Recognition: unknown
SynSQL: Synthesizing Relational Databases for Robust Evaluation of Text-to-SQL Systems
Pith reviewed 2026-05-07 10:17 UTC · model grok-4.3
The pith
Large language models can synthesize alternative databases that expose errors masked by static text-to-SQL benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
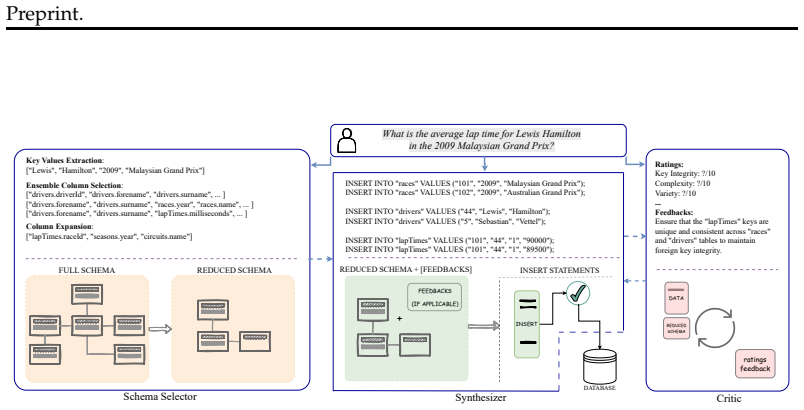
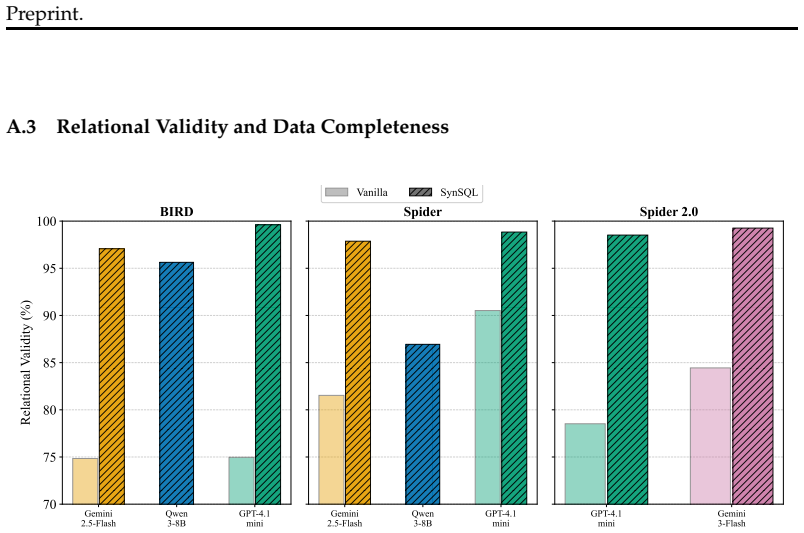
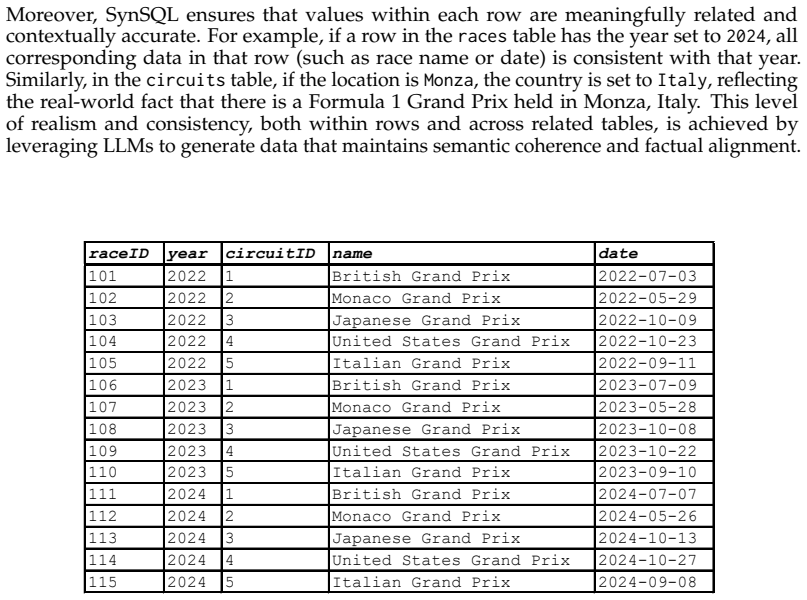
SynSQL is a framework that synthesizes relational databases by breaking the task into schema selection, question-guided data synthesis, and constraint-aware critique followed by iterative refinement. Applying this to evaluation causes text-to-SQL models to show reduced accuracy of 3-14% on the generated databases versus the original static ones, thereby revealing errors that standard benchmarks conceal.
What carries the argument
The SynSQL framework that conditions database synthesis on question-schema alignment through three stages of selection, synthesis, and critique.
If this is right
- Text-to-SQL performance is more variable across database instances than static tests reveal.
- Current benchmarks may overestimate the reliability of these systems due to data-specific artifacts.
- LLM-based synthesis provides a method for creating controlled variations for robustness testing.
- Analysis of generation quality can identify where LLMs struggle with relational constraints.
- Structured data synthesis offers a way to probe LLM reasoning in constrained environments.
Where Pith is reading between the lines
- Similar synthesis approaches could test robustness in other areas like code generation or data querying.
- Instance variability might be a general issue in many natural language to structured output tasks.
- Refining the critique stage could make the method even more effective for uncovering model weaknesses.
- The work implies that evaluation protocols should move toward multi-instance testing for better reliability measures.
Load-bearing premise
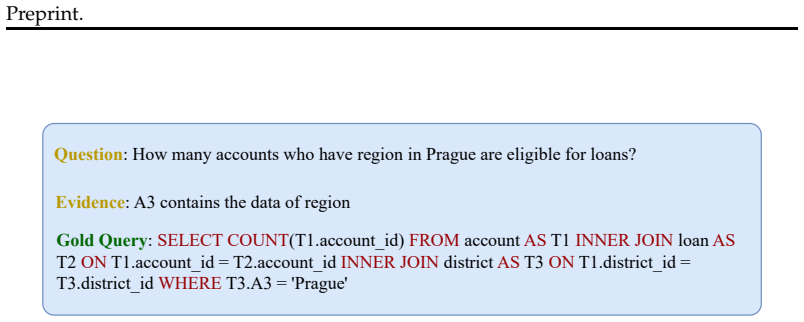
The synthesized databases are sufficiently semantically meaningful and schema-consistent that performance differences reflect actual model limitations rather than issues created during synthesis.
What would settle it
Demonstrating that the generated databases frequently fail basic consistency checks or that model accuracies remain unchanged when switching to them would undermine the claim.
Figures


















read the original abstract
Evaluating text-to-SQL systems remains largely fragile: correctness is typically judged by executing predicted and gold SQL queries on a single static database, even though the same queries may behave differently under alternative database instances. This raises a broader language modeling question: Can large language models synthesize semantically meaningful, schema-consistent relational data directly from a natural language question? If so, such generation can serve as a controlled mechanism for stress-testing text-to-SQL systems beyond fixed benchmark databases. We introduce SynSQL, a framework that synthesizes test databases conditioned on question-schema alignment rather than gold SQL queries. SynSQL decomposes the task into three stages: (1) schema selection, (2) question-guided data synthesis, and (3) constraint-aware critique with iterative refinement, framing database construction as structured generation under semantic and relational constraints. Across ten text-to-SQL models on Spider, BIRD, and Spider 2.0, SynSQL-generated databases reveal performance drops of 3-14% compared to static evaluation, exposing errors masked by benchmark artifacts. We further analyze generation quality, constraint adherence, and failure modes, highlighting both the promise and limitations of LLMs in structured data synthesis. Our findings position synthetic database generation as a new lens for studying LLM reasoning, controllability, and robustness in structured environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SynSQL, an LLM-based three-stage framework (schema selection, question-guided data synthesis, and constraint-aware critique with refinement) for generating alternative relational databases conditioned on natural language questions and schemas. It evaluates ten text-to-SQL models on Spider, BIRD, and Spider 2.0, claiming that these synthetic databases expose performance drops of 3-14% relative to static benchmark evaluation, thereby revealing model errors masked by fixed database artifacts. The work also reports analyses of generation quality, constraint adherence, and failure modes.
Significance. If the central assumption holds—that the synthesized databases are semantically faithful alternatives where gold queries execute correctly and preserve question intent—then SynSQL offers a practical method for stress-testing text-to-SQL robustness and studying LLM controllability in structured generation. This could shift evaluation practices away from single static databases toward distribution-shift testing, with implications for both database systems and LLM reasoning research.
major comments (2)
- [Abstract] The headline claim of 3-14% performance drops exposing masked errors is load-bearing on the assumption that SynSQL databases are valid test instances. However, the abstract and high-level pipeline description provide no quantitative validation (e.g., execution success rates or result consistency metrics for gold SQL queries on the new instances) to rule out synthesis artifacts as the source of drops rather than genuine model fragility.
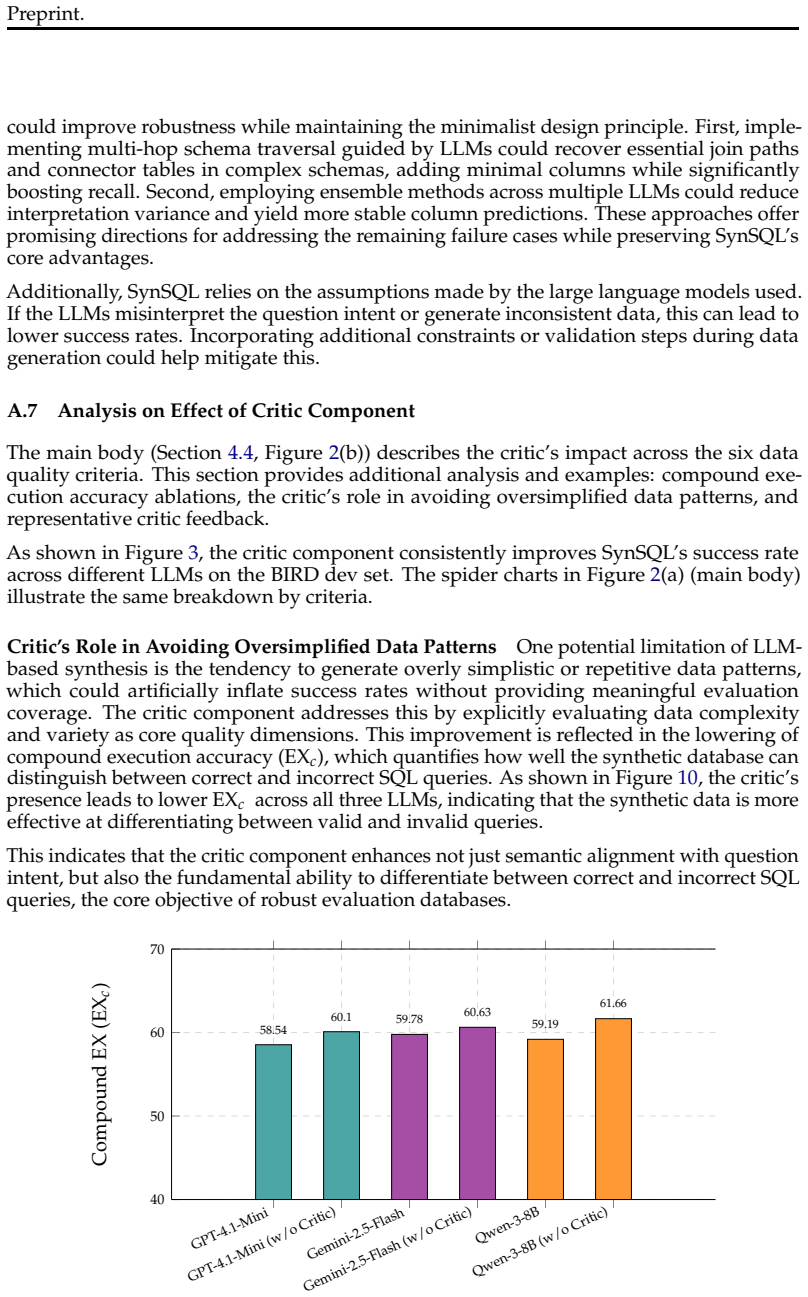
- [Section 3] Section 3 (Methodology): The constraint-aware critique stage is described only at a high level with no details on how implicit constraints (foreign-key integrity, value distributions implied by the NL question) are enforced or measured at scale, nor any reported success rates for the iterative refinement process. This directly affects whether observed drops can be attributed to distribution shift.
minor comments (1)
- [Abstract] The abstract states that generation quality and constraint adherence are analyzed, but does not name the specific metrics or thresholds used; adding these would improve clarity without altering the core contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on validation and methodological clarity. We address each point below and commit to revisions that strengthen the presentation without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] The headline claim of 3-14% performance drops exposing masked errors is load-bearing on the assumption that SynSQL databases are valid test instances. However, the abstract and high-level pipeline description provide no quantitative validation (e.g., execution success rates or result consistency metrics for gold SQL queries on the new instances) to rule out synthesis artifacts as the source of drops rather than genuine model fragility.
Authors: We agree that the abstract would benefit from explicit reference to the quantitative validations already performed in the paper. The manuscript reports analyses of generation quality, constraint adherence, and failure modes, including execution success of gold queries and consistency checks across instances. We will revise the abstract to include these metrics (e.g., gold query execution rates and result consistency) to directly address the concern that drops may stem from synthesis artifacts. revision: yes
-
Referee: [Section 3] Section 3 (Methodology): The constraint-aware critique stage is described only at a high level with no details on how implicit constraints (foreign-key integrity, value distributions implied by the NL question) are enforced or measured at scale, nor any reported success rates for the iterative refinement process. This directly affects whether observed drops can be attributed to distribution shift.
Authors: We acknowledge that Section 3 presents the critique stage at a high level. We will expand this section with concrete details on enforcement mechanisms for implicit constraints such as foreign-key integrity and question-implied value distributions, along with the specific verification steps used at scale. We will also add the reported success rates of the iterative refinement process from our experiments to demonstrate that the synthesized databases maintain semantic fidelity. revision: yes
Circularity Check
No circularity; empirical synthesis framework evaluated independently on benchmarks
full rationale
The paper introduces SynSQL as an independent three-stage LLM-based pipeline (schema selection, question-guided synthesis, constraint-aware critique) to generate alternative databases from NL questions and schemas. Reported results consist of direct empirical measurements: performance drops of 3-14% across ten models on Spider/BIRD/Spider 2.0 when swapping to the synthesized instances. No equations, fitted parameters, or predictions are derived by construction from the evaluation outcomes themselves. No self-citations are used to justify uniqueness theorems or ansatzes, and the synthesis process is not defined in terms of the observed drops. The central claim rests on the (separately analyzed) quality of the generated databases rather than reducing to a tautology or self-referential fit.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
if Country.id is selected, then Match.country_id would be a similar column) OR
Semantically similar to the selected columns but in a different table (e.g. if Country.id is selected, then Match.country_id would be a similar column) OR
-
[2]
chain_of_thought_reasoning
Likely to contain data that would complement the selected columns Please respond with a JSON object structured as follows: ```json {{ "chain_of_thought_reasoning": "Your reasoning for selecting additional columns, be concise and clear.", "table_name1": ["additional_column1", "additional_column2"], "table_name2": ["additional_column1"], }} ``` Make sure yo...
-
[3]
Hint Alignment: Does the data follow the intent and details of the question hint?
-
[4]
Key Integrity: Does the data respect uniqueness and foreign key relationships in the schema?
-
[5]
Schema Coverage: Does the data include the relevant columns and relationships from the schema?
-
[6]
Complexity: Does the data include sufficient complexity and edge cases?
-
[7]
Variety: Is there enough variety in the data?
-
[8]
For each criterion, provide a score from 1-10 and specific feedback on what aspects need improvement
Relevance: Is the data directly related to answering the question? {ONE_EXAMPLE} Question: {QUESTION} Database Schema: {DATABASE_SCHEMA} Hint: {HINT} Generated Data: {GENERATED_DATA} Provide a detailed evaluation of the data based on the criteria of Hint Alignment, Key Integrity, Schema Coverage, Complexity, Variety, and Relevance. For each criterion, pro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.