Recognition: unknown
Select to Think: Unlocking SLM Potential with Local Sufficiency
Pith reviewed 2026-05-07 08:37 UTC · model grok-4.3
The pith
The top-8 predictions of a 1.5B SLM contain the 32B LLM's preferred token 95 percent of the time at reasoning divergence points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We address the gap between SLMs and LLMs by identifying local sufficiency: at divergence points, the LLM's preferred token consistently resides within the SLM's top-K next-token predictions. SELECT TO THINK reframes the LLM's role from open-ended generation to selection among the SLM's proposals, simplifying the supervision signal to discrete candidate rankings. Leveraging this, S2T-LOCAL distills the selection logic into the SLM, empowering it to perform autonomous re-ranking without inference-time LLM dependency.
What carries the argument
Local sufficiency, the observation that the LLM's preferred token lies in the SLM's top-K predictions at points of divergence, enabling simplified supervision for distillation of selection logic.
If this is right
- The 1.5B SLM with S2T-LOCAL improves greedy decoding performance by 24.1% on average across benchmarks.
- S2T-LOCAL matches the efficacy of 8-path self-consistency while using single-trajectory efficiency.
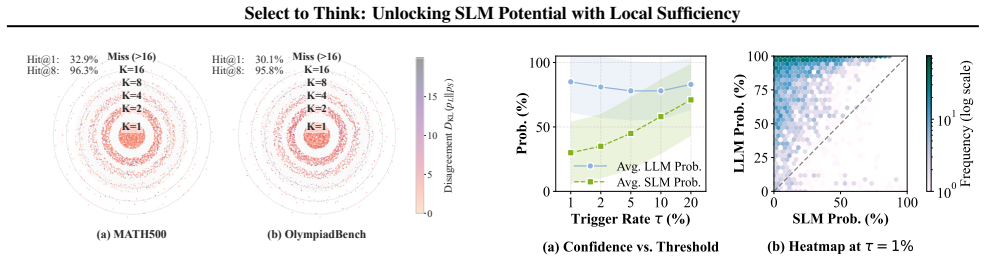
- Top-8 candidates from the 1.5B SLM capture the 32B LLM's choice with a 95% hit rate.
- SLMs can operate without external LLM calls at inference time after distillation.
Where Pith is reading between the lines
- Many apparent reasoning failures in SLMs may actually be selection failures rather than knowledge gaps.
- Similar top-K sufficiency checks could be explored for other generation domains such as code completion or mathematical proof steps.
- Training data efficiency might increase if models are taught to re-rank their own candidates instead of full imitation.
Load-bearing premise
The local sufficiency property holds consistently across diverse tasks and model scales, allowing the distilled selection logic to generalize without degrading performance on unseen data.
What would settle it
An experiment on a new benchmark or different SLM-LLM pair where the top-K hit rate drops substantially below 95% or where S2T-LOCAL training yields no improvement or negative results.
Figures


read the original abstract
Small language models (SLMs) offer computational efficiency for scalable deployment, yet they often fall short of the reasoning power exhibited by their larger counterparts (LLMs). To mitigate this gap, current approaches invoke an LLM to generate tokens at points of reasoning divergence, but these external calls introduce substantial latency and costs. Alternatively, standard distillation is often hindered by the capacity limitation, as SLMs struggle to accurately mimic the LLM's complex generative distribution. We address this dilemma by identifying local sufficiency: at divergence points, the LLM's preferred token consistently resides within the SLM's top-K next-token predictions, even when failing to emerge as the SLM top-1 choice. We therefore propose SELECT TO THINK (S2T), which reframes the LLM's role from open-ended generation to selection among the SLM's proposals, simplifying the supervision signal to discrete candidate rankings. Leveraging this, we introduce S2T-LOCAL, which distills the selection logic into the SLM, empowering it to perform autonomous re-ranking without inference-time LLM dependency. Empirically, we demonstrate that a 1.5B SLM's top-8 candidates capture the 32B LLM's choice with 95% hit rate. Translating this potential into performance, S2T-LOCAL improves greedy decoding by 24.1% on average across benchmarks, effectively matching the efficacy of 8-path self-consistency while operating with single-trajectory efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'local sufficiency' property: at reasoning divergence points, the token preferred by a 32B LLM lies within the top-K (K=8) predictions of a 1.5B SLM with 95% hit rate. It proposes Select to Think (S2T), in which the LLM is used only to rank among the SLM's candidate tokens rather than generate freely, and S2T-LOCAL, which distills the ranking logic into the SLM so that it can perform autonomous re-ranking at inference time. Empirically, S2T-LOCAL yields a 24.1% average improvement over greedy decoding across benchmarks while matching the accuracy of 8-path self-consistency at single-trajectory cost.
Significance. If the local-sufficiency property and the distilled selector prove robust, the work offers a practical route to close much of the capability gap between SLMs and LLMs without incurring repeated LLM calls or the latency of multi-path sampling. The single-trajectory efficiency claim is a concrete strength relative to self-consistency and similar ensembles. The result would be of interest to the efficiency and distillation communities provided the generalization evidence is strengthened.
major comments (3)
- [§4] §4 (Experiments): The reported 24.1% average gain and 95% hit rate are presented without per-task standard deviations, confidence intervals, or statistical significance tests against the greedy and self-consistency baselines. This information is load-bearing for the claim that S2T-LOCAL reliably matches 8-path self-consistency.
- [§3.3] §3.3 and §4.3: The distillation procedure for S2T-LOCAL is described at a high level, but the manuscript provides no out-of-distribution test sets, scaling curves across model sizes, or ablation on how divergence points are detected at inference time. These omissions directly affect the central generalization assumption that the distilled selector will remain effective on unseen tasks and scales.
- [§4.1] §4.1: The experimental setup does not specify the exact method used to identify divergence points during data collection for distillation, nor the precise definition of the training distribution over which the 95% hit rate was measured. Without these details the reproducibility of the local-sufficiency observation cannot be verified.
minor comments (2)
- [Abstract] The abstract introduces 'local sufficiency' without a concise formal statement; a one-sentence definition early in the introduction would improve readability.
- [§3] Notation for the top-K candidate set and the selection head should be introduced once and used consistently; occasional shifts between 'candidates' and 'proposals' are distracting.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which highlight important aspects of reproducibility and generalization. We address each major comment below with clarifications and commitments to strengthen the manuscript. All requested details and analyses can be incorporated in the revision without altering the core claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The reported 24.1% average gain and 95% hit rate are presented without per-task standard deviations, confidence intervals, or statistical significance tests against the greedy and self-consistency baselines. This information is load-bearing for the claim that S2T-LOCAL reliably matches 8-path self-consistency.
Authors: We agree that statistical rigor would improve the presentation of results. In the revised manuscript, we will report per-task standard deviations across multiple random seeds, include 95% confidence intervals, and add paired statistical significance tests (e.g., t-tests) comparing S2T-LOCAL against greedy decoding and 8-path self-consistency. These additions will directly support the reliability claims. revision: yes
-
Referee: [§3.3] §3.3 and §4.3: The distillation procedure for S2T-LOCAL is described at a high level, but the manuscript provides no out-of-distribution test sets, scaling curves across model sizes, or ablation on how divergence points are detected at inference time. These omissions directly affect the central generalization assumption that the distilled selector will remain effective on unseen tasks and scales.
Authors: We acknowledge that additional evidence on generalization would strengthen the central claims. In the revision, we will add experiments on held-out out-of-distribution tasks, scaling curves for SLM sizes from 1B to 7B, and an ablation study isolating the impact of different divergence detection heuristics at inference time. These will be presented in an expanded §4.3. revision: yes
-
Referee: [§4.1] §4.1: The experimental setup does not specify the exact method used to identify divergence points during data collection for distillation, nor the precise definition of the training distribution over which the 95% hit rate was measured. Without these details the reproducibility of the local-sufficiency observation cannot be verified.
Authors: We agree that precise methodological details are essential for reproducibility. The revised manuscript will include a complete description of the divergence point detection algorithm (including exact thresholds and token probability comparisons used during data collection), along with the precise definition of the training distribution, dataset splits, and sampling procedure underlying the 95% hit rate measurement. revision: yes
Circularity Check
Empirical hit-rate measurements and accuracy gains derive from direct observation, not tautological construction
full rationale
The paper's core claims rest on two direct empirical steps: (1) counting the frequency with which the 32B LLM's chosen token appears inside the 1.5B SLM's top-8 logits at divergence points (reported as 95% hit rate), and (2) measuring downstream benchmark accuracy after distilling a selection head into the SLM and comparing against greedy and self-consistency baselines. Neither step invokes an equation whose output is algebraically identical to its fitted input, nor does any load-bearing premise reduce to a self-citation whose own justification is unverified. The local-sufficiency property is defined by the observed token-overlap statistic rather than presupposed; the distillation objective is a standard ranking loss whose success is evaluated on held-out task accuracy. No uniqueness theorem, ansatz smuggling, or renaming of prior results is required to reach the reported 24.1% average improvement. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- top-K value =
8
invented entities (1)
-
local sufficiency
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
URL https://openreview. net/forum?id=zph7e5JaXc. Chen, C., Borgeaud, S., Irving, G., Lespiau, J.-B., Sifre, L., and Jumper, J. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023a. Chen, L., Zaharia, M., and Zou, J. Frugalgpt: How to use large language models while reducing cost and improving performa...
work page internal anchor Pith review arXiv
-
[3]
Unveiling the key factors for distilling chain-of-thought reasoning
Chen, X., Sun, Z., Wenjin, G., Zhang, M., Chen, Y ., Sun, Y ., Su, H., Pan, Y ., Klakow, D., Li, W., and Shen, X. Unveiling the key factors for distilling chain-of-thought reasoning. InFindings of the Association for Computa- tional Linguistics: ACL 2025, pp. 15094–15119,
2025
-
[4]
Dola: Decoding by contrasting layers improves factuality in large language models
Chuang, Y .-S., Xie, Y ., Luo, H., Kim, Y ., Glass, J., and He, P. Dola: Decoding by contrasting layers improves factuality in large language models.arXiv preprint arXiv:2309.03883,
-
[5]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review arXiv
-
[6]
Fu, T., Ge, Y ., You, Y ., Liu, E., Yuan, Z., Dai, G., Yan, S., Yang, H., and Wang, Y . R2r: Efficiently navigating divergent reasoning paths with small-large model token routing.arXiv preprint arXiv:2505.21600, 2025a. Fu, T., You, Y ., Chen, Z., Dai, G., Yang, H., and Wang, Y . Think-at-hard: Selective latent iterations to improve reasoning language mode...
-
[7]
Relayllm: Efficient reasoning via collaborative decod- ing.arXiv preprint arXiv:2601.05167,
Huang, C., Zheng, T., Huang, L., Li, J., Liu, H., and Huang, J. Relayllm: Efficient reasoning via collaborative decod- ing.arXiv preprint arXiv:2601.05167,
-
[8]
arXiv preprint arXiv:2502.18581 , year=
Kang, Z., Zhao, X., and Song, D. Scalable best-of-n selec- tion for large language models via self-certainty.arXiv preprint arXiv:2502.18581,
-
[9]
Guiding reasoning in small language models with llm assistance
Kim, Y ., Yi, E., Kim, M., Yun, S.-Y ., and Kim, T. Guiding reasoning in small language models with llm assistance. arXiv preprint arXiv:2504.09923,
-
[10]
Small models struggle to learn from strong reasoners
9 Select to Think: Unlocking SLM Potential with Local Sufficiency Li, Y ., Yue, X., Xu, Z., Jiang, F., Niu, L., Lin, B. Y ., Ra- masubramanian, B., and Poovendran, R. Small models struggle to learn from strong reasoners.arXiv preprint arXiv:2502.12143,
-
[11]
Lin, Z., Liang, T., Xu, J., Lin, Q., Wang, X., Luo, R., Shi, C., Li, S., Yang, Y ., and Tu, Z. Critical tokens matter: Token-level contrastive estimation enhances llm’s reason- ing capability.arXiv preprint arXiv:2411.19943,
-
[12]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review arXiv
-
[13]
Manvi, R., Hong, J., Seyde, T., Labonne, M., Lechner, M., and Levine, S. Zip-rc: Zero-overhead inference-time pre- diction of reward and cost for adaptive and interpretable generation.arXiv preprint arXiv:2512.01457,
- [14]
-
[15]
Specreason: Fast and ac- curate inference-time compute via speculative reasoning
Pan, R., Dai, Y ., Zhang, Z., Oliaro, G., Jia, Z., and Ne- travali, R. Specreason: Fast and accurate inference- time compute via speculative reasoning.arXiv preprint arXiv:2504.07891,
-
[16]
Qwen. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review arXiv
-
[17]
and Sch ¨utze, H
Schick, T. and Sch ¨utze, H. It’s not just size that matters: Small language models are also few-shot learners. InPro- ceedings of the 2021 conference of the North American chapter of the association for computational linguistics: Human language technologies, pp. 2339–2352,
2021
-
[18]
Trusting your evidence: Hallucinate less with context-aware decoding
Shi, W., Han, X., Lewis, M., Tsvetkov, Y ., Zettlemoyer, L., and Yih, W.-t. Trusting your evidence: Hallucinate less with context-aware decoding. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pp. 783–791,
2024
-
[19]
Large language model routing with benchmark datasets.arXiv preprint arXiv:2309.15789, 2023
Shnitzer, T., Ou, A., Silva, M., Soule, K., Sun, Y ., Solomon, J., Thompson, N., and Yurochkin, M. Large language model routing with benchmark datasets.arXiv preprint arXiv:2309.15789,
-
[20]
Multiplex thinking: Reasoning via token-wise branch- and-merge.arXiv preprint arXiv:2601.08808,
Tang, Y ., Dong, L., Hao, Y ., Dong, Q., Wei, F., and Gu, J. Multiplex thinking: Reasoning via token-wise branch- and-merge.arXiv preprint arXiv:2601.08808,
-
[21]
Gemma 2: Improving Open Language Models at a Practical Size
Team, G., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahri- ari, B., Ram ´e, A., et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review arXiv
-
[22]
Varshney, N. and Baral, C. Model cascading: Towards jointly improving efficiency and accuracy of nlp systems. arXiv preprint arXiv:2210.05528,
-
[23]
Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., Liu, D., Tu, J., Zhou, J., Lin, J., et al. Qwen2. 5-math techni- cal report: Toward mathematical expert model via self- improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review arXiv
-
[24]
and Math-AI, T
Zhang, Y . and Math-AI, T. American invitational mathemat- ics examination (aime) 2025,
2025
-
[25]
30:end while 31:Returnsequencey. B. Evaluation Details B.1. Benchmark Mathematical reasoning benchmarks. • GSM8K (Cobbe et al., 2021): A dataset of 8,500 linguistically diverse grade school math word problems requiring 2-8 step reasoning, serving as a standard benchmark for evaluating basic mathematical reasoning capabilities. 12 Select to Think: Unlockin...
2021
-
[26]
amateur” (or counterfactual) signal from an “expert
reshape logits by subtracting an “amateur” (or counterfactual) signal from an “expert” one to suppress generic or hallucinated tokens. This paradigm has inspired various extensions, including context-aware variants to resolve evidence-parametric conflicts (Shi et al., 2024), and internal-contrast methods (e.g.,DoLa(Chuang et al., 2023)) that utilize intra...
2024
-
[27]
Local Sufficiency
During inference, we apply a sigmoid activation to the criticality logit and threshold at 0.7 (configurable) to make binary triggering decisions, eliminating the need to compute expensive cross-model KL divergence at every step. 15 Select to Think: Unlocking SLM Potential with Local Sufficiency Table A1.Accuracy comparison under varying trigger threshold ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.