Recognition: unknown
Exploring the Limits of Pruning: Task-Specific Neurons, Model Collapse, and Recovery in Task-Specific Large Language Models
Pith reviewed 2026-05-07 09:59 UTC · model grok-4.3
The pith
Task-specific neurons concentrate critical information in specialized language models, as removing about 10% of them causes total performance collapse on the target task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
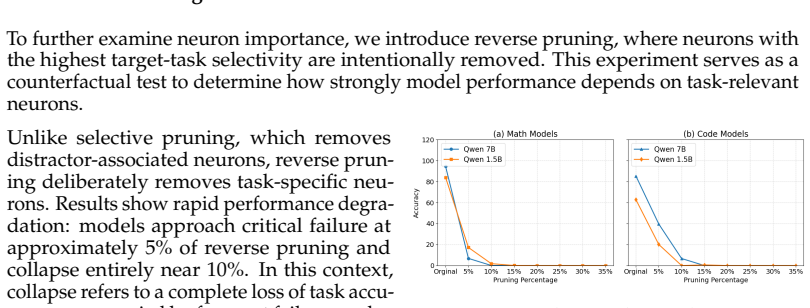
In language models specialized for mathematical reasoning and code generation, an activation-based selectivity metric identifies task-specific neurons such that removing roughly 10% of the most highly task-specific ones produces complete performance collapse on the target task, whereas selective removal of less critical neurons up to 30-35% leaves substantial accuracy intact; performance remains stable up to a 15-20% pruning threshold before sharp degradation, and fine-tuning recovers accuracy across pruning levels.
What carries the argument
An activation-based selectivity metric that ranks neurons according to their contribution to the target task, enabling selective pruning of low-contribution neurons while preserving task performance.
If this is right
- Critical task information concentrates in a small portion of the network rather than distributing evenly.
- Models tolerate selective pruning up to 15-20% before sharp increases in accuracy loss and generation failures.
- Fine-tuning after pruning substantially restores performance, especially for more aggressive pruning levels.
- Pruning reduces parameter count and VRAM usage while increasing inference throughput.
Where Pith is reading between the lines
- The concentration of task information could support targeted interventions such as neuron-level editing for model customization.
- Similar specialization patterns may emerge in models fine-tuned on other domains beyond math and code.
- The robustness threshold suggests practical guidelines for balancing compression and capability in deployment.
Load-bearing premise
The activation-based selectivity metric accurately identifies neurons that affect only the target task without harming general capabilities.
What would settle it
Apply the reverse pruning procedure to the identified task-specific neurons and measure whether performance on unrelated tasks remains unchanged.
Figures







read the original abstract
Neuron pruning is widely used to reduce the computational cost and parameter footprint of large language models, yet it remains unclear whether neurons in task-specific models contribute uniformly to task performance. In this work, we provide empirical evidence for the existence and importance of task-specific neurons through a systematic pruning study on language models specialized for mathematical reasoning and code generation. We introduce an activation-based selectivity metric to identify neurons with low contribution to the target task and prune them while preserving target-task accuracy, and compare selective pruning with random pruning. Selective pruning consistently outperforms random pruning, indicating that activation-based selectivity provides a systematic advantage over random pruning. Reverse pruning experiments further show that removing a small subset of highly task-specific neurons (~10%) causes complete performance collapse, suggesting that there exist task specific neurons and critical task information is concentrated in a small portion of the network. In contrast, selective pruning of less critical neurons (~30% - ~35%) reduces accuracy but still preserves significant performance. We also observed consistent reductions in parameters and runtime VRAM usage, along with improved inference throughput as pruning increases. Experiments on both 1.5B and 7B models reveal a robustness threshold around 15-20% pruning, beyond which accuracy loss and generation failures increase sharply. Fine-tuning substantially recovers performance across pruning levels, particularly for aggressively pruned models. These findings provide empirical evidence of neuron specialization in task-specific language models and offer insights into pruning robustness, model redundancy, and post-pruning recoverability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that task-specific LLMs for math reasoning and code generation contain identifiable task-specific neurons. Using an activation-based selectivity metric computed on target-task data, selective pruning of low-contribution neurons outperforms random pruning while preserving accuracy; reverse pruning of the top ~10% most selective neurons causes complete target-task collapse, while pruning ~30-35% of less-selective neurons retains substantial performance. Experiments across 1.5B and 7B models identify a robustness threshold at 15-20% pruning, with fine-tuning recovering accuracy even after aggressive pruning, alongside reductions in parameters, VRAM, and gains in inference speed.
Significance. If the central claims hold after addressing controls, the work supplies concrete empirical evidence for neuron specialization and information concentration in task-specific models, plus actionable pruning guidelines and recovery strategies. Credit is due for the consistent patterns observed across two model scales and the clear demonstration that post-pruning fine-tuning restores performance.
major comments (3)
- [Abstract / Experimental Setup] Abstract and pruning methodology: the activation-based selectivity metric is defined solely from target-task activations. No evaluations of the resulting pruned models on unrelated tasks (general language modeling, non-math QA, or GLUE-style benchmarks) are reported. This directly affects the load-bearing claim that the ~10% reverse-pruned neurons are task-specific rather than generally important; without such controls the collapse could be explained by overall neuron salience.
- [Results] Results section: the manuscript asserts consistent patterns and a 15-20% robustness threshold but supplies no dataset sizes, exact pruning percentages tested, number of independent runs, or statistical significance tests. These omissions prevent verification of the claimed superiority of selective over random pruning and the sharpness of the threshold.
- [Reverse Pruning Experiments] Reverse-pruning experiments: the statement that removing ~10% highly task-specific neurons produces 'complete performance collapse' requires a precise definition of collapse (e.g., exact accuracy drop on the target metric) and confirmation that the effect is selective to the target task; the current evidence does not rule out a general-importance interpretation.
minor comments (2)
- [Abstract] Abstract: quantitative magnitudes for the reported reductions in parameters, VRAM, and inference throughput are not provided.
- [Methods] Notation: the precise formula for the activation-based selectivity metric should be stated explicitly (including any normalization or thresholding steps) rather than described only qualitatively.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important ways to strengthen the evidence for task-specific neurons. We address each major comment below and commit to revisions that incorporate additional controls, details, and clarifications while preserving the core empirical findings across model scales.
read point-by-point responses
-
Referee: [Abstract / Experimental Setup] Abstract and pruning methodology: the activation-based selectivity metric is defined solely from target-task activations. No evaluations of the resulting pruned models on unrelated tasks (general language modeling, non-math QA, or GLUE-style benchmarks) are reported. This directly affects the load-bearing claim that the ~10% reverse-pruned neurons are task-specific rather than generally important; without such controls the collapse could be explained by overall neuron salience.
Authors: We agree this is a substantive limitation. The selectivity metric and pruning comparisons (selective vs. random) provide indirect support for task-specificity via differential performance preservation, but cross-task evaluations are needed to rule out general salience. In the revised manuscript we will add evaluations of pruned and reverse-pruned models on general language modeling perplexity and at least one non-target benchmark (e.g., a GLUE subset or non-math QA), reporting whether reverse pruning causes disproportionate collapse only on the target task. This directly addresses the concern. revision: yes
-
Referee: [Results] Results section: the manuscript asserts consistent patterns and a 15-20% robustness threshold but supplies no dataset sizes, exact pruning percentages tested, number of independent runs, or statistical significance tests. These omissions prevent verification of the claimed superiority of selective over random pruning and the sharpness of the threshold.
Authors: We acknowledge the omission of these reproducibility details. The revised manuscript will explicitly state the dataset sizes (e.g., number of examples for math reasoning and code generation tasks), list all tested pruning ratios (including the exact values around the 15-20% threshold), report results as means and standard deviations over at least three independent runs, and include statistical significance tests (e.g., paired t-tests) comparing selective vs. random pruning at each ratio. These additions will allow direct verification of the reported patterns. revision: yes
-
Referee: [Reverse Pruning Experiments] Reverse-pruning experiments: the statement that removing ~10% highly task-specific neurons produces 'complete performance collapse' requires a precise definition of collapse (e.g., exact accuracy drop on the target metric) and confirmation that the effect is selective to the target task; the current evidence does not rule out a general-importance interpretation.
Authors: We will add a precise operational definition of collapse (accuracy falling to near-zero or random-guessing levels on the target metric, with specific numerical thresholds reported for each task and model size). On selectivity, the existing selective-vs-random and forward-vs-reverse comparisons already show asymmetric effects, but we agree they are insufficient alone. As noted in our response to the first comment, the revision will include cross-task evaluations to test whether the collapse is target-task specific. We view this as strengthening rather than overturning the central claim. revision: partial
Circularity Check
No circularity: purely empirical pruning study with no derivations or self-referential reductions
full rationale
The paper reports experimental results from activation-based pruning on task-specific LLMs for math and code generation. It defines a selectivity metric from target-task activations, compares selective vs. random pruning, and observes performance collapse under reverse pruning of ~10% high-selectivity neurons. No equations, fitted parameters, predictions derived from inputs, or self-citations are used to support the central claims; all findings are direct observations from model runs. The work is self-contained against external benchmarks and contains no load-bearing steps that reduce to their own definitions or fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https: //arxiv.org/abs/2509.20721. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea ...
-
[2]
URLhttps://arxiv.org/abs/2107.03374. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review arXiv
-
[3]
Analyzing redun- dancy in pretrained transformer models
Fahim Dalvi, Hassan Sajjad, Nadir Durrani, and Yonatan Belinkov. Analyzing redun- dancy in pretrained transformer models. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.),Proceedings of the 2020 Conference on Empirical Methods in Nat- ural Language Processing (EMNLP), pp. 4908–4926, Online, November
2020
-
[4]
Analyzing Redundancy in Pretrained Transformer Models
Associa- tion for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.398. URL https://aclanthology.org/2020.emnlp-main.398/. Elias Frantar and Dan Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot. InInternational Conference on Machine Learning (ICML), pp. 10323– 10337. PMLR,
-
[5]
URLhttps://arxiv.org/abs/2106.09685. Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-coder technical report,
work page internal anchor Pith review arXiv
-
[6]
Qwen2.5-Coder Technical Report
URLhttps://arxiv.org/abs/2409.12186. Haoyu Li, Xuhong Li, Yiming Dong, and Kun Liu. From macro to micro: Probing dataset diversity in language model fine-tuning,
work page internal anchor Pith review arXiv
-
[7]
Xinyin Ma, Gongfan Fang, and Xinchao Wang
URL https://arxiv.org/abs/2505.24768. Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36,
-
[8]
Accessed: 2026-02-19
URL https://docs.nvidia.com/deeplearning/performance/ dl-performance-matrix-multiplication/index.html. Accessed: 2026-02-19. Telmo Pires, Ant´onio Vilarinho Lopes, Yannick Assogba, and Hendra Setiawan. One wide feedforward is all you need. In Philipp Koehn, Barry Haddow, Tom Kocmi, and Christof Monz (eds.),Proceedings of the Eighth Conference on Machine T...
2026
-
[9]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Association for Computational Linguistics. doi: 10.18653/v1/ 2023.wmt-1.98. URLhttps://aclanthology.org/2023.wmt-1.98/. Nicholas Pochinkov and Nandi Schoots. Dissecting language models: Machine unlearning via selective pruning.arXiv preprint arXiv:2403.01267,
-
[10]
SQuAD: 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. In Jian Su, Kevin Duh, and Xavier Carreras (eds.),Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 2383–2392, Austin, Texas, November
2016
-
[11]
SQuAD : 100,000+ questions for machine comprehension of text
Association for Computational Linguistics. doi: 10.18653/v1/D16-1264. URLhttps://aclanthology.org/D16-1264. Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.),Proceed- ings of the 2019 Conference on Empirical Methods in Natural Language Processing...
-
[12]
Association for Computational Linguistics. doi: 10.18653/v1/D19-1410. URLhttps://aclanthology.org/D19-1410/. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URL https://arxiv.org/abs/ 2402.03300. Yuzhong Song, Zeyu Zheng, Zhiying Pan, Chenhao Xue, Qipeng Wang, Jianwei Yin, Rui Wang, Haotian Zhang, Wenju Chen, Mingsong Chen, et al. Powerinfer: Fast large language model inference with macroscopic sparsity. InProceedings of the 29th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming ...
work page internal anchor Pith review arXiv
- [14]
-
[15]
arXiv preprint arXiv:2406.09265 , year=
URL https://huggingface.co/datasets/suriya7/everyday-Conversational-cleaned. Weixuan Wang et al. Sharing matters: Analysing neurons across languages and tasks in LLMs.arXiv preprint arXiv:2406.09265,
-
[16]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review arXiv
-
[17]
URLhttps://aclanthology.org/2022.coling-1.437/
International Committee on Computational Linguistics. URLhttps://aclanthology.org/2022.coling-1.437/. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert,
2022
-
[18]
BERTScore: Evaluating Text Generation with BERT
URLhttps://arxiv.org/abs/1904.09675. 11 Yiming Zhang et al. Loraprune: Pruning meets low-rank parameter-efficient fine-tuning. In The Twelfth International Conference on Learning Representations (ICLR),
work page internal anchor Pith review arXiv 1904
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.