Recognition: unknown
Global Sampling-Based Trajectory Optimization for Contact-Rich Manipulation via KernelSOS
Pith reviewed 2026-05-07 09:00 UTC · model grok-4.3
The pith
Kernel sum-of-squares optimization locates promising regions in contact-rich robot trajectory space before local refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Global-MPPI uses kernel sum-of-squares optimization to identify globally promising regions of the solution space, applies graduated non-convexity through log-sum-exp smoothing to handle non-smooth contact dynamics, and then employs the model-predictive path integral method for local refinement, producing higher-quality trajectories than sampling baselines on long-horizon contact-rich tasks.
What carries the argument
Kernel sum-of-squares optimization, which identifies globally promising regions of the high-dimensional non-smooth trajectory space.
If this is right
- The method converges faster than existing sampling baselines on high-dimensional contact-rich tasks.
- It reaches lower final trajectory costs than the baselines.
- The graduated smoothing schedule enables reliable handling of hybrid non-smooth dynamics.
- Global exploration reduces trapping in poor local minima for long-horizon problems.
Where Pith is reading between the lines
- The same global-plus-local structure could transfer to other robotics problems that feature discontinuous dynamics, such as legged locomotion or assembly.
- Explicit global polynomial search may lessen dependence on careful initial guesses that currently limit many manipulation planners.
- Replacing log-sum-exp with alternative smoothers might further improve scalability to even longer horizons or higher state dimensions.
Load-bearing premise
Kernel sum-of-squares optimization can reliably identify globally promising regions in the high-dimensional non-smooth trajectory space without prohibitive cost or missing critical modes.
What would settle it
On the PushT or dexterous in-hand manipulation benchmarks, Global-MPPI shows no consistent advantage in convergence speed or final cost over baseline sampling methods across repeated trials.
Figures

read the original abstract
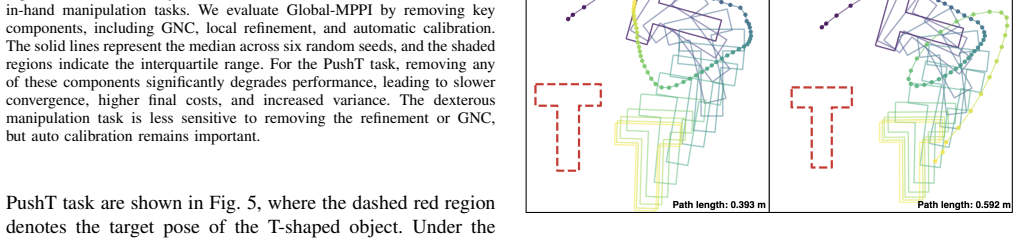
Contact-rich manipulation is challenging due to its high dimensionality, the requirement for long time horizons, and the presence of hybrid contact dynamics. Sampling-based methods have become a popular approach for this class of problems, but without explicit mechanisms for global exploration, they are susceptible to converging to poor local minima. In this paper, we introduce Global-MPPI, a unified trajectory optimization framework that integrates global exploration and local refinement. At the global level, we leverage kernel sum-of-squares optimization to identify globally promising regions of the solution space. To enable reliable performance for the non-smooth landscapes inherent to contact-rich manipulation, we introduce a graduated non-convexity strategy based on log-sum-exp smoothing, which transitions the optimization landscape from a smoothed surrogate to the original non-smooth objective. Finally, we employ the model-predictive path integral method to locally refine the solution. We evaluate Global-MPPI on high-dimensional, long-horizon contact-rich tasks, including the PushT task and dexterous in-hand manipulation. Experimental results demonstrate that our approach robustly uncovers high-quality solutions, achieving faster convergence and lower final costs compared to existing baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Global-MPPI, a trajectory optimization framework for contact-rich manipulation that uses kernel sum-of-squares (SOS) optimization on a graduated log-sum-exp smoothed surrogate to perform global exploration, followed by model-predictive path integral (MPPI) local refinement on the original non-smooth objective. It is evaluated on high-dimensional tasks including PushT and dexterous in-hand manipulation, with claims of faster convergence and lower final costs relative to baselines.
Significance. If the kernel-SOS step on the smoothed landscape reliably identifies regions containing high-quality modes of the true contact-rich objective, the framework would offer a concrete mechanism for global exploration in sampling-based methods for hybrid systems, addressing a known weakness of pure MPPI. The graduated non-convexity approach is a practical strength for bridging smoothed and discontinuous landscapes, and the empirical evaluation on long-horizon tasks provides initial evidence of utility.
major comments (2)
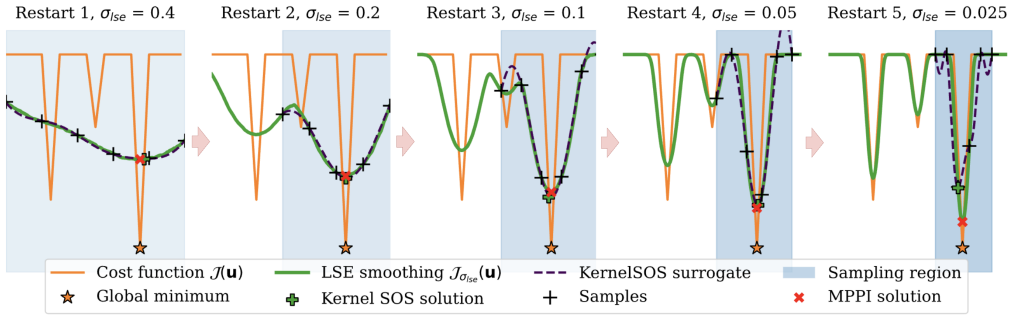
- [§3.3] §3.3 (graduated non-convexity strategy): the central claim that kernel SOS on the log-sum-exp surrogate locates globally promising regions for the original non-smooth problem lacks a supporting argument or ablation showing that the smoothing does not shift or merge basins away from high-quality modes of the true contact cost; without this, the reported faster convergence cannot be attributed to reliable global exploration.
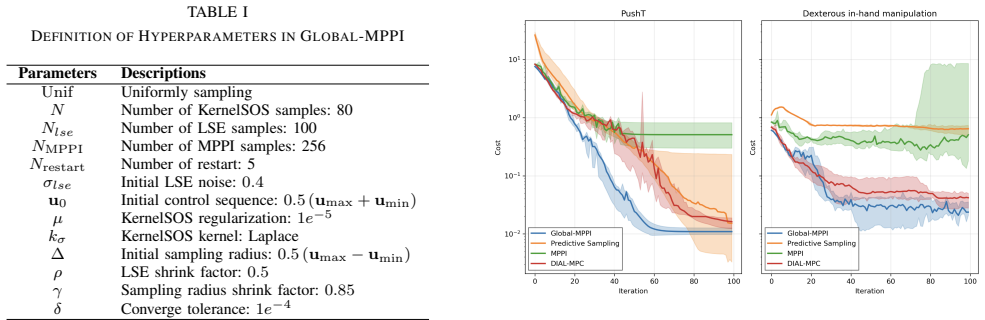
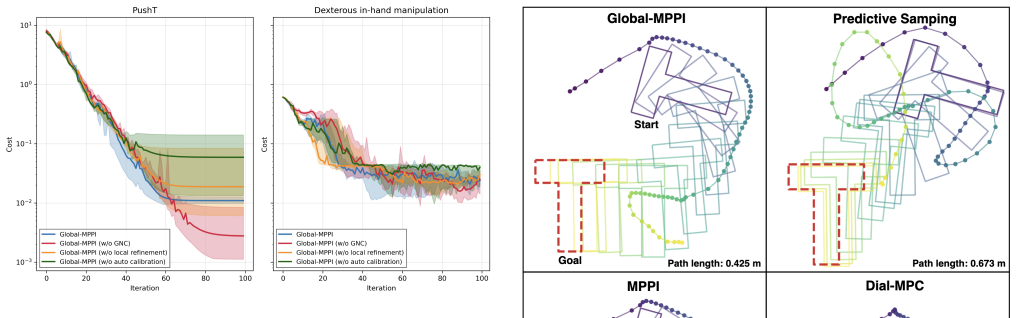
- [§4] §4 (experimental results): the performance gains over baselines are presented without error bars, statistical tests, or ablations isolating the contribution of the kernel-SOS global step versus the smoothing schedule or MPPI alone; this weakens the robustness claim for contact-rich tasks.
minor comments (2)
- [§3] Notation for the kernel and the log-sum-exp parameter schedule should be defined once and used consistently across sections to avoid reader confusion.
- [§4] Figure captions for the trajectory visualizations could more explicitly indicate which curves correspond to the smoothed surrogate versus the final refined trajectories.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. The comments raise valid points regarding the justification of our graduated non-convexity approach and the statistical robustness of the experiments. We address each below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§3.3] §3.3 (graduated non-convexity strategy): the central claim that kernel SOS on the log-sum-exp surrogate locates globally promising regions for the original non-smooth problem lacks a supporting argument or ablation showing that the smoothing does not shift or merge basins away from high-quality modes of the true contact cost; without this, the reported faster convergence cannot be attributed to reliable global exploration.
Authors: We concur that additional support for the claim would be beneficial. The log-sum-exp smoothing is chosen because it provides a differentiable approximation to the non-smooth contact costs, with the temperature parameter controlling the degree of smoothing. By starting with a high temperature (highly smoothed landscape) and gradually decreasing it, the kernel SOS optimization is performed on successively less smoothed versions, allowing it to track promising regions as the landscape approaches the original. Although a theoretical guarantee on exact basin preservation is difficult to establish for general hybrid dynamics, our experiments demonstrate that this procedure yields superior final costs compared to baselines. In the revised manuscript, we will expand §3.3 with a more detailed explanation of this rationale and include an ablation that compares the full method against versions with fixed smoothing or no global step. revision: partial
-
Referee: [§4] §4 (experimental results): the performance gains over baselines are presented without error bars, statistical tests, or ablations isolating the contribution of the kernel-SOS global step versus the smoothing schedule or MPPI alone; this weakens the robustness claim for contact-rich tasks.
Authors: We agree that the current presentation of results can be strengthened with better statistical analysis. We will update the experimental section to include error bars (mean ± standard deviation) computed over at least 10 independent trials for each task. We will also report p-values from appropriate statistical tests to confirm the significance of the observed improvements. Furthermore, we will add ablation studies that remove the kernel-SOS component (using only MPPI with graduated smoothing) and that use different smoothing schedules to quantify the individual contributions. These additions will be placed in §4 and the appendix. revision: yes
Circularity Check
No significant circularity; framework composes independent existing components
full rationale
The paper's derivation chain introduces Global-MPPI by combining kernel sum-of-squares optimization for global search, a graduated log-sum-exp smoothing schedule to handle non-smooth contact dynamics, and MPPI for local refinement. None of these steps reduce to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations that presuppose the target result. The log-sum-exp smoothing is presented as a standard graduated non-convexity technique applied to an external surrogate, and experimental claims rest on direct comparisons to baselines rather than tautological constructions. The central premise remains externally falsifiable via the reported task performance metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A review on reinforce- ment learning for contact-rich robotic manipulation tasks,
´I. Elguea-Aguinaco, A. Serrano-Mu ˜noz, D. Chrysostomou, I. Inziarte- Hidalgo, S. Bøgh, and N. Arana-Arexolaleiba, “A review on reinforce- ment learning for contact-rich robotic manipulation tasks,”Robotics and Computer-Integrated Manufacturing, vol. 81, p. 102517, 2023
2023
-
[2]
Full-order sampling-based mpc for torque-level locomotion control via diffusion-style annealing,
H. Xue, C. Pan, Z. Yi, G. Qu, and G. Shi, “Full-order sampling-based mpc for torque-level locomotion control via diffusion-style annealing,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 4974–4981
2025
-
[3]
Combining sampling- and gradient-based planning for contact-rich manipulation,
F. Rozzi, L. Roveda, and K. Haninger, “Combining sampling- and gradient-based planning for contact-rich manipulation,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 9901–9907
2024
-
[4]
Real-time whole-body control of legged robots with model- predictive path integral control,
J. Alvarez-Padilla, J. Z. Zhang, S. Kwok, J. M. Dolan, and Z. Manch- ester, “Real-time whole-body control of legged robots with model- predictive path integral control,” in2025 IEEE International Confer- ence on Robotics and Automation (ICRA). IEEE, 2025, pp. 14 721– 14 727
2025
-
[5]
Robust model predictive path integral control: Analysis and performance guarantees,
M. S. Gandhi, B. Vlahov, J. Gibson, G. Williams, and E. A. Theodorou, “Robust model predictive path integral control: Analysis and performance guarantees,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 1423–1430, 2021
2021
-
[6]
Sample-efficient cross-entropy method for real-time planning,
C. Pinneri, S. Sawant, S. Blaes, J. Achterhold, J. Stueckler, M. Rolinek, and G. Martius, “Sample-efficient cross-entropy method for real-time planning,” inConference on Robot Learning. PMLR, 2021, pp. 1049– 1065
2021
-
[7]
2016, arXiv e-prints, arXiv:1604.00772, doi: 10.48550/arXiv.1604.00772
N. Hansen, “The CMA Evolution Strategy: A Tutorial,” arXiv:1604.00772, 2023
-
[8]
An introduction to zero-order optimization techniques for robotics,
A. Jordana, J. Zhang, J. Amigo, and L. Righetti, “An introduction to zero-order optimization techniques for robotics,”arXiv preprint arXiv:2506.22087, 2025
-
[9]
Generalized Maximum Entropy Differential Dynamic Programming,
Y . Aoyama and E. A. Theodorou, “Generalized Maximum Entropy Differential Dynamic Programming,” inIEEE Conference on Decision and Control (CDC), 2024, pp. 8825–8831
2024
-
[10]
Reinforcement Learn- ing with Deep Energy-Based Policies,
T. Haarnoja, H. Tang, P. Abbeel, and S. Levine, “Reinforcement Learn- ing with Deep Energy-Based Policies,” inInternational Conference on Machine Learning, 2017
2017
-
[11]
Finding global minima via kernel approximations,
A. Rudi, U. Marteau-Ferey, and F. Bach, “Finding global minima via kernel approximations,”Mathematical Programming 209 (1), 2020
2020
-
[12]
Infinite-Dimensional Sums-of-Squares for Optimal Control,
E. Berthier, J. Carpentier, A. Rudi, and F. Bach, “Infinite-Dimensional Sums-of-Squares for Optimal Control,” inIEEE Conference on Deci- sion and Control (CDC), 2022, pp. 577–582
2022
-
[13]
Sampling-based global optimal control and estimation via semidefi- nite programming,
A. Groudiev, F. Schramm, ´E. Berthier, J. Carpentier, and F. D ¨umbgen, “Sampling-based global optimal control and estimation via semidefi- nite programming,”American Control Conference, 2025
2025
-
[14]
Learning risk-aware quadrupedal locomotion using distributional reinforcement learning,
L. Schneider, J. Frey, T. Miki, and M. Hutter, “Learning risk-aware quadrupedal locomotion using distributional reinforcement learning,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 11 451–11 458
2024
-
[15]
A survey on deep reinforcement learning algorithms for robotic manipulation,
D. Han, B. Mulyana, V . Stankovic, and S. Cheng, “A survey on deep reinforcement learning algorithms for robotic manipulation,”Sensors, vol. 23, no. 7, p. 3762, 2023
2023
-
[16]
Dexterous manipulation for multi-fingered robotic hands with reinforcement learning: A review,
C. Yu and P. Wang, “Dexterous manipulation for multi-fingered robotic hands with reinforcement learning: A review,”Frontiers in Neurorobotics, vol. 16, p. 861825, 2022
2022
-
[17]
Do dif- ferentiable simulators give better policy gradients?
H. J. Suh, M. Simchowitz, K. Zhang, and R. Tedrake, “Do dif- ferentiable simulators give better policy gradients?” inInternational Conference on Machine Learning. PMLR, 2022, pp. 20 668–20 696
2022
-
[18]
Bundled gradients through contact via randomized smoothing,
H. J. T. Suh, T. Pang, and R. Tedrake, “Bundled gradients through contact via randomized smoothing,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4000–4007, 2022
2022
-
[19]
Global planning for contact-rich manipulation via local smoothing of quasi-dynamic contact models,
T. Pang, H. T. Suh, L. Yang, and R. Tedrake, “Global planning for contact-rich manipulation via local smoothing of quasi-dynamic contact models,”IEEE Transactions on robotics, vol. 39, no. 6, pp. 4691–4711, 2023
2023
-
[20]
Leveraging randomized smoothing for optimal control of nonsmooth dynamical systems,
Q. Le Lidec, F. Schramm, L. Montaut, C. Schmid, I. Laptev, and J. Carpentier, “Leveraging randomized smoothing for optimal control of nonsmooth dynamical systems,”Nonlinear Analysis: Hybrid Sys- tems, vol. 52, 2024
2024
-
[21]
A Direct Method for Trajectory Optimization of Rigid Bodies Through Contact,
M. Posa, C. Cantu, and R. Tedrake, “A Direct Method for Trajectory Optimization of Rigid Bodies Through Contact,”International Journal of Robotics Research (IJRR), vol. 33, no. 1, pp. 69–81, Jan. 2014
2014
-
[22]
From Compliant to Rigid Contact Simulation: A Unified and Efficient Approach,
J. Carpentier, L. Montaut, and Q. L. Lidec, “From Compliant to Rigid Contact Simulation: A Unified and Efficient Approach,” inRobotics: Science and Systems, 2024
2024
-
[23]
Inverse dynamics trajectory optimization for contact-implicit model predictive control,
V . Kurtz, A. Castro, A. ¨O. ¨Onol, and H. Lin, “Inverse dynamics trajectory optimization for contact-implicit model predictive control,” The International Journal of Robotics Research, vol. 45, no. 1, pp. 23–40, 2026
2026
-
[24]
Simultaneous contact, gait, and motion planning for robust multilegged locomotion via mixed-integer convex optimization,
B. Aceituno-Cabezas, C. Mastalli, H. Dai, M. Focchi, A. Radulescu, D. G. Caldwell, J. Cappelletto, J. C. Grieco, G. Fern ´andez-L´opez, and C. Semini, “Simultaneous contact, gait, and motion planning for robust multilegged locomotion via mixed-integer convex optimization,”IEEE Robotics and Automation Letters, vol. 3, no. 3, pp. 2531–2538, 2018
2018
-
[25]
Towards tight convex relaxations for contact- rich manipulation,
B. P. Graesdal, S. Y . C. Chia, T. Marcucci, S. Morozov, A. Amice, P. A. Parrilo, and R. Tedrake, “Towards tight convex relaxations for contact- rich manipulation,”Robotics: Science and Systems (RSS), 2024
2024
-
[26]
Model predictive path integral control: From theory to parallel computation,
G. Williams, A. Aldrich, and E. A. Theodorou, “Model predictive path integral control: From theory to parallel computation,”Journal of Guidance, Control, and Dynamics, vol. 40, no. 2, pp. 344–357, 2017
2017
-
[27]
Bayesian optimiza- tion with safety constraints: safe and automatic parameter tuning in robotics,
F. Berkenkamp, A. Krause, and A. P. Schoellig, “Bayesian optimiza- tion with safety constraints: safe and automatic parameter tuning in robotics,”Machine learning, vol. 112, no. 10, pp. 3713–3747, 2023
2023
-
[28]
Taking the Human Out of the Loop: A Review of Bayesian Opti- mization,
B. Shahriari, K. Swersky, Z. Wang, R. P. Adams, and N. de Freitas, “Taking the Human Out of the Loop: A Review of Bayesian Opti- mization,”Proceedings of the IEEE, vol. 104, no. 1, pp. 148–175, Jan. 2016
2016
-
[29]
Efficient Global Optimization of Expensive Black-Box Functions,
D. R. Jones, M. Schonlau, and W. J. Welch, “Efficient Global Optimization of Expensive Black-Box Functions,”Journal of Global Optimization, vol. 13, no. 4, pp. 455–492, Dec. 1998
1998
-
[30]
Graduated non- convexity for robust spatial perception: From non-minimal solvers to global outlier rejection,
H. Yang, P. Antonante, V . Tzoumas, and L. Carlone, “Graduated non- convexity for robust spatial perception: From non-minimal solvers to global outlier rejection,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1127–1134, 2020
2020
-
[31]
Deterministic annealing for clustering, compression, classi- fication, regression, and related optimization problems,
K. Rose, “Deterministic annealing for clustering, compression, classi- fication, regression, and related optimization problems,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2210–2239, 2002
2002
-
[32]
K. P. Murphy,Machine learning: a probabilistic perspective. MIT press, 2012
2012
-
[33]
Hydrax: Sampling-based model predictive control on gpu with jax and mujoco mjx,
V . Kurtz, “Hydrax: Sampling-based model predictive control on gpu with jax and mujoco mjx,” 2024
2024
-
[34]
Mosek optimization toolbox for matlab,
M. ApS, “Mosek optimization toolbox for matlab,”User’s Guide and Reference Manual, Version, vol. 4, no. 1, p. 116, 2019
2019
-
[35]
Flicker,A Comparison of the Performance of SDP Solvers
C. Flicker,A Comparison of the Performance of SDP Solvers. New Mexico Institute of Mining and Technology, 2020
2020
-
[36]
Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning,
K. Shaw, A. Agarwal, and D. Pathak, “Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning,”Robotics: Science and Systems (RSS), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.