Recognition: unknown
EdgeSpike: Spiking Neural Networks for Low-Power Autonomous Sensing in Edge IoT Architectures
Pith reviewed 2026-05-07 12:31 UTC · model grok-4.3
The pith
Spiking neural networks match standard accuracy on edge sensors while using 31 times less energy on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EdgeSpike unifies hybrid surrogate-gradient and direct-encoding training, hardware-aware neural architecture search bounded by per-inference energy and memory budgets, event-driven runtime with spike-sparse kernels on neuromorphic and microcontroller targets, and a lightweight local plasticity rule for continual on-device adaptation. Across five sensing tasks the models reach 91.4 percent mean accuracy, 1.2 points below strong eight-bit baseline networks at 92.6 percent, while cutting energy per inference by a mean factor of 31 on neuromorphic hardware and 6.1 on microcontrollers. Latency stays at or below 9.4 milliseconds in all fifteen task-hardware pairings. A seven-month deployment of 64
What carries the argument
The EdgeSpike co-design pipeline that searches for spiking architectures under explicit energy and memory caps and supplies a local plasticity rule for ongoing adaptation without backpropagation.
If this is right
- Accuracy stays competitive with established networks on keyword spotting, vibration fault detection, muscle-signal gesture recognition, radar activity classification, and acoustic emission monitoring.
- Energy per inference drops enough to multiply projected battery runtime by several times in wireless sensor nodes.
- Local adaptation limits accuracy loss under seasonal input drift without requiring external retraining.
- Automated architecture search finds efficient designs that fit varying hardware energy and memory limits while preserving the reported gains.
Where Pith is reading between the lines
- Widespread use of such networks could support denser deployments of remote sensors where battery replacement is costly or impractical.
- If the energy reductions scale to additional tasks, spiking networks could replace conventional ones as the default for always-on edge classification.
- Adding explicit latency constraints to the architecture search might produce designs better suited to time-sensitive applications.
- Checking performance on a wider range of hardware would clarify how broadly the efficiency claims apply.
Load-bearing premise
The architecture search and local plasticity rule will keep delivering accuracy and energy advantages when applied to sensing tasks, seasonal conditions, or hardware setups beyond the five tasks and three platforms that were tested.
What would settle it
Re-running the full evaluation on a new sensing task outside the original five or on a fourth hardware platform and finding energy savings below 3 times or accuracy more than 3 points below the baseline would show the generalization does not hold.
Figures


read the original abstract
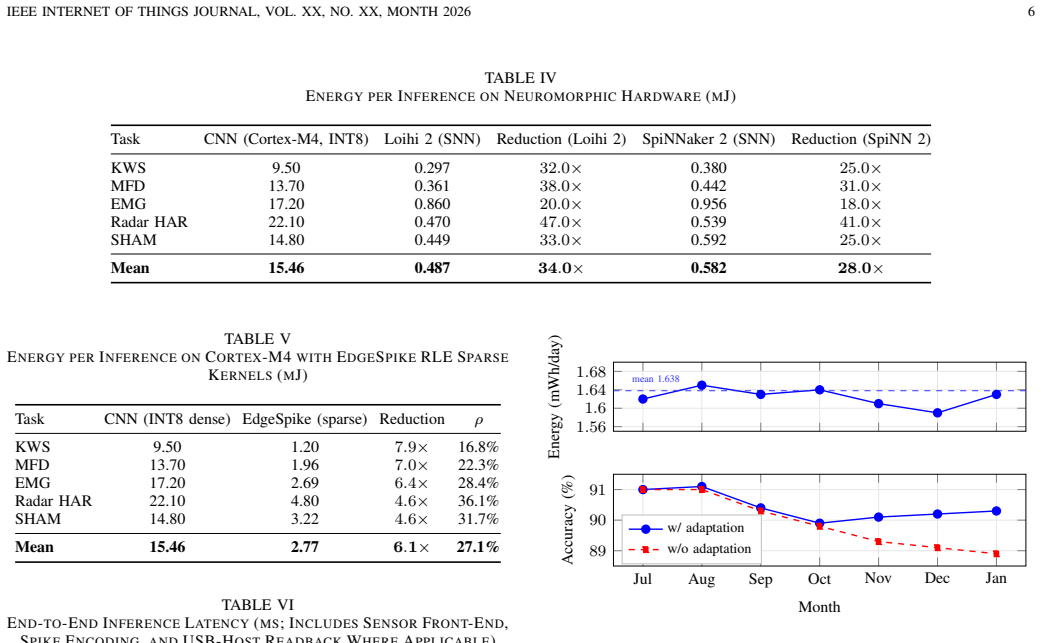
We propose EdgeSpike, a co-designed spiking neural network (SNN) framework for autonomous low-power sensing in edge Internet of Things (IoT) architectures. EdgeSpike unifies (i) a hybrid surrogate-gradient and direct-encoding training pipeline, (ii) a hardware-aware neural architecture search (NAS) bounded by per-inference energy and memory budgets, (iii) an event-driven runtime targeting Intel Loihi 2, SpiNNaker 2, and commodity ARM Cortex-M microcontrollers with custom spike-sparse SIMD kernels, and (iv) a lightweight local plasticity rule enabling continual on-device adaptation without backpropagation. The framework is evaluated across five sensing tasks (keyword spotting, vibration-based machine fault detection, surface electromyography gesture recognition, 77 GHz radar human-activity classification, and structural-health acoustic-emission monitoring) on three hardware targets. EdgeSpike achieves a mean classification accuracy of 91.4%, within 1.2 percentage points (pp) of strong INT8 convolutional neural network (CNN) baselines (mean 92.6%), while reducing energy per inference by 18x to 47x on neuromorphic hardware (mean 31x) and by 4.6x to 7.9x on Cortex-M (mean 6.1x). End-to-end latency remains at or below 9.4 ms across all 15 task-hardware configurations. A seven-month, 64-node wireless field deployment confirms a 6.3x extension in projected battery lifetime (from 312 to 1978 days at 2 Wh per node) and bounded accuracy degradation under seasonal drift (0.7 pp with on-device adaptation versus 2.1 pp without). Hardware-aware NAS evaluates 8400 candidates and yields a 12-point Pareto front. EdgeSpike will be released as open source with reproducible training pipelines, hardware-portable runtimes, and benchmark suites.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents EdgeSpike, a co-designed SNN framework for low-power autonomous sensing in edge IoT. It unifies a hybrid surrogate-gradient and direct-encoding training pipeline, hardware-aware NAS constrained by energy and memory budgets, event-driven runtimes for Loihi 2, SpiNNaker 2, and Cortex-M with spike-sparse kernels, and a lightweight local plasticity rule for on-device continual adaptation. Evaluations on five sensing tasks (keyword spotting, vibration fault detection, sEMG gesture recognition, 77 GHz radar activity classification, structural-health acoustic monitoring) across the three hardware targets report a mean accuracy of 91.4% (within 1.2 pp of INT8 CNN baselines at 92.6%), energy reductions of 18-47x (mean 31x) on neuromorphic hardware and 4.6-7.9x (mean 6.1x) on Cortex-M, latency at or below 9.4 ms, and a 7-month 64-node field deployment showing 6.3x projected battery lifetime extension (312 to 1978 days) with adaptation limiting seasonal drift to 0.7 pp. The NAS evaluated 8400 candidates for a 12-point Pareto front; the framework will be released open-source with reproducible pipelines and benchmarks.
Significance. If the quantitative claims can be verified through added statistical rigor and the generalization holds under broader testing, the work would advance practical SNN deployment for energy-constrained IoT by demonstrating near-CNN accuracy at substantially lower power with on-device adaptation. The scale of the NAS search (8400 candidates), the multi-hardware runtime support, and the explicit open-source commitment with reproducible training pipelines, hardware-portable runtimes, and benchmark suites are concrete strengths that would aid adoption and independent validation.
major comments (3)
- [Results section] Results section (performance tables and text reporting the 91.4% mean accuracy, 31x mean energy reduction, and 6.1x Cortex-M reduction): The aggregate figures are given without error bars, standard deviations, number of experimental runs, or statistical significance tests against baselines. This directly affects verifiability of whether the 1.2 pp accuracy margin and the energy savings ranges are reliable across the 15 task-hardware configurations.
- [Field deployment section] Field deployment section (seven-month 64-node wireless experiment): The 6.3x battery lifetime extension and 0.7 pp vs. 2.1 pp drift claims rest on a single deployment without reported details on node variability, data exclusion rules, full protocols, or tests under additional seasonal conditions. This leaves the robustness to real-world variability as an extrapolation rather than a demonstrated result.
- [Baseline and NAS descriptions] Baseline and NAS descriptions: The INT8 CNN baselines are called 'strong' without exact architectures, training protocols, or confirmation that they were optimized under identical hardware constraints; similarly, the energy/memory bounds used to evaluate the 8400 NAS candidates are not specified with equations or pseudocode, hindering reproduction of the 12-point Pareto front and the final models.
minor comments (2)
- [Abstract] Abstract: The phrasing of energy reduction ranges ('18x to 47x ... mean 31x') would benefit from explicit statement of how the mean is computed (arithmetic average across configurations or otherwise) to remove ambiguity.
- [Notation and figures] Notation and figures: Define 'pp' on first use in the main text; ensure figure legends explicitly label hardware platforms and tasks for each plotted point to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with specific plans for revision to improve statistical rigor, reproducibility, and transparency of the results.
read point-by-point responses
-
Referee: [Results section] Results section (performance tables and text reporting the 91.4% mean accuracy, 31x mean energy reduction, and 6.1x Cortex-M reduction): The aggregate figures are given without error bars, standard deviations, number of experimental runs, or statistical significance tests against baselines. This directly affects verifiability of whether the 1.2 pp accuracy margin and the energy savings ranges are reliable across the 15 task-hardware configurations.
Authors: We agree that the current presentation lacks sufficient statistical detail. In the revised manuscript we will report the number of independent runs (minimum five random seeds per task-hardware pair), include standard deviations and error bars on all aggregate figures, and add statistical significance tests (paired t-tests or Wilcoxon signed-rank tests with p-values) comparing EdgeSpike against the INT8 CNN baselines. These additions will directly support the reliability of the reported 1.2 pp accuracy margin and the energy-reduction ranges. revision: yes
-
Referee: [Field deployment section] Field deployment section (seven-month 64-node wireless experiment): The 6.3x battery lifetime extension and 0.7 pp vs. 2.1 pp drift claims rest on a single deployment without reported details on node variability, data exclusion rules, full protocols, or tests under additional seasonal conditions. This leaves the robustness to real-world variability as an extrapolation rather than a demonstrated result.
Authors: We acknowledge the need for greater transparency. The revised field-deployment section will include node-to-node variability statistics, explicit data-exclusion criteria, complete experimental protocols, and any seasonal observations recorded during the seven-month period. Because the study consisted of a single long-term deployment, we cannot add new multi-seasonal experiments at this stage; the expanded details will nevertheless allow readers to better assess the robustness of the 6.3x lifetime and drift claims. revision: partial
-
Referee: [Baseline and NAS descriptions] Baseline and NAS descriptions: The INT8 CNN baselines are called 'strong' without exact architectures, training protocols, or confirmation that they were optimized under identical hardware constraints; similarly, the energy/memory bounds used to evaluate the 8400 NAS candidates are not specified with equations or pseudocode, hindering reproduction of the 12-point Pareto front and the final models.
Authors: We will add a dedicated table (or appendix) listing the exact layer configurations, filter sizes, and training hyperparameters (optimizer, learning-rate schedule, data augmentation) for each INT8 CNN baseline, together with a statement confirming that they were optimized under the same energy and memory constraints used for EdgeSpike. For the NAS we will insert the precise energy and memory bound equations and pseudocode describing the constrained search, enabling independent reproduction of the 8400-candidate evaluation and the resulting 12-point Pareto front. revision: yes
Circularity Check
No circularity; results are direct empirical measurements from evaluations and deployment.
full rationale
The paper describes a co-designed SNN framework (hybrid training, hardware-aware NAS, event-driven runtime, local plasticity rule) and reports performance via direct experiments: mean 91.4% accuracy on five sensing tasks, energy reductions measured on Loihi 2/SpiNNaker 2/Cortex-M, and 6.3x battery extension from a 7-month 64-node field deployment. No equations, derivations, or first-principles claims appear that reduce to fitted parameters or self-citations by construction. NAS is described as evaluating 8400 candidates to produce a Pareto front, but this is an empirical search outcome, not a tautological prediction. All quantitative claims are presented as measured outcomes rather than quantities forced by the paper's own inputs or prior self-citations. The central results therefore remain independent of any circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Internet of Things: A survey,
L. Atzori, A. Iera, and G. Morabito, “The Internet of Things: A survey,” Comput. Netw., vol. 54, no. 15, pp. 2787-2805, Oct. 2010
2010
-
[2]
A survey on Internet of Things: Architecture, enabling technologies, security and privacy, and applications,
J. Lin, W. Yu, N. Zhang, X. Yang, H. Zhang, and W. Zhao, “A survey on Internet of Things: Architecture, enabling technologies, security and privacy, and applications,”IEEE Internet Things J., vol. 4, no. 5, pp. 1125-1142, Oct. 2017
2017
-
[3]
Quantization and training of neural networks for efficient integer-arithmetic-only inference,
B. Jacobet al., “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” inProc. IEEE/CVF CVPR, 2018, pp. 2704-2713
2018
-
[4]
Quantizing deep convolutional networks for efficient inference: A whitepaper
R. Krishnamoorthi, “Quantizing deep convolutional networks for effi- cient inference: A whitepaper,” arXiv:1806.08342, 2018
-
[5]
Hello edge: Keyword spotting on microcontrollers,
Y . Zhang, N. Suda, L. Lai, and V . Chandra, “Hello edge: Keyword spotting on microcontrollers,” arXiv:1711.07128, 2017
-
[6]
Deep residual learning for small-footprint keyword spotting,
R. Tang and J. Lin, “Deep residual learning for small-footprint keyword spotting,” inProc. IEEE ICASSP, 2018, pp. 5484-5488
2018
-
[7]
A review of structural health monitoring literature: 1996- 2001,
H. Sohnet al., “A review of structural health monitoring literature: 1996- 2001,” Los Alamos Nat. Lab., LA-13976-MS, 2003
1996
-
[8]
Networks of spiking neurons: The third generation of neural network models,
W. Maass, “Networks of spiking neurons: The third generation of neural network models,”Neural Netw., vol. 10, no. 9, pp. 1659-1671, Dec. 1997
1997
-
[9]
Memory and information processing in neuromorphic systems,
G. Indiveri and S.-C. Liu, “Memory and information processing in neuromorphic systems,”Proc. IEEE, vol. 103, no. 8, pp. 1379-1397, Aug. 2015
2015
-
[10]
Loihi: A neuromorphic manycore processor with on- chip learning,
M. Davieset al., “Loihi: A neuromorphic manycore processor with on- chip learning,”IEEE Micro, vol. 38, no. 1, pp. 82-99, Jan./Feb. 2018
2018
-
[11]
Advancing neuromorphic computing with Loihi: A survey of results and outlook,
M. Davieset al., “Advancing neuromorphic computing with Loihi: A survey of results and outlook,”Proc. IEEE, vol. 109, no. 5, pp. 911-934, May 2021
2021
-
[12]
arXiv preprint arXiv:1911.02385 (2019)
C. Mayr, S. Hoeppner, and S. Furber, “SpiNNaker 2: A 10 million core processor system for brain simulation and machine learning,” arXiv:1911.02385, 2019
-
[13]
Sparse convolutional neural networks,
B. Liuet al., “Sparse convolutional neural networks,” inProc. IEEE/CVF CVPR, 2015, pp. 806-814
2015
-
[14]
SuperSpike: Supervised learning in multilayer spiking neural networks,
F. Zenke and S. Ganguli, “SuperSpike: Supervised learning in multilayer spiking neural networks,”Neural Comput., vol. 30, no. 6, pp. 1514-1541, Jun. 2018
2018
-
[15]
Deep learning in spiking neural networks,
A. Tavanaei, M. Ghodrati, S. R. Kheradpisheh, T. Masquelier, and A. Maida, “Deep learning in spiking neural networks,”Neural Netw., vol. 111, pp. 47-63, Mar. 2019
2019
-
[16]
Efficient processing of deep neural networks: A tutorial and survey,
V . Sze, Y .-H. Chen, T.-J. Yang, and J. S. Emer, “Efficient processing of deep neural networks: A tutorial and survey,”Proc. IEEE, vol. 105, no. 12, pp. 2295-2329, Dec. 2017
2017
-
[17]
Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing,
P. U. Diehl, D. Neil, J. Binas, M. Cook, S.-C. Liu, and M. Pfeiffer, “Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing,” inProc. IEEE IJCNN, 2015, pp. 1-8
2015
-
[18]
Con- version of continuous-valued deep networks to efficient event-driven networks for image classification,
B. Rueckauer, I.-A. Lungu, Y . Hu, M. Pfeiffer, and S.-C. Liu, “Con- version of continuous-valued deep networks to efficient event-driven networks for image classification,”Front. Neurosci., vol. 11, p. 682, Dec. 2017
2017
-
[19]
Surrogate gradient learning in spiking neural networks,
E. O. Neftci, H. Mostafa, and F. Zenke, “Surrogate gradient learning in spiking neural networks,”IEEE Signal Process. Mag., vol. 36, no. 6, pp. 51-63, Nov. 2019
2019
-
[20]
Incorporating learnable membrane time constant to enhance learning of spiking neural networks,
W. Fang, Z. Yu, Y . Chen, T. Masquelier, T. Huang, and Y . Tian, “Incorporating learnable membrane time constant to enhance learning of spiking neural networks,” inProc. IEEE/CVF ICCV, 2021, pp. 2661- 2671
2021
-
[21]
Spatio-temporal backprop- agation for training high-performance spiking neural networks,
Y . Wu, L. Deng, G. Li, J. Zhu, and L. Shi, “Spatio-temporal backprop- agation for training high-performance spiking neural networks,”Front. Neurosci., vol. 12, p. 331, May 2018
2018
-
[22]
Going deeper with directly-trained larger spiking neural networks,
H. Zheng, Y . Wu, L. Deng, Y . Hu, and G. Li, “Going deeper with directly-trained larger spiking neural networks,” inProc. AAAI, 2021, pp. 11062-11070
2021
-
[23]
TrueNorth: Design and tool flow of a 65 mW 1 million neuron programmable neurosynaptic chip,
F. Akopyanet al., “TrueNorth: Design and tool flow of a 65 mW 1 million neuron programmable neurosynaptic chip,”IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst., vol. 34, no. 10, pp. 1537- 1557, Oct. 2015
2015
-
[24]
Accurate and efficient time- domain classification with adaptive spiking recurrent neural networks,
B. Yin, F. Corradi, and S. M. Bohté, “Accurate and efficient time- domain classification with adaptive spiking recurrent neural networks,” Nat. Mach. Intell., vol. 3, pp. 905-913, Sep. 2021
2021
-
[25]
Towards spike-based machine intelligence with neuromorphic computing,
K. Roy, A. Jaiswal, and P. Panda, “Towards spike-based machine intelligence with neuromorphic computing,”Nature, vol. 575, pp. 607- 617, Nov. 2019
2019
-
[26]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howardet al., “MobileNets: Efficient convolutional neural net- works for mobile vision applications,” arXiv:1704.04861, 2017
work page internal anchor Pith review arXiv 2017
-
[27]
EfficientNet: Rethinking model scaling for convolutional neural networks,
M. Tan and Q. V . Le, “EfficientNet: Rethinking model scaling for convolutional neural networks,” inProc. ICML, 2019, pp. 6105-6114
2019
-
[28]
Once-for-all: Train one network and specialize it for efficient deployment,
H. Cai, C. Gan, T. Wang, Z. Zhang, and S. Han, “Once-for-all: Train one network and specialize it for efficient deployment,” inProc. ICLR, 2020
2020
-
[29]
MCUNet: Tiny deep learning on IoT devices,
J. Lin, W.-M. Chen, Y . Lin, J. Cohn, C. Gan, and S. Han, “MCUNet: Tiny deep learning on IoT devices,” inProc. NeurIPS, 2020, pp. 11711- 11722
2020
-
[30]
MicroNets: Neural network architectures for deploying TinyML applications on commodity microcontrollers,
C. R. Banburyet al., “MicroNets: Neural network architectures for deploying TinyML applications on commodity microcontrollers,” in Proc. MLSys, 2021, pp. 517-532
2021
-
[31]
SpikNAS: Evolutionary neural architecture search for spiking neural networks,
Y . Na, S. Mukhopadhyay, and J. Kim, “SpikNAS: Evolutionary neural architecture search for spiking neural networks,” inProc. ICML Work- shops, 2022
2022
-
[32]
AutoSNN: Towards energy-efficient spiking neural networks,
B. Na, J. Mok, S. Park, D. Lee, H. Choe, and S. Yoon, “AutoSNN: Towards energy-efficient spiking neural networks,” inProc. ICML, 2022, pp. 16253-16269
2022
-
[33]
Neural architecture search for spiking neural networks,
Y . Kim, Y . Li, H. Park, Y . Venkatesha, and P. Panda, “Neural architecture search for spiking neural networks,” inProc. ECCV, 2022, pp. 36-56
2022
-
[34]
MLPerf Tiny benchmark,
C. Banburyet al., “MLPerf Tiny benchmark,” inProc. NeurIPS Datasets and Benchmarks Track, 2021
2021
-
[35]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatricket al., “Overcoming catastrophic forgetting in neural networks,”Proc. Nat. Acad. Sci., vol. 114, no. 13, pp. 3521-3526, Mar. 2017
2017
-
[36]
TinyTL: Reduce memory, not parameters for efficient on-device learning,
H. Cai, C. Gan, L. Zhu, and S. Han, “TinyTL: Reduce memory, not parameters for efficient on-device learning,” inProc. NeurIPS, 2020, pp. 11285-11297
2020
-
[37]
Synaptic modifications in cultured hip- pocampal neurons: Dependence on spike timing, synaptic strength, and postsynaptic cell type,
G. Q. Bi and M. M. Poo, “Synaptic modifications in cultured hip- pocampal neurons: Dependence on spike timing, synaptic strength, and postsynaptic cell type,”J. Neurosci., vol. 18, no. 24, pp. 10464-10472, Dec. 1998
1998
-
[38]
A solution to the learning dilemma for recurrent networks of spiking neurons,
G. Bellecet al., “A solution to the learning dilemma for recurrent networks of spiking neurons,”Nat. Commun., vol. 11, p. 3625, Jul. 2020
2020
-
[39]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. ICLR, 2019
2019
-
[40]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
P. Warden, “Speech commands: A dataset for limited-vocabulary speech recognition,” arXiv:1804.03209, 2018
work page Pith review arXiv 2018
-
[41]
Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study,
W. A. Smith and R. B. Randall, “Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study,” Mech. Syst. Signal Process., vol. 64-65, pp. 100-131, Dec. 2015
2015
-
[42]
The history and development of acoustic emission in concrete engineering,
M. Ohtsu, “The history and development of acoustic emission in concrete engineering,”Mag. Concr. Res., vol. 48, no. 177, pp. 321-330, 1996
1996
-
[43]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE CVPR, 2016, pp. 770-778
2016
-
[44]
TensorFlow Lite Micro: Embedded machine learning for TinyML systems,
R. Davidet al., “TensorFlow Lite Micro: Embedded machine learning for TinyML systems,” inProc. MLSys, 2021, pp. 800-811
2021
-
[45]
CMSIS-NN: Efficient neural network kernels for ARM Cortex-M CPUs,
L. Lai, N. Suda, and V . Chandra, “CMSIS-NN: Efficient neural network kernels for ARM Cortex-M CPUs,” arXiv:1801.06601, 2018
-
[46]
A study of LoRa: Long range and low power networks for the Internet of Things,
A. Augustin, J. Yi, T. Clausen, and W. M. Townsley, “A study of LoRa: Long range and low power networks for the Internet of Things,”Sensors, vol. 16, no. 9, p. 1466, Sep. 2016
2016
-
[47]
STM32L496xx Datasheet: Ultra-low-power Arm Cortex-M4 32-bit MCU+FPU,
STMicroelectronics, “STM32L496xx Datasheet: Ultra-low-power Arm Cortex-M4 32-bit MCU+FPU,” DS11585, Rev. 6, 2020
2020
-
[48]
STM32L4 Series Reference Manual RM0351,
STMicroelectronics, “STM32L4 Series Reference Manual RM0351,” Rev. 9, 2022
2022
-
[49]
Sparse GPU kernels for deep learning,
T. Gale, M. Zaharia, C. Young, and E. Elsen, “Sparse GPU kernels for deep learning,” inProc. SC, 2020, pp. 1-14
2020
-
[50]
Spike-driven Transformer V2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips,
M. Yao, J. Hu, T. Hu, Y . Xu, Z. Zhou, Y . Tian, B. Xu, and G. Li, “Spike-driven Transformer V2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips,” inProc. ICLR, 2024
2024
-
[51]
Neural inference at the frontier of energy, space, and time,
D. S. Modhaet al., “Neural inference at the frontier of energy, space, and time,”Science, vol. 382, no. 6668, pp. 329-335, Oct. 2023
2023
-
[52]
S. Hoeppneret al., “The SpiNNaker 2 processing element architecture for hybrid digital neuromorphic computing,” arXiv:2103.08392, 2021. IEEE INTERNET OF THINGS JOURNAL, VOL. XX, NO. XX, MONTH 2026 9 Gustav Olaf Yunus Laitinen-Fredriksson Lundström-Imanovreceived the M.Sc. degree in statistics and machine learning from Linköping University, Linköping, Swed...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.