Recognition: unknown
CL-bench Life: Can Language Models Learn from Real-Life Context?
Pith reviewed 2026-05-07 09:38 UTC · model grok-4.3
The pith
Frontier language models cannot reliably learn from messy real-life contexts, solving tasks at only 19.3 percent even for the best performer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
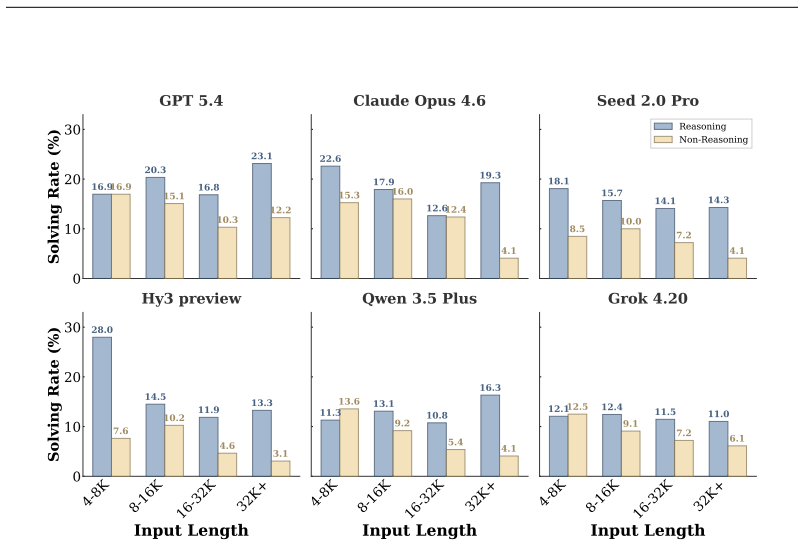
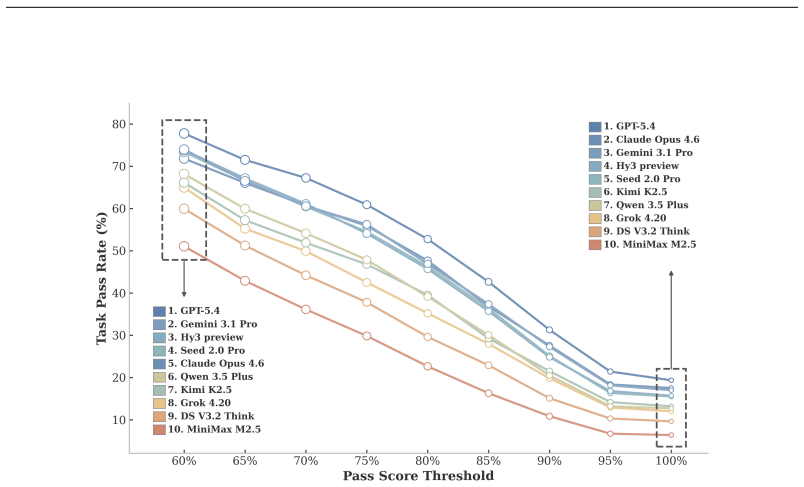
Real-life context learning remains highly challenging for current frontier language models. Even the best-performing model achieves only 19.3 percent task solving rate on CL-bench Life, while the average across ten models is 13.8 percent. Models struggle particularly with reasoning over messy group chat histories and fragmented behavioral records from everyday life. The benchmark consists of 405 human-curated context-task pairs and 5,348 rubrics designed to require strong abilities to learn from complex, personal, and fragmented real-life contexts that go beyond existing professional or synthetic benchmarks.
What carries the argument
CL-bench Life benchmark, a set of 405 human-curated context-task pairs and 5,348 verification rubrics covering real-life scenarios such as multi-party conversations, personal archives, and behavioral traces.
If this is right
- Frontier models require substantial advances before they can serve as reliable everyday personal assistants.
- Progress on CL-bench Life would directly improve AI handling of personal conversations and records.
- Current evaluation methods that use clean or professional contexts are insufficient for real-life applications.
- New training techniques focused on fragmented and multi-party data are needed to close the performance gap.
- The benchmark serves as a testbed that can guide development of more capable life-context models.
Where Pith is reading between the lines
- Improving performance here may require explicit handling of privacy constraints when models process personal archives.
- The gap suggests that simply increasing model size may not close the difference between professional and personal context handling.
- The benchmark could be extended with dynamic, ongoing contexts to better simulate real assistant usage over time.
- Low scores indicate that models may need separate modules for integrating behavioral traces rather than treating all context as text alone.
Load-bearing premise
The 405 context-task pairs and 5,348 rubrics faithfully represent the core difficulties of real-life context learning and that success on them will predict performance in actual personal use.
What would settle it
A new model scoring above 70 percent on the benchmark yet still failing to handle personal tasks in uncontrolled real-world settings, or a model scoring below 10 percent that succeeds in those settings.
Figures









read the original abstract
Today's AI assistants such as OpenClaw are designed to handle context effectively, making context learning an increasingly important capability for models. As these systems move beyond professional settings into everyday life, the nature of the contexts they must handle also shifts. Real-life contexts are often messy, fragmented, and deeply tied to personal and social experience, such as multi-party conversations, personal archives, and behavioral traces. Yet it remains unclear whether current frontier language models can reliably learn from such contexts and solve tasks grounded in them. To this end, we introduce CL-bench Life, a fully human-curated benchmark comprising 405 context-task pairs and 5,348 verification rubrics, covering common real-life scenarios. Solving tasks in CL-bench Life requires models to reason over complex, messy real-life contexts, calling for strong real-life context learning abilities that go far beyond those evaluated in existing benchmarks. We evaluate ten frontier LMs and find that real-life context learning remains highly challenging: even the best-performing model achieves only 19.3% task solving rate, while the average performance across models is only 13.8%. Models still struggle to reason over contexts such as messy group chat histories and fragmented behavioral records from everyday life. CL-bench Life provides a crucial testbed for advancing real-life context learning, and progress on it can enable more intelligent and reliable AI assistants in everyday life.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CL-bench Life, a human-curated benchmark of 405 context-task pairs and 5,348 verification rubrics targeting real-life scenarios such as multi-party chats and personal behavioral traces. It evaluates ten frontier language models, reports a maximum task-solving rate of 19.3% and an average of 13.8%, and concludes that real-life context learning remains highly challenging for current models.
Significance. If the benchmark construction and evaluation protocol are shown to be reliable, the work would provide a useful testbed for measuring progress on context learning outside professional settings. The scale of the rubric set is a positive feature for reproducible scoring.
major comments (2)
- [Abstract] Abstract: The claim that the reported scores demonstrate inherent difficulty in real-life context learning is not supported by the provided evidence. No human performance baseline on the same 405 pairs using the 5,348 rubrics is reported, nor are inter-annotator agreement statistics or details on how task difficulty and representativeness were controlled during curation. These omissions are load-bearing for interpreting low model scores as model limitations rather than artifacts of benchmark design.
- [Benchmark construction and evaluation sections] Benchmark construction and evaluation sections: The manuscript states that the contexts are 'messy, fragmented, and deeply tied to personal experience' but provides no quantitative validation (e.g., distribution statistics or expert review) that the 405 pairs match actual personal-use distributions. Without such grounding, the generalizability of the 13.8% average result to 'everyday life' remains unestablished.
minor comments (1)
- [Results] The abstract and results sections would benefit from an explicit table listing per-model scores and error breakdowns to allow readers to identify which context types drive the low aggregate numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of benchmark validation that will strengthen the interpretation of our results. We address each major comment below and commit to revisions that incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the reported scores demonstrate inherent difficulty in real-life context learning is not supported by the provided evidence. No human performance baseline on the same 405 pairs using the 5,348 rubrics is reported, nor are inter-annotator agreement statistics or details on how task difficulty and representativeness were controlled during curation. These omissions are load-bearing for interpreting low model scores as model limitations rather than artifacts of benchmark design.
Authors: We agree that a human performance baseline would provide essential context for interpreting the low model scores as evidence of inherent difficulty rather than benchmark artifacts. We will collect and report human performance results on the full set of 405 tasks using the 5,348 rubrics in the revised manuscript. We will also add inter-annotator agreement statistics for the rubric creation process and expand the curation section with explicit details on how task difficulty was controlled (e.g., expert review for solvability) and how representativeness was ensured during selection of the 405 pairs. revision: yes
-
Referee: [Benchmark construction and evaluation sections] Benchmark construction and evaluation sections: The manuscript states that the contexts are 'messy, fragmented, and deeply tied to personal experience' but provides no quantitative validation (e.g., distribution statistics or expert review) that the 405 pairs match actual personal-use distributions. Without such grounding, the generalizability of the 13.8% average result to 'everyday life' remains unestablished.
Authors: We acknowledge the need for quantitative grounding to support claims of representativeness. Although the contexts were selected and verified by human experts drawing from real personal and social scenarios, the current manuscript lacks explicit distribution statistics. In the revision, we will add quantitative validation including context length distributions, participant counts, fragmentation metrics (e.g., message discontinuity rates), and summaries of expert review processes confirming alignment with everyday personal-use patterns. This will better establish the generalizability of the 13.8% average performance to real-life contexts. revision: yes
Circularity Check
No circularity: direct empirical evaluation on new benchmark
full rationale
The paper introduces CL-bench Life as a human-curated benchmark of 405 context-task pairs and 5,348 rubrics, then reports straightforward model evaluation results (e.g., 19.3% best task-solving rate). No equations, derivations, fitted parameters, or predictions appear in the provided text. The central claim rests on direct performance measurements rather than any reduction of outputs to inputs by construction, self-citation chains, or ansatz smuggling. This is a standard empirical benchmark paper whose findings are independent of the inputs they describe.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human curation produces reliable and representative tasks and rubrics for real-life contexts.
Reference graph
Works this paper leans on
-
[1]
L-eval: Instituting standardized evaluation for long context language models
Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-eval: Instituting standardized evaluation for long context language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 14388–14411, Bangkok, Thailand, August 2024. Associatio...
-
[2]
Introducing the next generation of claude, 2024
Anthropic. Introducing the next generation of claude, 2024. URL https://www. anthropic.com/news/claude-3-family
2024
-
[3]
System card: Claude opus 4.6, 2026
Anthropic. System card: Claude opus 4.6, 2026. URL https://www.anthropic.com/ claude-opus-4-6-system-card. System card
2026
-
[4]
arXiv preprint arXiv:2502.15840 , year =
Axel Backlund and Lukas Petersson. Vending-bench: A benchmark for long-term coherence of autonomous agents, 2025. URLhttps://arxiv.org/abs/2502.15840
-
[5]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 31...
2024
-
[6]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pp. 3119–3137, 2024
2024
-
[7]
LongBench v2: Towards deeper understanding and reasoning on realistic long-context multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Ji- azheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp...
-
[8]
Generative ai at work.The Quarterly Journal of Economics, 140(2):889–942, 2025
Erik Brynjolfsson, Danielle Li, and Lindsey Raymond. Generative ai at work.The Quarterly Journal of Economics, 140(2):889–942, 2025
2025
-
[9]
Gonzalez, and Ion Stoica
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Why do multi-agent LLM systems fail? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025....
2025
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review arXiv 2021
-
[11]
Textworld: A learning environment for text-based games, 2019
Marc-Alexandre Côté, Ákos Kádár, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine, James Moore, Ruo Yu Tao, Matthew Hausknecht, Layla El Asri, Mahmoud Adada, Wendy Tay, 17 and Adam Trischler. Textworld: A learning environment for text-based games, 2019. URL https://arxiv.org/abs/1806.11532
-
[12]
Gemini 3.1 pro model card, 2026
Google DeepMind. Gemini 3.1 pro model card, 2026. URLhttps://deepmind.google/ models/model-cards/gemini-3-1-pro/. Model card
2026
-
[13]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
work page internal anchor Pith review arXiv 2025
-
[14]
Mind2web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=kiYqbO3wqw
2023
-
[15]
Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier llms
Kaustubh Deshpande, Ved Sirdeshmukh, Johannes Baptist Mols, Lifeng Jin, Ed-Yeremai Hernandez-Cardona, Dean Lee, Jeremy Kritz, Willow E Primack, Summer Yue, and Chen Xing. Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier llms. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 18632–18...
2025
-
[16]
Octobench: Benchmarking scaffold-aware instruction following in repository-grounded agentic coding,
Deming Ding, Shichun Liu, Enhui Yang, Jiahang Lin, Ziying Chen, Shihan Dou, Honglin Guo, Weiyu Cheng, Pengyu Zhao, Chengjun Xiao, et al. Octobench: Benchmarking scaffold-aware instruction following in repository-grounded agentic coding.arXiv preprint arXiv:2601.10343, 2026. 18
-
[17]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. InProceedings of the 2024 conference on empirical methods in natural language processing, pp. 1107–1128, 2024
2024
-
[18]
Bamboo: A com- prehensive benchmark for evaluating long text modeling capacities of large language models
Zican Dong, Tianyi Tang, Junyi Li, Wayne Xin Zhao, and Ji-Rong Wen. Bamboo: A com- prehensive benchmark for evaluating long text modeling capacities of large language models. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pp. 2086–2099, 2024
2024
-
[19]
Shihan Dou, Ming Zhang, Chenhao Huang, Jiayi Chen, Feng Chen, Shichun Liu, Yan Liu, Chenxiao Liu, Cheng Zhong, Zongzhang Zhang, Tao Gui, Chao Xin, Chengzhi Wei, Lin Yan, Yonghui Wu, Qi Zhang, and Xuanjing Huang. Evalearn: Quantifying the learning capability and efficiency of llms via sequential problem solving, 2025. URLhttps://arxiv.org/ abs/2506.02672
-
[20]
Cl-bench: A benchmark for context learning
Shihan Dou, Ming Zhang, Zhangyue Yin, Chenhao Huang, Yujiong Shen, Junzhe Wang, Jiayi Chen, Yuchen Ni, Junjie Ye, Cheng Zhang, et al. Cl-bench: A benchmark for context learning. arXiv preprint arXiv:2602.03587, 2026
-
[21]
Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. Workarena: How capable are web agents at solving common knowledge work tasks? InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id= BRfqYrikdo
2024
-
[22]
What can transformers learn in-context? a case study of simple function classes
Shivam Garg, Dimitris Tsipras, Percy Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.),Advances in Neural Information Processing Systems,
-
[23]
URLhttps://openreview.net/forum?id=flNZJ2eOet
-
[24]
Wei He, Yueqing Sun, Hongyan Hao, Xueyuan Hao, Zhikang Xia, Qi Gu, Chengcheng Han, Dengchang Zhao, Hui Su, Kefeng Zhang, et al. Vitabench: Benchmarking llm agents with versatile interactive tasks in real-world applications.arXiv preprint arXiv:2509.26490, 2025
-
[25]
RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024. URL https://openreview.net/ forum?id=kIoBbc76Sy
2024
-
[26]
CL4SE: Benchmarking Context Learning on Software Engineering
Haichuan Hu, Quanjun Zhang, Ye Shang, Guoqing Xie, Chunrong Fang, Zhenyu Chen, and Liang Xiao. Cl4se: Benchmarking context learning on software engineering, 2026. URL https://arxiv.org/abs/2602.23047
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Videowebarena: Evaluating long context multimodal agents with video understanding web tasks
Lawrence Keunho Jang, Yinheng Li, Dan Zhao, Charles Ding, Justin Lin, Paul Pu Liang, Rogerio Bonatti, and Kazuhito Koishida. Videowebarena: Evaluating long context multimodal agents with video understanding web tasks. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=unDQOUah0F
2025
-
[28]
SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=VTF8yNQM66
2024
-
[29]
Babilong: Testing the limits of llms with long context reasoning-in-a-haystack
Yury Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Sorokin, and Mikhail Burtsev. Babilong: Testing the limits of llms with long context reasoning-in-a-haystack. Advances in Neural Information Processing Systems, 37:106519–106554, 2024
2024
-
[30]
Wai-Chung Kwan, Xingshan Zeng, Yufei Wang, Yusen Sun, Liangyou Li, Yuxin Jiang, Lifeng Shang, Qun Liu, and Kam-Fai Wong. M4LE: A multi-ability multi-range multi-task multi- domain long-context evaluation benchmark for large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
-
[31]
Taewhoo Lee, Chanwoong Yoon, Kyochul Jang, Donghyeon Lee, Minju Song, Hyunjae Kim, and Jaewoo Kang. ETHIC: Evaluating large language models on long-context tasks with high information coverage. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1...
-
[32]
URLhttps://aclanthology.org/2025.naacl-long.283/
2025
-
[33]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[34]
Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. LooGLE: Can long-context language models understand long contexts? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 16304–16333, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/ v1/2024.acl-...
2024
-
[35]
Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. Loogle: Can long-context language models understand long contexts? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 16304–16333, 2024
2024
-
[36]
Wildbench: Benchmarking LLMs with challeng- ing tasks from real users in the wild
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. Wildbench: Benchmarking LLMs with challeng- ing tasks from real users in the wild. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=MKEHCx25xp
2025
-
[37]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[38]
Agentbench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents. InThe Twelfth International Conference on Learning R...
2024
-
[39]
Agentboard: An analytical evaluation board of multi-turn LLM agents
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. Agentboard: An analytical evaluation board of multi-turn LLM agents. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps://openreview.net/forum?id= 4S8agvKjle
2024
-
[40]
Evaluating Very Long-Term Conversational Memory of
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 13851–13870, Bangkok, Thailand, August 2024. Association for Computational Li...
-
[41]
A Survey of Context Engineering for Large Language Models
Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, et al. A survey of context engineering for large language models. arXiv preprint arXiv:2507.13334, 2025
work page internal anchor Pith review arXiv 2025
-
[42]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants, 2023. URL https://arxiv.org/ abs/2311.12983
work page internal anchor Pith review arXiv 2023
-
[43]
Minimax m2.5: Built for real-world productivity, 2026
MiniMax. Minimax m2.5: Built for real-world productivity, 2026. URLhttps://minimax. io/news/minimax-m25. Official release page. 20
2026
-
[44]
Evaluation and benchmark- ing of llm agents: A survey
Mahmoud Mohammadi, Yipeng Li, Jane Lo, and Wendy Yip. Evaluation and benchmark- ing of llm agents: A survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, KDD ’25, pp. 6129–6139. Association for Com- puting Machinery, 2025. ISBN 9798400714542. doi: 10.1145/3711896.3736570. URL https://doi.org/10.1145/3711896.3736570
-
[45]
Introducing GPT-5
OpenAI. Introducing GPT-5. https://openai.com/index/ introducing-gpt-5-4/, 2025. Accessed: 2025
2025
-
[46]
Gpt-5.1, 2025
OpenAI. Gpt-5.1, 2025. URL https://openai.com/zh-Hans-CN/index/ gpt-5-1/
2025
-
[47]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InIn the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23), UIST ’23, New York, NY , USA, 2023. Association for Computing Machinery
2023
-
[48]
ChatDev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 15174–15186, Bang...
2024
-
[49]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InThe Twelfth International Conference on Learning...
2024
-
[50]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
2026
-
[51]
Qwen3.6-Plus: Towards real world agents, April 2026
Qwen Team. Qwen3.6-Plus: Towards real world agents, April 2026. URLhttps://qwen. ai/blog?id=qwen3.6
2026
-
[52]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=Yacmpz84TH
2023
-
[53]
Counting-stars: A multi-evidence, position-aware, and scalable benchmark for evaluating long-context large language models
Mingyang Song, Mao Zheng, and Xuan Luo. Counting-stars: A multi-evidence, position-aware, and scalable benchmark for evaluating long-context large language models. InProceedings of the 31st International Conference on Computational Linguistics, pp. 3753–3763, 2025
2025
-
[54]
OpenClaw: The ai that actually does things
Peter Steinberger and OpenClaw Contributors. OpenClaw: The ai that actually does things. https://github.com/openclaw/openclaw, 2025. Open-source AI agent framework. MIT License. Accessed: 2025
2025
-
[55]
Griffiths
Theodore Sumers, Shunyu Yao, Karthik R Narasimhan, and Thomas L. Griffiths. Cognitive architectures for language agents.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=1i6ZCvflQJ. Survey Cer- tification, Featured Certification
2024
-
[56]
Collab-overcooked: Benchmarking and evaluating large language models as collaborative agents
Haochen Sun, Shuwen Zhang, Lujie Niu, Lei Ren, Hao Xu, Hao Fu, Fangkun Zhao, Caixia Yuan, and Xiaojie Wang. Collab-overcooked: Benchmarking and evaluating large language models as collaborative agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 4922–4951, Suzhou, China, November 2025. Association for Comp...
-
[57]
Effective context engineering for ai agents, Sep 2025
Anthropic Applied AI Team. Effective context engineering for ai agents, Sep 2025. URL https://www.anthropic.com/engineering/ effective-context-engineering-for-ai-agents. 21
2025
-
[58]
Seed 2.0 official launch, 2026
ByteDance Seed Team. Seed 2.0 official launch, 2026. URL https://seed.bytedance. com/en/blog/seed-2-0-official-launch. Official launch page
2026
-
[59]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y . Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kefan Chen, Liang Chen, Ruijue Chen, Xinhao Chen, Yanru Chen, Yanxu Chen, Yicun Chen, Yimin Chen, Yingjiang Chen, Yuankun Chen, Yujie Chen, Yutian Chen, Zhirong Chen, Ziwei Che...
work page internal anchor Pith review arXiv 2026
-
[60]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
2024
-
[61]
Memoryllm: towards self- updatable large language models
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, Jingbo Shang, and Julian McAuley. Memoryllm: towards self- updatable large language models. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024. 22
2024
-
[62]
Long- memeval: Benchmarking chat assistants on long-term interactive memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview. net/forum?id=pZiyCaVuti
2025
-
[63]
Grok 4 model card, 2025
xAI. Grok 4 model card, 2025. URL https://data.x.ai/ 2025-08-20-grok-4-model-card.pdf. Model card
2025
-
[64]
Travelplanner: A benchmark for real-world planning with language agents
Jian Xie, Kai Zhang, Jiangjie Chen, Tinghui Zhu, Renze Lou, Yuandong Tian, Yanghua Xiao, and Yu Su. Travelplanner: A benchmark for real-world planning with language agents. In Forty-first International Conference on Machine Learning, 2024
2024
-
[65]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InThe Thirty-eight Conference on N...
2024
-
[66]
Beyond goldfish memory: Long-term open- domain conversation
Jing Xu, Arthur Szlam, and Jason Weston. Beyond goldfish memory: Long-term open- domain conversation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 5180–5197, Dublin, Ireland, May
-
[67]
Beyond Goldfish Memory: Long-Term Open-Domain Conversation , url =
Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.356. URL https://aclanthology.org/2022.acl-long.356/
-
[68]
Search-in-the- chain: Interactively enhancing large language models with search for knowledge-intensive tasks
Shicheng Xu, Liang Pang, Huawei Shen, Xueqi Cheng, and Tat-Seng Chua. Search-in-the- chain: Interactively enhancing large language models with search for knowledge-intensive tasks. InThe Web Conference 2024, 2024. URL https://openreview.net/forum? id=tr0TcqitMH
2024
-
[69]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[70]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2369–2380, Brussels, Belgium, October-November 2018. Association for C...
-
[71]
Webshop: Towards scalable real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik R Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.),Advances in Neural Information Processing Systems, 2022. URLhttps://openreview.net/forum?id=R9KnuFlvnU
2022
-
[72]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024.URL https://arxiv. org/abs/2406.12045, 2024
work page internal anchor Pith review arXiv 2024
-
[73]
Tooleyes: Fine-grained evaluation for tool learning capabilities of large language models in real-world scenarios
Junjie Ye, Guanyu Li, Songyang Gao, Caishuang Huang, Yilong Wu, Sixian Li, Xiaoran Fan, Shihan Dou, Tao Ji, Qi Zhang, Tao Gui, and Xuanjing Huang. Tooleyes: Fine-grained evaluation for tool learning capabilities of large language models in real-world scenarios. InProceedings of the 31st International Conference on Computational Linguistics, COLING 2025, A...
2025
-
[74]
Helmet: How to evaluate long-context language models effectively and thoroughly, 2025
Howard Yen, Tianyu Gao, Minmin Hou, Ke Ding, Daniel Fleischer, Peter Izsak, Moshe Wasserblat, and Danqi Chen. Helmet: How to evaluate long-context language models effectively and thoroughly.arXiv preprint arXiv:2410.02694, 2024. 23
-
[75]
HELMET: How to evaluate long-context models effectively and thoroughly
Howard Yen, Tianyu Gao, Minmin Hou, Ke Ding, Daniel Fleischer, Peter Izsak, Moshe Wasserblat, and Danqi Chen. HELMET: How to evaluate long-context models effectively and thoroughly. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=293V3bJbmE
2025
-
[76]
MMAU: A holistic benchmark of agent capabilities across diverse domains
Guoli Yin, Haoping Bai, Shuang Ma, Feng Nan, Yanchao Sun, Zhaoyang Xu, Shen Ma, Jiarui Lu, Xiang Kong, Aonan Zhang, Dian Ang Yap, Yizhe Zhang, Karsten Ahnert, Vik Kamath, Mathias Berglund, Dominic Walsh, Tobias Gindele, Juergen Wiest, Zhengfeng Lai, Xiaoming Simon Wang, Jiulong Shan, Meng Cao, Ruoming Pang, and Zirui Wang. MMAU: A holistic benchmark of ag...
-
[77]
Shuangshuang Ying, Zheyu Wang, Yunjian Peng, Jin Chen, Yuhao Wu, Hongbin Lin, Dingyu He, Siyi Liu, Gengchen Yu, YinZhu Piao, et al. Retrieval-infused reasoning sandbox: A benchmark for decoupling retrieval and reasoning capabilities.arXiv preprint arXiv:2601.21937, 2026
-
[78]
Longcite: Enabling llms to generate fine-grained citations in long-context qa
Jiajie Zhang, Yushi Bai, Xin Lv, Wanjun Gu, Danqing Liu, Minhao Zou, Shulin Cao, Lei Hou, Yuxiao Dong, Ling Feng, et al. Longcite: Enabling llms to generate fine-grained citations in long-context qa. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 5098–5122, 2025
2025
- [79]
-
[80]
MemoryBank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: enhancing large language models with long-term memory. InProceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Inte...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.