao Ran, Za- ibin Zhang, et al. How far are vlms from visual spatial in- telligence? a benchmark-driven perspective.arXiv preprint arXiv:2509.18905, 2025. 2
-
[62]
Actial: Activate spatial reasoning ability of multimodal large language models
Xiaoyu Zhan, Wenxuan Huang, Hao Sun, Xinyu Fu, Changfeng Ma, Shaosheng Cao, Bohan Jia, Shaohui Lin, Zhenfei Yin, LEI BAI, Wanli Ouyang, Yuanqi Li, Jie Guo, and Yanwen Guo. Actial: Activate spatial reasoning ability of multimodal large language models. InThe Annual Con- ference on Neural Information Processing Systems, 2025. 3
2025
-
[63]
Jiahui Zhang, Yurui Chen, Yanpeng Zhou, Yueming Xu, Ze Huang, Jilin Mei, Junhui Chen, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, et al. From flatland to space: Teaching vision-language models to perceive and reason in 3d.arXiv preprint arXiv:2503.22976, 2025. 2
-
[64]
Why do mllms struggle with spatial understanding? a systematic analysis from data to architecture, 2025
Jiajun Zhang, Shuo Ren, Wang Xu, Yibin Huang, Wanyue Zhang, Yangbin Xu, JingJing Huang, and Helu Zhi. Why do mllms struggle with spatial understanding? a systematic analysis from data to architecture, 2025. 2, 6
2025
-
[65]
Can world models benefit vlms for world dynamics?, 2025
Kevin Zhang, Kuangzhi Ge, Xiaowei Chi, Renrui Zhang, Shaojun Shi, Zhen Dong, Sirui Han, and Shanghang Zhang. Can world models benefit vlms for world dynamics?, 2025. 2, 3
2025
-
[66]
Think3d: Think- ing with space for spatial reasoning, 2026
Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Binghao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, Lijun Wang, and Huchuan Lu. Think3d: Think- ing with space for spatial reasoning, 2026. 3
2026
-
[67]
Xu Zheng, Zihao Dongfang, Lutao Jiang, Boyuan Zheng, Yulong Guo, Zhenquan Zhang, Giuliano Albanese, Runyi Yang, Mengjiao Ma, Zixin Zhang, et al. Multimodal spatial reasoning in the large model era: A survey and benchmarks. arXiv preprint arXiv:2510.25760, 2025. 3
-
[68]
Stable virtual camera: Generative view synthesis with diffusion models
Jensen Zhou, Hang Gao, Vikram V oleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, and Varun Jampani. Stable virtual camera: Generative view synthesis with diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12405–12414, 2025. 3, 6
2025
-
[69]
A1–A4” denotes motion-only prompts and “D1–D4
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, Jiahao Wang, Nianchen Deng, Songze Li, Yinan He, Tan Jiang, Jiapeng Luo, Yi Wang, Con- ghui He, Botian Shi, Xingchen...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.