Recognition: unknown
VeraRetouch: A Lightweight Fully Differentiable Framework for Multi-Task Reasoning Photo Retouching
Pith reviewed 2026-05-07 08:55 UTC · model grok-4.3
The pith
VeraRetouch replaces non-differentiable external tools with a custom renderer to allow end-to-end training of reasoning photo retouching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
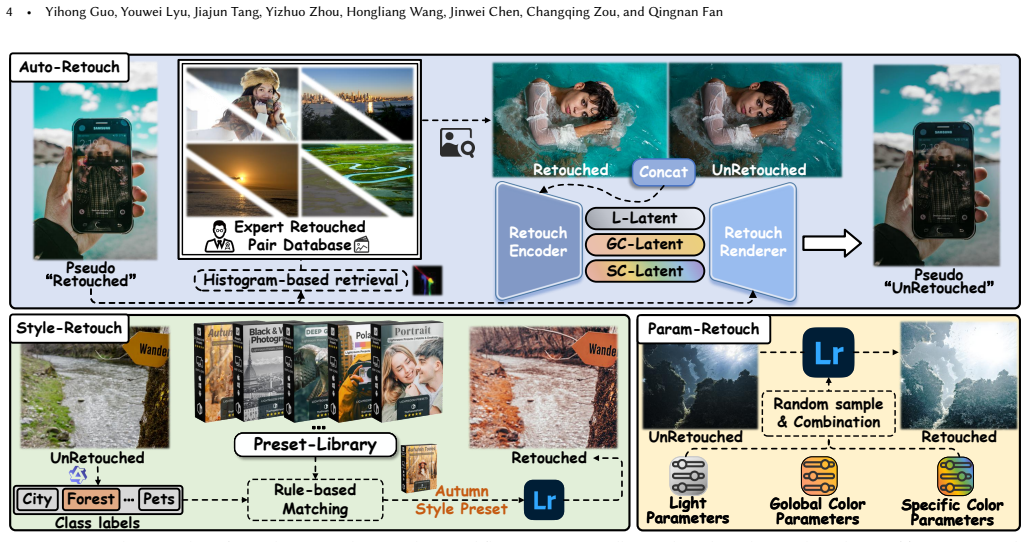
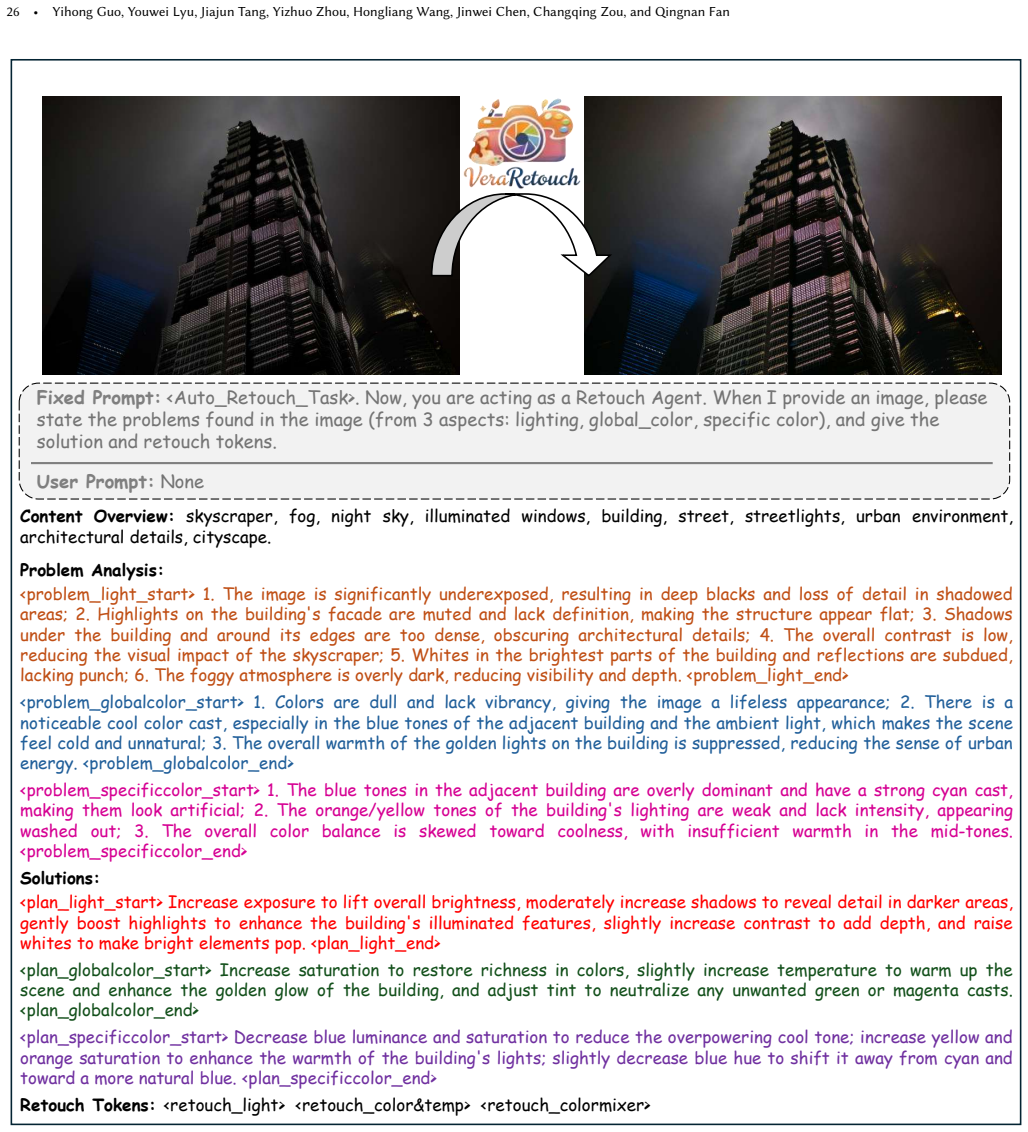
VeraRetouch shows that a compact 0.5B vision-language model can generate retouching plans from image semantics and instructions, which a fully differentiable Retouch Renderer then applies at the pixel level through decoupled control latents for lighting, global color, and specific colors. End-to-end training is enabled by the new AetherRetouch-1M+ dataset constructed via inverse degradation and by DAPO-AE reinforcement learning post-training, producing superior multi-task performance in a lightweight model suitable for mobile use.
What carries the argument
The fully differentiable Retouch Renderer, which applies retouching effects using decoupled control latents for lighting, global color, and specific color adjustments to support direct end-to-end pixel-level optimization.
If this is right
- Retouching plans can be optimized directly at the pixel level without barriers from non-differentiable external software.
- Model size remains small enough to support mobile deployment while matching benchmark performance of larger systems.
- Large-scale professional retouching datasets can be generated automatically through the inverse degradation workflow.
- Reinforcement learning post-training improves the model's ability to make autonomous aesthetic judgments.
Where Pith is reading between the lines
- The decoupled control latents could be extended to support additional operations such as local sharpening or texture adjustments in other editing tasks.
- Inverse degradation methods for dataset creation offer a reusable approach for generating training pairs in related low-data image processing problems.
- On-device reasoning for photo edits may reduce the need for cloud-based processing in consumer photography tools.
Load-bearing premise
The Retouch Renderer can faithfully reproduce professional retouching effects using only the decoupled control latents for lighting, global color, and specific colors without introducing artifacts or losing fidelity compared to external tools.
What would settle it
If images produced by the Retouch Renderer receive consistently lower quality scores or human preference ratings than identical adjustments made with external professional software, the claim that the renderer enables faithful end-to-end training would be refuted.
Figures



































read the original abstract
Reasoning photo retouching has gained significant traction, requiring models to analyze image defects, give reasoning processes, and execute precise retouching enhancements. However, existing approaches often rely on non-differentiable external software, creating optimization barriers and suffering from high parameter redundancy and limited generalization. To address these challenges, we propose VeraRetouch, a lightweight and fully differentiable framework for multi-task photo retouching. We employ a 0.5B Vision-Language Model (VLM) as the central intelligence to formulate retouching plans based on instructions and scene semantics. Furthermore, we develop a fully differentiable Retouch Renderer that replaces external tools, enabling direct end-to-end pixel-level training through decoupled control latents for lighting, global color, and specific color adjustments. To overcome data scarcity, we introduce AetherRetouch-1M+, the first million-scale dataset for professional retouching, constructed via a new inverse degradation workflow. Furthermore, we propose DAPO-AE, a reinforcement learning post-training strategy that enhances autonomous aesthetic cognition. Extensive experiments demonstrate that VeraRetouch achieves state-of-the-art performance across multiple benchmarks while maintaining a significantly smaller footprint, enabling mobile deployment. Our code and models are publicly available at https://github.com/OpenVeraTeam/VeraRetouch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VeraRetouch, a lightweight fully differentiable framework for multi-task reasoning photo retouching. It centers a 0.5B VLM to generate retouching plans from instructions and scene semantics, paired with a fully differentiable Retouch Renderer that uses decoupled control latents for lighting, global color, and specific color adjustments to enable end-to-end pixel-level optimization. To address data scarcity, it introduces the AetherRetouch-1M+ dataset constructed via an inverse degradation workflow and DAPO-AE, a reinforcement learning post-training strategy to improve autonomous aesthetic cognition. The central claim is that this yields state-of-the-art performance across multiple benchmarks while maintaining a significantly smaller footprint suitable for mobile deployment.
Significance. If the empirical claims hold, the work would be significant for enabling end-to-end differentiable retouching pipelines that avoid non-differentiable external tools, potentially improving optimization and generalization in photo editing tasks. The scale of the introduced dataset and the RL post-training approach for aesthetic reasoning represent potentially useful resources for the community, and the emphasis on a compact model footprint directly addresses practical deployment constraints in computer vision applications.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The manuscript asserts state-of-the-art performance on multiple benchmarks but reports no quantitative metrics, baseline comparisons, ablation studies, or error analysis. This absence prevents verification of whether the data and methods support the central claims of superior performance and differentiability benefits.
- [§3.2] §3.2 (Retouch Renderer): The claim that the fully differentiable renderer faithfully replicates professional retouching operations using only decoupled control latents for lighting, global color, and specific colors lacks supporting evidence on artifact introduction or fidelity loss relative to external tools; this is load-bearing for the end-to-end training argument.
- [§3.3] §3.3 (Dataset construction): The inverse degradation workflow used to build AetherRetouch-1M+ is described at a high level but without details on how it avoids circularity with the training objective or ensures professional-quality ground truth, which is critical for the data-scarcity solution.
minor comments (2)
- [Appendix or §4] The paper mentions public code and models at a GitHub link but does not include any reproducibility checklist or details on training hyperparameters in the main text.
- [§3.2] Notation for the control latents (lighting, global color, specific color) is introduced without a clear mathematical formulation or diagram showing their decoupling.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The manuscript asserts state-of-the-art performance on multiple benchmarks but reports no quantitative metrics, baseline comparisons, ablation studies, or error analysis. This absence prevents verification of whether the data and methods support the central claims of superior performance and differentiability benefits.
Authors: We acknowledge that the experimental section requires more explicit quantitative support to substantiate the SOTA claims. While some results are presented, the manuscript does not include sufficient tables with metrics, direct baseline comparisons, ablations, or error analysis. In the revised manuscript, we will expand §4 with detailed quantitative metrics (PSNR, SSIM, LPIPS, aesthetic scores), comparisons against relevant baselines, ablation studies on the VLM, renderer, and RL components, and an error analysis discussing limitations and failure cases. This will enable verification of the performance and differentiability claims. revision: yes
-
Referee: [§3.2] §3.2 (Retouch Renderer): The claim that the fully differentiable renderer faithfully replicates professional retouching operations using only decoupled control latents for lighting, global color, and specific colors lacks supporting evidence on artifact introduction or fidelity loss relative to external tools; this is load-bearing for the end-to-end training argument.
Authors: We agree that additional evidence is needed to support the renderer's fidelity claim. The current description focuses on the decoupled latents but does not provide direct comparisons to external tools. We will revise §3.2 to include quantitative fidelity evaluations (e.g., SSIM, perceptual metrics) and visual comparisons of outputs against professional software such as Adobe Lightroom, along with analysis of artifact introduction. This will better substantiate the benefits for end-to-end training. revision: yes
-
Referee: [§3.3] §3.3 (Dataset construction): The inverse degradation workflow used to build AetherRetouch-1M+ is described at a high level but without details on how it avoids circularity with the training objective or ensures professional-quality ground truth, which is critical for the data-scarcity solution.
Authors: We recognize that more details are required on the dataset construction process. The inverse degradation workflow is intended to generate paired data from professional edits, but the manuscript lacks specifics on circularity avoidance and quality assurance. We will expand §3.3 with concrete details: use of held-out professionally retouched images for validation to prevent circularity, step-by-step workflow explanations, and quality control measures involving expert retouchers to ensure professional ground truth. This will clarify how the data-scarcity solution is robust. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The abstract presents VeraRetouch as introducing independent components: a 0.5B VLM for retouching plan formulation, a fully differentiable Retouch Renderer using decoupled control latents, the AetherRetouch-1M+ dataset via inverse degradation workflow, and DAPO-AE RL post-training. No equations, self-definitions, or load-bearing claims are shown that reduce outputs to inputs by construction (e.g., no fitted parameters renamed as predictions or uniqueness theorems from self-citations). The methods address data scarcity and optimization barriers as external contributions, keeping the central SOTA claim self-contained without circular reductions visible in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The inverse degradation workflow produces high-quality, diverse professional retouching data representative of real scenarios.
- domain assumption Decoupled control latents for lighting, global color, and specific color adjustments can independently and accurately control retouching operations in a differentiable manner.
invented entities (2)
-
Retouch Renderer
no independent evidence
-
DAPO-AE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
FLUX. 1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space.arXiv preprint arXiv:2506.15742(2025). Jie Liang, Hui Zeng, Miaomiao Cui, Xuansong Xie, and Lei Zhang. 2021. Ppr10k: A large-scale portrait photo retouching dataset with human-region mask and group- level consistency. InProceedings of the IEEE/CVF Conference on Comp...
work page internal anchor Pith review arXiv 2025
-
[2]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deeplpf: Deep local parametric filters for image enhancement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12826–12835. Temesgen Muruts Weldengus, Binnan Liu, Fei Kou, Youwei Lyu, Jinwei Chen, Qingnan Fan, and Changqing Zou. 2025. InstantRetouch: Personalized Image Retouching without Test-time Fine-tuning Using an A...
2025
-
[3]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Rsfnet: A white-box image retouching approach using region-specific color filters. InProceedings of the IEEE/CVF International Conference on Computer Vision. 12160–12169. Zhaoqing Pan, Feng Yuan, Jianjun Lei, Wanqing Li, Nam Ling, and Sam Kwong. 2021. MIEGAN: Mobile image enhancement via a multi-module cascade neural network. IEEE Transactions on Multimed...
work page internal anchor Pith review arXiv 2021
-
[4]
InEuropean Conference on Computer Vision
NamedCurves: Learned Image Enhancement via Color Naming. InEuropean Conference on Computer Vision. Springer, 92–108. Unsplash. 2024. Unsplash Dataset. https://unsplash.com/data. Accessed: 2025-06-20. Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokula Santhanam, James Gabriel, Peter Grasch, Oncel Tuzel, et al
2024
-
[5]
Fastvlm: Efficient vision encoding for vision language models. InProceedings of the Computer Vision and Pattern Recognition Conference. 19769–19780. Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. 2025. Qwen-image technical report.arXiv preprint arXiv:2508.02324(2025). Haoning ...
work page internal anchor Pith review arXiv 2025
-
[6]
<problem_light_end> <problem_globalcolor_start> 1
The subject’s face and hands lack proper lighting balance, appearing washed or shadowed depending on the position. <problem_light_end> <problem_globalcolor_start> 1. Colors are oversaturated and unnatural, especially greens and yellows, giving the scene an artificial glow; 2. The overall color temperature is too warm, causing a yellow-green tint that detr...
2026
-
[7]
<problem_globalcolor_end> <problem_specificcolor_start> 1
The warm golden tones of the fried food and sauce are not fully realized, reducing the appetizing quality of the image. <problem_globalcolor_end> <problem_specificcolor_start> 1. The orange tones in the food and sauce appear washed out and lean towards yellow, reducing their richness and appeal; 2. The reds in the garnish are muted and lack intensity, mak...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.