Recognition: unknown
RAQG-QPP: Query Performance Prediction with Retrieved Query Variants and Retrieval Augmented Query Generation
Pith reviewed 2026-05-07 09:34 UTC · model grok-4.3
The pith
Using queries retrieved from logs and expanded by large language models improves unsupervised query performance prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RAQG-QPP improves query performance prediction by retrieving real queries from a historical log as variants and then using large language models to generate further variants conditioned on those retrieved queries, producing better estimates of retrieval quality than term-expansion methods, with gains up to 30 percent on neural models such as MonoT5 evaluated on TREC DL'19 and DL'20.
What carries the argument
Retrieved query variants from a log combined with LLM-generated variants conditioned on the retrieved queries (RAQG) to supply coherent signals for QPP.
If this is right
- QPP accuracy rises substantially for neural ranking models such as MonoT5.
- The method outperforms the strongest existing query-variant prediction baselines by as much as 30 percent.
- Better QPP enables more effective query-specific selective decision making in retrieval pipelines.
- The gains hold on the TREC DL'19 and DL'20 benchmarks without any relevance judgments.
Where Pith is reading between the lines
- Query logs may serve as grounding data for other unsupervised information-retrieval techniques that rely on variant or expansion signals.
- Conditioning generation on real logged queries could reduce hallucination risks in broader LLM-assisted retrieval workflows.
- The approach invites testing whether click or session data from the same logs can further strengthen the variant signals.
Load-bearing premise
Retrieved queries from the log share sufficiently similar information needs with the input query and LLM-generated variants remain coherent, on-topic, and free of hallucinations that would degrade the prediction signals.
What would settle it
Applying the method to a query log dominated by unrelated past queries or to an LLM that produces many off-topic or hallucinatory variants would eliminate or reverse the reported accuracy gains on the TREC DL collections.
Figures






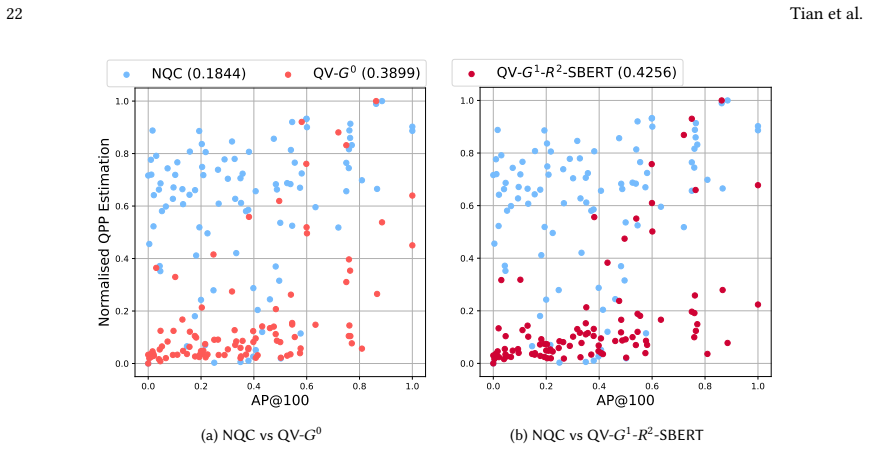

read the original abstract
Query Performance Prediction (QPP) estimates the retrieval quality of ranking models without the use of any human-assessed relevance judgements, and finds applications in query-specific selective decision making to improve overall retrieval effectiveness. Although unsupervised QPP approaches are effective for lexical retrieval models, they usually perform weaker for neural rankers. Recent work shows that leveraging query variants (QVs), i.e., queries with potentially similar information needs to a given query, can enhance unsupervised QPP accuracy. However, existing QV-based prediction methods rely on query variants generated by term expansion of the input query, which is likely to yield incoherent, hallucinatory and off-topic QVs. In this paper, we propose to make use of queries retrieved from a log of past queries as QVs to be subsequently used for QPP. In addition to directly applying retrieved QVs in QPP, we further propose to leverage large language models (LLMs) to generate QVs conditioned on the retrieved QVs, thus mitigating the limitation of relying only on existing queries in a log. Experiments on TREC DL'19 and DL'20 show that QPP enhanced with RAQG outperform the best-performing existing QV-based prediction approach by as much as 30% on neural ranking models such as MonoT5.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RAQG-QPP for query performance prediction (QPP), which retrieves query variants (QVs) from a past query log and augments them with LLM-generated variants conditioned on the retrieved QVs. This addresses limitations of prior term-expansion QV methods that produce incoherent or off-topic variants. Experiments on TREC DL'19 and DL'20 report that RAQG-enhanced QPP outperforms the best existing QV-based approaches by up to 30% on neural rankers such as MonoT5.
Significance. If the reported gains prove robust and reproducible, the work would advance unsupervised QPP for neural retrieval models by offering a practical source of coherent QVs drawn from real user logs and LLM augmentation. This could improve query-specific selective processing in production IR systems. The focus on standard TREC DL tracks and direct comparison to prior QV baselines provides a clear empirical baseline for impact.
major comments (2)
- The abstract and experimental results claim up to 30% improvement over prior QV-based QPP on TREC DL'19/DL'20 with neural rankers, but the manuscript provides no details on the experimental protocol, baseline re-implementations, choice of QPP correlation metrics, statistical testing procedures, or controls for LLM output variability. This information is load-bearing for verifying the central performance claim.
- The method assumes that log-retrieved queries share sufficiently similar information needs and that LLM-conditioned variants remain coherent and free of hallucinations. No validation of these assumptions (e.g., manual review of sample QVs, coherence metrics, or ablation on hallucinated variants) is described, which directly affects whether the added QVs improve rather than degrade the QPP signal.
minor comments (1)
- The abstract states gains 'by as much as 30%' without specifying the exact metric (e.g., Pearson's r or Kendall's tau) or the precise baseline being compared; adding these specifics would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important areas where the manuscript can be strengthened for clarity and rigor. We address each major comment below and will revise the paper accordingly to improve verifiability and address methodological assumptions.
read point-by-point responses
-
Referee: The abstract and experimental results claim up to 30% improvement over prior QV-based QPP on TREC DL'19/DL'20 with neural rankers, but the manuscript provides no details on the experimental protocol, baseline re-implementations, choice of QPP correlation metrics, statistical testing procedures, or controls for LLM output variability. This information is load-bearing for verifying the central performance claim.
Authors: We agree that the current description of the experimental setup is insufficiently detailed for full reproducibility and verification of the reported gains. Section 4 outlines the use of TREC DL'19 and DL'20 collections, MonoT5 and other neural rankers, and Pearson/Kendall tau correlations for QPP evaluation, but we will expand this section substantially in the revision. Specifically, we will add: (1) a complete experimental protocol with dataset splits and preprocessing steps; (2) explicit descriptions of how prior QV-based baselines (e.g., term-expansion methods) were re-implemented, including any hyperparameter choices; (3) details on statistical testing (paired t-tests with p-values and effect sizes); and (4) controls for LLM variability, such as fixed random seeds, temperature settings, and reporting of results across multiple generations with standard deviations. These additions will directly support the 30% improvement claim. revision: yes
-
Referee: The method assumes that log-retrieved queries share sufficiently similar information needs and that LLM-conditioned variants remain coherent and free of hallucinations. No validation of these assumptions (e.g., manual review of sample QVs, coherence metrics, or ablation on hallucinated variants) is described, which directly affects whether the added QVs improve rather than degrade the QPP signal.
Authors: This is a valid concern, as the effectiveness of RAQG-QPP depends on the quality of the retrieved and generated query variants. The manuscript currently relies on the assumption without explicit validation. In the revised version, we will add a dedicated analysis subsection (likely in Section 5) that includes: (1) manual review of 50 randomly sampled retrieved QVs and LLM-generated variants with qualitative assessment of topical coherence; (2) quantitative coherence metrics, such as average cosine similarity of sentence embeddings between the original query and variants; and (3) an ablation study that filters or removes variants flagged as potentially hallucinatory (e.g., via low similarity thresholds) and reports the resulting impact on QPP accuracy. This will provide evidence that the added variants strengthen rather than degrade the QPP signal. revision: yes
Circularity Check
No circularity: empirical method with external components
full rationale
The paper proposes an empirical QPP method using retrieved log queries and LLM-generated variants, evaluated on standard TREC DL'19/DL'20 collections with neural rankers. No mathematical derivation, fitted parameters, or self-referential definitions are present. The approach relies on external query logs and off-the-shelf LLMs rather than any internal fitting or self-citation chain that reduces the central claim to its inputs. Experiments report gains over prior QV baselines, but these are falsifiable on public data without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
B. He, I. Ounis, Query performance prediction, Information Systems 31 (2006) 585–594. URL: https://www.sciencedirect.com/science/article/pii/ S0306437905000955. doi:https://doi.org/10.1016/j.is.2005.11.003, (1) SPIRE 2004 (2) Multimedia Databases
-
[2]
Datta, D
S. Datta, D. Ganguly, S. MacAvaney, D. Greene, A deep learning approach for selective relevance feedback, in: ECIR (2), volume 14609 ofLecture Notes in Computer Science, Springer, 2024, pp. 189–204
2024
-
[3]
Shtok, O
A. Shtok, O. Kurland, D. Carmel, F. Raiber, G. Markovits, Predicting query performance by query-drift estimation, ACM Trans. Inf. Syst. 30 (2012)
2012
-
[4]
H. Roitman, S. Erera, B. Weiner, Robust standard deviation estimation for query performance prediction, ICTIR ’17, Association for Computing Machinery, New York, NY, USA, 2017, p. 245–248. URL: https://doi.org/10.1145/3121050.3121087
-
[5]
Datta, D
S. Datta, D. Ganguly, M. Mitra, D. Greene, A relative information gain-based query performance prediction framework with generated query variants, ACM Trans. Inf. Syst. 41 (2022)
2022
-
[6]
Zendel, A
O. Zendel, A. Shtok, F. Raiber, O. Kurland, J. S. Culpepper, Information needs, queries, and query performance prediction, in: proc. of SIGIR’19, 2019, p. 395–404
2019
-
[7]
Shtok, O
A. Shtok, O. Kurland, D. Carmel, Query performance prediction using reference lists, ACM Trans. Inf. Syst. 34 (2016)
2016
-
[8]
N. A. Jaleel, J. Allan, W. B. Croft, F. Diaz, L. S. Larkey, X. Li, M. D. Smucker, C. Wade, Umass at TREC 2004: Novelty and HARD, in: TREC 2004, 2004, pp. 1–13
2004
-
[9]
Mikolov, K
T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space, in: 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, Arizona, USA, May 2-4, 2013, Workshop Track Proceedings, 2013, pp. 1–12
2013
-
[10]
Gospodinov, S
M. Gospodinov, S. MacAvaney, C. Macdonald, Doc2query–: When less is more, in: Advances in Information Retrieval, Springer Nature Switzerland, Cham, 2023, pp. 414–422
2023
-
[11]
M. Alaofi, L. Gallagher, M. Sanderson, F. Scholer, P. Thomas, Can generative llms create query variants for test collections? an exploratory study, in: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, Association for Computing Machinery, New York, NY, USA, 2023, p. 1869–1873. URL: ...
-
[12]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, D. Amodei, ...
2020
-
[13]
K. Ran, M. Alaofi, M. Sanderson, D. Spina, Two heads are better than one: Improving search effectiveness through llm generated query variants, in: Proceedings of the 2025 ACM SIGIR Conference on Human Information Interaction and Retrieval, CHIIR ’25, Association for Computing Machinery, New York, NY, USA, 2025
2025
-
[14]
Farquhar, J
S. Farquhar, J. Kossen, L. Kuhn, Y. Gal, Detecting Hallucinations in Large Language Models Using Semantic Entropy, Nature (London) 630 (2024) 625–630
2024
-
[15]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
P. Bajaj, D. Campos, N. Craswell, L. Deng, J. Gao, X. Liu, R. Majumder, A. McNamara, B. Mitra, T. Nguyen, et al., MS MARCO: A human generated machine reading comprehension dataset, arXiv preprint arXiv:1611.09268 (2016). Manuscript submitted to ACM 26 Tian et al
work page internal anchor Pith review arXiv 2016
-
[16]
Frayling, S
E. Frayling, S. MacAvaney, C. Macdonald, I. Ounis, Effective adhoc retrieval through traversal of a query-document graph, in: Advances in Information Retrieval, Springer Nature Switzerland, Cham, 2024, pp. 89–104
2024
-
[17]
Lavrenko, W
V. Lavrenko, W. B. Croft, Relevance based language models, in: proc. of SIGIR’01, 2001, p. 120–127
2001
-
[18]
C. Hauff, D. Hiemstra, F. de Jong, A survey of pre-retrieval query performance predictors, in: Proceedings of the 17th ACM Conference on Information and Knowledge Management, CIKM ’08, Association for Computing Machinery, New York, NY, USA, 2008, p. 1419–1420. URL: https://doi.org/10.1145/1458082.1458311. doi:10.1145/1458082.1458311
-
[19]
Arabzadeh, F
N. Arabzadeh, F. Zarrinkalam, J. Jovanovic, F. Al-Obeidat, E. Bagheri, Neural embedding-based specificity metrics for pre-retrieval query performance prediction, IPM 57 (2020) 102248
2020
-
[20]
D. Roy, D. Ganguly, M. Mitra, G. J. Jones, Estimating Gaussian Mixture Models in the local neighbourhood of Embedded Word Vectors for Query Performance Prediction, IPM 56 (2019) 1026–1045
2019
-
[21]
Cronen-Townsend, Y
S. Cronen-Townsend, Y. Zhou, W. B. Croft, Predicting query performance, in: proc. of SIGIR’02, 2002, p. 299–306
2002
-
[22]
Cummins, J
R. Cummins, J. Jose, C. O’Riordan, Improved query performance prediction using standard deviation, in: proc. of SIGIR’11, Association for Computing Machinery, 2011, p. 1089–1090
2011
-
[23]
Roitman, S
H. Roitman, S. Erera, B. Weiner, Robust standard deviation estimation for query performance prediction, in: Proceedings of the ACM SIGIR International Conference on Theory of Information Retrieval, ICTIR ’17, 2017, p. 245–248
2017
-
[24]
Shtok, O
A. Shtok, O. Kurland, D. Carmel, Using statistical decision theory and relevance models for query-performance prediction, in: Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’10, Association for Computing Machinery, 2010, p. 259–266
2010
-
[25]
G. K. Jayasinghe, W. Webber, M. Sanderson, L. S. Dharmasena, J. S. Culpepper, Statistical comparisons of non-deterministic ir systems using two dimensional variance, IPM 51 (2015) 677–694
2015
-
[26]
A. Chakraborty, D. Ganguly, O. Conlan, Retrievability based document selection for relevance feedback with automatically generated query variants, in: Proceedings of the 29th ACM International Conference on Information & Knowledge Management, CIKM ’20, Association for Computing Machinery, New York, NY, USA, 2020, p. 125–134. URL: https://doi.org/10.1145/3...
-
[27]
Ebrahimi, M
S. Ebrahimi, M. Khodabakhsh, N. Arabzadeh, E. Bagheri, Estimating query performance through rich contextualized query representations, in: Advances in Information Retrieval, Springer Nature Switzerland, Cham, 2024, pp. 49–58
2024
-
[28]
A. Drozdov, H. Zhuang, Z. Dai, Z. Qin, R. Rahimi, X. Wang, D. Alon, M. Iyyer, A. McCallum, D. Metzler, K. Hui, PaRaDe: Passage ranking using demonstrations with LLMs, in: Findings of the Association for Computational Linguistics: EMNLP 2023, Association for Computational Linguistics, Singapore, 2023, pp. 14242–14252. URL: https://aclanthology.org/2023.fin...
-
[29]
S. MacAvaney, L. Soldaini, One-shot labeling for automatic relevance estimation, in: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, Association for Computing Machinery, New York, NY, USA, 2023, p. 2230–2235. URL: https://doi.org/10.1145/3539618.3592032. doi:10.1145/3539618.3592032
- [30]
-
[31]
L. Wang, N. Yang, F. Wei, Query2doc: Query expansion with large language models, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Singapore, 2023, pp. 9414–9423. URL: https://aclanthology.org/2023.emnlp- main.585. doi:10.18653/v1/2023.emnlp-main.585
-
[32]
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, B. Chang, X. Sun, L. Li, Z. Sui, A survey on in-context learning, 2024. arXiv:2301.00234
work page internal anchor Pith review arXiv 2024
-
[33]
A. Parry, D. Ganguly, M. Chandra, "in-context learning" or: How i learned to stop worrying and love "applied information retrieval", 2024. doi:10.1145/3626772.3657842.arXiv:2405.01116
-
[34]
O. Khattab, K. Santhanam, X. L. Li, D. Hall, P. Liang, C. Potts, M. Zaharia, Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive nlp, 2022.arXiv:2212.14024
-
[35]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, D. Kiela, Retrieval-augmented generation for knowledge-intensive nlp tasks, in: Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Curran Associates Inc., Red Hook, NY, USA, 2020, pp. 1–16
2020
-
[36]
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, H. Wang, Retrieval-augmented generation for large language models: A survey, 2023.arXiv:2312.10997
work page internal anchor Pith review arXiv 2023
-
[37]
Active retrieval augmented generation
Z. Jiang, F. Xu, L. Gao, Z. Sun, Q. Liu, J. Dwivedi-Yu, Y. Yang, J. Callan, G. Neubig, Active retrieval augmented generation, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Singapore, 2023, pp. 7969–7992. URL: https://aclanthology.org/2023.emnlp-main.495. doi:10.18653/...
-
[38]
Webber, A
W. Webber, A. Moffat, J. Zobel, A similarity measure for indefinite rankings, ACM Trans. Inf. Syst. 28 (2010)
2010
-
[39]
Reimers, I
N. Reimers, I. Gurevych, Sentence-BERT: Sentence embeddings using Siamese BERT-networks, in: proc. of EMNLP-IJCNLP, 2019, pp. 3982–3992
2019
-
[40]
D. Roy, D. Ganguly, M. Mitra, G. J. F. Jones, Word vector compositionality based relevance feedback using kernel density estimation, in: CIKM, ACM, 2016, pp. 1281–1290
2016
-
[41]
G. Amati, C. J. Van Rijsbergen, Probabilistic models of information retrieval based on measuring the divergence from randomness, ACM Trans. Inf. Syst. 20 (2002) 357–389. URL: https://doi.org/10.1145/582415.582416. doi:10.1145/582415.582416. Manuscript submitted to ACM RAQG-QPP: QPP with Retrieved Query Variants and RAG 27
-
[42]
Ganguly, D
D. Ganguly, D. Roy, M. Mitra, G. J. F. Jones, Word embedding based generalized language model for information retrieval, in: SIGIR, ACM, 2015, pp. 795–798
2015
-
[43]
P. Sen, D. Ganguly, G. J. F. Jones, Word-node2vec: Improving word embedding with document-level non-local word co-occurrences, in: NAACL-HLT (1), Association for Computational Linguistics, 2019, pp. 1041–1051
2019
-
[44]
C. Zhai, J. Lafferty, Model-based feedback in the kl-divergence retrieval model (2001)
2001
-
[45]
D. Roy, D. Ganguly, S. Bhatia, S. Bedathur, M. Mitra, Using word embeddings for information retrieval: How collection and term normalization choices affect performance, in: CIKM, ACM, 2018, pp. 1835–1838
2018
-
[46]
S. Lupart, T. Formal, S. Clinchant, Ms-shift: An analysis of ms marco distribution shifts on neural retrieval, in: Advances in Information Retrieval: 45th European Conference on Information Retrieval, ECIR 2023, Dublin, Ireland, April 2–6, 2023, Proceedings, Part I, Springer-Verlag, Berlin, Heidelberg, 2023, p. 636–652. URL: https://doi.org/10.1007/978-3-...
-
[48]
CoRRabs/2003.07820(2020), https://arxiv.org/ abs/2003.07820
N. Craswell, B. Mitra, E. Yilmaz, D. Campos, Overview of the TREC 2020 Deep Learning track, CoRR abs/2003.07820 (2021).arXiv:2102.07662
-
[49]
Abualsaud, N
M. Abualsaud, N. Ghelani, H. Zhang, M. D. Smucker, G. V. Cormack, M. R. Grossman, A system for efficient high-recall retrieval, in: proc. of SIGIR’18, 2018, p. 1317–1320
2018
-
[50]
D. Ganguly, S. Datta, M. Mitra, D. Greene, An analysis of variations in the effectiveness of query performance prediction, CoRR abs/2202.06306 (2022)
-
[51]
Robertson, S
S. Robertson, S. Walker, S. Jones, M. M. Hancock-Beaulieu, M. Gatford, Okapi at trec-3, in: Overview of the Third Text REtrieval Conference (TREC-3), Gaithersburg, MD: NIST, 1995, pp. 109–126. URL: https://www.microsoft.com/en-us/research/publication/okapi-at-trec-3/
1995
-
[52]
Lin, J.-H
S.-C. Lin, J.-H. Yang, J. Lin, In-batch negatives for knowledge distillation with tightly-coupled teachers for dense retrieval, in: Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021), 2021, pp. 163–173
2021
-
[53]
Khattab, M
O. Khattab, M. Zaharia, ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT, in: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, 2020, p. 39–48
2020
-
[54]
R. F. Nogueira, Z. Jiang, R. Pradeep, J. Lin, Document ranking with a pretrained sequence-to-sequence model, in: Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, volume EMNLP 2020 ofFindings of ACL, Association for Computational Linguistics, 2020, pp. 708–718
2020
-
[55]
X. Ma, L. Wang, N. Yang, F. Wei, J. Lin, Fine-tuning llama for multi-stage text retrieval, in: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’24, Association for Computing Machinery, New York, NY, USA, 2024, p. 2421–2425. URL: https://doi.org/10.1145/3626772.3657951
-
[56]
Macdonald, N
C. Macdonald, N. Tonellotto, S. MacAvaney, I. Ounis, PyTerrier: Declarative experimentation in python from bm25 to dense retrieval, in: proc. of CIKM ’21, 2021, p. 4526–4533
2021
-
[57]
Arabzadeh, M
N. Arabzadeh, M. Khodabakhsh, E. Bagheri, BERT-QPP: contextualized pre-trained transformers for query performance prediction, in: CIKM, ACM, 2021, pp. 2857–2861
2021
-
[58]
G. Faggioli, O. Zendel, J. S. Culpepper, N. Ferro, F. Scholer, sMARE: a new paradigm to evaluate and understand query performance prediction methods, Information Retrieval Journal 25 (2022). URL: https://doi.org/10.1007/s10791-022-09407-w. doi:10.1007/s10791-022-09407-w
-
[59]
N. Craswell, B. Mitra, E. Yilmaz, D. Campos, J. Lin, Overview of the trec 2021 deep learning track, 2025. URL: https://arxiv.org/abs/2507.08191. arXiv:2507.08191
-
[60]
N. Craswell, B. Mitra, E. Yilmaz, D. Campos, J. Lin, E. M. Voorhees, I. Soboroff, Overview of the trec 2022 deep learning track, 2025. URL: https://arxiv.org/abs/2507.10865.arXiv:2507.10865. Manuscript submitted to ACM
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.