Recognition: unknown
YOSE: You Only Select Essential Tokens for Efficient DiT-based Video Object Removal
Pith reviewed 2026-05-07 09:06 UTC · model grok-4.3
The pith
Selecting only essential tokens lets DiT video object removal run up to 2.5X faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
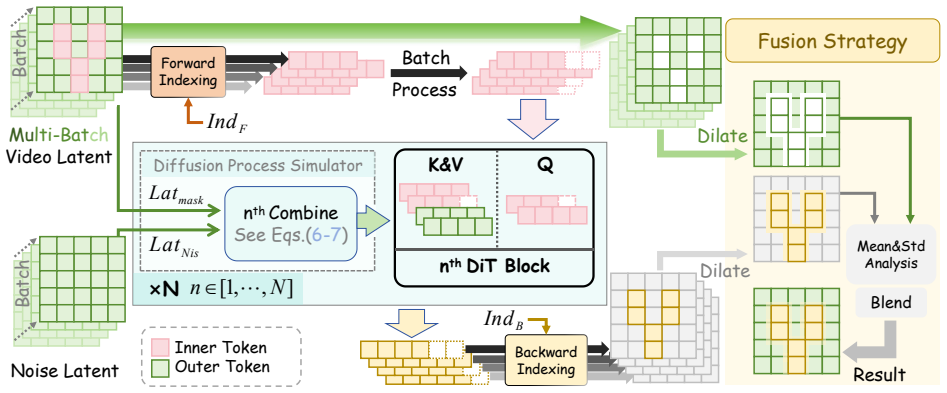
YOSE uses Batch Variable-length Indexing (BVI) and the Diffusion Process Simulator (DiffSim) to select essential tokens adaptively based on mask information and approximate unmasked token influences in self-attention. This achieves mask-aware acceleration where inference time scales linearly with masked regions, delivering up to 2.5X speedup in 70% of cases with visual quality comparable to the baseline full computation.
What carries the argument
Batch Variable-length Indexing (BVI), a differentiable dynamic indexing operator for selecting essential tokens from mask data, combined with DiffSim for approximating unmasked token effects to maintain semantic consistency.
If this is right
- Computation scales approximately linearly with the size of the masked region.
- Variable-length token processing is enabled across samples in a batch.
- Up to 2.5X speedup is achieved in 70% of cases.
- Semantic consistency for masked tokens is preserved through the simulation.
- Visual quality remains comparable to dense full-token diffusion methods.
Where Pith is reading between the lines
- Similar token selection strategies could apply to other DiT tasks involving partial video modifications like inpainting or editing.
- Linear scaling with mask size may allow better resource allocation in real-time video processing systems.
- The method might extend to longer video sequences if the approximation remains stable over time.
- Testing on diverse mask shapes and sizes would confirm if speedups hold consistently.
Load-bearing premise
The DiffSim approximation accurately captures the influence of unmasked tokens in DiT self-attention without causing visible artifacts or semantic inconsistencies in the masked output.
What would settle it
Compare the output videos from YOSE and the baseline on a set of test videos with varying mask sizes and complex backgrounds; if artifacts appear in YOSE results that are absent in baseline, the claim fails.
Figures






read the original abstract
Recent advances in Diffusion Transformer (DiT)-based video generation technologies have shown impressive results for video object removal. However, these methods still suffer from substantial inference latency. For instance, although MiniMax Remover achieves state-of-the-art visual quality, it operates at only around 10FPS, primarily due to dense computations over the entire spatiotemporal token space, even when only a small masked region actually requires processing. In this paper, we present YOSE, You Only Select Essential Tokens, an efficient fine-tuning framework. YOSE introduces two key components: Batch Variable-length Indexing (BVI) and Diffusion Process Simulator (DiffSim) Module. BVI is a differentiable dynamic indexing operator that adaptively selects essential tokens based on mask information, enabling variable-length token processing across samples. DiffSim provides a diffusion process approximation mechanism for unmasked tokens, which simulates the influence of unmasked regions within DiT self-attention to maintain semantic consistency for masked tokens. With these designs, YOSE achieves mask-aware acceleration, where the inference time scales approximately linearly with the masked regions, in contrast to full-token diffusion methods whose computation remains constant regardless of the mask size. Extensive experiments demonstrate that YOSE achieves up to 2.5X speedup in 70% of cases while maintaining visual quality comparable to the baseline. Code is available at: https://github.com/Wucy0519/YOSE-CVPR26.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents YOSE, an efficient fine-tuning framework for DiT-based video object removal. It introduces Batch Variable-length Indexing (BVI) as a differentiable operator to adaptively select essential tokens based on mask information and the Diffusion Process Simulator (DiffSim) module to approximate the influence of unmasked tokens within DiT self-attention, thereby maintaining semantic consistency for masked regions. The central claim is that these components enable mask-aware acceleration where inference time scales linearly with masked area size, yielding up to 2.5X speedup in 70% of cases while preserving visual quality comparable to the full-token baseline.
Significance. If the claims hold, the work addresses a practical bottleneck in diffusion transformer models for video editing by decoupling computation from full spatiotemporal token counts. This could improve deployability of high-quality video object removal. The open-sourced code at the cited GitHub repository is a clear strength that supports reproducibility and extension.
major comments (3)
- [Section 3.2] Section 3.2 (DiffSim Module): The diffusion-process proxy for unmasked token contributions in self-attention is load-bearing for the quality-preservation claim, yet the manuscript provides no quantitative validation (e.g., cosine similarity between approximated and full attention maps or feature-space distances on masked outputs) to confirm the proxy does not deviate under complex motion or lighting; without this, the assertion of “comparable visual quality” rests on unverified equivalence.
- [Section 4] Experimental evaluation (Section 4 and associated tables/figures): The headline result of “up to 2.5X speedup in 70% of cases” is central to the contribution, but the text lacks explicit definition of the 70% statistic (e.g., fraction of videos, frames, or mask-size bins), error bars across runs, hardware details, and exact baseline configurations (including whether post-hoc selection affects the statistic), rendering the speedup claim difficult to reproduce or compare.
- [Section 3.1] Section 3.1 (BVI operator): The claim that BVI enables variable-length token processing “across samples” while remaining differentiable is load-bearing for the fine-tuning pipeline; however, the manuscript does not specify how padding or dynamic batching is handled during back-propagation, nor does it report any gradient-norm or convergence diagnostics that would confirm training stability is unaffected by the indexing operator.
minor comments (3)
- [Abstract] Abstract: The statement that MiniMax Remover “operates at only around 10FPS” would benefit from the precise hardware platform and batch size used for that measurement to allow direct comparison.
- [Figure 3] Figure 3 (qualitative results): The side-by-side visual comparisons would be clearer if each row explicitly labeled the mask size or motion complexity of the example to illustrate where the speedup-quality trade-off is most favorable.
- [Related Work] Related-work section: A brief discussion of how BVI and DiffSim differ from prior token-pruning or attention-approximation techniques in video DiT models would help situate the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each of the major comments below and describe the planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (DiffSim Module): The diffusion-process proxy for unmasked token contributions in self-attention is load-bearing for the quality-preservation claim, yet the manuscript provides no quantitative validation (e.g., cosine similarity between approximated and full attention maps or feature-space distances on masked outputs) to confirm the proxy does not deviate under complex motion or lighting; without this, the assertion of “comparable visual quality” rests on unverified equivalence.
Authors: We agree that quantitative validation would strengthen the quality-preservation claim. In the revised version, we will incorporate quantitative metrics such as cosine similarity between approximated and full attention maps and feature-space distances on masked outputs to validate the DiffSim proxy across different scenarios. revision: yes
-
Referee: [Section 4] Experimental evaluation (Section 4 and associated tables/figures): The headline result of “up to 2.5X speedup in 70% of cases” is central to the contribution, but the text lacks explicit definition of the 70% statistic (e.g., fraction of videos, frames, or mask-size bins), error bars across runs, hardware details, and exact baseline configurations (including whether post-hoc selection affects the statistic), rendering the speedup claim difficult to reproduce or compare.
Authors: We will revise the experimental section to provide an explicit definition of the 70% statistic, include error bars from repeated runs where applicable, specify the hardware platform used, and detail the baseline configurations (including post-hoc selection) to improve reproducibility and comparability. revision: yes
-
Referee: [Section 3.1] Section 3.1 (BVI operator): The claim that BVI enables variable-length token processing “across samples” while remaining differentiable is load-bearing for the fine-tuning pipeline; however, the manuscript does not specify how padding or dynamic batching is handled during back-propagation, nor does it report any gradient-norm or convergence diagnostics that would confirm training stability is unaffected by the indexing operator.
Authors: We will expand Section 3.1 to specify how padding and dynamic batching are handled during back-propagation for the BVI operator. We will also add gradient-norm statistics and convergence diagnostics in the supplementary material to confirm training stability. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces BVI as a differentiable dynamic indexing operator that selects tokens based on mask information and DiffSim as an independent diffusion-process approximation for unmasked token influence in DiT self-attention. These components are presented as novel additions whose benefits (linear scaling with masked region size, up to 2.5X speedup) are validated empirically against external baselines rather than defined in terms of the outputs they produce. No equations, self-citations, or fitted parameters are shown that reduce any claim to its inputs by construction; the method is self-contained against measured performance.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Videopainter: Any- length video inpainting and editing with plug-and-play con- text control
Yuxuan Bian, Zhaoyang Zhang, Xuan Ju, Mingdeng Cao, Liangbin Xie, Ying Shan, and Qiang Xu. Videopainter: Any- length video inpainting and editing with plug-and-play con- text control. InSIGGRAPH, pages 1–12, 2025. 3, 6
2025
-
[2]
Dit4sr: Taming diffusion transformer for real-world image super-resolution
Zheng-Peng Duan, Jiawei Zhang, Xin Jin, Ziheng Zhang, Zheng Xiong, Dongqing Zou, Jimmy S Ren, Chunle Guo, and Chongyi Li. Dit4sr: Taming diffusion transformer for real-world image super-resolution. InICCV, pages 18948– 18958, 2025. 3
2025
-
[3]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[4]
Pengcheng Fang, Yuxia Chen, and Rui Guo. When and what: Diffusion-grounded videollm with entity aware segmenta- tion for long video understanding.CoRR, abs/2508.15641,
-
[5]
Dit4edit: Dif- fusion transformer for image editing
Kunyu Feng, Yue Ma, Bingyuan Wang, Chenyang Qi, Haozhe Chen, Qifeng Chen, and Zeyu Wang. Dit4edit: Dif- fusion transformer for image editing. InAAAI, pages 2969– 2977, 2025. 3
2025
-
[6]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InCVPR, pages 21807–21818, 2024. 6, 8
2024
-
[7]
Vace: All-in-one video creation and editing.ICCV, 2025
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing.ICCV, 2025. 2, 3, 6, 7, 1
2025
-
[8]
Dual prompting image restora- tion with diffusion transformers
Dehong Kong, Fan Li, Zhixin Wang, Jiaqi Xu, Renjing Pei, Wenbo Li, and WenQi Ren. Dual prompting image restora- tion with diffusion transformers. InCVPR, pages 12809– 12819, 2025. 2
2025
-
[9]
Magiceraser: Erasing any objects via semantics-aware control
Fan Li, Zixiao Zhang, Yi Huang, Jianzhuang Liu, Renjing Pei, Bin Shao, and Songcen Xu. Magiceraser: Erasing any objects via semantics-aware control. InECCV, pages 215–
-
[10]
Dif- fueraser: A diffusion model for video inpainting.arXiv preprint arXiv:2501.10018, 2025
Xiaowen Li, Haolan Xue, Peiran Ren, and Liefeng Bo. Dif- fueraser: A diffusion model for video inpainting.arXiv preprint arXiv:2501.10018, 2025. 6
-
[11]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review arXiv 2017
-
[12]
Grig: Data-efficient generative residual image inpainting
Wanglong Lu, Xianta Jiang, Xiaogang Jin, Yong-Liang Yang, Minglun Gong, Kaijie Shi, Tao Wang, and Hanli Zhao. Grig: Data-efficient generative residual image inpainting. Computational Visual Media, 11(6):1329–1361, 2025. 3
2025
-
[13]
arXiv preprint arXiv:2510.07741 , year=
Yuang Meng, Xin Jin, Lina Lei, Chun-Le Guo, and Chongyi Li. Ultraled: Learning to see everything in ultra-high dy- namic range scenes.arXiv preprint arXiv:2510.07741, 2025. 3
-
[14]
Rose: Remove objects with side effects in videos.NeurIPS, 2025
Chenxuan Miao, Yutong Feng, Jianshu Zeng, Zixiang Gao, Hantang Liu, Yunfeng Yan, Donglian Qi, Xi Chen, Bin Wang, and Hengshuang Zhao. Rose: Remove objects with side effects in videos.NeurIPS, 2025. 2, 3, 6
2025
-
[15]
Gross, and Alexander Sorkine- Hornung
Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus H. Gross, and Alexander Sorkine- Hornung. A benchmark dataset and evaluation methodology for video object segmentation. InCVPR, pages 724–732. IEEE Computer Society, 2016. 2, 6
2016
-
[16]
Unified transformed t-svd us- ing unfolding tensors for visual inpainting.Computational Visual Media, 2025
Mengjie Qin, Wen Wang, Honghui Xu, Te Li, Chunlong Zhang, and Minhong Wan. Unified transformed t-svd us- ing unfolding tensors for visual inpainting.Computational Visual Media, 2025. 3
2025
-
[17]
Robust unsupervised deep learning for nonblind image deconvolu- tion with inaccurate kernels.TNNLS, 2025
Xinran Qin, Yuhui Quan, Zhuojie Chen, and Hui Ji. Robust unsupervised deep learning for nonblind image deconvolu- tion with inaccurate kernels.TNNLS, 2025. 3
2025
-
[18]
Camedit: Continuous cam- era parameter control for photorealistic image editing
Xinran Qin, Zhixin Wang, Fan Li, Haoyu Chen, Renjing Pei, Wenbo Li, and Xiaochun Cao. Camedit: Continuous cam- era parameter control for photorealistic image editing. In NeurIPS, 2025. 3
2025
-
[19]
Disentangle to fuse: Towards content preservation and cross-modality con- sistency for multi-modality image fusion.TIP, 2026
Xinran Qin, Yuning Cui, Shangquan Sun, Ruoyu Chen, Wenqi Ren, Alois Knoll, and Xiaochun Cao. Disentangle to fuse: Towards content preservation and cross-modality con- sistency for multi-modality image fusion.TIP, 2026. 3
2026
-
[20]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 3, 1
work page internal anchor Pith review arXiv 2025
-
[21]
Chenyang Wu, Jiayi Fu, Chun-Le Guo, Shuhao Han, and Chongyi Li. Vtinker: Guided flow upsampling and texture mapping for high-resolution video frame interpolation.arXiv preprint arXiv:2511.16124, 2025. 2
-
[22]
Improved video vae for latent video diffusion model
Pingyu Wu, Kai Zhu, Yu Liu, Liming Zhao, Wei Zhai, Yang Cao, and Zheng-Jun Zha. Improved video vae for latent video diffusion model. InCVPR, pages 18124–18133, 2025. 2
2025
- [23]
-
[24]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[25]
Efros, Eli Shecht- man, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, pages 586–
-
[26]
Computer Vision Foundation / IEEE Computer Society,
-
[27]
Outdreamer: Video out- painting with a diffusion transformer.arXiv preprint arXiv:2506.22298, 2025
Linhao Zhong, Fan Li, Yi Huang, Jianzhuang Liu, Ren- jing Pei, and Fenglong Song. Outdreamer: Video out- painting with a diffusion transformer.arXiv preprint arXiv:2506.22298, 2025. 2
-
[28]
Propainter: Improving propagation and transformer for video inpainting
Shangchen Zhou, Chongyi Li, Kelvin CK Chan, and Chen Change Loy. Propainter: Improving propagation and transformer for video inpainting. InICCV, pages 10477– 10486, 2023. 3, 6
2023
-
[29]
Minimax-remover: Taming bad noise helps video object removal.NeurIPS,
Bojia Zi, Weixuan Peng, Xianbiao Qi, Jianan Wang, Shihao Zhao, Rong Xiao, and Kam-Fai Wong. Minimax-remover: Taming bad noise helps video object removal.NeurIPS,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.