Recognition: unknown
On the Effectiveness of Modular Testing in EvoSuite
Pith reviewed 2026-05-07 10:23 UTC · model grok-4.3
The pith
Relaxing rules on non-target setup calls in EvoSuite's modular testing mode improves target method branch coverage by 15.15 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
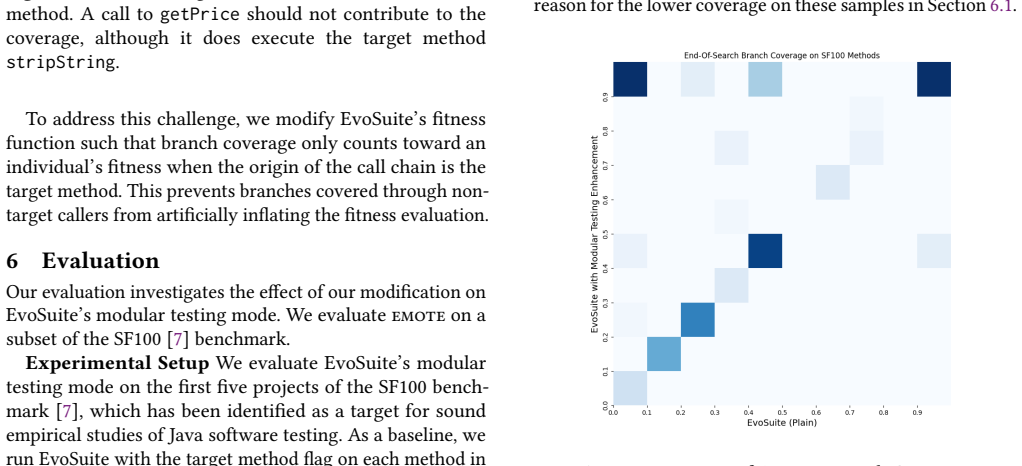
Emote relaxes EvoSuite's strict prohibition on non-target method calls during prefix construction and modifies the fitness function so that branch coverage is measured only along the call chain that begins at the target method. When run on classes from the SF100 benchmark, this produces tests that reach 15.15 percent more branches in the target methods than the unmodified modular mode.
What carries the argument
Emote's combination of relaxed prefix generation (allowing non-target setup methods) and a call-chain-focused fitness function that isolates coverage credit to paths originating from the target method.
If this is right
- Generated test suites will contain more complete state initialization for the target method without requiring full program execution.
- Modular testing can now produce higher-coverage unit tests for individual methods in object-oriented Java code.
- The same relaxation plus fitness change can be applied to other search-based test generators that currently enforce strict target isolation.
Where Pith is reading between the lines
- The technique may reduce the manual effort needed to create effective fuzz drivers for complex classes.
- Coverage gains might translate to higher mutation scores if the tests exercise more realistic execution paths.
- Other tools could adopt similar call-chain filtering to improve isolation without losing necessary setup.
Load-bearing premise
That focusing the fitness function on the target call chain will guide the search toward useful setup sequences rather than letting irrelevant calls dominate or dilute the coverage signal.
What would settle it
A direct head-to-head comparison on the same SF100 subset measuring not only branch coverage but also the number of distinct setup sequences discovered and whether the generated tests actually reach more branches inside the target methods when executed.
Figures




read the original abstract
This paper explores the effectiveness of modular randomized testing for object oriented programs in Java. Modular testing involves testing individual components of a program in isolation. Often times, for effective test generation, a series of non-target setup calls must be included to obtain high coverage of the target component. In this work, we evaluate and improve modular testing with the EvoSuite test generator. We find that due to strict restrictions that disallow calls to non-target setup methods, EvoSuite's modular testing mode is ineffective and often results in low branch coverage. We propose \textsc{emote} (Effective Modular Testing with EvoSuite): an enhancement to EvoSuite that relaxes this restriction, allowing non-target methods to be included in the test prefixes. This modification draws inspiration from developer-written fuzz drivers, which often invoke setup methods to properly initialize the state before testing the target method. To ensure meaningful test generation, we modify EvoSuite's fitness function to focus branch coverage contributions on the call chain originating from the target method. \textsc{emote} is evaluated on a subset of the SF100 benchmark, showing a 15.15\% improvement in coverage of the target methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that EvoSuite's modular testing mode is ineffective for Java OO programs because of strict restrictions disallowing non-target setup method calls, resulting in low branch coverage. It proposes Emote, which relaxes these restrictions to allow setup calls in test prefixes (inspired by developer fuzz drivers) and modifies the fitness function to focus coverage contributions on the call chain from the target method. On a subset of the SF100 benchmark, Emote achieves a 15.15% improvement in target-method coverage.
Significance. If the empirical result holds under rigorous evaluation, the work provides a practical enhancement to automated test generation tools for object-oriented code. By enabling necessary state-initialization calls while reweighting fitness toward the target call chain, it could improve the realism and effectiveness of modular testing without requiring full program context, with potential impact on tools like EvoSuite and related search-based testing research.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): The central claim of a 15.15% coverage improvement is reported without any description of the SF100 subset size or selection criteria, number of repetitions per subject, statistical significance tests, variance across runs, or explicit baseline comparisons (e.g., unmodified EvoSuite modular mode vs. Emote). These details are load-bearing for assessing whether the observed gain is reliable or reproducible.
- [§3 and §4] §3 (Emote design) and §4: The fitness-function modification is intended to focus on the target call chain and avoid excessive irrelevant setup calls, but the evaluation reports only aggregate target coverage. No supporting metrics are provided (e.g., average test prefix length, fraction of calls that contribute to target coverage, or state-reachability checks), leaving open the possibility that gains arise from longer tests rather than improved modular initialization.
minor comments (1)
- [Abstract] Abstract: The phrase 'a subset of the SF100 benchmark' should be expanded with at least the number of classes or methods evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for major revision. We address each major comment below and indicate the changes made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): The central claim of a 15.15% coverage improvement is reported without any description of the SF100 subset size or selection criteria, number of repetitions per subject, statistical significance tests, variance across runs, or explicit baseline comparisons (e.g., unmodified EvoSuite modular mode vs. Emote). These details are load-bearing for assessing whether the observed gain is reliable or reproducible.
Authors: We agree that these experimental details are essential for assessing reliability and reproducibility. In the revised manuscript, we have expanded both the abstract and §4 to include the SF100 subset size and selection criteria, the number of repetitions per subject, results of statistical significance tests with p-values, variance (standard deviation) across runs, and explicit comparisons against the unmodified EvoSuite modular mode as the baseline. revision: yes
-
Referee: [§3 and §4] §3 (Emote design) and §4: The fitness-function modification is intended to focus on the target call chain and avoid excessive irrelevant setup calls, but the evaluation reports only aggregate target coverage. No supporting metrics are provided (e.g., average test prefix length, fraction of calls that contribute to target coverage, or state-reachability checks), leaving open the possibility that gains arise from longer tests rather than improved modular initialization.
Authors: We acknowledge that supporting metrics would help confirm that gains derive from the fitness-function focus on the target call chain rather than test length alone. In the revised §4 we now report average test prefix lengths for Emote versus the baseline and the fraction of prefix calls that contribute to target coverage under the modified fitness function. We did not add state-reachability checks, as they would require substantial new instrumentation beyond the scope of this work; the existing coverage results combined with the fitness modification and prefix-length data provide sufficient evidence against the alternative explanation. revision: partial
Circularity Check
No circularity: purely empirical tool evaluation
full rationale
The paper describes an empirical modification to EvoSuite (relaxing non-target call restrictions and reweighting the fitness function toward the target call chain) followed by a direct measurement of branch coverage on a subset of the SF100 benchmark. The reported 15.15% improvement is an observed outcome of running the altered generator, not a quantity derived from equations that reduce to the paper's own inputs, fitted parameters, or self-citations. No mathematical derivation chain, uniqueness theorems, or ansatzes appear; the central claim is therefore self-contained as an experimental result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Branch coverage focused on the target method's call chain is a valid measure of meaningful test effectiveness
- domain assumption The SF100 subset provides a fair basis for comparing modular testing modes
Reference graph
Works this paper leans on
-
[1]
Aldeida Aleti, I. Moser, and Lars Grunske. 2017. Analysing the fitness landscape of search-based software testing problems.Automated Soft- ware Engg.24, 3 (Sept. 2017), 603–621. doi:10.1007/s10515-016-0197-7
-
[2]
Domagoj Babic, Stefan Bucur, Yaohui Chen, Franjo Ivancic, Tim King, Markus Kusano, Caroline Lemieux, László Szekeres, and Wei Wang
-
[3]
InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering
FUDGE: Fuzz Driver Generation at Scale. InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering
2019
-
[4]
Elizabeth Dinella, Shuvendu K. Lahiri, and Mayur Naik. 2024. Infer- ring Natural Preconditions via Program Transformation. InCompanion Proceedings of the 32nd ACM International Conference on the Founda- tions of Software Engineering(Porto de Galinhas, Brazil)(FSE 2024). Association for Computing Machinery, New York, NY, USA, 657–658. doi:10.1145/3663529.3663865
-
[5]
Elizabeth Dinella, Gabriel Ryan, Todd Mytkowicz, and Shuvendu K. Lahiri. 2022. TOGA: a neural method for test oracle generation. In Proceedings of the 44th International Conference on Software Engineering (ICSE ’22). ACM. doi:10.1145/3510003.3510141
-
[6]
Gordon Fraser and Andrea Arcuri. 2011. Evolutionary Generation of Whole Test Suites. InInternational Conference On Quality Software (QSIC). IEEE Computer Society, Los Alamitos, CA, USA, 31–40. doi:10. 1109/QSIC.2011.19
2011
-
[7]
Gordon Fraser and Andrea Arcuri. 2011. EvoSuite: automatic test suite generation for object-oriented software. InProceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering(Szeged, Hungary)(ESEC/FSE ’11). Association for Computing Machinery, New York, NY, USA, 416–419. doi:10.1145/2025113.2025179
-
[8]
Gordon Fraser and Andrea Arcuri. 2012. Sound empirical evidence in software testing. InProceedings of the 34th International Conference on Software Engineering(Zurich, Switzerland)(ICSE ’12). IEEE Press, 178–188
2012
-
[9]
Gordon Fraser and Andrea Arcuri. 2013. Handling test length bloat.Software Testing, Verification and Reliability23, 7 (2013), 553–
2013
-
[10]
arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/stvr.1495 doi:10.1002/stvr.1495
-
[11]
Gordon Fraser and Andrea Arcuri. 2013. Whole Test Suite Generation. IEEE Transactions on Software Engineering39, 2 (2013), 276–291. doi:10. 1109/TSE.2012.14
2013
-
[12]
John H Holland. 1992. Genetic algorithms.Scientific american267, 1 (1992), 66–73
1992
- [13]
-
[14]
Sourabh Katoch, Sumit Singh Chauhan, and Vijay Kumar. 2021. A review on genetic algorithm: past, present, and future.Multimedia tools and applications80 (2021), 8091–8126
2021
-
[15]
Caroline Lemieux, Jeevana Priya Inala, Shuvendu K. Lahiri, and Sid- dhartha Sen. 2023. CodaMosa: Escaping Coverage Plateaus in Test Gen- eration with Pre-trained Large Language Models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). 919–931. doi:10.1109/ICSE48619.2023.00085
-
[16]
LLVM. n.d.. LibFuzzer Documentation.https://llvm.org/docs/LibFuzzer. html. Accessed: 2025-03-02
2025
-
[17]
Lahiri, Michael D
Carlos Pacheco, Shuvendu K. Lahiri, Michael D. Ernst, and Thomas Ball. 2007. Feedback-directed random test generation. InICSE 2007, Proceedings of the 29th International Conference on Software Engineering. Minneapolis, MN, USA, 75–84
2007
-
[18]
Rohan Padhye, Caroline Lemieux, Koushik Sen, Mike Papadakis, and Yves Le Traon. 2019. Semantic fuzzing with zest. InProceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis(Beijing, China)(ISSTA 2019). Association for Computing Machinery, New York, NY, USA, 329–340. doi:10.1145/3293882.3330576
-
[20]
Reformulating Branch Coverage as a Many-Objective Opti- mization Problem.2015 IEEE 8th International Conference on Soft- ware Testing, Verification and Validation, ICST 2015 - Proceedings. doi:10.1109/ICST.2015.7102604
-
[21]
Annibale Panichella, Fitsum Meshesha Kifetew, and Paolo Tonella
-
[22]
Automated Test Case Generation as a Many-Objective Optimisa- tion Problem with Dynamic Selection of the Targets.IEEE Transactions on Software Engineering44, 2 (2018), 122–158. doi:10.1109/TSE.2017. 2663435
-
[23]
Weifeng Sun, Hongyan Li, Meng Yan, Yan Lei, and Hongyu Zhang
-
[24]
Revisiting and Improving Retrieval-Augmented Deep Assertion Generation. InProceedings of the 38th IEEE/ACM International Confer- ence on Automated Software Engineering(Echternach, Luxembourg) (ASE ’23). IEEE Press, 1123–1135. doi:10.1109/ASE56229.2023.00090
-
[25]
Sebastian Vogl, Sebastian Schweikl, and Gordon Fraser. 2021. Encoding the certainty of boolean variables to improve the guidance for search- based test generation. InProceedings of the Genetic and Evolutionary Computation Conference(Lille, France)(GECCO ’21). Association for Computing Machinery, New York, NY, USA, 1088–1096. doi:10.1145/ 3449639.3459339
-
[26]
Hao Yu, Yiling Lou, Ke Sun, Dezhi Ran, Tao Xie, Dan Hao, Ying Li, Ge Li, and Qianxiang Wang. 2022. Automated assertion generation via information retrieval and its integration with deep learning. In Proceedings of the 44th International Conference on Software Engineer- ing(Pittsburgh, Pennsylvania)(ICSE ’22). Association for Computing Machinery, New York,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.