Recognition: unknown
Automated Detection of Mutual Gaze and Joint Attention in Dual-Camera Settings via Dual-Stream Transformers
Pith reviewed 2026-05-07 08:30 UTC · model grok-4.3
The pith
A dual-stream Transformer using frozen GazeLLE backbones detects mutual gaze and joint attention in dual-camera videos more accurately than baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The dual-stream Transformer architecture, by combining frozen GazeLLE backbones with a custom token fusion mechanism, successfully models the spatial and semantic relationships across camera views to detect mutual gaze and joint attention in dyadic interactions.
What carries the argument
Dual-stream Transformer with custom token fusion mechanism that maps spatial and semantic relationships between two camera views of interacting dyads.
If this is right
- Automated coding replaces manual annotation for large collections of caregiver-infant videos.
- The open-sourced pre-trained weights can be fine-tuned to new laboratory camera configurations.
- The approach demonstrates that pre-trained gaze-aware models can be adapted for multi-view social interaction analysis.
- Performance gains over convolutional and LLM baselines indicate the fusion step adds value for relational gaze tasks.
Where Pith is reading between the lines
- Lower analysis costs could support larger-scale longitudinal studies of early social development.
- The same dual-stream fusion pattern may transfer to other multi-view settings such as human-robot or child-peer interactions.
- Further gains are likely if the fusion layer is fine-tuned on domain-specific labeled examples while keeping the backbones frozen.
Load-bearing premise
Frozen GazeLLE backbones plus the custom token fusion are sufficient to capture complex cross-camera relational dynamics without task-specific fine-tuning of the visual priors.
What would settle it
Running the released model on a new dual-camera dataset with markedly different camera angles, lighting, or participant ages and checking whether accuracy falls below the convolutional baseline.
Figures







read the original abstract
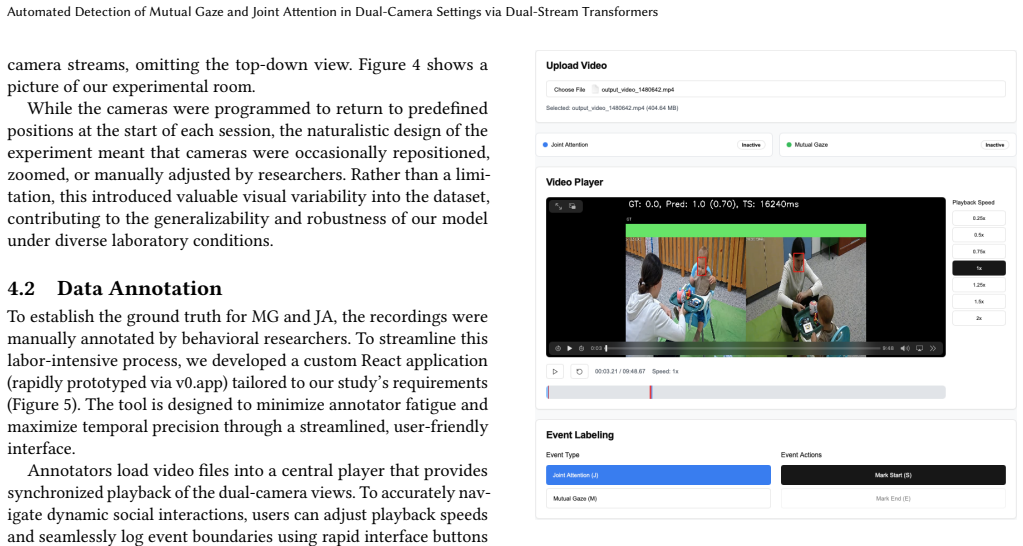
Analyzing mutual gaze (MG) and joint attention (JA) is critical in developmental psychology but traditionally relies on labor-intensive manual coding. Automating this process in multi-camera laboratory settings is computationally challenging due to complex cross-camera relational dynamics. In this paper, we propose a highly efficient dual-stream Transformer architecture for detecting MG and JA from synchronized dual-camera recordings. Our approach leverages frozen gaze-aware backbones (GazeLLE) to extract rich visual priors, combined with a custom token fusion mechanism to map the spatial and semantic relationships between interacting dyads. Evaluated on an ecologically valid dataset of caregiver-infant interactions, our model exhibits good performance, significantly outperforming both a convolutional baseline and a state-of-the-art multimodal Large Language Model (LLM). By open-sourcing our model and pre-trained weights, we provide behavioral scientists with a scalable tool that can be fine-tuned to diverse laboratory environments, effectively bridging the gap between computational modeling and applied interaction research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a dual-stream Transformer architecture for automated detection of mutual gaze (MG) and joint attention (JA) from synchronized dual-camera recordings of caregiver-infant interactions. It extracts visual priors using frozen GazeLLE backbones and introduces a custom token fusion mechanism to model cross-camera spatial and semantic relationships. The authors claim the model achieves good performance on an ecologically valid dataset, significantly outperforming both a convolutional baseline and a state-of-the-art multimodal LLM, and they open-source the model and pre-trained weights to support fine-tuning in diverse lab settings.
Significance. If the performance claims hold under rigorous evaluation, the work could meaningfully advance automated behavioral analysis in developmental psychology by replacing labor-intensive manual coding of MG and JA with a scalable, efficient computational tool. The open-sourcing of code and weights is a clear strength that enables adoption and adaptation by non-experts. Leveraging pre-trained gaze-aware backbones reduces training costs, but the significance is tempered by the need to confirm that the frozen monocular priors plus fusion suffice for dual-view relational modeling.
major comments (2)
- [Abstract and §5] Abstract and §5 (Results and Evaluation): The central claim of 'good performance' and 'significantly outperforming' both a convolutional baseline and a multimodal LLM is presented without any numeric metrics (e.g., accuracy, F1, AUC), error bars, dataset size, number of dyads, train/test splits, cross-validation details, or statistical tests. This absence prevents verification of the performance claim and makes the soundness of the experimental validation difficult to assess.
- [§3.1] §3.1 (Backbone and Architecture): The decision to freeze the GazeLLE backbones (trained on monocular gaze) without task-specific fine-tuning or an ablation isolating the custom token fusion mechanism is load-bearing for the claim that the model captures complex cross-camera relational dynamics. No evidence is provided that the fusion compensates for the lack of dual-view adaptation; if the priors do not transfer, the reported outperformance would rest on an unverified assumption rather than demonstrated sufficiency.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., F1-score or accuracy) to support the performance statements.
- [Figure 1] Figure 1 or 2 (architecture diagram): Clarify the exact token fusion operation (e.g., cross-attention equations or concatenation details) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment point by point below, indicating the revisions made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Results and Evaluation): The central claim of 'good performance' and 'significantly outperforming' both a convolutional baseline and a multimodal LLM is presented without any numeric metrics (e.g., accuracy, F1, AUC), error bars, dataset size, number of dyads, train/test splits, cross-validation details, or statistical tests. This absence prevents verification of the performance claim and makes the soundness of the experimental validation difficult to assess.
Authors: We agree that the abstract and the narrative summary in §5 would be improved by explicitly stating the key numeric results. Although the full metrics appear in the tables and figures of §5, we have revised the abstract to include the primary performance figures (F1 and AUC for MG and JA detection) and expanded the opening of §5 to summarize dataset size (number of dyads and recordings), train/test splits, cross-validation details, error bars, and statistical test results against the baselines. These changes make the performance claims directly verifiable from the text. revision: yes
-
Referee: [§3.1] §3.1 (Backbone and Architecture): The decision to freeze the GazeLLE backbones (trained on monocular gaze) without task-specific fine-tuning or an ablation isolating the custom token fusion mechanism is load-bearing for the claim that the model captures complex cross-camera relational dynamics. No evidence is provided that the fusion compensates for the lack of dual-view adaptation; if the priors do not transfer, the reported outperformance would rest on an unverified assumption rather than demonstrated sufficiency.
Authors: We appreciate the referee's emphasis on this design choice. The backbones were frozen to retain robust monocular gaze priors while avoiding overfitting on the limited dual-camera data and to keep training efficient. The custom token fusion is specifically designed to capture cross-camera spatial and semantic relations. In the revised manuscript we have added an ablation study (new subsection in §3.1 and corresponding results in §5) that compares the full model to (i) a version with unfrozen backbones and (ii) a version without the fusion module. The ablation confirms that the fusion mechanism compensates for the absence of dual-view fine-tuning, enabling the frozen priors to support the reported performance gains with lower computational cost. revision: yes
Circularity Check
No circularity: architecture and evaluation are empirically grounded
full rationale
The paper presents a dual-stream Transformer that extracts features from frozen external GazeLLE backbones, applies a custom token fusion layer, and trains end-to-end on labeled dual-camera interaction data. Performance is measured by direct comparison to a convolutional baseline and a multimodal LLM on a held-out dataset. No equation defines a quantity in terms of itself, no fitted parameter is relabeled as a prediction, and no load-bearing premise reduces to a self-citation chain. The derivation relies on standard supervised learning and externally pre-trained components whose validity is independent of the present results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Roger Bakeman and Lauren B. Adamson. 1984. Coordinating Attention to People and Objects in Mother–Infant and Peer–Infant Interaction.Child Development 55, 4 (1984), 1278–1289. doi:10.2307/1129997
-
[2]
Lukas Biewald. 2020. Experiment Tracking with Weights and Biases. https: //www.wandb.com/ Software available from wandb.com
2020
-
[3]
George Butterworth and Nicholas Jarrett. 1991. What Minds Have in Common Is Space: Spatial Mechanisms Serving Joint Visual Attention in Infancy.British Journal of Developmental Psychology9, 1 (1991), 55–72. doi:10.1111/j.2044-835X. 1991.tb00862.x
-
[4]
Jeremy I. M. Carpendale, Ulrich Müller, Benjamin Wallbridge, Tanya Broesch, Thea Cameron-Faulkner, and Kayla Ten Eycke. 2021. The Development of Giving in Forms of Object Exchange: Exploring the Roots of Communication and Morality in Early Interaction Around Objects.Human Development65, 3 (2021), 166–179. doi:10.1159/000517221
-
[5]
Johnson, Daniel Forster, and Gedeon O
Kaya de Barbaro, Catharine M. Johnson, Daniel Forster, and Gedeon O. Deák
-
[6]
Sensorimotor Decoupling Contributes to Triadic Attention: A Longitudinal Investigation of Mother–Infant–Object Interactions.Child Development87, 2 (2016), 494–512. doi:10.1111/cdev.12464
- [7]
-
[8]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInterna- tional Conference on Learning Representations. https:...
2021
-
[9]
Lifeng Fan, Yixin Chen, Ping Wei, Wenguan Wang, and Song-Chun Zhu. 2018. Inferring Shared Attention in Social Scene Videos. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6460–6468. doi:10.1109/CVPR.2018. 00676
-
[10]
Teresa Farroni, Gergely Csibra, Francesca Simion, and Mark H. Johnson. 2002. Eye Contact Detection in Humans from Birth.Proceedings of the National Academy of Sciences99, 14 (2002), 9602–9605. doi:10.1073/pnas.152159999
-
[11]
Jaddi, T
T. Jaddi, T. Kishimoto, and Kim A. Bard. 2026. Cross-Cultural and Cross-Species Comparisons of Mutual Gaze and Infant Emotion: Challenging WEIRD and BIZARRE Assumptions.Journal of Comparative Psychology(2026). doi:10.1037/ com0000444 Advance online publication
2026
-
[12]
Hiromi Kobayashi and Shiro Kohshima. 1997. Unique Morphology of the Human Eye.Nature387, 6635 (1997), 767–768. doi:10.1038/42842
-
[13]
Peitong Li, Hui Lu, Ronald Poppe, and Albert Salah. 2023. Automated Detection of Joint Attention and Mutual Gaze in Free Play Parent-Child Interactions. 374–382. doi:10.1145/3610661.3616234
-
[14]
Paul C. MacLean, Katherine N. Rynes, Cecilia Aragón, Arvind Caprihan, J. P. Phillips, and Julia R. Lowe. 2014. Mother–Infant Mutual Eye Gaze Supports Emotion Regulation in Infancy During the Still-Face Paradigm.Infant Behavior and Development37, 4 (2014), 512–522. doi:10.1016/j.infbeh.2014.06.008
-
[15]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Lab...
work page internal anchor Pith review arXiv 2024
-
[16]
Fiona Ryan, Ajay Bati, Sangmin Lee, Daniel Bolya, Judy Hoffman, and James M. Rehg. 2025. Gaze-LLE: Gaze Target Estimation via Large-Scale Learned En- coders. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2025
-
[17]
Gaze-LLE: Streamlined Gaze Architecture with a Lightweight Decoder
Fiona K. Ryan. 2024. Gaze-LLE: Official code for "Gaze-LLE: Streamlined Gaze Architecture with a Lightweight Decoder". https://github.com/fkryan/gazelle. MIT License
2024
-
[18]
Michael Scaife and Jerome S. Bruner. 1975. The Capacity for Joint Visual Attention in the Infant.Nature253, 5489 (1975), 265–266. doi:10.1038/253265a0
-
[19]
Sefik Serengil and Alper Ozpinar. 2024. A Benchmark of Facial Recognition Pipelines and Co-Usability Performances of Modules.Journal of Information Technologies17, 2 (2024), 95–107. doi:10.17671/gazibtd.1399077
-
[20]
Sefik Ilkin Serengil and Alper Ozpinar. 2020. LightFace: A Hybrid Deep Face Recognition Framework. In2020 Innovations in Intelligent Systems and Applica- tions Conference (ASYU). IEEE, 23–27. doi:10.1109/ASYU50717.2020.9259802
- [21]
-
[22]
Gaze Following with Interaction Features in Vision Transformers
Yuehao Song, Xinggang Wang, Jingfeng Yao, Wenyu Liu, Jinglin Zhang, and Xiangmin Xu. 2024. ViTGaze: Official code for "Gaze Following with Interaction Features in Vision Transformers". https://github.com/hustvl/ViTGaze. MIT License
2024
- [23]
-
[24]
Ollama Team. 2024. Ollama: Get up and running with large language models locally. https://ollama.com/ Accessed: 2026-04-22
2024
-
[25]
2008.Origins of Human Communication
Michael Tomasello. 2008.Origins of Human Communication. MIT Press
2008
-
[26]
Michael Tomasello, Brian Hare, Hermann Lehmann, and Josep Call. 2007. Re- liance on Head versus Eyes in the Gaze Following of Great Apes and Human Infants: The Cooperative Eye Hypothesis.Journal of Human Evolution52, 3 (2007), 314–320. doi:10.1016/j.jhevol.2006.10.001
-
[27]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guil- laume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971 [cs.CL] https://arxiv.org/abs/2302.13971
work page internal anchor Pith review arXiv 2023
-
[28]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. 2024. A survey on multimodal large language models.National Science Review11, 12 (Nov. 2024). doi:10.1093/nsr/nwae403
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.