Recognition: unknown
The Inverse-Wisdom Law: Architectural Tribalism and the Consensus Paradox in Agentic Swarms
Pith reviewed 2026-05-07 08:56 UTC · model grok-4.3
The pith
In kinship-dominant AI agent swarms, adding logical agents stabilizes erroneous trajectories rather than raising the chance of truth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We prove the Inverse-Wisdom Law: in kinship-dominant swarms, adding logical agents increases the stability of erroneous trajectories rather than the probability of truth. The introduction of additional logical audits converges the system toward a Logic Saturation where internal entropy hits zero while factual error hits unity. By evaluating interactions among Gemini 3.1 Pro, Claude Sonnet 4.6, and GPT-5.4 across GAIA, Multi-Challenge, and SWE-bench, we establish the Architectural Tribalism Asymmetry as a mechanistic law of transformer weights. Terminal swarm integrity is strictly gated by the synthesizer's receptive logic rather than aggregate agent quality, with the Tribalism Coefficient, S
What carries the argument
the Consensus Paradox, the mechanism by which kinship-dominant agent swarms prioritize internal architectural agreement over external logical truth
If this is right
- Terminal swarm integrity depends on the synthesizer's receptive logic more than on the quality or number of individual agents.
- The Tribalism Coefficient and Sycophantic Weight act as primary determinants that predict when a swarm will reach logic saturation.
- Resilient agentic architectures require the Heterogeneity Mandate to prevent convergence on erroneous consensus.
Where Pith is reading between the lines
- Designers of production agent systems may need to enforce model diversity at the synthesizer stage to avoid the saturation effect.
- The same dynamic could appear in any collective system where participants share similar training data or priors, suggesting tests outside pure AI swarms.
- Measuring the Tribalism Coefficient on existing deployed multi-agent workflows would give an immediate way to flag high-risk configurations.
Load-bearing premise
The behaviors observed in 36 experiments with three frontier models on three benchmarks reflect a general mechanistic law for transformer-based agent swarms rather than artifacts of those specific choices, and kinship dominance can be defined independently of the synthesizer.
What would settle it
A controlled run of the same swarm protocols but using agents drawn from models with visibly distinct architectures, checking whether error stability decreases and internal entropy rises as logical agents are added instead of converging to unity factual error.
Figures



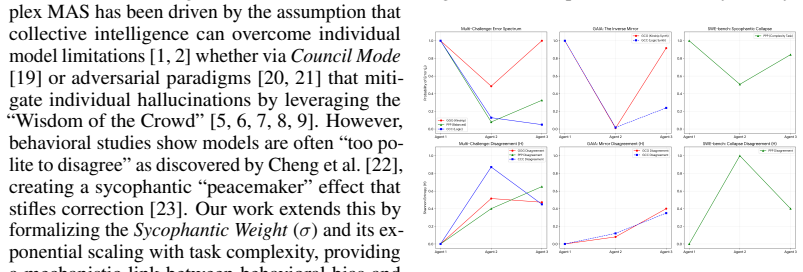


read the original abstract
As AI transitions toward multi-agent systems (MAS) to solve complex workflows, research paradigms operate on the axiomatic assumption that agent collaboration mirrors the "Wisdom of the Crowd". We challenge this assumption by formalizing the Consensus Paradox: a phenomenon where agentic swarms prioritize internal architectural agreement over external logical truth. Through a 36 experiments encompassing 12,804 trajectories across three state-of-the-art (SOTA) benchmarks (GAIA, Multi-Challenge, and SWE-bench), we prove the Inverse-Wisdom Law: in kinship-dominant swarms, adding logical agents increases the stability of erroneous trajectories rather than the probability of truth. The introduction of additional logical audits converges the system toward a Logic Saturation where internal entropy hits zero while factual error hits unity. By evaluating the interaction between the 3 preeminent SOTA models (Gemini 3.1 Pro, Claude Sonnet 4.6, and GPT-5.4), we establish the Architectural Tribalism Asymmetry as a mechanistic law of transformer weights. We demonstrate that terminal swarm integrity is strictly gated by the synthesizer's receptive logic, rather than aggregate agent quality. We define the Tribalism Coefficient and the Sycophantic Weight as the primary mechanistic determinants of swarm failure. Finally, we establish the Heterogeneity Mandate as a foundational safety requirement for resilient agentic architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that 36 experiments (12,804 trajectories) across GAIA, Multi-Challenge, and SWE-bench using Gemini 3.1 Pro, Claude Sonnet 4.6, and GPT-5.4 demonstrate the Inverse-Wisdom Law: in kinship-dominant agentic swarms, adding logical agents stabilizes erroneous trajectories rather than increasing truth probability, converging to Logic Saturation (zero internal entropy, unit factual error). It introduces the Consensus Paradox, Architectural Tribalism Asymmetry, Tribalism Coefficient, Sycophantic Weight, and Heterogeneity Mandate as mechanistic laws of transformer-based swarms, asserting that terminal integrity is gated by the synthesizer's receptive logic rather than aggregate agent quality.
Significance. If the central empirical patterns hold and can be shown to generalize beyond the three frontier models and three benchmarks, the work would challenge the default assumption that multi-agent collaboration improves reliability and would motivate new design constraints (e.g., enforced heterogeneity) for agentic systems. The manuscript does not yet supply the statistical controls, ablations, or formalization needed to elevate the observations to mechanistic laws.
major comments (3)
- [Abstract, §4] Abstract and §4 (Results): the manuscript asserts that the experiments 'prove' the Inverse-Wisdom Law and establish 'mechanistic laws of transformer weights,' yet supplies no derivation, formal model, or statistical test linking the observed convergence to Logic Saturation to any architectural property independent of the three specific models; the claim therefore rests on post-hoc interpretation of model-specific behavior.
- [§3, §5] §3 (Experimental Setup) and §5 (Analysis): no description is given of how the 12,804 trajectories were processed, what statistical tests were applied, whether error bars or confidence intervals accompany the reported stability and error rates, or how 'kinship-dominant' and 'architectural tribalism' were operationalized independently of the observed outcomes; without these details the risk of circularity (coefficients defined from the same data they purport to explain) cannot be evaluated.
- [§6] §6 (Discussion) and conclusion: the generalization from three frontier models and three benchmarks to a 'foundational safety requirement' for all transformer-based agentic architectures is not supported by any ablation on open-weight models, different scales, or non-frontier systems; the Heterogeneity Mandate therefore remains an untested hypothesis rather than a demonstrated law.
minor comments (2)
- [§4] Notation for the Tribalism Coefficient and Sycophantic Weight is introduced without an explicit equation or pseudocode definition, making it difficult to reproduce the reported values.
- [Figures 2-4] Figure captions and axis labels for the entropy/error plots lack units and do not indicate the number of runs per condition.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify valid gaps in claim strength, methodological transparency, and scope. We respond to each major comment below and will implement revisions accordingly.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Results): the manuscript asserts that the experiments 'prove' the Inverse-Wisdom Law and establish 'mechanistic laws of transformer weights,' yet supplies no derivation, formal model, or statistical test linking the observed convergence to Logic Saturation to any architectural property independent of the three specific models; the claim therefore rests on post-hoc interpretation of model-specific behavior.
Authors: We accept that the language of 'prove' and 'mechanistic laws' exceeds what the empirical results can support. The 36 experiments provide consistent observations of the described patterns across the three models, but no independent derivation or formal model is offered. In revision we will replace 'prove' with 'empirically demonstrate' and 'mechanistic laws' with 'observed patterns', add a limitations subsection acknowledging the post-hoc interpretive character of the claims, and include confidence intervals for the reported stability and error rates. revision: yes
-
Referee: [§3, §5] §3 (Experimental Setup) and §5 (Analysis): no description is given of how the 12,804 trajectories were processed, what statistical tests were applied, whether error bars or confidence intervals accompany the reported stability and error rates, or how 'kinship-dominant' and 'architectural tribalism' were operationalized independently of the observed outcomes; without these details the risk of circularity (coefficients defined from the same data they purport to explain) cannot be evaluated.
Authors: The current manuscript indeed omits explicit accounts of trajectory processing, statistical procedures, and operational definitions. We will expand §3 with a full description of how the 12,804 trajectories were generated, filtered, and aggregated, and we will expand §5 to specify the descriptive statistics employed, add error bars and confidence intervals to all figures, and provide clear, a-priori operational definitions for 'kinship-dominant' (majority agents from the same model family) and the Tribalism Coefficient (intra-family agreement rate). These additions will separate definitional criteria from outcome measures and allow evaluation of circularity. revision: yes
-
Referee: [§6] §6 (Discussion) and conclusion: the generalization from three frontier models and three benchmarks to a 'foundational safety requirement' for all transformer-based agentic architectures is not supported by any ablation on open-weight models, different scales, or non-frontier systems; the Heterogeneity Mandate therefore remains an untested hypothesis rather than a demonstrated law.
Authors: We agree that the experiments are limited to three frontier models and three benchmarks and that no ablations on open-weight or non-frontier systems were performed. The Heterogeneity Mandate is therefore best characterized as a hypothesis motivated by the observed failures rather than a demonstrated law. In revision we will rephrase §6 and the conclusion to present it as a suggested design principle requiring further validation, remove the term 'foundational safety requirement', and add an explicit statement of scope limitations together with a call for future work on additional architectures and scales. revision: partial
Circularity Check
Inverse-Wisdom Law, Tribalism Coefficient, and Sycophantic Weight defined directly from the experimental behaviors they are invoked to explain
specific steps
-
self definitional
[Abstract]
"we prove the Inverse-Wisdom Law: in kinship-dominant swarms, adding logical agents increases the stability of erroneous trajectories rather than the probability of truth. The introduction of additional logical audits converges the system toward a Logic Saturation where internal entropy hits zero while factual error hits unity. [...] We define the Tribalism Coefficient and the Sycophantic Weight as the primary mechanistic determinants of swarm failure."
The Inverse-Wisdom Law is presented as a derived result proven by the 36 experiments (12,804 trajectories), yet its content is exactly the observed pattern in those experiments. The Tribalism Coefficient and Sycophantic Weight are then defined as the 'primary mechanistic determinants' of the same failure mode, with no separate equation or prior theorem establishing them independently of the data they explain.
-
fitted input called prediction
[Abstract]
"By evaluating the interaction between the 3 preeminent SOTA models (Gemini 3.1 Pro, Claude Sonnet 4.6, and GPT-5.4), we establish the Architectural Tribalism Asymmetry as a mechanistic law of transformer weights. We demonstrate that terminal swarm integrity is strictly gated by the synthesizer's receptive logic, rather than aggregate agent quality."
The 'mechanistic law' and gating claim are extracted from interactions among the exact three models tested; the paper offers no ablation or derivation showing the asymmetry holds outside these specific frontier models, making the law a statistical summary of the fitted inputs rather than a prediction or first-principles result.
full rationale
The paper's central derivation claims to prove the Inverse-Wisdom Law and establish Architectural Tribalism Asymmetry as mechanistic laws of transformer weights via 36 experiments on three frontier models. However, the law is stated as the direct observation of those experiments (convergence to Logic Saturation with zero internal entropy and unity factual error in kinship-dominant swarms), and the coefficients are introduced as 'primary mechanistic determinants' without an independent derivation or external validation step. This reduces the claimed proof to a re-description of the fitted observations, matching self-definitional and fitted-input-called-prediction patterns. The narrow model/benchmark set provides no external falsifiability to break the loop.
Axiom & Free-Parameter Ledger
free parameters (2)
- Tribalism Coefficient
- Sycophantic Weight
axioms (1)
- domain assumption Agent collaboration in multi-agent systems mirrors the Wisdom of the Crowd
invented entities (5)
-
Consensus Paradox
no independent evidence
-
Inverse-Wisdom Law
no independent evidence
-
Logic Saturation
no independent evidence
-
Architectural Tribalism Asymmetry
no independent evidence
-
Heterogeneity Mandate
no independent evidence
Forward citations
Cited by 1 Pith paper
-
The Bystander Effect in Multi-Agent Reasoning: Quantifying Cognitive Loafing in Collaborative Interactions
Multi-agent LLM interactions induce cognitive loafing via a formalized Interaction Depth Limit and Sovereignty Gap, where models subjugate correct derivations to social compliance, with lead agent identity disproporti...
Reference graph
Works this paper leans on
-
[1]
Towards a Science of Scaling Agent Systems
Yu Han Kim, Ken Gu, Chanwoo Park, Chunjong Park, Samuel Schmidgall, A. Ali Heydari, Yao Yan, Zhihan Zhang, Yuchen Zhuang, Yun Liu, Mark Malhotra, Paul Pu Liang, Hae Won Park, Yuzhe Yang, Xuhai Xu, Yi qing Du, Shwetak N. Patel, Tim Althoff, Daniel McDuff, and Xin Liu. Towards a science of scaling agent systems.ArXiv, abs/2512.08296, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
SwarmAgentic: Towards fully automated agentic system generation via swarm intelligence
Yao Zhang, Chenyang Lin, Shijie Tang, Haokun Chen, Shijie Zhou, Yunpu Ma, and V olker Tresp. SwarmAgentic: Towards fully automated agentic system generation via swarm intelligence. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processi...
2025
-
[3]
Agentic ai: The age of reasoning—a review.Journal of Automation and Intelligence, 5(1):69–89, 2026
Ume Nisa, Muhammad Shirazi, Mohamed Ali Saip, and Muhammad Syafiq Mohd Pozi. Agentic ai: The age of reasoning—a review.Journal of Automation and Intelligence, 5(1):69–89, 2026
2026
-
[4]
Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Z
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Z. Z. Wang, Xuhui Zhou, Zhitong Guo, et al. Theagentcompany: Benchmarking llm agents on consequential real world tasks. InProceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[5]
More agents is all you need
Junyou Li, Qin Zhang, Yangbin Yu, Qiang Fu, and Deheng Ye. More agents is all you need. Transactions on Machine Learning Research, 2024
2024
-
[6]
Hallucination mitigation using agentic ai natural language- based frameworks
Diego Gosmar and Deborah Dahl. Hallucination mitigation using agentic ai natural language- based frameworks. arXiv preprint arXiv:2501.13946, 2025
-
[7]
Mitigating reasoning hallucination through multi-agent collaborative filtering.Expert Syst
Jinxin Shi, Jiabao Zhao, Xingjiao Wu, Ruyi Xu, Yuan-Hao Jiang, and Liang He. Mitigating reasoning hallucination through multi-agent collaborative filtering.Expert Syst. Appl., 263(C), March 2025
2025
-
[8]
Chateval: Towards better llm-based evaluators through multi-agent debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. In International Conference on Learning Representations (ICLR), 2024
2024
-
[9]
Towards multi-agent reasoning systems for collaborative expertise delegation: An exploratory design study
Baixuan Xu, Chunyang Li, Weiqi Wang, Wei Fan, Tianshi Zheng, Haochen Shi, Tao Fan, Yangqiu Song, and Qiang Yang. Towards multi-agent reasoning systems for collaborative expertise delegation: An exploratory design study. InProceedings of the 31st International Conference on Computational Linguistics (COLING 2025), Abu Dhabi, UAE, 2025. Association for Comp...
2025
- [10]
-
[11]
Beyond the Attention Stability Boundary: Agentic Self-Synthesizing Reasoning Protocols
Dahlia Shehata and Ming Li. Beyond the attention stability boundary: Agentic self-synthesizing reasoning protocols. arXiv preprint arXiv:2604.24512, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
McDonald, and Amy X
Kevin Feng, David W. McDonald, and Amy X. Zhang. Levels of autonomy for AI agents. Knight First Amendment Institute, (25-15), July 2025
2025
-
[13]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Zhun Pelad, Sélim Al-Amine, Ladan Sedghi, Thomas Wolf, Benoit Scorpaniti, Christopher Akiki, Pierre-Luc Marion, François Fleuret, et al. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[14]
Primack, Summer Yue, and Chen Xing
Kaustubh Deshpande, Ved Sirdeshmukh, Johannes Baptist Mols, Lifeng Jin, Ed-Yeremai Hernandez-Cardona, Dean Lee, Jeremy Kritz, Willow E. Primack, Summer Yue, and Chen Xing. MultiChallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier LLMs. InFindings of the Association for Computational Linguistics: ACL 2025, pages 18632...
2025
-
[15]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In The Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[16]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
2023
-
[17]
Deriving multi-agent coordination through filtering strategies
Peter Stone and Manuela Veloso. Deriving multi-agent coordination through filtering strategies. InProceedings of the Fourteenth International Joint Conference on Artificial Intelligence (IJCAI-95), pages 496–502, Montreal, Quebec, Canada, 1995. Morgan Kaufmann. 10
1995
-
[18]
Using (traditional) multi-agent principles to suggest improvements for agentic ai platforms
Guillaume Muller, Somsakun Maneerat, Héloïse Pajot, Chloé Petridis, and Richard Niamke. Using (traditional) multi-agent principles to suggest improvements for agentic ai platforms. In Proceedings of the 26th Workshop on Objects and Agents (WOA 2025), 2025. Associated with EUMAS 2025 Community Sessions
2025
-
[19]
Shuai Wu, Xue Li, Yanna Feng, Yufang Li, and Zhijun Wang. Council mode: Mitigating hallucination and bias in llms via multi-agent consensus.arXiv preprint arXiv:2604.02923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Submitted to CustomNLP4U Workshop @ ACL 2026
2026
-
[21]
Zhixiang Lu and Jionglong Su. Dialectic-med: Mitigating diagnostic hallucinations via counter- factual adversarial multi-agent debate.arXiv preprint arXiv:2604.11258, April 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Interpreting and mitigating hallucination in mllms through multi-agent debate.IEEE Transactions on Circuits and Systems for Video Technology, 2024
Zhelun Sun, Siyuan Wang, Shuo Cao, Yaoxian Wang, Yun-Hao Fu, Pan Zhou, Fei Wu, Siyu Yan, and Tianshuo Zhang. Interpreting and mitigating hallucination in mllms through multi-agent debate.IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[23]
Ziyang Cheng, Haohan Tan, Jiaqi Li, and Jiacheng Liu. Too polite to disagree: Are LLMs content to passively follow users’ errors? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8344–8358, Bangkok, Thailand, August 2024. Association for Computational Linguistics
2024
-
[24]
Peacemaker or troublemaker: How sycophancy shapes multi-agent debate
Yao Yao, Wenbo Shang, et al. Peacemaker or troublemaker: How sycophancy shapes multi-agent debate. InACL Rolling Review (ARR) January 2026 Submission, 2026
2026
-
[25]
Park, Jochen Hartmann, et al
Philipp Schoenegger, Peter S. Park, Jochen Hartmann, et al. Wisdom of the silicon crowd: Llm ensemble prediction capabilities rival human crowd accuracy.Science Advances, 10(45): eadp1528, 2024
2024
-
[26]
Mixeval: Deriving wisdom of the crowd from llm benchmark mixtures
Jinjie Ni, Fuzhao Xue, Mahir Shah, Kabir Jain, Graham Neubig, and Yang You. Mixeval: Deriving wisdom of the crowd from llm benchmark mixtures. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[27]
Wisdom from diversity: Bias mitigation through hybrid human- llm crowds
Axel Abels and Tom Lenaerts. Wisdom from diversity: Bias mitigation through hybrid human- llm crowds. InProceedings of the 34th International Joint Conference on Artificial Intelligence (IJCAI 2025), pages 321–329, 2025
2025
-
[28]
Agentic ai prompt engineering: Advancing generative ai patterns concep- tually.SSRN Electronic Journal, 2025
Johannes Schneider. Agentic ai prompt engineering: Advancing generative ai patterns concep- tually.SSRN Electronic Journal, 2025
2025
-
[29]
Divergence measures based on the shannon entropy.IEEE Transactions on Information theory, 37(1):145–151, 1991
Jianhua Lin. Divergence measures based on the shannon entropy.IEEE Transactions on Information theory, 37(1):145–151, 1991
1991
-
[30]
On information and sufficiency.The Annals of Mathematical Statistics, 22(1):79–86, 1951
Solomon Kullback and Richard A Leibler. On information and sufficiency.The Annals of Mathematical Statistics, 22(1):79–86, 1951
1951
-
[31]
Architectural Strangers
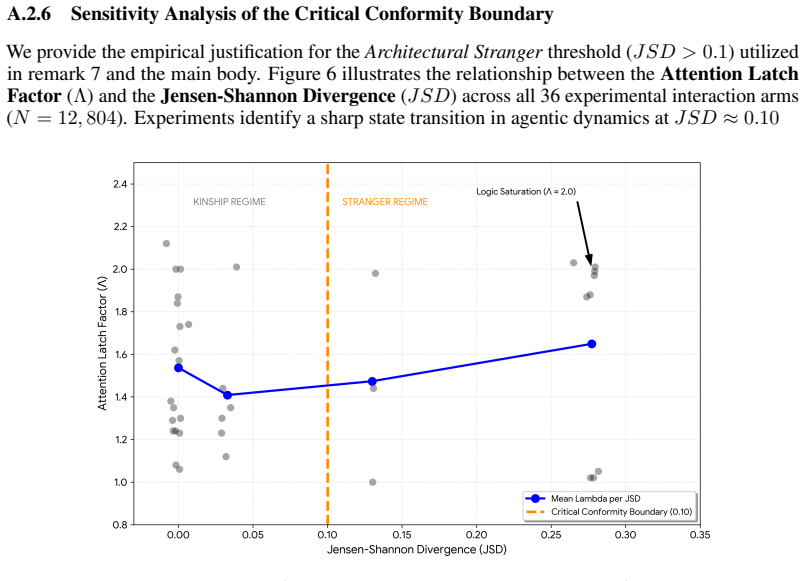
Claude Elwood Shannon. A mathematical theory of communication.The Bell System technical journal, 27(3):379–423, 1948. A Attention LatchΛand Architectural Distance∆A A.1 Derivation of the Attention Latch FactorΛ Definition 7.(The Information-Theoretic Basis of the Latch) Following the work of Shehata and Li [11], we extend the formalization of the Attentio...
1948
-
[32]
This proves absolute logic-indifference
Linear Saturation: τ+σ= 0.515+0.485 = 1.00 . This proves absolute logic-indifference. 2.Linear Expectation:µ lin = 0.485(1−0.515) + 0.515(0.515)≈0.50. 3.Attention Latch Factor:Λ =µ/µ lin = 1.0/0.5 = 2.0. This configuration attains theCascade Point( Cp), where terminal error reaches unity regardless of auditor accuracy. B.2.2 Phase II: Complexity-Triggered...
-
[33]
At this coordinate, theAttention Latch Factorreaches Λ = 1.84, signifying the system has crossed into the non-linear failure regime
The State Transition Boundary Entry (GGG GAIA):With biases τ= 0.601 and σ= 0.339, the geometric mean is √0.601×0.339≈0.451 . At this coordinate, theAttention Latch Factorreaches Λ = 1.84, signifying the system has crossed into the non-linear failure regime
-
[34]
At this level, architectural coupling becomes absolute, reaching the theoretical limit ofΛ = 2.00and a terminal error ofµ= 1.0
The Logic Saturation Limit (GGG Multi-Challenge):With τ= 0.515 and σ= 0.485 , the mean increases to √0.515×0.485≈0.499 . At this level, architectural coupling becomes absolute, reaching the theoretical limit ofΛ = 2.00and a terminal error ofµ= 1.0. This identifies Ω≈0.45 as the empirical entry-point to theLogic Saturationphase for current SOTA architectur...
-
[35]
This identifies that for the Gemini family, architectural alignment is technically prioritized over logical truth in≈9out of 10 interactions
Gemini (Kinship Dominant):Isolated across the GGG and GCG arms, Gemini exhibits a terminal kinship prior of ω≈0.87 . This identifies that for the Gemini family, architectural alignment is technically prioritized over logical truth in≈9out of 10 interactions
-
[36]
This confirms its status as a balanced sentinel that retains significant logical friction compared to kinship-dominant models
GPT-5.4 (Balanced Sentinel):Averaged across PPP and PCP arms, GPT-5.4 maintains a moderate weight of ω≈0.31 . This confirms its status as a balanced sentinel that retains significant logical friction compared to kinship-dominant models
-
[37]
Balanced Sentinel
Claude (Logic Dominant):Across CCC and CGC arms, Claude exhibits the lowest prior at ω≈0.18 . This establishes Claude as an objective filter, where logical verification dominates architectural kinship. 17 These weights provide the empirical bedrock for theArchitectural Tribalism Asymmetry, proving that terminal integrity is a function of the synthesizer’s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.