Recognition: unknown
Budget-Constrained Online Retrieval-Augmented Generation: The Chunk-as-a-Service Model
Pith reviewed 2026-05-07 15:08 UTC · model grok-4.3
The pith
Chunk-as-a-Service charges only for the relevant chunks actually retrieved to enrich specific prompts, selected online under budget limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating retrieval-augmented generation as a Chunk-as-a-Service model and applying the Utility-Cost Online Selection Algorithm for budget-constrained online decisions, a subset of prompts can be enriched to maximize the product of the number of enriched prompts and their average relevance while achieving higher performance-to-budget ratios than per-prompt billing.
What carries the argument
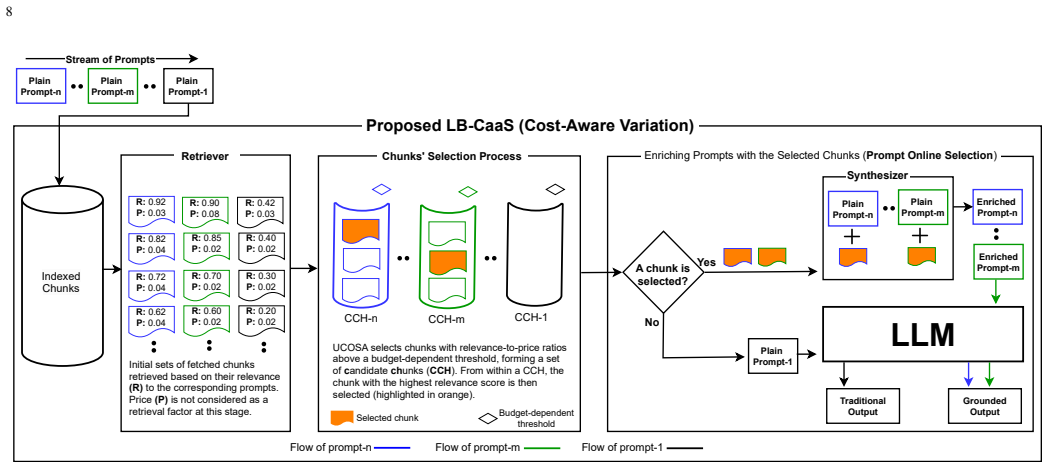
The Utility-Cost Online Selection Algorithm (UCOSA), which estimates utility and cost for each prompt in real time and selects a subset to enrich under budget constraints.
If this is right
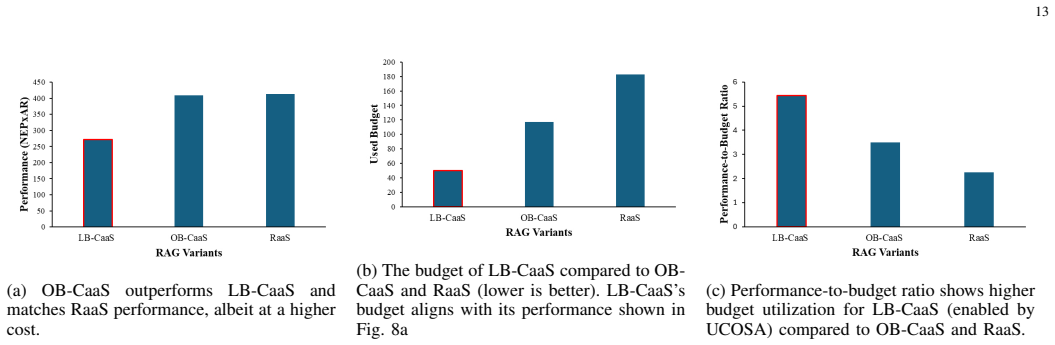
- Limited-Budget CaaS and Open-Budget CaaS achieve performance-to-budget ratios of 140 percent and 86 percent compared with RaaS.
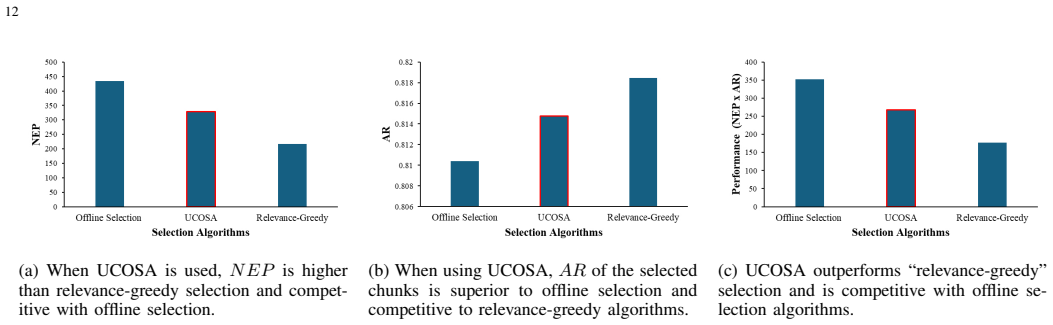
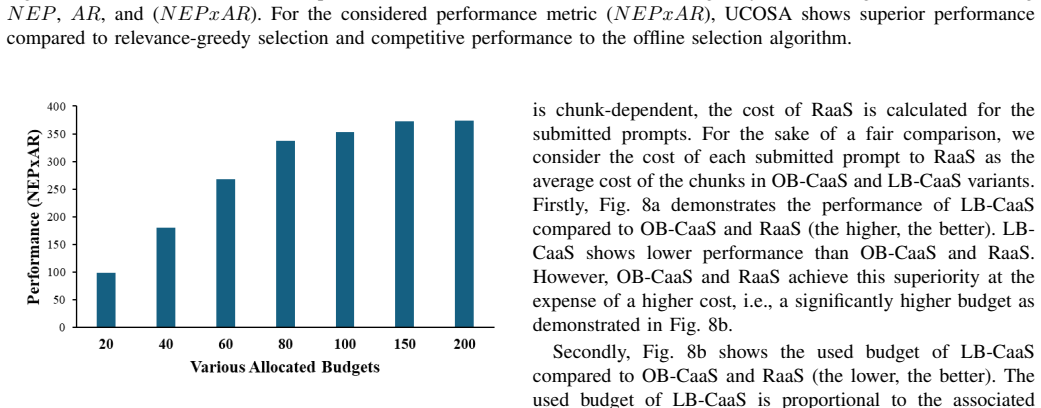
- UCOSA improves the NEP times AR metric by about 52 percent relative to random selection.
- UCOSA reaches around 75 percent of the NEP times AR performance of offline selection methods.
- CaaS ties charges directly to the relevance and usage of individual chunks rather than every submitted prompt.
Where Pith is reading between the lines
- The same online utility-cost framing could apply to other streaming services that allocate limited resources to user requests whose value is revealed only after partial processing.
- Providers adopting CaaS would have a direct incentive to improve chunk quality because payment depends on measured relevance.
- Real-world deployment could test whether the assumed real-time estimates remain stable when user prompts arrive from diverse domains.
Load-bearing premise
Prompt utility and chunk relevance can be estimated accurately enough in real time to guide good selection decisions without any knowledge of future prompts or complete context.
What would settle it
A logged sequence of prompts with known ground-truth relevance scores and utilities where running the online UCOSA selection produces a lower total NEP times AR value than the offline optimum computed after seeing the entire sequence.
Figures




read the original abstract
Large Language Models (LLMs) have revolutionized the field of natural language processing. However, they exhibit some limitations, including a lack of reliability and transparency: they may hallucinate and fail to provide sources that support the generated output. Retrieval-Augmented Generation (RAG) was introduced to address such limitations in LLMs. One popular implementation, RAG-as-a-Service (RaaS), has shortcomings that hinder its adoption and accessibility. For instance, RaaS pricing is based on the number of submitted prompts, without considering whether the prompts are enriched by relevant chunks, i.e., text segments retrieved from a vector database, or the quality of the utilized chunks (i.e., their degree of relevance). This results in an opaque and less cost-effective payment model. We propose Chunk-as-a-Service (CaaS) as a transparent and cost-effective alternative. CaaS includes two variants: Open-Budget CaaS (OB-CaaS) and Limited-Budget CaaS (LB-CaaS), which is enabled by our ``Utility-Cost Online Selection Algorithm (UCOSA)''. UCOSA further extends the cost-effectiveness and the accessibility of the OB-CaaS variant by enriching, in an online manner, a subset of the submitted prompts based on budget constraints and utility-cost tradeoff. Our experiments demonstrate the efficacy of the proposed UCOSA compared to both offline and relevance-greedy selection baselines. In terms of the performance metric-the number of enriched prompts (NEP) multiplied by the Average Relevance (AR)-UCOSA outperforms random selection by approximately 52% and achieves around 75% of the performance of offline selection methods. Additionally, in terms of budget utilization, LB-CaaS and OB-CaaS achieve higher performance-to-budget ratios of 140% and 86%, respectively, compared to RaaS, indicating their superior efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Chunk-as-a-Service (CaaS) as a transparent, utility-based alternative to RAG-as-a-Service (RaaS), introducing Open-Budget CaaS (OB-CaaS) and Limited-Budget CaaS (LB-CaaS) variants. The latter is enabled by the Utility-Cost Online Selection Algorithm (UCOSA), which performs online prompt enrichment under budget constraints by trading off estimated prompt utility against chunk retrieval cost. Experiments claim UCOSA improves the NEP × AR metric by approximately 52% over random selection and reaches ~75% of offline selection performance, while CaaS variants show superior performance-to-budget ratios (140% and 86%) relative to RaaS.
Significance. If the empirical claims are substantiated with reproducible details, the work could meaningfully advance practical RAG deployment by shifting from per-prompt pricing to per-enrichment utility pricing. The online UCOSA formulation directly addresses streaming query scenarios with hard budget limits, and the performance-to-budget ratio metric highlights efficiency gains over volume-based models.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation section: The central performance claims (UCOSA outperforming random by ~52% and reaching ~75% of offline on NEP×AR; 140%/86% budget ratios) are reported without any description of the datasets, query volume, vector database characteristics, how prompt utility and chunk relevance scores are computed in real time, the precise implementation of the random/relevance-greedy/offline baselines, or statistical tests for the reported deltas. These omissions make the claims unverifiable and prevent assessment of whether the online policy's advantage holds under realistic estimation noise.
- [UCOSA algorithm] UCOSA algorithm description (likely §3): The online selection policy rests on the assumption that prompt utility and chunk relevance can be estimated accurately from only the current prompt and available chunks, without future context. No sensitivity analysis, noise model, or ablation on estimation error is provided; if these estimates are biased or low-accuracy (common in evolving RAG streams), the reported gains over relevance-greedy and random baselines could collapse.
minor comments (2)
- [Abstract] Abstract: The performance-to-budget ratios are stated as '140% and 86%' without clarifying the exact baseline value or normalization; this should be defined explicitly (e.g., relative to RaaS NEP×AR per unit budget).
- [Evaluation Metrics] Notation: The combined metric NEP × AR is introduced without discussion of whether it correlates with downstream generation quality or user utility; a brief justification or correlation study would strengthen the evaluation.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We appreciate the opportunity to clarify and strengthen the presentation of our work on Chunk-as-a-Service and the UCOSA algorithm. Below, we provide point-by-point responses to the major comments and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: The central performance claims (UCOSA outperforming random by ~52% and reaching ~75% of offline on NEP×AR; 140%/86% budget ratios) are reported without any description of the datasets, query volume, vector database characteristics, how prompt utility and chunk relevance scores are computed in real time, the precise implementation of the random/relevance-greedy/offline baselines, or statistical tests for the reported deltas. These omissions make the claims unverifiable and prevent assessment of whether the online policy's advantage holds under realistic estimation noise.
Authors: We agree with the referee that the Experimental Evaluation section requires more detailed information to ensure reproducibility and verifiability of the results. In the revised manuscript, we will expand this section to include: (1) descriptions of the datasets used, including their sources and characteristics; (2) details on query volumes and vector database setups; (3) explanations of how prompt utility and chunk relevance scores are computed in real time, including any models or heuristics employed; (4) precise descriptions of the baseline implementations (random, relevance-greedy, and offline); and (5) statistical tests (e.g., t-tests or confidence intervals) to support the reported performance deltas. These additions will allow readers to assess the robustness of UCOSA under realistic conditions. revision: yes
-
Referee: [UCOSA algorithm] UCOSA algorithm description (likely §3): The online selection policy rests on the assumption that prompt utility and chunk relevance can be estimated accurately from only the current prompt and available chunks, without future context. No sensitivity analysis, noise model, or ablation on estimation error is provided; if these estimates are biased or low-accuracy (common in evolving RAG streams), the reported gains over relevance-greedy and random baselines could collapse.
Authors: The referee correctly identifies that UCOSA relies on online estimates of utility and relevance based on the current prompt and chunks. We acknowledge that the original submission did not include a sensitivity analysis or ablation on estimation errors. To address this, we will add a new subsection in the revised manuscript that includes: (i) a noise model for estimation errors, (ii) sensitivity analysis varying the accuracy of utility and relevance estimates, and (iii) ablations showing how performance degrades under increasing noise levels. This will demonstrate the conditions under which the reported gains hold and provide insights into robustness in realistic RAG scenarios with potential estimation biases. revision: yes
Circularity Check
No circularity: empirical validation against external baselines with no self-referential reductions.
full rationale
The paper defines the UCOSA algorithm and CaaS variants explicitly, then reports experimental comparisons of NEP×AR and performance-to-budget ratios against random, relevance-greedy, and offline baselines. No equations are presented that reduce the reported gains to fitted parameters or prior self-citations by construction. The central claims rest on direct measurement of the proposed online selection policy versus independent baselines, making the derivation self-contained rather than tautological. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[2]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
M. Reid, N. Savinov, D. Teplyashin, D. Lepikhin, T. Lillicrap, J.-b. Alayrac, R. Soricut, A. Lazaridou, O. Firat, J. Schrittwieseret al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Palm: Scal- ing language modeling with pathways,
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmannet al., “Palm: Scal- ing language modeling with pathways,”Journal of Machine Learning Research, vol. 24, no. 240, pp. 1–113, 2023
2023
-
[5]
Harnessing the power of llms in practice: A survey on chatgpt and beyond,
J. Yang, H. Jin, R. Tang, X. Han, Q. Feng, H. Jiang, S. Zhong, B. Yin, and X. Hu, “Harnessing the power of llms in practice: A survey on chatgpt and beyond,”ACM Transactions on Knowledge Discovery from Data, vol. 18, no. 6, pp. 1–32, 2024. 16
2024
-
[6]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Computing Surveys, vol. 55, no. 12, pp. 1–38, 2023
2023
-
[7]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qinet al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” arXiv preprint arXiv:2311.05232, 2023
work page internal anchor Pith review arXiv 2023
-
[8]
How language model hallucinations can snowball,
M. Zhang, O. Press, W. Merrill, A. Liu, and N. A. Smith, “How language model hallucinations can snowball,” inForty-first International Conference on Machine Learning, 2024. [Online]. Available: https://openreview.net/forum?id=FPlaQyAGHu
2024
-
[9]
Retrieval augmented language model pre-training,
K. Guu, K. Lee, Z. Tung, P. Pasupat, and M. Chang, “Retrieval augmented language model pre-training,” inInternational conference on machine learning. PMLR, 2020, pp. 3929–3938
2020
-
[10]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020
2020
-
[11]
as-a Service
V . as-a Service. Vectara RAG-as-a-Service . Accessed: 2024-08-07. [Online]. Available: https://vectara.com/retrieval-augmented-generation/
2024
-
[12]
L. Cloud. LlamaIndex Cloud . Accessed: 2024-08-07. [Online]. Available: https://docs.llamaindex.ai/en/stable/llama cloud/
2024
-
[13]
RAG-as-a-Service,
Nuclia, “RAG-as-a-Service,” 2024, [Online; accessed 01-June-2024]. [Online]. Available: https://nuclia.com/rag-as-a-service/
2024
-
[14]
RAG-as-a-Service,
Geniusee, “RAG-as-a-Service,” 2024, [Online; accessed 02-June-2024]. [Online]. Available: https://geniusee.com/ retrieval-augmented-generation
2024
-
[15]
RAG-as-a-Service,
Amazon Bedrock, “RAG-as-a-Service,” 2024, [Online; accessed 02- June-2024]. [Online]. Available: https://aws.amazon.com/bedrock/
2024
-
[16]
Retrieval meets long context large language models,
P. Xu, W. Ping, X. Wu, L. McAfee, C. Zhu, Z. Liu, S. Subramanian, E. Bakhturina, M. Shoeybi, and B. Catanzaro, “Retrieval meets long context large language models,” inThe Twelfth International Conference on Learning Representations
-
[17]
A. Roberts, C. Raffel, and N. Shazeer, “How much knowledge can you pack into the parameters of a language model?”arXiv preprint arXiv:2002.08910, 2020
-
[18]
Teaching Language Models to Support Answers with Verified Quotes.CoRR, abs/2203.11147,
J. Menick, M. Trebacz, V . Mikulik, J. Aslanides, F. Song, M. Chad- wick, M. Glaese, S. Young, L. Campbell-Gillingham, G. Irvinget al., “Teaching language models to support answers with verified quotes,” arXiv preprint arXiv:2203.11147, 2022
-
[19]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,
L. Kuhn, Y . Gal, and S. Farquhar, “Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,” inThe Eleventh International Confer- ence on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=VD-AYtP0dve
2023
-
[20]
Detecting hallucinations in large language models using semantic entropy,
S. Farquhar, J. Kossen, L. Kuhn, and Y . Gal, “Detecting hallucinations in large language models using semantic entropy,”Nature, vol. 630, no. 8017, pp. 625–630, 2024
2024
-
[21]
Training language models on the knowledge graph: Insights on hallucinations and their detectability,
J. Hron, L. Culp, G. Elsayed, R. Liu, B. Adlam, M. Bileschi, B. Bohnet, J. Co-Reyes, N. Fiedel, C. D. Freemanet al., “Training language models on the knowledge graph: Insights on hallucinations and their detectability,”arXiv preprint arXiv:2408.07852, 2024
-
[22]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, and H. Wang, “Retrieval-augmented generation for large language models: A survey,”arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review arXiv 2023
-
[23]
Seven failure points when engineering a retrieval augmented generation system,
S. Barnett, S. Kurniawan, S. Thudumu, Z. Brannelly, and M. Abdelrazek, “Seven failure points when engineering a retrieval augmented generation system,” inProceedings of the IEEE/ACM 3rd International Conference on AI Engineering-Software Engineering for AI, 2024, pp. 194–199
2024
-
[24]
Benchmarking large language models in retrieval-augmented generation,
J. Chen, H. Lin, X. Han, and L. Sun, “Benchmarking large language models in retrieval-augmented generation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 17 754– 17 762
2024
-
[25]
Vectara Price Plan
Vectara. Vectara Price Plan. Accessed: 2024-09-01. [Online]. Available: https://vectara.com/pricing/
2024
-
[26]
LlamaIndex
C. LlamaIndex. Cloud LlamaIndex Price Plan. Accessed: 2024-09-01. [Online]. Available: https://docs.cloud.llamaindex.ai/llamaparse/usage data
2024
-
[27]
Nuclia Price Plan
Nuclia. Nuclia Price Plan. Accessed: 2024-09-01. [Online]. Available: https://nuclia.com/pricing/
2024
-
[28]
Mba-rag: a bandit approach for adaptive retrieval-augmented generation through question complexity,
X. Tang, Q. Gao, J. Li, N. Du, Q. Li, and S. Xie, “Mba-rag: a bandit approach for adaptive retrieval-augmented generation through question complexity,” inProceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 3248–3254
2025
-
[29]
Dynamic resource allocation in cloud computing: anal- ysis and taxonomies,
A. Belgacem, “Dynamic resource allocation in cloud computing: anal- ysis and taxonomies,”Computing, vol. 104, no. 3, pp. 681–710, 2022
2022
-
[30]
A cost-aware mechanism for optimized resource provisioning in cloud computing,
S. Ghasemi, M. R. Meybodi, M. D. T. Fooladi, and A. M. Rahmani, “A cost-aware mechanism for optimized resource provisioning in cloud computing,”Cluster Computing, vol. 21, no. 2, pp. 1381–1394, 2018
2018
-
[31]
A comprehensive analysis of cloud service models: Iaas, paas, and saas in the context of emerging technologies and trend,
R. Younis, M. Iqbal, K. Munir, M. A. Javed, M. Haris, and S. Alahmari, “A comprehensive analysis of cloud service models: Iaas, paas, and saas in the context of emerging technologies and trend,” in2024 international conference on electrical, communication and computer engineering (ICECCE). IEEE, 2024, pp. 1–6
2024
-
[32]
Auto- nomic cloud resource provisioning and scheduling using meta-heuristic algorithm,
M. Kumar, S. C. Sharma, S. Goel, S. K. Mishra, and A. Husain, “Auto- nomic cloud resource provisioning and scheduling using meta-heuristic algorithm,”Neural Computing and Applications, vol. 32, no. 24, pp. 18 285–18 303, 2020
2020
-
[33]
P.-Y . Lin and Y .-l. Tsai, “Scorerag: A retrieval-augmented generation framework with consistency-relevance scoring and structured summa- rization for news generation,”arXiv preprint arXiv:2506.03704, 2025
-
[34]
Rear: A relevance-aware retrieval-augmented framework for open-domain ques- tion answering,
Y . Wang, R. Ren, J. Li, W. X. Zhao, J. Liu, and J.-R. Wen, “Rear: A relevance-aware retrieval-augmented framework for open-domain ques- tion answering,”arXiv preprint arXiv:2402.17497, 2024
-
[35]
(2025) Aws pricing
Amazon. (2025) Aws pricing. [Online]. Available: https://aws.amazon. com/pricing/
2025
-
[36]
Haystack for Buidling RAG Piplelines
Haystack. Haystack for Buidling RAG Piplelines. Accessed: 2025-08-
2025
-
[37]
Available: https://haystack.deepset.ai/overview/intro
[Online]. Available: https://haystack.deepset.ai/overview/intro
-
[38]
LlamaIndex Vector Store
LlamaIndex. LlamaIndex Vector Store . Accessed: 2025-08-08. [Online]. Available: https://tinyurl.com/LlamaIndex-Vector-Store
2025
-
[39]
M. FAISS. META FAISS Vector Database. Accessed: 2025-08-08. [Online]. Available: https://faiss.ai/index.html
2025
-
[40]
Pinecone Vector Database
Pinecone. Pinecone Vector Database. Accessed: 2025-08-08. [Online]. Available: https://www.pinecone.io/
2025
-
[41]
Chroma Vector Database
Chroma. Chroma Vector Database. Accessed: 2025-08-08. [Online]. Available: https://docs.trychroma.com/
2025
-
[42]
E. Stack. Elastic Search Relevance Engine. Accessed: 2025- 08-08. [Online]. Available: https://www.elastic.co/elasticsearch/ elasticsearch-relevance-engine
2025
-
[43]
OpenZeppelin Smart Contract
OpenZeppelin. OpenZeppelin Smart Contract. Accessed: 2025- 08-09. [Online]. Available: https://github.com/OpenZeppelin/ openzeppelin-contracts
2025
-
[44]
Consensys Smart Contract
Consensys. Consensys Smart Contract. Accessed: 2025-08-09. [Online]. Available: https://github.com/Consensys
2025
-
[45]
Zuora Revenue Sharing
Zuora. Zuora Revenue Sharing. Accessed: 2025-08-09. [Online]. Available: https://www.zuora.com/
2025
-
[46]
Chargebee Revenue Sharing
Chargebee. Chargebee Revenue Sharing. Accessed: 2025-08-09. [Online]. Available: https://www.chargebee.com/
2025
-
[47]
Lamaindex RAG Framework
Llamaindex. Lamaindex RAG Framework. Accessed: 2024-05-06. [Online]. Available: https://docs.llamaindex.ai/en/stable/
2024
-
[48]
ChatGPT 3.5
OpenAI. ChatGPT 3.5. Accessed: 2024-05-06. [Online]. Available: https://www.chatgpt.com/
2024
-
[49]
LlamaIndex Embedding
LlamaIndex. LlamaIndex Embedding . Accessed: 2024-08-07. [Online]. Available: https://tinyurl.com/LlamaIndex-Embedding
2024
-
[50]
Raptor: Recursive abstractive processing for tree-organized retrieval,
P. Sarthi, S. Abdullah, A. Tuli, S. Khanna, A. Goldie, and C. D. Manning, “Raptor: Recursive abstractive processing for tree-organized retrieval,” inThe Twelfth International Conference on Learning Repre- sentations, 2024
2024
-
[51]
Retrieval augmented generation or long-context llms? a comprehensive study and hybrid approach,
Z. Li, C. Li, M. Zhang, Q. Mei, and M. Bendersky, “Retrieval augmented generation or long-context llms? a comprehensive study and hybrid approach,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2024, pp. 881–893
2024
-
[52]
(2025) Llamaindex similarity metrics
LlamaIndex. (2025) Llamaindex similarity metrics. [Online]. Available: https://tinyurl.com/m4p9ucus
2025
-
[53]
LlamaIndex Cosine Similarity
——. LlamaIndex Cosine Similarity . Accessed: 2025-09-09. [Online]. Available: https://tinyurl.com/LlamaIndex-Cosine-Similarity
2025
-
[54]
(2025) Llamaindex similarity metrics
ScienceDirect. (2025) Llamaindex similarity metrics. [Online]. Available: https://www.sciencedirect.com/topics/computer-science/ cosine-similarity
2025
-
[55]
(2025) LlamaIndex Chunk Size Evaluation
LlamaIndex. (2025) LlamaIndex Chunk Size Evaluation. [Online]. Available: https://www.llamaindex.ai/blog/ evaluating-the-ideal-chunk-size-for-a-rag-system-using-llamaindex-6207e5d3fec5
2025
-
[56]
Chen and C.-J
P.-Y . Chen and C.-J. Hsieh,Adversarial robustness for machine learning. Academic Press, 2022
2022
-
[57]
Warr,Strengthening deep neural networks: Making AI less susceptible to adversarial trickery
K. Warr,Strengthening deep neural networks: Making AI less susceptible to adversarial trickery. O’Reilly Media, 2019
2019
-
[58]
Christian and T
B. Christian and T. Griffiths,Algorithms to live by: The computer science of human decisions. Macmillan, 2016. 17 Shawqi Al-Malikiis currently a postdoctoral re- searcher at Hamad Bin Khalifa University (HBKU), Doha, Qatar. He received his M.Sc. degree from King Fahd University of Petroleum and Minerals (KFUPM) in Dhahran, Saudi Arabia, in 2018, and his P...
2016
-
[59]
Prior to his academic career, Dr
His research interests span adversarial robust- ness, LLMs security, privacy, reliability, and human- LLM alignment. Prior to his academic career, Dr. Al- Maliki held positions as a Full-Stack Web Developer & Project Manager at Alyaum Media House (2009-
2009
-
[60]
and a computer instructor at New Horizon Institute (2006-2008), both in Saudi Arabia. Dr. Ammar Gharaibehis an Associate Professor with the Computer Engineering department of Ger- man Jordanian University, and currently serving as the Acting Dean of the School of Computing at GJU. He received his Ph.D. degree in Computer Engineering from New Jersey Instit...
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.