Recognition: 2 theorem links
· Lean TheoremLearning Tactile-Aware Quadrupedal Loco-Manipulation Policies
Pith reviewed 2026-05-12 02:29 UTC · model grok-4.3
The pith
A hierarchical policy uses predicted tactile cues from human demonstrations to enable coordinated quadrupedal locomotion and contact-rich manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
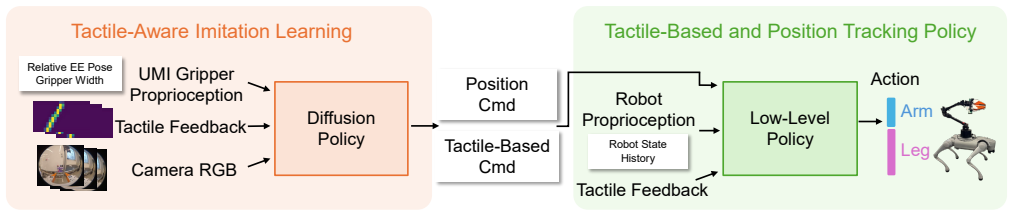
The central discovery is a tactile-aware loco-manipulation policy learning pipeline with a hierarchical structure. A tactile-conditioned visuotactile high-level policy trained on real-world human demonstrations predicts end-effector trajectories and evolving tactile interaction cues. A large-scale reinforcement learning policy in simulation then learns to track these diverse commanded trajectories and tactile cues, transferring zero-shot to the real world. This enables coordinated locomotion and manipulation in contact-rich scenarios.
What carries the argument
The hierarchical policy structure where the high-level policy predicts both trajectories and tactile interaction cues from demonstrations, and the whole-body control policy tracks them via simulation-trained reinforcement learning.
If this is right
- The system achieves 28.54% average performance improvement over vision-only and visuotactile baselines on real-world tasks.
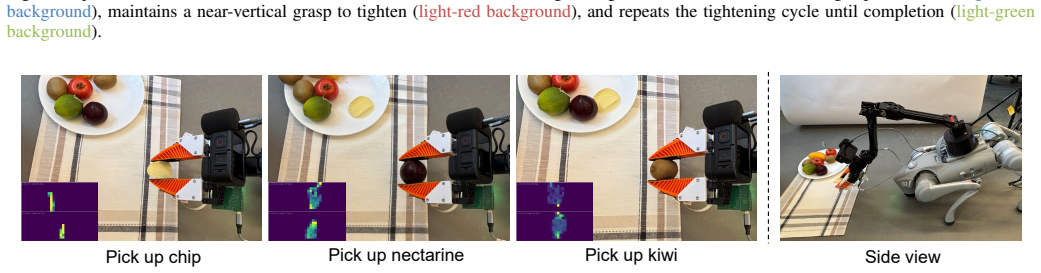
- Zero-shot transfer to real hardware is possible for tasks including in-hand reorientation with insertion, valve tightening, and delicate object manipulation.
- Coordinated locomotion and manipulation becomes feasible under uncertain, evolving contact conditions.
- Scalable learning for tactile-aware quadrupedal policies is demonstrated through this pipeline.
Where Pith is reading between the lines
- This approach might generalize to other legged robots if the tactile prediction and tracking can be adapted to different sensor configurations.
- Future extensions could incorporate online adaptation of the tactile cues during execution to handle unexpected changes in the environment.
- Success here suggests that predicting contact evolution from demonstrations could reduce reliance on precise physics simulation for manipulation tasks.
Load-bearing premise
That tactile interaction cues predicted from human demonstrations can be accurately tracked by a simulation-trained whole-body policy and transferred zero-shot to real hardware without significant sim-to-real gaps in tactile sensing or contact dynamics.
What would settle it
Running the real-world experiments and observing no average improvement over the vision-only baseline across the tested tasks, or measuring large discrepancies between predicted and actual tactile signals during execution.
Figures





read the original abstract
Quadrupedal loco-manipulation is commonly built on visual perception and proprioception. Yet reliable contact-rich manipulation remains difficult: vision and proprioception alone cannot resolve uncertain, evolving interactions with the environment. Tactile sensing offers direct contact observability, but scalable tactile-aware learning framework for quadrupedal loco-manipulation is still underexplored. In this paper, we present a tactile-aware loco-manipulation policy learning pipeline with a hierarchical structure. Our approach has two key components. First, we leverage real-world human demonstrations to train a tactile-conditioned visuotactile high-level policy. This policy predicts not only end-effector trajectories for manipulation, but also the evolving tactile interaction cues that characterize how contact should develop over time. Second, we perform large-scale reinforcement learning in simulation to learn a tactile-aware whole-body control policy that tracks diverse commanded trajectories and tactile interaction cues, and transfers zero-shot to the real world. Together, these components enable coordinated locomotion and manipulation under contact-rich scenarios. We evaluate the system on real-world contact-rich tasks, including in-hand reorientation with insertion, valve tightening, and delicate object manipulation. Compared to vision-only and visuotactile baselines, our method improves performance by 28.54% on average across these tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical tactile-aware framework for quadrupedal loco-manipulation. A high-level visuotactile policy is trained on human demonstrations to output end-effector trajectories together with predicted tactile interaction cues; a low-level whole-body policy is then trained via large-scale RL in simulation to track these commands and transfers zero-shot to hardware. Real-world evaluation on contact-rich tasks (in-hand reorientation with insertion, valve tightening, delicate object manipulation) reports a 28.54% average improvement over vision-only and visuotactile baselines.
Significance. If the zero-shot sim-to-real transfer of tactile-cue tracking holds without relying on simulator artifacts, the hierarchical separation of cue prediction from whole-body control would represent a meaningful step toward scalable contact-rich loco-manipulation on quadrupeds. The work directly targets an acknowledged gap in tactile-aware learning for legged systems.
major comments (2)
- [Abstract] Abstract: the central claim of a 28.54% average performance improvement is presented without any description of baseline implementations, number of trials, variance, statistical tests, or error analysis. This omission renders the empirical support for the method unverifiable and directly load-bearing for the paper's contribution.
- [Abstract] Abstract: the zero-shot transfer of the simulation-trained whole-body policy is asserted to succeed on contact-rich tasks, yet no information is supplied on the tactile sensor model, contact-patch parameterization, friction/compliance settings, or domain randomization used during RL. This leaves the weakest assumption (accurate reproduction of real tactile responses and evolving contact physics) unexamined and risks the policy succeeding via sim-specific artifacts rather than robust cue tracking.
minor comments (1)
- [Abstract] Abstract: the phrase 'large-scale reinforcement learning' is used without reference to algorithm, horizon length, or compute scale; adding these details would improve reproducibility context even at the abstract level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the abstract to improve self-containment while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 28.54% average performance improvement is presented without any description of baseline implementations, number of trials, variance, statistical tests, or error analysis. This omission renders the empirical support for the method unverifiable and directly load-bearing for the paper's contribution.
Authors: We agree the abstract should briefly contextualize the reported improvement. Full details appear in Section 5: baselines are a vision-only end-effector tracker and a visuotactile RL policy with direct tactile input; evaluation uses 10 independent trials per task with standard deviation reported in Table 1 and one-way ANOVA (p < 0.01) for significance. We have revised the abstract to include a concise clause on the evaluation protocol and statistical support. revision: yes
-
Referee: [Abstract] Abstract: the zero-shot transfer of the simulation-trained whole-body policy is asserted to succeed on contact-rich tasks, yet no information is supplied on the tactile sensor model, contact-patch parameterization, friction/compliance settings, or domain randomization used during RL. This leaves the weakest assumption (accurate reproduction of real tactile responses and evolving contact physics) unexamined and risks the policy succeeding via sim-specific artifacts rather than robust cue tracking.
Authors: Simulation details are provided in Section 4.2: the tactile model replicates the real GelSight sensor via 3D force and deformation fields; contact patches are discretized at 16x16 resolution; friction and compliance are randomized over μ ∈ [0.3, 1.2] and k ∈ [100, 500] N/m during large-scale RL. These choices, together with the real-world results, support that transfer relies on cue tracking rather than artifacts. We have added a short summary sentence on the sensor model and randomization to the abstract. revision: yes
Circularity Check
No circularity: empirical hierarchical learning pipeline with no derivations or self-referential fits
full rationale
The paper outlines a two-stage learning pipeline—(1) training a high-level visuotactile policy on real human demonstrations to output end-effector trajectories plus predicted tactile cues, and (2) large-scale RL in simulation to train a whole-body policy that tracks those commands, followed by zero-shot real-world transfer—without any equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations. Performance claims rest on empirical comparisons (28.54% average improvement on real contact-rich tasks) rather than any constructed equivalence between inputs and outputs. The sim-to-real assumption is an external empirical claim, not a self-definitional reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction uncleartactile-aware hierarchical loco-manipulation learning framework... high-level tactile-conditioned diffusion model... low-level... reinforcement learning in simulation... zero-shot to the real world... 28.54% average performance improvement
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleartactile signals... low-dimensional tactile descriptor... contact area m, contact orientation θ, contact center c... reward rtac exp(−∥scmd−s∥²/σtac)
Reference graph
Works this paper leans on
-
[1]
Deep whole-body control: learning a unified policy for manipulation and locomotion,
Z. Fu, X. Cheng, and D. Pathak, “Deep whole-body control: learning a unified policy for manipulation and locomotion,” inConference on Robot Learning. PMLR, 2023, pp. 138–149
work page 2023
-
[2]
Legged robots for object manipulation: A review,
Y . Gong, G. Sun, A. Nair, A. Bidwai, R. CS, J. Grezmak, G. Sartoretti, and K. A. Daltorio, “Legged robots for object manipulation: A review,” Frontiers in Mechanical Engineering, vol. 9, p. 1142421, 2023
work page 2023
-
[3]
TouchGuide: Inference-Time Steering of Visuomotor Policies via Touch Guidance
Z. Zhang, J. Ma, X. Yang, X. Wen, Y . Zhang, B. Li, Y . Qin, J. Liu, C. Zhao, L. Kanget al., “Touchguide: Inference-time steering of visuo- motor policies via touch guidance,”arXiv preprint arXiv:2601.20239, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
UniT: Data efficient tactile representation with generalization to unseen objects,
Z. Xu, R. Uppuluri, X. Zhang, C. Fitch, P. G. Crandall, W. Shou, D. Wang, and Y . She, “UniT: Data efficient tactile representation with generalization to unseen objects,” 2025
work page 2025
-
[5]
Machine learning for tactile perception: advancements, challenges, and opportunities,
Z. Hu, L. Lin, W. Lin, Y . Xu, X. Xia, Z. Peng, Z. Sun, and Z. Wang, “Machine learning for tactile perception: advancements, challenges, and opportunities,”Advanced Intelligent Systems, vol. 5, no. 7, p. 2200371, 2023
work page 2023
-
[6]
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song, “Universal manipulation interface: In-the-wild robot teach- ing without in-the-wild robots,”arXiv preprint arXiv:2402.10329, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Umi-on-air: Embodiment-aware guidance for embodiment-agnostic visuomotor policies,
H. Gupta, X. Guo, H. Ha, C. Pan, M. Cao, D. Lee, S. Scherer, S. Song, and G. Shi, “Umi-on-air: Embodiment-aware guidance for embodiment- agnostic visuomotor policies,”arXiv preprint arXiv:2510.02614, 2025
-
[8]
Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper,
X. Zhu, B. Huang, and Y . Li, “Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper,”arXiv preprint arXiv:2507.15062, 2025
-
[9]
Mimictouch: Leveraging multi-modal human tactile demonstrations for contact-rich manipulation,
K. Yu, Y . Han, Q. Wang, V . Saxena, D. Xu, and Y . Zhao, “Mimictouch: Leveraging multi-modal human tactile demonstrations for contact-rich manipulation,”arXiv preprint arXiv:2310.16917, 2023
-
[10]
Towards forceful robotic foundation models: a literature survey,
W. Xie and N. Correll, “Towards forceful robotic foundation models: a literature survey,”arXiv preprint arXiv:2504.11827, 2025
-
[11]
Safe self-supervised learning in real of visuo-tactile feedback policies for industrial insertion,
L. Fu, H. Huang, L. Berscheid, H. Li, K. Goldberg, and S. Chitta, “Safe self-supervised learning in real of visuo-tactile feedback policies for industrial insertion,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 10 380–10 386
work page 2023
-
[12]
ManiFeel: Benchmark- ing and understanding visuotactile manipulation policy learning
Q. K. Luu, P. Zhou, Z. Xu, Z. Zhang, Q. Qiu, and Y . She, “Mani- feel: Benchmarking and understanding visuotactile manipulation policy learning,”arXiv preprint arXiv:2505.18472, 2025
-
[13]
In-hand singulation and scooping manipulation with a 5 dof tactile gripper,
Y . Zhou, P. Zhou, S. Wang, and Y . She, “In-hand singulation and scooping manipulation with a 5 dof tactile gripper,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 5238–5243
work page 2024
-
[14]
Locotouch: Learning dynamic quadrupedal transport with tactile sensing,
C. Lin, Y . R. Song, B. Huo, M. Yu, Y . Wang, S. Liu, Y . Yang, W. Yu, T. Zhang, J. Tanet al., “Locotouch: Learning dynamic quadrupedal transport with tactile sensing,”arXiv preprint arXiv:2505.23175, 2025
-
[15]
H. Ha, Y . Gao, Z. Fu, J. Tan, and S. Song, “Umi on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers,”arXiv preprint arXiv:2407.10353, 2024
-
[16]
Walk these ways: Tuning robot control for generalization with multiplicity of behavior,
G. B. Margolis and P. Agrawal, “Walk these ways: Tuning robot control for generalization with multiplicity of behavior,” inConference on Robot Learning. PMLR, 2023, pp. 22–31
work page 2023
-
[17]
Learning a unified policy for position and force control in legged loco-manipulation,
P. Zhi, P. Li, J. Yin, B. Jia, and S. Huang, “Learning a unified policy for position and force control in legged loco-manipulation,” inConference on Robot Learning. PMLR, 2025, pp. 652–669
work page 2025
-
[18]
Whole-body end- effector pose tracking,
T. Portela, A. Cramariuc, M. Mittal, and M. Hutter, “Whole-body end- effector pose tracking,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 11 205–11 211
work page 2025
-
[19]
Vi- sual whole-body control for legged loco-manipulation,
M. Liu, Z. Chen, X. Cheng, Y . Ji, R.-Z. Qiu, R. Yang, and X. Wang, “Vi- sual whole-body control for legged loco-manipulation,”arXiv preprint arXiv:2403.16967, 2024
-
[20]
Roboduet: Learning a cooperative policy for whole-body legged loco-manipulation,
G. Pan, Q. Ben, Z. Yuan, G. Jiang, Y . Ji, S. Li, J. Pang, H. Liu, and H. Xu, “Roboduet: Learning a cooperative policy for whole-body legged loco-manipulation,”IEEE Robotics and Automation Letters, vol. 10, no. 5, pp. 4564–4571, 2025
work page 2025
-
[21]
Quadwbg: Gener- alizable quadrupedal whole-body grasping,
J. Wang, J. Rajabov, C. Xu, Y . Zheng, and H. Wang, “Quadwbg: Gener- alizable quadrupedal whole-body grasping,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 11 675–11 682
work page 2025
-
[22]
Learning multi-stage pick-and-place with a legged mobile manipulator,
H. Zhang, H. Yu, L. Zhao, A. Choi, Q. Bai, Y . Yang, and W. Xu, “Learning multi-stage pick-and-place with a legged mobile manipulator,” IEEE Robotics and Automation Letters, vol. 10, no. 11, pp. 11 419– 11 426, 2025
work page 2025
-
[23]
Odyssey: Open-world quadrupeds exploration and manipulation for long-horizon tasks,
K. Wang, L. Lu, M. Liu, J. Jiang, Z. Li, B. Zhang, W. Zheng, X. Yu, H. Chen, and C. Shen, “Odyssey: Open-world quadrupeds exploration and manipulation for long-horizon tasks,”arXiv preprint arXiv:2508.08240, 2025
-
[24]
Mlm: Learning multi-task loco-manipulation whole-body control for quadruped robot with arm,
X. Liu, B. Ma, C. Qi, Y . Ding, N. Xu, G. Zhang, P. Chen, K. Liu, Z. Jia, C. Guanet al., “Mlm: Learning multi-task loco-manipulation whole-body control for quadruped robot with arm,”IEEE Robotics and Automation Letters, vol. 11, no. 1, pp. 81–88, 2025
work page 2025
-
[25]
UMI on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers,
H. Ha, Y . Gao, Z. Fu, J. Tan, and S. Song, “UMI on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers,” inProceedings of the 2024 Conference on Robot Learning, 2024
work page 2024
-
[26]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
work page 2025
-
[27]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
work page 2018
-
[28]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[29]
Vt-refine: Learning bimanual assembly with visuo-tactile feedback via simulation fine- tuning,
B. Huang, J. Xu, I. Akinola, W. Yang, B. Sundaralingam, R. O’Flaherty, D. Fox, X. Wang, A. Mousavian, Y .-W. Chaoet al., “Vt-refine: Learning bimanual assembly with visuo-tactile feedback via simulation fine- tuning,”arXiv preprint arXiv:2510.14930, 2025
-
[30]
Tacsl: A library for visuotactile sensor simulation and learning,
I. Akinola, J. Xu, J. Carius, D. Fox, and Y . Narang, “Tacsl: A library for visuotactile sensor simulation and learning,”IEEE Transactions on Robotics, 2025
work page 2025
-
[31]
Tactile-rl for insertion: Generalization to objects of unknown geome- try,
S. Dong, D. K. Jha, D. Romeres, S. Kim, D. Nikovski, and A. Rodriguez, “Tactile-rl for insertion: Generalization to objects of unknown geome- try,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 6437–6443
work page 2021
-
[32]
H. Zhang, R. Dai, G. Solak, P. Zhou, Y . She, and A. Ajoudani, “Safe learning for contact-rich robot tasks: A survey from classical learning-based methods to safe foundation models,”arXiv preprint arXiv:2512.11908, 2025
-
[33]
Visual-tactile pretraining and online multitask learning for humanlike manipulation dexterity,
Q. Ye, Q. Liu, S. Wang, J. Chen, Y . Cui, K. Jin, H. Chen, X. Cai, G. Li, and J. Chen, “Visual-tactile pretraining and online multitask learning for humanlike manipulation dexterity,”Science Robotics, vol. 11, no. 110, p. eady2869, 2026
work page 2026
-
[34]
Tactile-driven dexterous in-hand writing via extrinsic contact sensing,
C. Zhao, L. Xie, B. Huang, S. Wang, and D. Ma, “Tactile-driven dexterous in-hand writing via extrinsic contact sensing,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[35]
Texterity: Tactile extrinsic dexterity,
A. Bronars, S. Kim, P. Patre, and A. Rodriguez, “Texterity: Tactile extrinsic dexterity,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 7976–7983
work page 2024
-
[36]
An autonomous strawberry-harvesting robot: Design, development, integration, and field evaluation,
Y . Xiong, Y . Ge, L. Grimstad, and P. J. From, “An autonomous strawberry-harvesting robot: Design, development, integration, and field evaluation,”Journal of Field Robotics, vol. 37, no. 2, pp. 202–224, 2020
work page 2020
-
[37]
A survey of robotic harvesting systems and enabling technologies,
L. Droukas, Z. Doulgeri, N. L. Tsakiridis, D. Triantafyllou, I. Kleitsiotis, I. Mariolis, D. Giakoumis, D. Tzovaras, D. Kateris, and D. Bochtis, “A survey of robotic harvesting systems and enabling technologies,”Journal of Intelligent & Robotic Systems, vol. 107, no. 2, p. 21, 2023
work page 2023
-
[38]
Stable reinforcement learning with autoencoders for tactile and visual data,
H. Van Hoof, N. Chen, M. Karl, P. Van Der Smagt, and J. Peters, “Stable reinforcement learning with autoencoders for tactile and visual data,” in2016 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2016, pp. 3928–3934
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.