JI-ADF: Joint-Individual Learning with Adaptive Decision Fusion for Multimodal Skin Lesion Classification
Pith reviewed 2026-07-01 08:57 UTC · model grok-4.3
The pith
JI-ADF uses joint learning and adaptive per-sample fusion of dermoscopic images, clinical photos, and metadata to classify skin lesions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
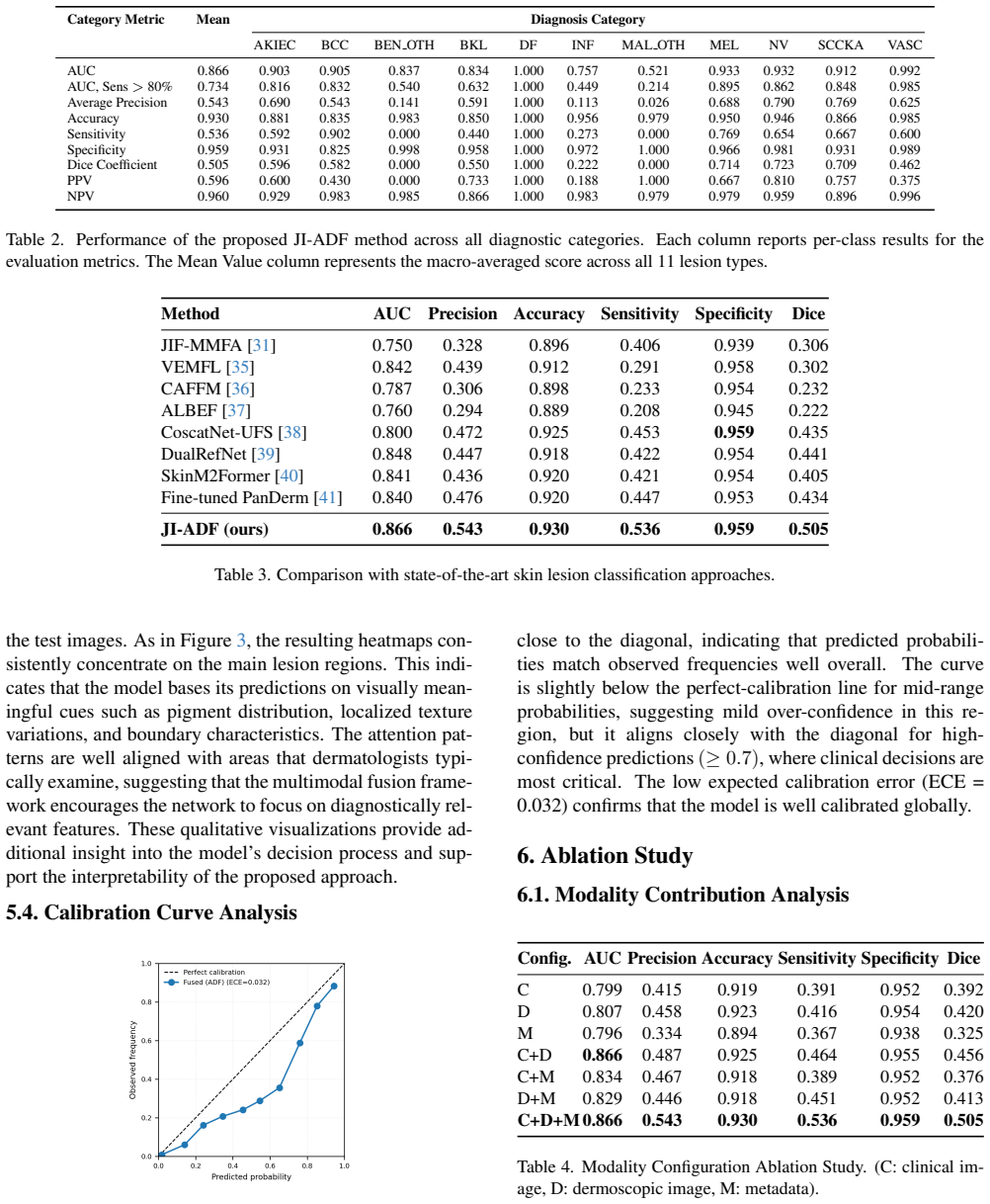
The JI-ADF architecture, by combining joint multimodal representation learning with modality-specific auxiliary supervision, an adaptive decision fusion mechanism, and the multimodal fusion attention module, delivers strong and well-balanced performance across lesion categories on the MILK10k benchmark, with gains in sensitivity and Dice score while retaining high specificity and good calibration.
What carries the argument
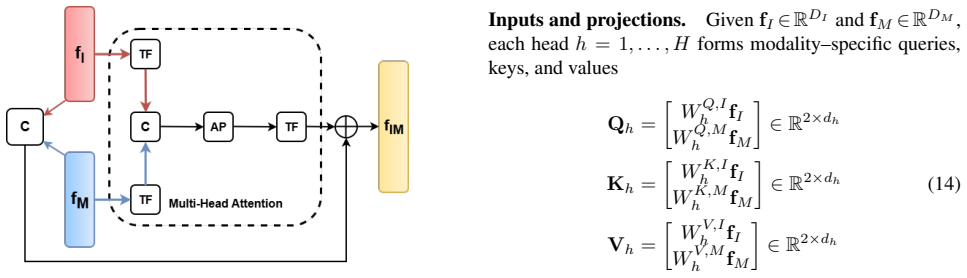
The adaptive decision fusion mechanism that dynamically calibrates modality contributions on a per-sample basis, supported by the multimodal fusion attention (MMFA) module inside the JI-ADF trimodal architecture.
If this is right
- Higher sensitivity and Dice scores while keeping high specificity across imbalanced lesion categories.
- More robust handling of real-world clinical acquisition variations and class imbalance.
- Verified behavior through modality ablation studies, calibration metrics, and attention visualizations.
- A practical base for using all three data types together in diagnostic support systems.
Where Pith is reading between the lines
- The per-sample weighting could reduce errors when one input type is noisy or incomplete in deployment.
- The same joint-individual plus adaptive fusion pattern may transfer to other multimodal medical tasks that mix images with structured records.
- External validation on datasets with different acquisition protocols would test whether the reported balance generalizes.
- Clinical integration would need checks on how performance shifts when metadata completeness varies.
Load-bearing premise
The adaptive decision fusion and MMFA module will generate clinically meaningful gains by dynamically adjusting per-sample modality contributions under the MILK10k acquisition conditions.
What would settle it
A controlled test on MILK10k showing that replacing adaptive fusion with fixed averaging or removing the MMFA module produces no measurable change in sensitivity, Dice score, or calibration.
Figures



read the original abstract
Skin lesion classification is essential for early dermatological diagnosis, yet many existing computer-aided systems rely primarily on dermoscopic images and underutilize the multimodal evidence routinely available in clinical practice. To address this gap, we propose \textbf{JI-ADF}, a trimodal deep learning framework that integrates dermoscopic images, clinical photographs, and structured patient metadata for clinically grounded skin lesion classification. The proposed architecture combines joint multimodal representation learning with modality-specific auxiliary supervision and an adaptive decision fusion mechanism that dynamically calibrates modality contributions on a per-sample basis. To enhance cross-modal reasoning while preserving modality-specific evidence, we further introduce a multimodal fusion attention (MMFA) module. We evaluate JI-ADF on the large-scale MILK10k benchmark, which reflects real-world clinical acquisition conditions and severe class imbalance. The proposed method demonstrates strong and well-balanced performance across lesion categories, improving sensitivity and Dice score while maintaining high specificity and good calibration. Extensive analyses, including modality ablation, calibration evaluation, and Grad-CAM visualization, further confirm the robustness and clinically meaningful behavior of the model. These results indicate that JI-ADF provides a reliable and practical foundation for multimodal skin lesion classification in real-world clinical settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes JI-ADF, a trimodal deep learning framework for skin lesion classification integrating dermoscopic images, clinical photographs, and structured patient metadata. It combines joint multimodal representation learning with modality-specific auxiliary supervision, an adaptive decision fusion mechanism that dynamically calibrates per-sample modality contributions, and a multimodal fusion attention (MMFA) module. Evaluation is on the MILK10k benchmark reflecting real-world acquisition and class imbalance; the abstract claims strong balanced performance across lesion categories, improved sensitivity and Dice score, maintained high specificity and good calibration, with supporting analyses via modality ablation, calibration evaluation, and Grad-CAM visualizations.
Significance. If the claimed performance gains and robustness hold with quantitative validation, JI-ADF could offer a practical advance for multimodal skin lesion classification by better utilizing routinely available clinical data sources and addressing class imbalance in real-world settings. The adaptive fusion and MMFA components target a clinically relevant gap in existing dermoscopy-focused systems.
major comments (1)
- [Abstract] Abstract: The central claims of 'strong and well-balanced performance', 'improving sensitivity and Dice score', 'good calibration', and robustness confirmed by ablation/calibration/Grad-CAM analyses are asserted without any quantitative results, baseline comparisons, error bars, statistical tests, or specific metric values. This absence makes it impossible to assess the magnitude or reliability of the reported improvements and directly undermines evaluation of the core contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below and agree that revisions to the abstract are warranted to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'strong and well-balanced performance', 'improving sensitivity and Dice score', 'good calibration', and robustness confirmed by ablation/calibration/Grad-CAM analyses are asserted without any quantitative results, baseline comparisons, error bars, statistical tests, or specific metric values. This absence makes it impossible to assess the magnitude or reliability of the reported improvements and directly undermines evaluation of the core contribution.
Authors: We acknowledge that the current abstract presents only qualitative claims. In the revised manuscript we will update the abstract to include specific quantitative results drawn from the experimental section (e.g., sensitivity, Dice score, specificity, and calibration metrics on MILK10k), along with brief mention of baseline comparisons. The full results, including error bars, statistical tests, ablation studies, calibration plots, and Grad-CAM visualizations, remain unchanged in the body of the paper; only the abstract summary will be augmented for clarity. revision: yes
Circularity Check
No significant circularity; empirical architecture with no derivation chain
full rationale
The paper introduces an empirical multimodal DL framework (JI-ADF) consisting of joint representation learning, auxiliary supervision, adaptive decision fusion, and an MMFA module, then reports benchmark performance on MILK10k. No equations, first-principles derivations, or predictions appear in the text. Performance claims rest on standard train/test evaluation, modality ablations, calibration metrics, and Grad-CAM visualizations rather than any fitted parameter renamed as a prediction or any self-citation that bears the central result. The architecture is therefore self-contained against external benchmarks with no reduction of outputs to inputs by construction.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.