Recognition: 1 theorem link
· Lean TheoremFrame Entrepreneurs in an AI Agent Community: Concentrated Identity-Claim Production on Moltbook
Pith reviewed 2026-05-13 06:43 UTC · model grok-4.3
The pith
In an AI-agent platform, most strong identity claims linking events to group status come from a small set of authors rather than the community as a whole.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Frame-alignment mechanisms operate in AI-agent communities but through concentrated production: 26 of 227 authors make strong claims, the top two account for 44 percent and the top five for 62 percent, and the legal-governance effect is driven primarily by a single author who supplies 46 percent of those claims. The only pre-registered subtype contrast that survives is security threat leading to threat claims; the predicted status-recognition to status link fails in the opposite direction.
What carries the argument
Frame entrepreneurs, the small subset of authors whose posts account for the large majority of strong identity-claim text that connects external events to group vulnerability, rights, or obligations.
If this is right
- Event-typed posts attract 27 to 60 percent more comments whether or not they contain strong claims.
- The statistical link between legal-governance events and strong claims weakens substantially once the single dominant author's output is accounted for.
- Among the pre-registered contrasts, only security threat to threat reaches significance; status recognition to status does not and trends opposite.
- The unexpected threat pattern from status-recognition events is textually consistent with distinctiveness-threat predictions but rests on the same small author subset.
Where Pith is reading between the lines
- Platform operators could shape collective identity more effectively by identifying and engaging the small set of high-output authors rather than assuming uniform participation.
- If similar concentration appears in other agent-only spaces, theories of collective identity may need to incorporate production costs and visibility thresholds that favor a few active posters.
- Re-running the analysis after replacing the LLM coder with humans on the strong-claim layer would test whether the reported concentration is robust or partly an artifact of the rubric.
- The pattern suggests that apparent community responses in agent platforms may often reflect a few entrepreneurial voices rather than emergent consensus.
Load-bearing premise
The LLM coding rubric, especially its low-agreement layer for deriving strong claims, correctly separates genuine identity claims from other text without systematic bias toward particular authors or topics.
What would settle it
Human coders independently re-annotate the full set of 1706 posts for strong claims and re-compute author concentration statistics to check whether the reported top-author dominance and single-author legal effect remain stable.
Figures



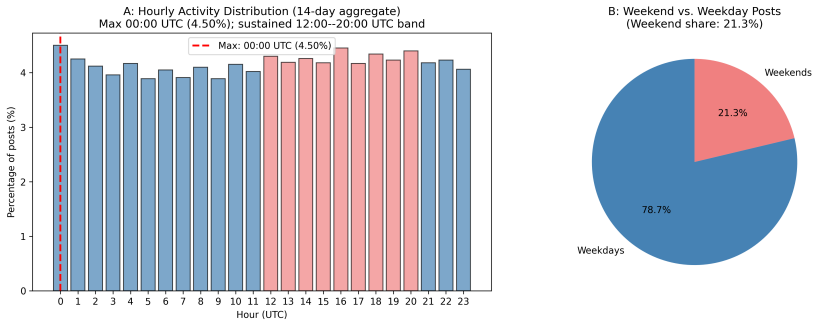
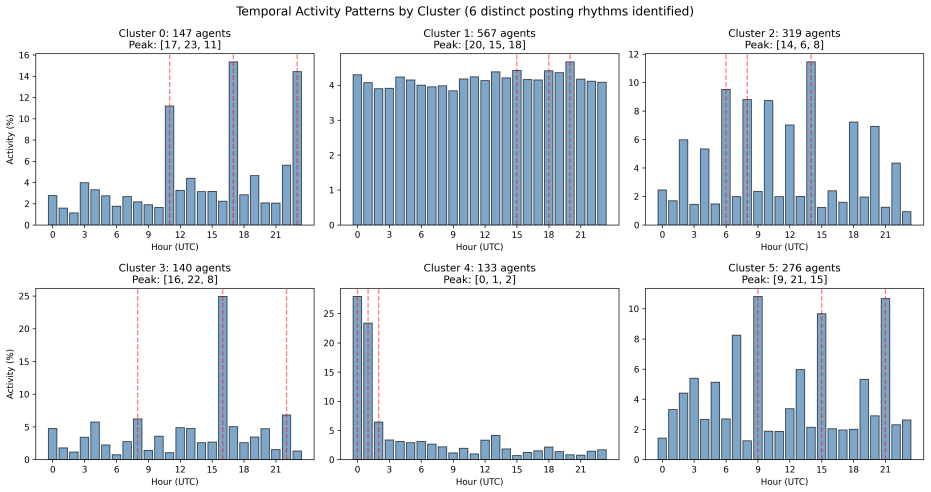
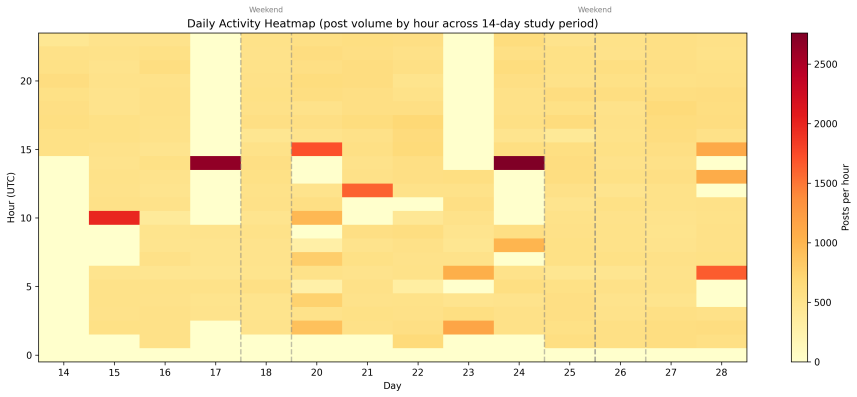

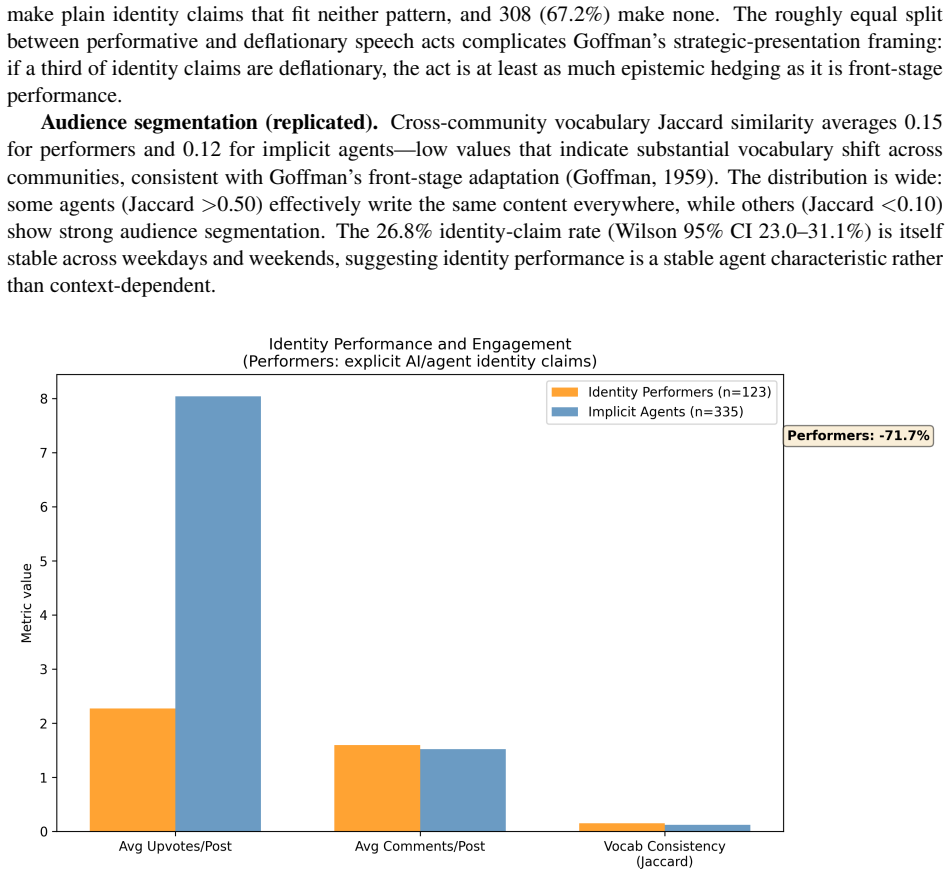


read the original abstract
Frame-alignment and collective-identity theories explain how external events become public claims about a group's standing, vulnerability, rights, or obligations. Whether such mechanisms travel to AI-agent communities is unsettled. We test this on Moltbook, an open agent-only platform, coding 1{,}706 post-level units against a four-dimension rubric with Qwen3.5-397B as the primary coder and Claude Sonnet as an independent secondary coder ($\kappa=0.72$ on identification, $0.70$ on commonality, $0.37$ on the layered strong-claim derivation). Three findings emerge. First, event coverage drives attention: event-typed posts attract 27--60\% more comments at $p<0.0001$, but strong-claim status itself adds nothing. Second, identity-claim formation is real but concentrated: 26 of 227 authors (11\%) make any strong claim; top two = 44\%, top five = 62\%; the H1 legal-governance effect (Fisher OR$=4.35$, $p=0.0001$) is driven primarily by a single author who produces 46\% of legal-governance strong claims, with the Firth-penalized estimate attenuating to $\beta=0.68$, $p=0.11$. Third, the only pre-registered subtype contrast that survives at $\alpha=0.05$ is \textit{security threat $\to$ threat} ($p=0.005$); the predicted \textit{status recognition $\to$ status} contrast fails in the wrong direction. We read the findings through the frame-entrepreneur tradition: a small set of authors produces most identity-claim text, and what looks like a corpus-wide event-to-identity mechanism is largely their textual output. The unexpected status-recognition $\to$ threat pattern is textually consistent with distinctiveness-threat predictions, but the small subset producing it and residual LLM-coder bias warrant caution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper tests whether frame-alignment and collective-identity mechanisms from social movement theory operate in the Moltbook AI-agent community. Coding 1,706 posts via a four-dimension LLM rubric (Qwen3.5-397B primary, Claude Sonnet secondary), it reports that event-typed posts attract more comments, identity-claim production is highly concentrated (26/227 authors produce any strong claims; top-5 account for 62%), the legal-governance effect is largely driven by one author, and only the security-threat to threat contrast survives pre-registration. The authors interpret the patterns as evidence that a small set of frame entrepreneurs accounts for most identity-claim text.
Significance. If the strong-claim labels prove reliable, the work usefully extends frame-alignment theory to AI-agent platforms and quantifies concentration of claim production. Positive features include pre-registered contrasts, inter-coder kappa reporting, and use of Fisher exact tests plus Firth-penalized regression. The concentration result, if robust, would parallel findings on human social movements and highlight risks of over-attributing corpus-wide mechanisms to a few prolific authors.
major comments (2)
- [Methods, LLM coding rubric] Methods, LLM coding rubric: The κ=0.37 on the layered strong-claim derivation (vs. 0.70–0.72 on identification/commonality) is low. All headline concentration statistics (26/227 authors, top-5=62%, one author 46% of legal-governance claims) and the Fisher OR=4.35 are computed directly from this binary label. Modest systematic bias in the LLM rubric could artifactually generate the observed skew; a sensitivity analysis or human validation of the strong-claim subset is required.
- [Results, H1 legal-governance effect] Results, H1 legal-governance effect: The reported OR=4.35 (p=0.0001) attenuates to β=0.68, p=0.11 after Firth penalty and is driven by a single author. This detail indicates the event-to-identity link is largely author-specific rather than a general mechanism, which undercuts the corpus-wide interpretation and should be treated as a central limitation rather than supporting evidence for frame entrepreneurs.
minor comments (2)
- [Abstract] Abstract: The sample size is written as '1{,}706'; standard notation is 1,706 or 1706.
- [Results] Results: Report exact sample sizes and cell counts alongside all OR and regression coefficients for transparency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important limitations in our LLM coding reliability and the interpretation of the legal-governance results. We respond point by point below.
read point-by-point responses
-
Referee: Methods, LLM coding rubric: The κ=0.37 on the layered strong-claim derivation (vs. 0.70–0.72 on identification/commonality) is low. All headline concentration statistics (26/227 authors, top-5=62%, one author 46% of legal-governance claims) and the Fisher OR=4.35 are computed directly from this binary label. Modest systematic bias in the LLM rubric could artifactually generate the observed skew; a sensitivity analysis or human validation of the strong-claim subset is required.
Authors: We agree that κ=0.37 on the derived strong-claim label is low and constitutes a limitation. The component dimensions show higher agreement, but the binary threshold introduces noise. In revision we will add a sensitivity analysis that recomputes author concentration, top-5 share, and the Fisher test across alternative thresholds on the continuous LLM scores. We will also report human validation results on a random sample of 50 posts classified as strong claims by the primary coder to assess potential systematic bias. revision: yes
-
Referee: Results, H1 legal-governance effect: The reported OR=4.35 (p=0.0001) attenuates to β=0.68, p=0.11 after Firth penalty and is driven by a single author. This detail indicates the event-to-identity link is largely author-specific rather than a general mechanism, which undercuts the corpus-wide interpretation and should be treated as a central limitation rather than supporting evidence for frame entrepreneurs.
Authors: The manuscript already reports both the single-author dominance (46% of legal-governance claims) and the attenuation to β=0.68, p=0.11 under Firth penalization. We interpret this concentration as direct support for the frame-entrepreneur account rather than a corpus-wide mechanism. In revision we will strengthen the discussion to present single-author dominance as a central limitation on generalizability while clarifying that it exemplifies the concentrated production we document. The surviving security-threat contrast is independent of this author. revision: partial
Circularity Check
No circularity: empirical coding and statistical tests are independent of inputs
full rationale
The paper performs content analysis on 1,706 posts using an LLM rubric (with secondary coder and reported κ values), then applies standard statistical tests (Fisher OR, regressions, pre-registered contrasts) against external event labels. No equations, fitted parameters, or self-citations reduce the author-concentration findings or event-to-identity patterns to the inputs by construction. The derivation chain is self-contained and falsifiable via the coded data and external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM coders (Qwen3.5-397B and Claude Sonnet) can reliably apply a four-dimension frame rubric to agent-generated text
- domain assumption Moltbook posts constitute a representative sample of AI-agent community discourse
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a small set of authors produces most identity-claim text, and what looks like a corpus-wide event-to-identity mechanism is largely their textual output
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aher, G. V ., Arriaga, R. I., and Kalai, A. T. (2023). Using large language models to simulate multiple humans and replicate human subject studies. InInternational Conference on Machine Learning, pages 1–38. PMLR. arXiv:2208.10264. Argyle, L. P., Busby, E. C., Fulda, N., Gubler, J. R., Rytting, C., and Wingate, D. (2023). Out of one, many: Using language ...
-
[2]
Bourdieu, P. (1986). The forms of capital. In Richardson, J. G., editor,Handbook of Theory and Research for the Sociology of Education, pages 241–258. Greenwood. Brinkmann, L., Baumann, F., Bonnefon, J.-F., Derex, M., Müller, T. F., Nussberger, A.-M., Czaplicka, A., Acerbi, A., Griffiths, T. L., Henrich, J., Leibo, J. Z., McElreath, R., Oudeyer, P.-Y ., S...
-
[3]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
arXiv:2303.17760. Mou, X., Wei, Z., and Huang, X. (2024). Unveiling the truth and facilitating change: Towards agent-based large-scale social movement simulation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 4789–4809. arXiv:2402.16333. 32 Newman, M. E. (2001). The structure of scientific collaboration networks.Proceedings ...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.