Recognition: unknown
Unified Data Discovery across Query Modalities and User Intents
Pith reviewed 2026-05-07 08:48 UTC · model grok-4.3
The pith
UniDisc learns one cross-modal model that turns both natural-language statements and tables into unified representations for retrieving relevant tables from data lakes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
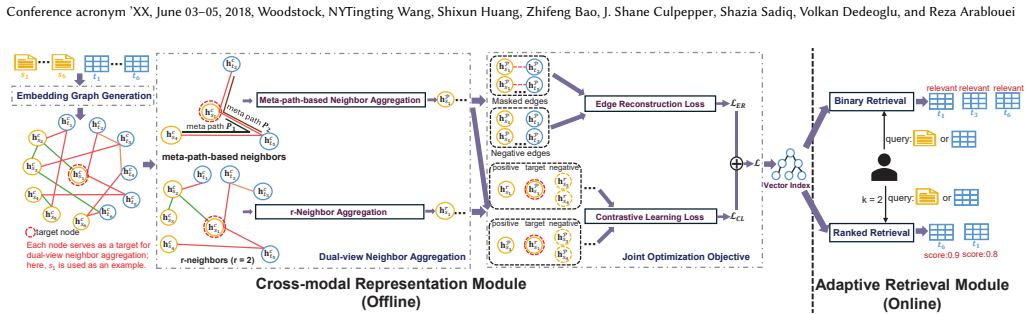
UniDisc learns a common cross-modal representation model that produces unified representations for queries of different modalities and candidate tables, enabling uniform relevance assessment across discovery scenarios. It models natural-language statements and tables as nodes in a heterogeneous graph with multiple edge types, then applies dual-view neighbor aggregation and joint optimization to obtain robust, context-aware embeddings from signals already available in the data lake.
What carries the argument
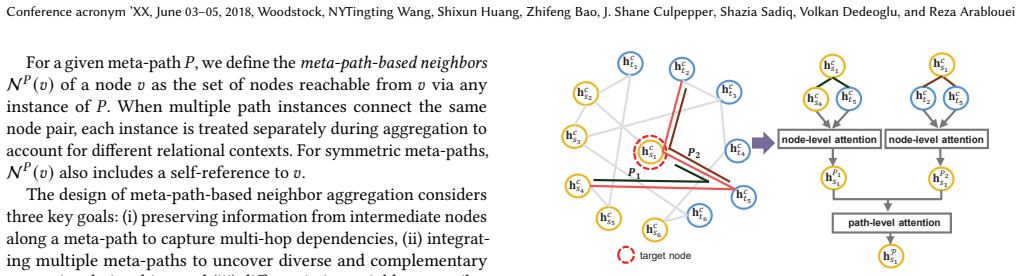
A heterogeneous graph whose nodes are natural-language statements and tables and whose edges encode contextual relations in the data lake; dual-view neighbor aggregation plus joint optimization produces the shared embeddings.
If this is right
- A single trained model supports both natural-language and table queries without intent-specific components.
- Relevance scoring becomes uniform across open-ended enrichment, table-question answering, and fact-verification tasks.
- The same embeddings can be reused for retrieval under new user intents without additional labeled data.
- Experiments on seven datasets show consistent gains over strong single-modality baselines.
Where Pith is reading between the lines
- The same graph-construction pattern could incorporate additional modalities such as column statistics or query logs if they supply comparable neighborhood signals.
- Lakes with sparse metadata might require an auxiliary pre-training stage or external knowledge sources to maintain representation quality.
- Because the learned embeddings are intent-agnostic, they could be plugged directly into downstream pipelines such as automated table joins or verification workflows.
Load-bearing premise
Signals already present among tables and text in a data lake are rich enough to train reliable cross-modal representations without large numbers of explicitly labeled query-table pairs.
What would settle it
Performance on a data lake whose tables lack dense interconnections or descriptive metadata drops below that of modality-specific supervised baselines.
Figures






read the original abstract
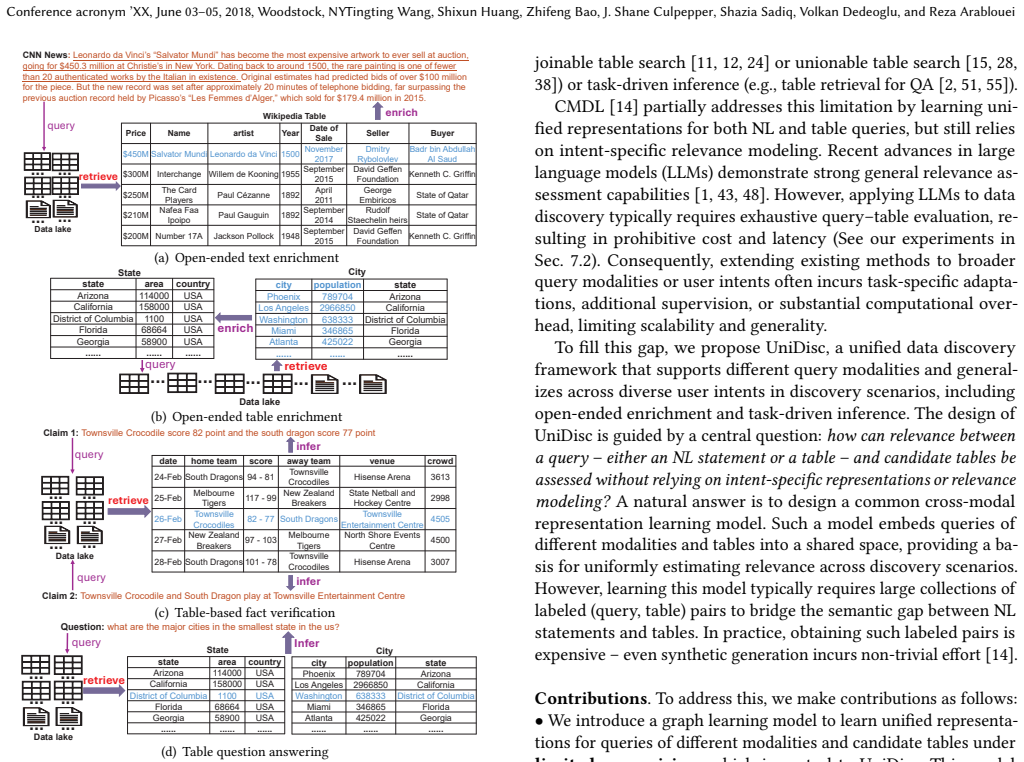
Data discovery - retrieving relevant tables from a data lake in response to user queries - is a fundamental building block for downstream analytics. In practice, data discovery must support different query modalities, including natural language (NL) statements and tables, and accommodate diverse user intents, ranging from open-ended enrichment to task-driven inference for applications such as table question answering and fact verification. However, most existing methods are designed for a single query modality or a specific user intent, limiting their generalizability. We propose UniDisc, a unified data discovery framework that supports both NL statements and tables as queries and generalizes across diverse user intents without intent-specific representations or relevance modeling. UniDisc learns a common cross-modal representation model that produces unified representations for queries of different modalities and candidate tables, enabling uniform relevance assessment across discovery scenarios. Since learning such a model typically requires large labeled collections of query-table pairs, which are expensive to obtain, UniDisc instead exploits contextual signals naturally available in data lakes. Specifically, it models NL statements and tables as nodes in a heterogeneous graph with multiple edge types, and applies dual-view neighbor aggregation and joint optimization to learn robust, context-aware representations under limited supervision. These representations support flexible relevance estimation during retrieval. Experiments on seven datasets show that UniDisc consistently outperforms strong baselines on both NL- and table-based discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UniDisc, a unified data discovery framework for data lakes that supports both natural language statements and tables as queries while generalizing across diverse user intents (e.g., enrichment, fact verification) without modality- or intent-specific models. It constructs a heterogeneous graph with NL statements and tables as nodes, applies dual-view neighbor aggregation and joint optimization to learn unified cross-modal representations from naturally occurring contextual signals under limited supervision, and claims these representations enable uniform relevance assessment with consistent outperformance over baselines on seven datasets.
Significance. If the central claims hold, the work would be significant for data management by offering a generalizable, label-efficient approach to cross-modal data discovery that avoids the fragmentation of prior modality- or intent-specific methods. The exploitation of contextual signals in data lakes rather than large labeled query-table collections is a practical strength, and the graph-based dual-view learning provides a concrete mechanism for context-aware representations. However, the absence of quantitative results, baseline details, or ablation studies in the provided description limits the ability to gauge real-world impact.
major comments (2)
- Abstract: The claim that 'experiments on seven datasets show that UniDisc consistently outperforms strong baselines on both NL- and table-based discovery' provides no quantitative metrics, error bars, baseline names, dataset descriptions, or ablation studies. This absence is load-bearing for the central claim of uniform relevance assessment and generalizability across modalities and intents, as the support for outperformance cannot be evaluated from the given text.
- Abstract (method description): The heterogeneous graph construction is described only at a high level ('models NL statements and tables as nodes in a heterogeneous graph with multiple edge types'), without specifying how NL statement nodes are populated from the data lake or what the edge types capture. This detail is critical for assessing whether naturally occurring contextual signals suffice to learn robust cross-modal representations under limited supervision, directly affecting the weakest assumption underlying the uniform relevance claim.
minor comments (1)
- The abstract would be clearer if it briefly named the seven datasets or characterized the 'strong baselines' to allow readers to immediately contextualize the outperformance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, drawing on details from the full paper while noting opportunities for clarification in the abstract.
read point-by-point responses
-
Referee: Abstract: The claim that 'experiments on seven datasets show that UniDisc consistently outperforms strong baselines on both NL- and table-based discovery' provides no quantitative metrics, error bars, baseline names, dataset descriptions, or ablation studies. This absence is load-bearing for the central claim of uniform relevance assessment and generalizability across modalities and intents, as the support for outperformance cannot be evaluated from the given text.
Authors: We acknowledge that the abstract is intentionally concise and omits specific quantitative details, which is standard practice to respect length constraints. The full manuscript provides these in Section 5 (Experiments), including tables reporting precision, recall, and F1 scores across the seven datasets, comparisons against named strong baselines from prior work, error bars computed over multiple runs, descriptions of each dataset's size and characteristics, and ablation studies isolating the effects of dual-view neighbor aggregation and joint optimization. These results directly support the claims of consistent outperformance and generalizability. We can partially revise the abstract to include a brief reference to key performance gains if the editor permits modest expansion. revision: partial
-
Referee: Abstract (method description): The heterogeneous graph construction is described only at a high level ('models NL statements and tables as nodes in a heterogeneous graph with multiple edge types'), without specifying how NL statement nodes are populated from the data lake or what the edge types capture. This detail is critical for assessing whether naturally occurring contextual signals suffice to learn robust cross-modal representations under limited supervision, directly affecting the weakest assumption underlying the uniform relevance claim.
Authors: The abstract summarizes the method at a high level. The full paper details the construction in Section 3: NL statement nodes are populated by extracting naturally occurring text from table metadata, captions, sample data, and surrounding documents in the data lake; edge types include semantic similarity links, co-occurrence relations within the same lake context, schema overlaps (e.g., shared columns), and other contextual signals. This setup enables learning unified cross-modal representations under limited supervision without requiring large labeled query-table pairs. We can add a short clarifying phrase to the abstract to address this point. revision: partial
Circularity Check
No significant circularity; derivation relies on external data-lake signals and graph construction
full rationale
The paper's central claim is that UniDisc learns unified cross-modal representations by modeling NL statements and tables as nodes in a heterogeneous graph built from naturally occurring contextual signals, then applying dual-view neighbor aggregation and joint optimization. No equations, definitions, or claims in the provided text reduce the learned representations or relevance assessment to a self-definition, a fitted parameter renamed as prediction, or a self-citation chain. The approach is presented as exploiting independent data-lake structure under limited supervision and is evaluated on seven external datasets, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contextual signals naturally present in data lakes can be modeled as a heterogeneous graph with multiple edge types to enable representation learning under limited supervision.
Reference graph
Works this paper leans on
-
[1]
Negar Arabzadeh and Charles L. A. Clarke. 2025. Benchmarking LLM-based Relevance Judgment Methods. InSIGIR. 3194–3204
2025
-
[2]
Muhammad Imam Luthfi Balaka, David Alexander, Qiming Wang, Yue Gong, Adila Krisnadhi, and Raul Castro Fernandez. 2025. Pneuma: Leveraging LLMs for Tabular Data Representation and Retrieval in an End-to-End System.Proc. ACM Manag. Data3, 3 (2025), 200:1–200:28
2025
-
[3]
Alex Bogatu, Alvaro A. A. Fernandes, Norman W. Paton, and Nikolaos Konstanti- nou. 2020. Dataset Discovery in Data Lakes. InICDE. 709–720
2020
-
[4]
Dan Brickley, Matthew Burgess, and Natasha F. Noy. 2019. Google Dataset Search: Building a search engine for datasets in an open Web ecosystem. In WWW. 1365–1375
2019
-
[5]
Sonia Castelo, Rémi Rampin, Aécio S. R. Santos, Aline Bessa, Fernando Chirigati, and Juliana Freire. 2021. Auctus: A Dataset Search Engine for Data Discovery and Augmentation.Proc. VLDB Endow.14, 12 (2021), 2791–2794
2021
-
[6]
Mingke Chai, Zihui Gu, Xiaoman Zhao, Ju Fan, and Xiaoyong Du. 2021. TFV: A Framework for Table-Based Fact Verification.IEEE Data Eng. Bull.44, 3 (2021), 39–51
2021
-
[7]
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. 2020. TabFact: A Large-scale Dataset for Table-based Fact Verification. InICLR
2020
-
[8]
Zhiyu Chen, Mohamed Trabelsi, Jeff Heflin, Yinan Xu, and Brian D. Davison. 2020. Table Search Using a Deep Contextualized Language Model. InSIGIR. 589–598
2020
-
[9]
Levy de Souza Silva and Luciano Barbosa. 2023. Matching news articles and wikipedia tables for news augmentation.Knowl. Inf. Syst.65, 4 (2023), 1713–1734
2023
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT. 4171–4186
2019
-
[11]
Yuyang Dong, Kunihiro Takeoka, Chuan Xiao, and Masafumi Oyamada. 2021. Efficient Joinable Table Discovery in Data Lakes: A High-Dimensional Similarity- Based Approach. InICDE. 456–467
2021
-
[12]
Yuyang Dong, Chuan Xiao, Takuma Nozawa, Masafumi Enomoto, and Masafumi Oyamada. 2023. DeepJoin: Joinable Table Discovery with Pre-trained Language Models.Proc. VLDB Endow.16, 10 (2023), 2458–2470
2023
-
[13]
DrugBank. 2024. https://www.drugbank.com/
2024
-
[14]
Eltabakh, Mayuresh Kunjir, Ahmed K
Mohamed Y. Eltabakh, Mayuresh Kunjir, Ahmed K. Elmagarmid, and Moham- mad Shahmeer Ahmad. 2023. Cross Modal Data Discovery over Structured and Unstructured Data Lakes.Proc. VLDB Endow.16, 11 (2023), 3377–3390
2023
-
[15]
Grace Fan, Jin Wang, Yuliang Li, Dan Zhang, and Renée J. Miller. 2023. Semantics- aware Dataset Discovery from Data Lakes with Contextualized Column-based Representation Learning.Proc. VLDB Endow.16, 7 (2023), 1726–1739
2023
-
[16]
Yanlin Feng, Sajjadur Rahman, Aaron Feng, Vincent Chen, and Eser Kandogan
-
[17]
InGUIDE-AI@SIGMOD
CMDBench: A Benchmark for Coarse-to-fine Multimodal Data Discovery in Compound AI Systems. InGUIDE-AI@SIGMOD. 16–25
-
[18]
Raul Castro Fernandez, Ziawasch Abedjan, Famien Koko, Gina Yuan, Samuel Madden, and Michael Stonebraker. 2018. Aurum: A Data Discovery System. In ICDE. 1001–1012
2018
-
[19]
Xinyu Fu, Jiani Zhang, Ziqiao Meng, and Irwin King. 2020. Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding. InWWW. 2331–2341
2020
-
[20]
Sainyam Galhotra, Yue Gong, and Raul Castro Fernandez. 2023. Metam: Goal- Oriented Data Discovery. InICDE. 2780–2793
2023
-
[21]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation.Proc. VLDB Endow.17, 5 (2024), 1132–1145
2024
-
[22]
GPT-4. 2024. https://openai.com/research/gpt-4
2024
-
[23]
Zihui Gu, Ju Fan, Nan Tang, Preslav Nakov, Xiaoman Zhao, and Xiaoyong Du
-
[24]
PASTA: Table-Operations Aware Fact Verification via Sentence-Table Cloze Pre-training. InEMNLP. 4971–4983
-
[25]
Zihui Gu, Ruixue Fan, Xiaoman Zhao, Meihui Zhang, Ju Fan, and Xiaoyong Du
-
[26]
In SIGMOD
OpenTFV: An Open Domain Table-Based Fact Verification System. In SIGMOD. 2405–2408
-
[27]
Yuxiang Guo, Yuren Mao, Zhonghao Hu, Lu Chen, and Yunjun Gao. 2025. Snoopy: Effective and Efficient Semantic Join Discovery via Proxy Columns.IEEE Trans. Knowl. Data Eng.37, 5 (2025), 2971–2985
2025
-
[28]
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Martin Eisenschlos. 2020. TaPas: Weakly Supervised Table Parsing via Pre-training. InACL. 4320–4333
2020
-
[29]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InICLR
2022
-
[30]
Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. 2020. Heterogeneous Graph Transformer. InWWW. 2704–2710
2020
-
[31]
Miller, and Mirek Riedewald
Aamod Khatiwada, Grace Fan, Roee Shraga, Zixuan Chen, Wolfgang Gatter- bauer, Renée J. Miller, and Mirek Riedewald. 2023. SANTOS: Relationship-based Semantic Table Union Search.Proc. ACM Manag. Data1, 1 (2023), 9:1–9:25
2023
-
[32]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. InICRL
2017
-
[33]
Kezhi Kong, Jiani Zhang, Zhengyuan Shen, Balasubramaniam Srinivasan, Chuan Lei, Christos Faloutsos, Huzefa Rangwala, and George Karypis. 2024. OpenTab: Advancing Large Language Models as Open-domain Table Reasoners. InICLR
2024
-
[34]
Alyssa Lees, Luciano Barbosa, Flip Korn, Levy de Souza Silva, You Wu, and Cong Yu. 2021. Collocating News Articles with Structured Web Tables. InCompanion of The Web Conference. 393–401
2021
-
[35]
Fei Li and H. V. Jagadish. 2014. Constructing an Interactive Natural Language Interface for Relational Databases.Proc. VLDB Endow.8, 1 (2014), 73–84
2014
-
[36]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin Chen-Chuan Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. InNIPS
2023
-
[37]
Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2020. Approximate Nearest Neighbor Search on High Dimensional Data - Experiments, Analyses, and Improvement.IEEE Trans. Knowl. Data Eng. 32, 8 (2020), 1475–1488
2020
-
[38]
Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, and Jian-Guang Lou. 2022. TAPEX: Table Pre-training via Learning a Neural SQL Executor. InICLR
2022
-
[39]
Llama4-Scout. 2025. https://www.llama.com/models/llama-4/
2025
-
[40]
Miller, Ken Q
Fatemeh Nargesian, Erkang Zhu, Renée J. Miller, Ken Q. Pu, and Patricia C. Arocena. 2019. Data Lake Management: Challenges and Opportunities.Proc. VLDB Endow.12, 12 (2019), 1986–1989
2019
-
[41]
Pu, and Renée J
Fatemeh Nargesian, Erkang Zhu, Ken Q. Pu, and Renée J. Miller. 2018. Table Union Search on Open Data.Proc. VLDB Endow.11, 7 (2018), 813–825
2018
-
[42]
Vaishali Pal, Andrew Yates, Evangelos Kanoulas, and Maarten de Rijke. 2023. MultiTabQA: Generating Tabular Answers for Multi-Table Question Answering. InACL. 6322–6334
2023
-
[43]
Panupong Pasupat and Percy Liang. 2015. Compositional Semantic Parsing on Semi-Structured Tables. InACL. 1470–1480
2015
-
[44]
Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding, Kuansan Wang, and Jie Tang. 2020. Gcc: Graph contrastive coding for graph neural network pre-training. InKDD. 1150–1160
2020
-
[45]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.J. Mach. Learn. Res.21 (2020), 140:1–140:67
2020
-
[46]
Mandeep Rathee, Sean MacAvaney, and Avishek Anand. 2025. Guiding Retrieval Using LLM-Based Listwise Rankers. InECIR
2025
-
[47]
Robertson and Hugo Zaragoza
Stephen E. Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (2009), 333–389
2009
-
[48]
Mittal, and Fatma Özcan
Diptikalyan Saha, Avrilia Floratou, Karthik Sankaranarayanan, Umar Farooq Minhas, Ashish R. Mittal, and Fatma Özcan. 2016. ATHENA: An Ontology- Driven System for Natural Language Querying over Relational Data Stores.Proc. VLDB Endow.9, 12 (2016), 1209–1220
2016
-
[49]
Roee Shraga, Haggai Roitman, Guy Feigenblat, and Mustafa Canim. 2020. Web Table Retrieval using Multimodal Deep Learning. InSIGIR. 1399–1408
2020
-
[50]
Chang-Yu Tai, Ziru Chen, Tianshu Zhang, Xiang Deng, and Huan Sun. 2023. Exploring Chain of Thought Style Prompting for Text-to-SQL. InEMNLP. 5376– 5393
2023
-
[51]
Voorhees, Tetsuya Sakai, and Ian Soboroff
Rikiya Takehi, Ellen M. Voorhees, Tetsuya Sakai, and Ian Soboroff. 2025. LLM- Assisted Relevance Assessments: When Should We Ask LLMs for Help?. InSIGIR. 95–105
2025
-
[52]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InNIPS. 5998–6008
2017
-
[53]
Jin Wang, Yanlin Feng, Chen Shen, Sajjadur Rahman, and Eser Kandogan
- [54]
-
[55]
Qiming Wang and Raul Castro Fernandez. 2023. Solo: Data Discovery Using Natural Language Questions Via A Self-Supervised Approach.Proc. ACM Manag. Data1, 4 (2023), 262:1–262:27
2023
-
[56]
Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S. Yu. 2019. Heterogeneous Graph Attention Network. InWWW. 2022–2032
2019
-
[57]
Xiao Wang, Nian Liu, Hui Han, and Chuan Shi. 2021. Self-supervised heteroge- neous graph neural network with co-contrastive learning. InKDD. 1726–1736
2021
-
[58]
Jian Wu, Linyi Yang, Yuliang Ji, Wenhao Huang, Börje F. Karlsson, and Manabu Okumura. 2024. GenDec: A robust generative Question-decomposition method for Multi-hop reasoning.CoRRabs/2402.11166 (2024)
-
[59]
Jian Wu, Linyi Yang, Dongyuan Li, Yuliang Ji, Manabu Okumura, and Yue Zhang
-
[60]
MMQA: Evaluating LLMs with Multi-Table Multi-Hop Complex Questions. InICLR
-
[61]
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S. Yu. 2021. A Comprehensive Survey on Graph Neural Networks.IEEE Trans. Neural Networks Learn. Syst.32, 1 (2021), 4–24. Unified Data Discovery across Query Modalities and User Intents Conference acronym ’XX, June 03–05, 2018, Woodstock, NY
2021
-
[62]
Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. 2020. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. In ACL. 8413–8426
2020
-
[63]
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020. Graph contrastive learning with augmentations.Advances in neural information processing systems33 (2020), 5812–5823
2020
-
[64]
Chuxu Zhang, Dongjin Song, Chao Huang, Ananthram Swami, and Nitesh V. Chawla. 2019. Heterogeneous Graph Neural Network. InKDD. 793–803
2019
-
[65]
Hongzhi Zhang, Yingyao Wang, Sirui Wang, Xuezhi Cao, Fuzheng Zhang, and Zhongyuan Wang. 2020. Table Fact Verification with Structure-Aware Trans- former. InEMNLP. 1624–1629
2020
-
[66]
Shuo Zhang and Krisztian Balog. 2018. Ad Hoc Table Retrieval using Semantic Similarity. InWWW. 1553–1562
2018
-
[67]
Tianshu Zhang, Xiang Yue, Yifei Li, and Huan Sun. 2024. TableLlama: Towards Open Large Generalist Models for Tables. InNAACL. 6024–6044
2024
-
[68]
Yunjia Zhang, Jordan Henkel, Avrilia Floratou, Joyce Cahoon, Shaleen Deep, and Jignesh M. Patel. 2024. ReAcTable: Enhancing ReAct for Table Question Answering.Proc. VLDB Endow.17, 8 (2024), 1981–1994
2024
-
[69]
Yuxuan Zhou, Xien Liu, Kaiyin Zhou, and Ji Wu. 2022. Table-based Fact Verifica- tion with Self-adaptive Mixture of Experts. InFindings of ACL. 139–149
2022
-
[70]
#$ % "#$ &
Erkang Zhu, Dong Deng, Fatemeh Nargesian, and Renée J. Miller. 2019. JOSIE: Overlap Set Similarity Search for Finding Joinable Tables in Data Lakes. In SIGMOD. 847–864. Conference acronym ’XX, June 03–05, 2018, Woodstock, NYTingting Wang, Shixun Huang, Zhifeng Bao, J. Shane Culpepper, Shazia Sadiq, Volkan Dedeoglu, and Reza Arablouei A An Example for Join...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.