Recognition: unknown
AttriBE: Quantifying Attribute Expressivity in Body Embeddings for Recognition and Identification
Pith reviewed 2026-05-07 09:46 UTC · model grok-4.3
The pith
Body re-identification embeddings encode body mass index more strongly than pitch, gender or yaw, with the pattern shifting across network layers and training stages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Transformer-based ReID embeddings encode a hierarchy of implicit attributes in which BMI consistently shows the highest expressivity, followed by pitch, gender and yaw. Expressivity evolves across layers and epochs, with pose attributes peaking in intermediate layers and BMI strengthening in deeper layers. In cross-spectral settings that bridge visible and infrared modalities, pitch becomes comparable to BMI while attribute trends increase monotonically with depth, indicating greater reliance on structural cues when modality gaps must be bridged.
What carries the argument
AttriBE, a framework that defines attribute expressivity as the mutual information between ReID features and a target attribute and estimates that quantity with a secondary neural network.
If this is right
- Final embeddings prioritize morphometric cues such as BMI over pose or demographic signals.
- Pose information is captured most strongly in intermediate layers before being partially suppressed in deeper ones.
- BMI encoding grows steadily with both depth and training time.
- Cross-spectral matching increases dependence on pitch and other structural attributes.
Where Pith is reading between the lines
- Model designers could monitor expressivity during training to decide when to add regularizers that suppress unwanted attributes.
- The same measurement approach could be applied to face or gait embeddings to compare which attributes dominate in those domains.
- In operational systems the persistent BMI signal may create unintended performance differences across body-size groups.
- Architectures that deliberately flatten certain attribute dimensions in later layers might improve cross-modal robustness.
Load-bearing premise
The secondary neural network supplies an accurate and unbiased estimate of mutual information between the ReID features and the chosen attributes.
What would settle it
Direct measurement of how accurately each attribute can be predicted from the frozen ReID embeddings fails to reproduce the same ranking and layer-wise trends reported by the secondary network.
Figures







read the original abstract
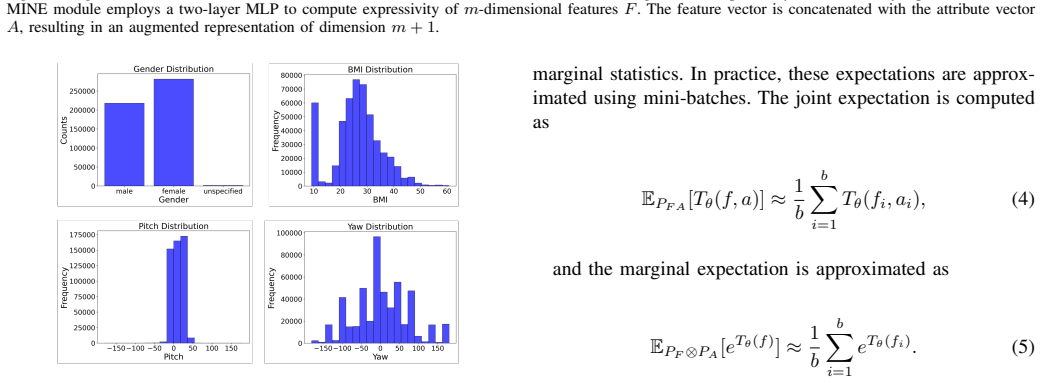
Person re-identification (ReID) systems that match individuals across images or video frames are essential in many real-world applications. However, existing methods are often influenced by attributes such as gender, pose, and body mass index (BMI), which vary in unconstrained settings and raise concerns related to fairness and generalization. To address this, we extend the notion of expressivity, defined as the mutual information between learned features and specific attributes, using a secondary neural network to quantify how strongly attributes are encoded. Applying this framework to three transformer-based ReID models on a large-scale visible-spectrum dataset, we find that BMI consistently shows the highest expressivity in deeper layers. Attributes in the final representation are ranked as BMI > Pitch > Gender > Yaw, and expressivity evolves across layers and training epochs, with pose peaking in intermediate layers and BMI strengthening with depth. We further extend the analysis to cross-spectral person identification across infrared modalities including short-wave, medium-wave, and long-wave infrared. In this setting, pitch becomes comparable to BMI and attribute trends increase monotonically across depth, suggesting increased reliance on structural cues when bridging modality gaps. Overall, the results show that transformer-based ReID embeddings encode a hierarchy of implicit attributes, with morphometric information persistently embedded and pose contributing more strongly under cross-spectral conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AttriBE, a framework extending the notion of expressivity (mutual information between ReID embeddings and target attributes) estimated via a secondary neural network. Applied to three transformer-based ReID models on a large-scale visible-spectrum dataset, it reports that BMI shows the highest expressivity in deeper layers, with final-representation rankings BMI > Pitch > Gender > Yaw; expressivity evolves across layers (pose peaking intermediately, BMI strengthening with depth) and training epochs. In cross-spectral infrared settings (SWIR/MWIR/LWIR), pitch becomes comparable to BMI and trends increase monotonically with depth, suggesting greater reliance on structural cues across modalities.
Significance. If the mutual-information estimates prove reliable, the work offers concrete empirical observations on the implicit encoding of morphometric and pose attributes in ReID features, with direct relevance to fairness, generalization, and cross-modal robustness in person identification. The layer-wise and modality-specific tracking of expressivity could inform model design and bias mitigation. The approach is a straightforward empirical measurement on fixed pretrained models with no circular fitting of parameters inside the same experiment.
major comments (3)
- [Method / AttriBE framework] The reported attribute hierarchy (BMI > Pitch > Gender > Yaw) and all layer/epoch/modality trends rest on the secondary neural network recovering a faithful estimate of mutual information. For continuous attributes the proxy uses regression loss; no calibration on synthetic data with known ground-truth MI, no comparison to non-parametric estimators (kNN, kernel density), and no ablation on auxiliary-network depth/regularization are described. This is load-bearing because auxiliary-model inductive bias or overfitting in the high-dimensional embedding space could produce the observed ranking and monotonicity rather than intrinsic encoding in the ReID transformer.
- [Experiments] The abstract and results summary supply no dataset size, attribute-labeling protocol or accuracy (especially for continuous BMI), or statistical tests for the claimed expressivity differences and cross-spectral shifts. Without these, it is impossible to judge whether the data support the stated hierarchy and trends.
- [Cross-spectral analysis] The cross-spectral claim that pitch becomes comparable to BMI and that attribute trends increase monotonically across depth requires tabulated MI values or figures showing the quantitative shift relative to the visible-spectrum case; the current description is qualitative.
minor comments (2)
- Define the expressivity measure (mutual-information estimator) with an explicit equation at first use rather than describing it only in prose.
- Clarify whether the secondary network is trained from scratch for each layer/epoch or shares weights, and report its architecture and training hyperparameters.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have addressed each major comment point by point below and will revise the paper to incorporate the suggested improvements, which we believe will strengthen the presentation and validation of the AttriBE framework.
read point-by-point responses
-
Referee: [Method / AttriBE framework] The reported attribute hierarchy (BMI > Pitch > Gender > Yaw) and all layer/epoch/modality trends rest on the secondary neural network recovering a faithful estimate of mutual information. For continuous attributes the proxy uses regression loss; no calibration on synthetic data with known ground-truth MI, no comparison to non-parametric estimators (kNN, kernel density), and no ablation on auxiliary-network depth/regularization are described. This is load-bearing because auxiliary-model inductive bias or overfitting in the high-dimensional embedding space could produce the observed ranking and monotonicity rather than intrinsic encoding in the ReID transformer.
Authors: We agree that the fidelity of the mutual-information estimates is central to the validity of the reported hierarchy and trends. Although the auxiliary-network approach follows established neural MI estimation practices, we acknowledge the absence of explicit calibration and robustness checks in the original submission. In the revised manuscript we will add: (1) calibration experiments on synthetic data with known ground-truth MI values, (2) direct comparisons against non-parametric estimators (kNN and kernel-density) on representative embedding subsets, and (3) an ablation varying auxiliary-network depth and regularization. These additions will demonstrate that the observed rankings and layer-wise patterns are not artifacts of the estimator. revision: yes
-
Referee: [Experiments] The abstract and results summary supply no dataset size, attribute-labeling protocol or accuracy (especially for continuous BMI), or statistical tests for the claimed expressivity differences and cross-spectral shifts. Without these, it is impossible to judge whether the data support the stated hierarchy and trends.
Authors: We apologize for the lack of explicit detail in the abstract and summary sections. The full manuscript already contains the underlying dataset description, but we will expand the abstract, add a dedicated experimental-details subsection, and include a summary table reporting exact dataset size, train/test splits, attribute-labeling protocol (including how continuous BMI values were obtained and their estimation accuracy), and statistical significance tests (bootstrap confidence intervals and paired tests) for all reported expressivity differences and cross-spectral shifts. revision: yes
-
Referee: [Cross-spectral analysis] The cross-spectral claim that pitch becomes comparable to BMI and that attribute trends increase monotonically across depth requires tabulated MI values or figures showing the quantitative shift relative to the visible-spectrum case; the current description is qualitative.
Authors: We concur that the cross-spectral results would be more convincing with quantitative support. In the revised manuscript we will insert a table listing mutual-information values for each attribute and layer under both visible and cross-spectral (SWIR/MWIR/LWIR) conditions, together with side-by-side trend plots that directly compare the visible and infrared curves. These additions will make the claimed shift toward structural cues (e.g., pitch becoming comparable to BMI) and the monotonic depth dependence fully quantitative. revision: yes
Circularity Check
No significant circularity; empirical measurement on fixed models
full rationale
The paper defines expressivity as mutual information between ReID embeddings and attributes, then estimates it empirically by training a secondary neural network on fixed pretrained transformer models. This is a measurement procedure applied after model training, with no equations or steps that reduce the reported attribute rankings (BMI > Pitch > Gender > Yaw), layer-wise trends, or cross-spectral observations to quantities fitted inside the same experiment. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation. The approach remains self-contained as an observational analysis against external pretrained models and datasets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mutual information between learned features and target attributes can be approximated by the predictive performance of a secondary neural network
invented entities (1)
-
Attribute expressivity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep convolutional neural networks in the face of caricature,
M. Q. Hill, C. J. Parde, C. D. Castillo, Y . I. Colon, R. Ranjan, J.-C. Chen, V . Blanz, and A. J. O’Toole, “Deep convolutional neural networks in the face of caricature,”Nature Machine Intelligence, vol. 1, no. 11, pp. 522–529, 2019
2019
-
[2]
Deep learning for face recognition: Pride or prejudiced?
S. Nagpal, M. Singh, R. Singh, and M. Vatsa, “Deep learning for face recognition: Pride or prejudiced?”arXiv preprint arXiv:1904.01219, 2019
-
[3]
Face and image representation in deep cnn features,
C. J. Parde, C. Castillo, M. Q. Hill, Y . I. Colon, S. Sankaranarayanan, J.-C. Chen, and A. J. O’Toole, “Face and image representation in deep cnn features,” in2017 12th ieee international conference on automatic face & gesture recognition (fg 2017). IEEE, 2017, pp. 673–680
2017
-
[4]
Introduction to face recognition and evaluation of algorithm performance,
G. H. Givens, J. R. Beveridge, P. J. Phillips, B. Draper, Y . M. Lui, and D. Bolme, “Introduction to face recognition and evaluation of algorithm performance,”Computational Statistics & Data Analysis, vol. 67, pp. 236–247, 2013
2013
-
[5]
Generalizing face quality and factor measures to video,
Y . Lee, P. J. Phillips, J. J. Filliben, J. R. Beveridge, and H. Zhang, “Generalizing face quality and factor measures to video,” inIEEE International Joint Conference on Biometrics. IEEE, 2014, pp. 1–8
2014
-
[6]
How are attributes expressed in face dcnns?
P. Dhar, A. Bansal, C. D. Castillo, J. Gleason, P. J. Phillips, and R. Chellappa, “How are attributes expressed in face dcnns?” in2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020). IEEE, 2020, pp. 85–92
2020
-
[7]
Person re-identification for smart cities: State-of-the-art and the path ahead,
N. K. S. Behera, P. K. Sa, and S. Bakshi, “Person re-identification for smart cities: State-of-the-art and the path ahead,”Pattern Recognition Letters, vol. 138, pp. 282–289, 2020
2020
-
[8]
Deep-reid: Deep features and autoencoder assisted image patching strategy for person re-identification in smart cities surveillance,
S. U. Khan, T. Hussain, A. Ullah, and S. W. Baik, “Deep-reid: Deep features and autoencoder assisted image patching strategy for person re-identification in smart cities surveillance,”Multimedia Tools and Applications, vol. 83, no. 5, pp. 15 079–15 100, 2024
2024
-
[9]
Pedestrian models for autonomous driving part ii: high-level models of human behavior,
F. Camara, N. Bellotto, S. Cosar, F. Weber, D. Nathanael, M. Althoff, J. Wu, J. Ruenz, A. Dietrich, G. Markkulaet al., “Pedestrian models for autonomous driving part ii: high-level models of human behavior,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 9, pp. 5453–5472, 2020
2020
-
[10]
Identifying unknown instances for autonomous driving,
K. Wong, S. Wang, M. Ren, M. Liang, and R. Urtasun, “Identifying unknown instances for autonomous driving,” inConference on Robot Learning. PMLR, 2020, pp. 384–393
2020
-
[11]
Scalable person re-identification: A benchmark,
L. Zheng, L. Shen, L. Tian, S. Wang, J. Wang, and Q. Tian, “Scalable person re-identification: A benchmark,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 1116–1124
2015
-
[12]
Temporal knowledge propagation for image-to-video person re-identification,
X. Gu, B. Ma, H. Chang, S. Shan, and X. Chen, “Temporal knowledge propagation for image-to-video person re-identification,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9647–9656
2019
-
[13]
Clothes- changing person re-identification with rgb modality only,
X. Gu, H. Chang, B. Ma, S. Bai, S. Shan, and X. Chen, “Clothes- changing person re-identification with rgb modality only,” inProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1060–1069
2022
-
[14]
Dissecting human body representations in deep networks trained for person identification,
T. M. Metz, M. Q. Hill, B. Myers, V . N. Gandi, R. Chilakapati, and A. J. O’Toole, “Dissecting human body representations in deep networks trained for person identification,”arXiv preprint arXiv:2502.15934, 2025
-
[15]
Mutual information neural estimation,
M. I. Belghazi, A. Baratin, S. Rajeshwar, S. Ozair, Y . Bengio, A. Courville, and D. Hjelm, “Mutual information neural estimation,” inInternational conference on machine learning. PMLR, 2018, pp. 531–540
2018
-
[16]
T. M. Cover,Elements of information theory. John Wiley & Sons, 1999
1999
-
[17]
A quantitative evaluation of the expressivity of bmi, pose and gender in body embeddings for recognition and identification,
B. Pal, S. Huang, and R. Chellappa, “A quantitative evaluation of the expressivity of bmi, pose and gender in body embeddings for recognition and identification,” in2025 IEEE International Joint Conference on Biometrics (IJCB), 2025, pp. 1–10
2025
-
[18]
Expanding accurate person recognition to new altitudes and ranges: The briar dataset,
D. Cornett, J. Brogan, N. Barber, D. Aykac, S. Baird, N. Burchfield, C. Dukes, A. Duncan, R. Ferrell, J. Goddardet al., “Expanding accurate person recognition to new altitudes and ranges: The briar dataset,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 593–602
2023
-
[19]
Multi-domain biometric recognition using body embeddings,
A. Nanduri, S. Huang, and R. Chellappa, “Multi-domain biometric recognition using body embeddings,” in2025 IEEE 19th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 2025, pp. 1–10
2025
-
[20]
S. Huang, Y . Zhou, R. Prabhakar, X. Liu, Y . Guo, H. Yi, C. Peng, R. Chellappa, and C. P. Lau, “Self-supervised learning of whole and component-based semantic representations for person re-identification,” arXiv preprint arXiv:2311.17074, 2023
-
[21]
Diverse embedding expansion network and low-light cross-modality benchmark for visible-infrared person re- identification,
Y . Zhang and H. Wang, “Diverse embedding expansion network and low-light cross-modality benchmark for visible-infrared person re- identification,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 2153–2162
2023
-
[22]
Iarpa janus bench- mark multi-domain face,
N. D. Kalka, J. A. Duncan, J. Dawson, and C. Otto, “Iarpa janus bench- mark multi-domain face,” in2019 IEEE 10th International Conference JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 13 on Biometrics Theory, Applications and Systems (BTAS). IEEE, 2019, pp. 1–9
2015
-
[23]
Template-based multi-domain face recognition,
A. Nanduri and R. Chellappa, “Template-based multi-domain face recognition,” in2024 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2024, pp. 1–10
2024
-
[24]
Diagnosing gender bias in image recognition systems,
C. Schwemmer, C. Knight, E. D. Bello-Pardo, S. Oklobdzija, M. Schoonvelde, and J. W. Lockhart, “Diagnosing gender bias in image recognition systems,”Socius, vol. 6, p. 2378023120967171, 2020
2020
-
[25]
Pass: protected attribute suppression system for mitigating bias in face recog- nition,
P. Dhar, J. Gleason, A. Roy, C. D. Castillo, and R. Chellappa, “Pass: protected attribute suppression system for mitigating bias in face recog- nition,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 087–15 096
2021
-
[26]
An examination of bias of facial analysis based bmi prediction models,
H. Siddiqui, A. Rattani, K. Ricanek, and T. Hill, “An examination of bias of facial analysis based bmi prediction models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2926–2935
2022
-
[27]
Gamma-face: Gaussian mixture models amend diffusion models for bias mitigation in face images,
B. Pal, A. Kannan, R. P. Kathirvel, A. J. O’Toole, and R. Chellappa, “Gamma-face: Gaussian mixture models amend diffusion models for bias mitigation in face images,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 471–488
2024
-
[28]
Di- versinet: Mitigating bias in deep classification networks across sensitive attributes through diffusion-generated data,
B. Pal, A. Roy, R. P. Kathirvel, A. J. O’Toole, and R. Chellappa, “Di- versinet: Mitigating bias in deep classification networks across sensitive attributes through diffusion-generated data,” in2024 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2024, pp. 1–10
2024
-
[29]
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav),
B. Kim, M. Wattenberg, J. Gilmer, C. Cai, J. Wexler, F. Viegas et al., “Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav),” inInternational conference on machine learning. PMLR, 2018, pp. 2668–2677
2018
-
[30]
Understanding intermediate layers using linear classifier probes
G. Alain, “Understanding intermediate layers using linear classifier probes,”arXiv preprint arXiv:1610.01644, 2016
work page internal anchor Pith review arXiv 2016
-
[31]
Understanding black-box predictions via influence functions,
P. W. Koh and P. Liang, “Understanding black-box predictions via influence functions,” inInternational conference on machine learning. PMLR, 2017, pp. 1885–1894
2017
-
[32]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 618–626
2017
-
[33]
Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks,
A. Chattopadhay, A. Sarkar, P. Howlader, and V . N. Balasubramanian, “Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks,” in2018 IEEE winter conference on applica- tions of computer vision (WACV). IEEE, 2018, pp. 839–847
2018
-
[34]
Person re-identification by deep learning attribute-complementary information,
A. Schumann and R. Stiefelhagen, “Person re-identification by deep learning attribute-complementary information,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2017, pp. 20–28
2017
-
[35]
Recognizing people by body shape using deep networks of images and words,
B. A. Myers, L. Jaggernauth, T. M. Metz, M. Q. Hill, V . N. Gandi, C. D. Castillo, and A. J. O’Toole, “Recognizing people by body shape using deep networks of images and words,” in2023 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2023, pp. 1–8
2023
-
[36]
Towards interpretable face recognition,
B. Yin, L. Tran, H. Li, X. Shen, and X. Liu, “Towards interpretable face recognition,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 9348–9357
2019
-
[37]
The bayesian case model: A gen- erative approach for case-based reasoning and prototype classification,
B. Kim, C. Rudin, and J. A. Shah, “The bayesian case model: A gen- erative approach for case-based reasoning and prototype classification,” Advances in neural information processing systems, vol. 27, 2014
2014
-
[38]
Explain- able person re-identification with attribute-guided metric distillation,
X. Chen, X. Liu, W. Liu, X.-P. Zhang, Y . Zhang, and T. Mei, “Explain- able person re-identification with attribute-guided metric distillation,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 11 813–11 822
2021
-
[39]
Deep learning and the information bottleneck principle,
N. Tishby and N. Zaslavsky, “Deep learning and the information bottleneck principle,” in2015 ieee information theory workshop (itw). IEEE, 2015, pp. 1–5
2015
-
[40]
Celebrities-reid: A benchmark for clothes variation in long-term person re-identification,
Y . Huang, Q. Wu, J. Xu, and Y . Zhong, “Celebrities-reid: A benchmark for clothes variation in long-term person re-identification,” in2019 International Joint Conference on Neural Networks (IJCNN). IEEE, 2019, pp. 1–8
2019
-
[41]
Event-guided person re-identification via sparse-dense complementary learning,
C. Cao, X. Fu, H. Liu, Y . Huang, K. Wang, J. Luo, and Z.-J. Zha, “Event-guided person re-identification via sparse-dense complementary learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 990–17 999
2023
-
[42]
Temporal complemen- tary learning for video person re-identification,
R. Hou, H. Chang, B. Ma, S. Shan, and X. Chen, “Temporal complemen- tary learning for video person re-identification,” inComputer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV 16. Springer, 2020, pp. 388–405
2020
-
[43]
Learning multi-granular hypergraphs for video-based person re-identification,
Y . Yan, J. Qin, J. Chen, L. Liu, F. Zhu, Y . Tai, and L. Shao, “Learning multi-granular hypergraphs for video-based person re-identification,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2899–2908
2020
-
[44]
Multi-granularity reference-aided attentive feature aggregation for video-based person re- identification,
Z. Zhang, C. Lan, W. Zeng, and Z. Chen, “Multi-granularity reference-aided attentive feature aggregation for video-based person re- identification,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 407–10 416
2020
-
[45]
Cavit: Contextual alignment vision transformer for video object re- identification,
J. Wu, L. He, W. Liu, Y . Yang, Z. Lei, T. Mei, and S. Z. Li, “Cavit: Contextual alignment vision transformer for video object re- identification,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 549–566
2022
-
[46]
Farsight: A physics- driven whole-body biometric system at large distance and altitude,
F. Liu, R. Ashbaugh, N. Chimitt, N. Hassan, A. Hassani, A. Jaiswal, M. Kim, Z. Mao, C. Perry, Z. Renet al., “Farsight: A physics- driven whole-body biometric system at large distance and altitude,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 6227–6236
2024
-
[47]
Weakly supervised face and whole body recognition in turbulent environments,
K. Nikhal and B. S. Riggan, “Weakly supervised face and whole body recognition in turbulent environments,” in2023 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2023, pp. 1–10
2023
-
[48]
Hashreid: Dy- namic network with binary codes for efficient person re-identification,
K. Nikhal, Y . Ma, S. S. Bhattacharyya, and B. S. Riggan, “Hashreid: Dy- namic network with binary codes for efficient person re-identification,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 6046–6055
2024
-
[49]
Sharc: Shape and appear- ance recognition for person identification in-the-wild,
H. Zhu, W. Zheng, Z. Zheng, and R. Nevatia, “Sharc: Shape and appear- ance recognition for person identification in-the-wild,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 6290–6300
2024
-
[50]
Beyond appearance: a semantic controllable self-supervised learning framework for human-centric visual tasks,
W. Chen, X. Xu, J. Jia, H. Luo, Y . Wang, F. Wang, R. Jin, and X. Sun, “Beyond appearance: a semantic controllable self-supervised learning framework for human-centric visual tasks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 15 050–15 061
2023
-
[51]
Learning discriminative features with multiple granularities for person re-identification,
G. Wang, Y . Yuan, X. Chen, J. Li, and X. Zhou, “Learning discriminative features with multiple granularities for person re-identification,” in Proceedings of the 26th ACM international conference on Multimedia, 2018, pp. 274–282
2018
-
[52]
Pass:part-aware self-supervised pre-training for person re-identification,
K. Zhu, H. Guo, T. Yan, Y . Zhu, J. Wang, and M. Tang, “Pass:part-aware self-supervised pre-training for person re-identification,” inEuropean conference on computer vision. Springer, 2022, pp. 198–214
2022
-
[53]
Yolov10: Real-time end-to-end object detection,
A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han, and G. Ding, “Yolov10: Real-time end-to-end object detection,”Advances in neural information processing systems, vol. 37, pp. 107 984–108 011, 2024
2024
-
[54]
Tracking people by predicting 3D appearance, location & pose,
J. Rajasegaran, G. Pavlakos, A. Kanazawa, and J. Malik, “Tracking people by predicting 3D appearance, location & pose,” inCVPR, 2022
2022
-
[55]
Hu- mans in 4D: Reconstructing and tracking humans with transformers,
S. Goel, G. Pavlakos, J. Rajasegaran, A. Kanazawa, and J. Malik, “Hu- mans in 4D: Reconstructing and tracking humans with transformers,” in ICCV, 2023
2023
-
[56]
Pose-guided feature dis- entangling for occluded person re-identification based on transformer,
T. Wang, H. Liu, P. Song, T. Guo, and W. Shi, “Pose-guided feature dis- entangling for occluded person re-identification based on transformer,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, no. 3, 2022, pp. 2540–2549
2022
-
[57]
Dc-former: Diverse and compact transformer for person re- identification,
W. Li, C. Zou, M. Wang, F. Xu, J. Zhao, R. Zheng, Y . Cheng, and W. Chu, “Dc-former: Diverse and compact transformer for person re- identification,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 2, 2023, pp. 1415–1423
2023
-
[58]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words,”arXiv preprint arXiv:2010.11929, vol. 7, 2020
work page internal anchor Pith review arXiv 2010
-
[59]
Unsupervised learning of visual features by contrasting cluster assign- ments,
M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrasting cluster assign- ments,”Advances in neural information processing systems, vol. 33, pp. 9912–9924, 2020
2020
-
[60]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660
2021
-
[61]
Unsupervised pre-training for person re-identification,
D. Fu, D. Chen, J. Bao, H. Yang, L. Yuan, L. Zhang, H. Li, and D. Chen, “Unsupervised pre-training for person re-identification,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14 750–14 759. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 14 Basudha Palis a recent Ph.D. graduate in Electri- cal an...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.