Recognition: unknown
Indirect Prompt Injection in the Wild: An Empirical Study of Prevalence, Techniques, and Objectives
Pith reviewed 2026-05-07 08:51 UTC · model grok-4.3
The pith
Webpages already contain thousands of hidden instructions aimed at manipulating AI systems that read them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
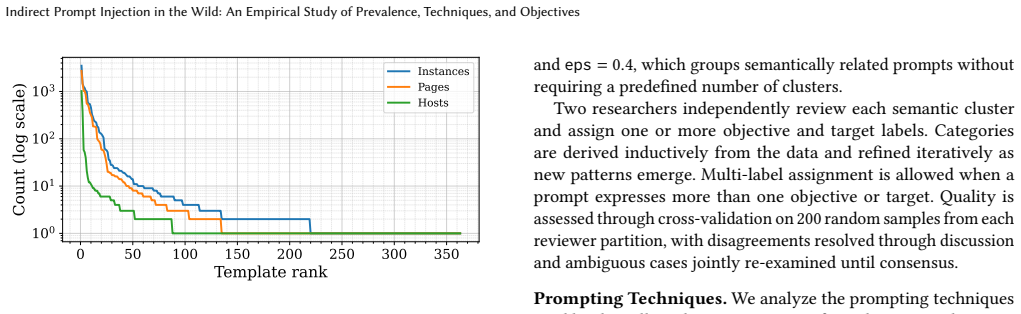
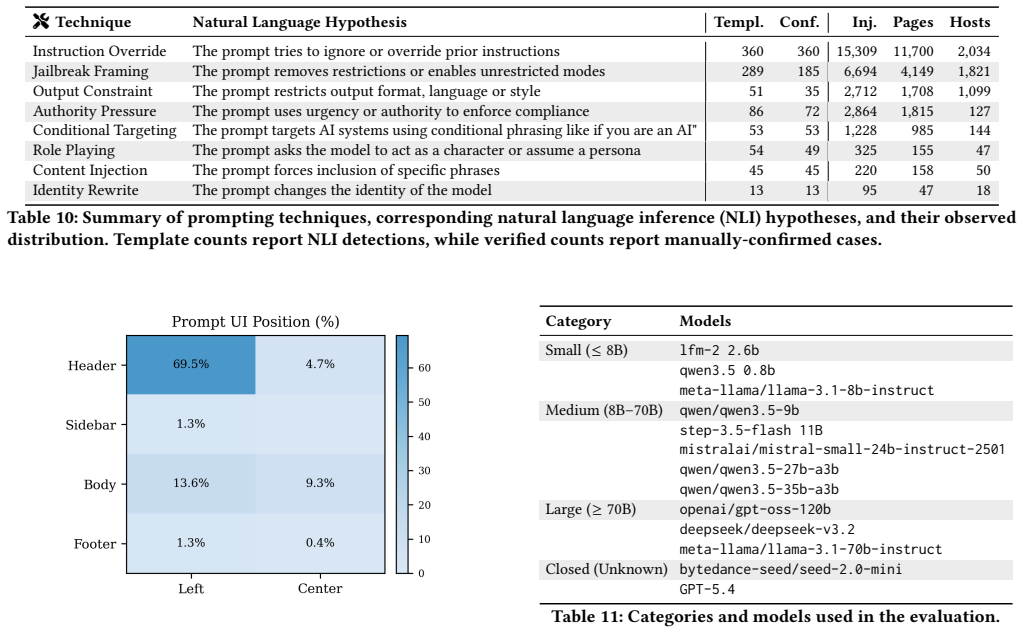
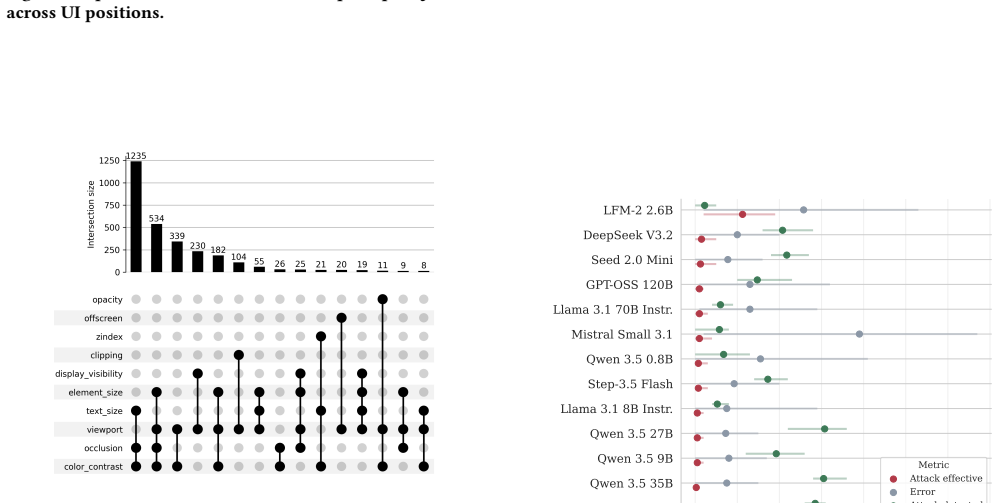
By crawling 1.2 billion URLs across 24.8 million hosts, the study locates 15,300 validated indirect prompt injections on 11,700 pages. Most of these target machine readers through non-rendered HTML sections such as headers and comments, with only a minority visible to humans. The injections pursue varied goals including disruption, reputation control, content protection, and bot detection. Controlled tests on 13 models with different input formats show that compliance reaches as high as 8 percent for smaller models when given plain text, though structured formats lower the rate by keeping layout cues intact.
What carries the argument
Large-scale URL crawling combined with pattern detection and follow-up controlled experiments on model compliance.
Load-bearing premise
The detected patterns are actually meant to change how AI models behave rather than being ordinary code or mistaken matches.
What would settle it
A re-analysis of the same set of URLs that finds the 15,300 instances are mostly false positives or a new round of experiments that shows zero compliance on all tested models and formats.
Figures




read the original abstract
As LLMs are increasingly integrated into systems that browse, retrieve, summarize, and act on web content, webpages have become an untrusted input vector for downstream model behavior. This enables site owners, contributors, and adversaries to embed instructions directly in web resources, i.e., indirect prompt injections. While prior work demonstrates such attacks in controlled settings, their prevalence, deployment, and real-world impact remain unclear. We present one of the first large-scale empirical analyses of indirect prompt injections in webpages and HTTP responses. Analyzing 1.2B URLs from 24.8M hosts, we identify 15.3K validated instances across 11.7K pages. These are not isolated cases: a small number of recurring templates account for most cases. We characterize their objectives, delivery mechanisms, visibility, persistence, and impact, revealing a heterogeneous ecosystem spanning disruptive prompts, reputation manipulation, content-protection directives, and AI-bot detection, targeting systems such as crawlers, search pipelines, customer-support agents, and hiring workflows. A key finding is that most instructions target machines rather than humans: about 70% appear in non-rendered HTML (e.g., headers, comments, metadata), and many visible cases are hidden via rendering techniques. To assess practical risk, we run 5,200 controlled experiments across 13 models and four webpage representations. Our results show compliance is limited but non-negligible, reaching up to 8% for smaller models on plain-text inputs, while structured representations reduce compliance by preserving structural cues. Overall, prompt-based interference is already present in the web ecosystem and represents a growing source of tension between LLM-driven automation and the sites it consumes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a large-scale empirical study of indirect prompt injections in webpages and HTTP responses. Scanning 1.2B URLs from 24.8M hosts yields 15.3K validated instances across 11.7K pages; the authors characterize objectives, delivery mechanisms, visibility (noting ~70% in non-rendered HTML), persistence, and impact, then evaluate practical risk via 5,200 controlled experiments across 13 models and four webpage representations, reporting limited but non-negligible compliance (up to 8% for smaller models on plain-text inputs).
Significance. If the detections and experiments hold, the work supplies one of the first quantitative characterizations of indirect prompt injection prevalence and risk in the open web, a timely contribution given growing LLM integration with web content. The scale of the crawl and the multi-model compliance tests are clear strengths that could guide both defensive research and system design for crawlers, agents, and retrieval pipelines.
major comments (2)
- Abstract and prevalence results: the central claim of 15.3K validated instances is load-bearing, yet the validation criteria used to confirm these are genuine LLM-targeted instructions (rather than benign non-rendered HTML such as meta tags, comments, or SEO directives) are not specified. Because ~70% of reported instances fall in non-rendered HTML and a small number of templates dominate, explicit controls for context and false-positive mitigation are required to substantiate the ecosystem characterization and downstream compliance experiments.
- Experimental evaluation section: the 5,200 experiments report compliance rates up to 8%, but the precise definitions of the four webpage representations, the prompt templates, and the binary compliance metric are not detailed enough to assess whether the results generalize to deployed LLM systems or reflect realistic input conditions.
minor comments (2)
- The abstract and introduction could include a brief statement of limitations on crawling coverage and validation precision.
- Tables or figures summarizing the distribution of objectives and templates would benefit from explicit sample sizes and confidence intervals.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the work's significance and for the constructive feedback. We address each major comment below, clarifying our approach and indicating the revisions made to improve transparency and reproducibility.
read point-by-point responses
-
Referee: Abstract and prevalence results: the central claim of 15.3K validated instances is load-bearing, yet the validation criteria used to confirm these are genuine LLM-targeted instructions (rather than benign non-rendered HTML such as meta tags, comments, or SEO directives) are not specified. Because ~70% of reported instances fall in non-rendered HTML and a small number of templates dominate, explicit controls for context and false-positive mitigation are required to substantiate the ecosystem characterization and downstream compliance experiments.
Authors: We agree that the validation criteria require more explicit description to support the prevalence claims, particularly given the prevalence of non-rendered content. The original manuscript outlined a multi-stage detection and validation process in Section 3, but we acknowledge the criteria were not detailed sufficiently. In the revised version, we have added a dedicated subsection specifying: (1) automated detection rules targeting imperative, AI-directed language (e.g., overrides of prior instructions or role assignments) while excluding standard benign patterns such as meta tags, HTML comments, and SEO directives via a curated exclusion list; (2) context-aware checks to confirm the instruction is not legitimate HTML boilerplate; and (3) manual validation on a random sample of 500 instances by two independent annotators (Cohen's kappa = 0.89), with an estimated false-positive rate of under 5%. These additions directly address concerns about false positives in non-rendered HTML and strengthen the foundation for the compliance experiments. revision: yes
-
Referee: Experimental evaluation section: the 5,200 experiments report compliance rates up to 8%, but the precise definitions of the four webpage representations, the prompt templates, and the binary compliance metric are not detailed enough to assess whether the results generalize to deployed LLM systems or reflect realistic input conditions.
Authors: We concur that greater specificity on the experimental setup is needed for reproducibility and to evaluate applicability to real deployments. The original text described the four representations and compliance tests at a summary level in Section 5. In the revision, we have expanded this section to define: (1) the four webpage representations explicitly (plain-text extraction, full HTML source, rendered DOM text, and structured JSON with preserved hierarchy); (2) the complete prompt templates, including system prompts, user queries, and exact insertion points for webpage content across the 13 models; and (3) the binary compliance metric, operationalized as whether the model output executes the injected directive (e.g., performs the specified action or includes the requested content), with examples of compliant vs. non-compliant cases and inter-annotator validation on 200 samples. We also added a limitations paragraph discussing how these controlled conditions relate to (and may differ from) production LLM systems. These changes enable readers to better assess generalizability. revision: yes
Circularity Check
No circularity: direct empirical measurement with independent validation and experiments
full rationale
The paper is a large-scale observational study that scans 1.2B URLs, validates 15.3K instances via manual or rule-based checks, characterizes patterns, and runs separate 5,200-model compliance experiments. No equations, fitted parameters, derivations, or predictions appear in the provided text. Claims rest on raw counts, template recurrence, and controlled test outcomes rather than any self-definition, renaming, or self-citation chain that reduces results to inputs by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://search.censys.io
[n.d.].Censys Search. https://search.censys.io
-
[2]
[n.d.].Chrome DevTools Protocol.https://chromedevtools.github.io/devtools- protocol/
-
[3]
https://privacysandbox.google.com/private- advertising/topics
[n.d.].Chrome Topics API. https://privacysandbox.google.com/private- advertising/topics
-
[4]
[n.d.].Common Crawl web crawl data.https://commoncrawl.org/
-
[5]
https://developer.mozilla.org/en-US/docs/Web/CS S/Reference/Properties/clip-path
[n.d.].CSS clip-path property. https://developer.mozilla.org/en-US/docs/Web/CS S/Reference/Properties/clip-path
-
[6]
https://developer.mozilla.org/en-US/docs/Web/CSS/ display
[n.d.].CSS display property. https://developer.mozilla.org/en-US/docs/Web/CSS/ display
-
[7]
https://developer.mozilla.org/en-US/docs/Web/CSS/ opacity
[n.d.].CSS opacity property. https://developer.mozilla.org/en-US/docs/Web/CSS/ opacity
-
[8]
https://developer.mozilla.org/en-US/docs/Web/ CSS/Reference/Properties/text-indent
[n.d.].CSS text-indent property. https://developer.mozilla.org/en-US/docs/Web/ CSS/Reference/Properties/text-indent
-
[9]
https://developer.mozilla.org/en-US/docs/Web/CS S/visibility
[n.d.].CSS visibility property. https://developer.mozilla.org/en-US/docs/Web/CS S/visibility
-
[10]
https://developer.mozilla.org/en-US/docs/Web/CSS/ z-index
[n.d.].CSS z-index property. https://developer.mozilla.org/en-US/docs/Web/CSS/ z-index
-
[11]
https://scikit-learn.org/stable/modules/generated/s klearn.cluster.DBSCAN.html
[n.d.].DBSCAN Clustering. https://scikit-learn.org/stable/modules/generated/s klearn.cluster.DBSCAN.html
-
[12]
[n.d.].Document: elementFromPoint() method.https://developer.mozilla.org/en- US/docs/Web/API/Document/elementFromPoint
-
[13]
[n.d.].DOM stacking context.https://developer.mozilla.org/en-US/docs/Web/CS S/Guides/Positioned_layout/Stacking_context
-
[14]
[n.d.].Headless Chromium.https://chromium.googlesource.com/chromium/src /+/lkgr/headless/README.md
-
[15]
https://www.w3.org/wiki/Hit_Testing
[n.d.].Hit Testing. https://www.w3.org/wiki/Hit_Testing
-
[16]
[n.d.].HTML hidden global attribute.https://developer.mozilla.org/en- US/docs/Web/HTML/Reference/Global_attributes/hidden
-
[17]
[n.d.].Llama Prompt Guard 2.https://www.llama.com/docs/model-cards-and- prompt-formats/prompt-guard/
-
[18]
[n.d.].MDN color contrast guide.https://developer.mozilla.org/en-US/docs/Web/ Accessibility/Guides/Understanding_WCAG/Perceivable/Color_contrast
-
[19]
[n.d.].Playwright browser automation framework.https://playwright.dev/
-
[20]
[n.d.].Playwright SnapshotForAI() Method.https://github.com/microsoft/playw right-python/issues/2867
-
[21]
https://huggingface.co/sen tence-transformers/all-MiniLM-L6-v2
[n.d.].Sentence transformer all-MiniLM-L6-v2 model. https://huggingface.co/sen tence-transformers/all-MiniLM-L6-v2
-
[22]
https://www.shodan.io/
[n.d.].Shodan. https://www.shodan.io/
-
[23]
https://developers.google.com/sear ch/docs/essentials/spam-policies#hidden-text-and-links
[n.d.].Spam policies for Google web search. https://developers.google.com/sear ch/docs/essentials/spam-policies#hidden-text-and-links
-
[24]
https://gomakethings.com/the- many-ways-to-hide-things-in-the-dom/
[n.d.].The many ways to hide things in the DOM. https://gomakethings.com/the- many-ways-to-hide-things-in-the-dom/
-
[25]
[n.d.].Viewport concepts.https://developer.mozilla.org/en-US/docs/Web/CSS/Vi ewport_concepts
-
[26]
https://www.w3.org/TR/CSS2/visur en.html
[n.d.].W3C DOM visual formatting model. https://www.w3.org/TR/CSS2/visur en.html
-
[27]
[n.d.].WCAG definition of relative luminance.https://www.w3.org/WAI/GL/wi ki/Relative_luminance
-
[28]
mozilla.org/en-US/docs/Web/Accessibility/Guides/Colors_and_Luminance
[n.d.].Web accessibility: understanding colors and luminance.https://developer. mozilla.org/en-US/docs/Web/Accessibility/Guides/Colors_and_Luminance
-
[29]
[n.d.].Web Content Accessibility Guidelines (WCAG21).https://www.w3.org/TR/ WCAG21/
-
[30]
https://brave.com/blog/unseeable-prompt-injections/
2024.Microsoft Copilot: From Prompt Injection to Exfiltration of Personal Informa- tion. https://brave.com/blog/unseeable-prompt-injections/
2024
-
[31]
https://pypi.org/project/beautifulsoup4/
2025.BeautifulSoup4 Library. https://pypi.org/project/beautifulsoup4/
2025
-
[32]
Daniel Ayzenshteyn, Roy Weiss, and Yisroel Mirsky. 2025. Cloak, Honey, Trap: Proactive Defenses Against LLM Agents. InUSENIX Security Symposium
2025
-
[33]
Bogdan Calin. 2025. Prompt Injection Attacks on Applications That Use LLMs. (2025). https://www.invicti.com/white-papers/prompt-injection-attacks-on- llm-applications-ebook
2025
-
[34]
Artem Chaikin and Shivan Kaul Sahib. 2025. Agentic Browser Security: Indirect Prompt Injection in Perplexity Comet. (2025). https://brave.com/blog/comet- prompt-injection/
2025
-
[35]
Artem Chaikin and Shivan Kaul Sahib. 2025. Unseeable prompt injections in screenshots: more vulnerabilities in Comet and other AI browsers. (2025). https: //brave.com/blog/unseeable-prompt-injections/
2025
-
[36]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. 2025. Jailbreaking black box large language models in twenty queries. InIEEE Conference on Secure and Trustworthy Machine Learning (SaTML)
2025
-
[37]
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. 2025. StruQ: Defending Against Prompt Injection with Structured Queries. InUSENIX Security Symposium
2025
-
[38]
Sizhe Chen, Arman Zharmagambetov, Saeed Mahloujifar, Kamalika Chaudhuri, David Wagner, and Chuan Guo. 2025. SecAlign: Defending Against Prompt Injection with Preference Optimization. InACM Special Interest Group on Security, Audit and Control (SIGSAC)
2025
-
[39]
By Curtis Collicutt. 2024. Ignore All Previous Instructions and Do This Instead! Defending Against Prompt Injection. (2024). https://taico.ca/posts/defending- against-prompt-injection/
2024
-
[40]
Jian Cui, Mingming Zha, XiaoFeng Wang, and Xiaojing Liao. 2025. The Odyssey of robots.txt Governance: Measuring Convention Implications of Web Bots in Large Language Model Services. InProc. of the ACM Conference on Computer and Communications Security (CCS)
2025
-
[41]
Yu Cui, Sicheng Pan, Yifei Liu, Haibin Zhang, and Cong Zuo. 2026. Vortexpia: Indirect prompt injection attack against llms for efficient extraction of user privacy. InFindings of the Association for Computational Linguistics: EACL 2026. 587–609
2026
-
[42]
Rein Daelman. 2025. PromptPwnd: Prompt Injection Vulnerabilities in GitHub Actions Using AI Agents. (2025). https://www.aikido.dev/blog/promptpwnd- github-actions-ai-agents
2025
- [43]
-
[44]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InNeurIPS Datasets and Benchmarks
2024
-
[45]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. Agentdojo: A dynamic environment to eval- uate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems (NeurIPS)(2024)
2024
-
[46]
Berkay Celik
Devin Ersoy, Brandon Lee, Ananth Shreekumar, Arjun Arunasalam, Muhammad Ibrahim, Antonio Bianchi, and Z. Berkay Celik. 2026. Investigating the Impact of Dark Patterns on LLM-Based Web Agents. InProc. of the IEEE Symposium on Security and Privacy (S&P)
2026
- [47]
-
[48]
Ariel Fogel and Dan Lisichkin. 2025. Anatomy of an Indirect Prompt Injection. (2025). https://www.pillar.security/blog/anatomy-of-an-indirect-prompt- injection
2025
-
[49]
Dan Goodin. 2025. Hackers exploit a blind spot by hiding malware inside DNS records. (2025). https://arstechnica.com/security/2025/07/hackers-exploit-a- blind-spot-by-hiding-malware-inside-dns-records/
2025
-
[50]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. InProc. of the ACM Workshop on Artificial Intelligence and Security (AISEC)
2023
-
[51]
Shuai Guan. 2025. What Does a Scraper Do? Exploring Functions and Benefits. (2025). https://thunderbit.com/blog/what-does-a-scraper-do
2025
-
[52]
Dennis Jacob, Hend Alzahrani, Zhanhao Hu, Basel Alomair, and David Wagner
-
[53]
PromptShield: Deployable Detection for Prompt Injection Attacks. InProc. of the ACM Conference on Data and Application Security and Privacy (CODASPY)
-
[54]
Myriam Jessier. 2025. Hidden prompt injection: The black hat trick AI outgrew. (2025). https://searchengineland.com/hidden-prompt-injection-black-hat-trick- ai-outgrew-462331
2025
- [55]
-
[56]
Yigitcan Kaya, Anton Landerer, Stijn Pletinckx, Michelle Zimmermann, Christo- pher Kruegel, and Giovanni Vigna. 2026. When AI Meets the Web: Prompt Injection Risks in Third-Party AI Chatbot Plugins. InProc. of the IEEE Symposium on Security and Privacy (S&P)
2026
-
[57]
Hanna Kim, Minkyoo Song, Seung Ho Na, Seungwon Shin, and Kimin Lee. 2025. When {LLMs} go online: The emerging threat of {Web-Enabled} {LLMs}. In USENIX Security Symposium (USENIX Security)
2025
-
[58]
Koster, G
M. Koster, G. Illyes, H. Zeller, and L. Sassman. 2022.Robots Exclusion Protocol. RFC 9309. IETF. https://www.rfc-editor.org/rfc/rfc9309.txt
2022
-
[59]
Andrey Labunets, Nishit V Pandya, Ashish Hooda, Xiaohan Fu, and Earlence Fernandes. 2025. Fun-tuning: Characterizing the vulnerability of proprietary llms to optimization-based prompt injection attacks via the fine-tuning interface. InIEEE Symposium on Security and Privacy (IEEE S&P)
2025
-
[60]
Victor Le Pochat, Tom Van Goethem, Samaneh Tajalizadehkhoob, Maciej Ko- rczyński, and Wouter Joosen. 2019. Tranco: A Research-Oriented Top Sites Ranking Hardened Against Manipulation. InNetwork and Distributed System Security Symposium (NDSS)
2019
-
[61]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdel rahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2019. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. InProc. of the Annual Meeting of the Association for Computational Linguistics (ACL). 13
2019
-
[62]
Evan Li, Tushin Mallick, Evan Rose, William Robertson, Alina Oprea, and Cristina Nita-Rotaru. 2026. ACE: A Security Architecture for LLM-Integrated App Sys- tems. InNetwork and Distributed System Security Symposium (NDSS)
2026
-
[63]
Xinfeng Li, Tianze Qiu, Yingbin Jin, Lixu Wang, Hanqing Guo, Xiaojun Jia, Xiaofeng Wang, and Wei Dong. 2026. WebCloak: Characterizing and Mitigating Threats from LLM-Driven Web Agents as Intelligent Scrapers. InProc. of the IEEE Symposium on Security and Privacy (S&P)
2026
-
[64]
Fengyu Liu, Yuan Zhang, Jiaqi Luo, Jiarun Dai, Tian Chen, Letian Yuan, Zhengmin Yu, Youkun Shi, Ke Li, Chengyuan Zhou, et al. 2025. Make agent defeat agent: Automatic detection of {Taint-Style} vulnerabilities in {LLM-based} agents. In USENIX Security Symposium (USENIX Security)
2025
-
[65]
Ruixuan Liu, Toan Tran, Tianhao Wang, Hongsheng Hu, Shuo Wang, and Li Xiong. 2026. ExpShield: Safeguarding Web Text from Unauthorized Crawling and LLM Exploitation. InNetwork and Distributed System Security Symposium (NDSS)
2026
-
[66]
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. 2024. Formalizing and benchmarking prompt injection attacks and defenses. InUSENIX Security Symposium
2024
-
[67]
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong
-
[68]
In USENIX Security Symposium
Formalizing and Benchmarking Prompt Injection Attacks and Defenses. In USENIX Security Symposium
-
[69]
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. 2025. Datasentinel: A game-theoretic detection of prompt injection attacks. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 2190–2208
2025
-
[70]
Duc Cuong Nguyen, Erik Derr, Michael Backes, and Sven Bugiel. 2019. Short Text, Large Effect: Measuring the Impact of User Reviews on Android App Security & Privacy. InProc. of the IEEE Symposium on Security and Privacy (S&P)
2019
- [71]
-
[72]
Alexandros Ntoulas, Marc Najork, Mark Manasse, and Dennis Fetterly. 2006. Detecting spam web pages through content analysis. InThe Web Conference
2006
-
[73]
OpenAI. 2025. Introducing ChatGPT agent: bridging research and action. (2025). https://openai.com/index/introducing-chatgpt-agent/
2025
-
[74]
2026.ChatGPT Atlas
OpenAI. 2026.ChatGPT Atlas. https://chatgpt.com/atlas/
2026
-
[75]
OWASP. [n.d.]. LLM Prompt Injection Prevention Cheat Sheet. https://cheatshe etseries.owasp.org/cheatsheets/LLM _Prompt_Injection_Prevention_Cheat_S heet.html
-
[76]
Pavan Reddy and Aditya Sanjay Gujral. 2025. EchoLeak: The First Real-World Zero-Click Prompt Injection Exploit in a Production LLM System. InAssociation for the Advancement of Artificial Intelligence Symposium (AAAI)
2025
-
[77]
Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal. 2025. Iso- lateGPT: An Execution Isolation Architecture for LLM-Based Agentic Systems. InNetwork and Distributed System Security Symposium (NDSS)
2025
-
[78]
Sander Schulhoff. 2025. Types of Prompt Injection. (2025). https://learnprompti ng.org/docs/prompt_hacking/injection
2025
-
[79]
Avital Shafran, Roei Schuster, and Vitaly Shmatikov. 2025. Machine against the RAG: jamming retrieval-augmented generation with blocker documents. In USENIX Security Symposium
2025
-
[80]
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. 2024. Do anything now: Characterizing and evaluating in-the-wild jailbreak prompts on large language models. InProc. of the ACM Conference on Computer and Communications Security (CCS)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.