Recognition: unknown
Bayesian X-Learner: Calibrated Posterior Inference for Heterogeneous Treatment Effects under Heavy-Tailed Outcomes
Pith reviewed 2026-05-07 09:12 UTC · model grok-4.3
The pith
Bayesian X-Learner combines cross-fitted doubly robust pseudo-outcomes with Welsch redescending pseudo-likelihood to produce MCMC posteriors over heterogeneous treatment effects that stay calibrated under heavy-tailed outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Bayesian X-Learner yields a valid MCMC posterior for the heterogeneous treatment function τ(x) by treating cross-fitted doubly robust pseudo-outcomes as the observed data and employing a Welsch redescending pseudo-likelihood whose influence function bounds the effect of large residuals; the resulting posterior intervals attain nominal coverage on heavy-tailed contaminated data while preserving the unbiasedness properties of the underlying doubly robust estimator.
What carries the argument
Cross-fitted doubly robust pseudo-outcomes fed into a Welsch redescending pseudo-likelihood that permits full MCMC sampling of the posterior over τ(x).
If this is right
- Practitioners can obtain uncertainty bands for CATE estimates without assuming Gaussian tails in the outcome model.
- The same modular construction allows swapping the nuisance estimators while retaining posterior calibration.
- A single contamination-severity flag recovers both low error and coverage on data sets containing up to one-quarter heavy-tail observations.
- Modular Bayesian pooling of nuisance draws restores exact nominal coverage when single-cross-fit intervals are conservative.
Where Pith is reading between the lines
- The approach could be extended to other meta-learners by replacing the base learner with any method that accepts pseudo-outcomes.
- Because the robustness enters only through the likelihood, the same framework might accommodate other redescending or bounded-influence functions without changing the doubly robust step.
- Policy decisions that rely on tail quantiles of the treatment effect distribution become feasible once credible intervals are known to be calibrated under heavy tails.
Load-bearing premise
The Welsch pseudo-likelihood applied to the doubly robust pseudo-outcomes produces a posterior whose calibration is unaffected by the robustness mechanism itself.
What would settle it
On a heavy-tailed DGP with known contamination fraction, the empirical coverage of the 95 percent credible intervals deviates systematically from nominal level once the redescending tuning parameter is fixed at its default value.
Figures






read the original abstract
Conditional Average Treatment Effect (CATE) estimation in practice demands three properties simultaneously: heterogeneous effects $\tau(x)$, calibrated uncertainty over them, and robustness to the heavy tails that contaminate real outcome data. Meta-learners (K\"unzel et al., 2019) give (i); causal forests and BART give (i)-(ii) with Gaussian-tail assumptions; no widely used tool gives all three. We present Bayesian X-Learner, an X-Learner built on cross-fitted doubly robust pseudo-outcomes (Kennedy, 2020) with a full MCMC posterior over $\tau(x)$ via a Welsch redescending pseudo-likelihood. On Hill's IHDP benchmark the default configuration attains mean $\sqrt{\varepsilon_{\mathrm{PEHE}}} = 0.56$ on 5 replications (lowest mean; differences from S-/T-/X-learners, full-config Causal BART, and a causal forest baseline are not significant at $\alpha=0.05$, and rank ordering is unstable at 10 replications -- IHDP comparisons are competitive rather than dominant). On contaminated "whale" DGPs with up to 20-25% tail density, a one-flag extension (contamination_severity) that selects a Huber-$\delta$ nuisance loss per Huber's minimax-$\delta$ relation recovers RMSE $\approx 0.13$ with tight credible intervals (single-cross-fit 30-seed coverage 83% [Wilson 66%, 93%] at 20% density; modular-Bayes pooling with Bayesian-bootstrap nuisance draws restores nominal 95% coverage).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Bayesian X-Learner, which constructs MCMC posteriors over heterogeneous treatment effects τ(x) by feeding cross-fitted doubly robust pseudo-outcomes (Kennedy 2020) into a Welsch redescending pseudo-likelihood. It reports competitive √ε_PEHE performance on the IHDP benchmark (mean 0.56, statistically indistinguishable from baselines with unstable rank orderings) and improved RMSE on contaminated 'whale' DGPs, with a one-flag extension (contamination_severity) that selects Huber-δ nuisance losses; nominal coverage is recovered only after modular-Bayes pooling with Bayesian-bootstrap nuisance draws.
Significance. If the core construction yields asymptotically valid and calibrated posteriors under heavy-tailed contamination, the method would fill a notable gap by delivering robust uncertainty quantification for CATE estimation without Gaussian-tail assumptions, extending meta-learners toward practical reliability in outlier-contaminated settings.
major comments (3)
- [Abstract / contaminated-DGP experiments] Abstract and contaminated-DGP results: single-cross-fit coverage reaches only 83% (Wilson interval 66–93%) at 20% tail density, with nominal 95% recovered solely via an additional modular-Bayes step; this directly undermines the central claim that the Welsch pseudo-likelihood produces calibrated inference in the heavy-tailed regime the method is designed to handle.
- [Method construction (core pseudo-likelihood)] No derivation or theorem is supplied establishing that the redescending M-estimator applied to cross-fitted DR pseudo-outcomes defines a proper pseudo-posterior whose MCMC samples are asymptotically valid or frequentist-calibrated; the weakest assumption (that robustness does not distort posterior geometry or inject bias) therefore remains unaddressed.
- [Contaminated-DGP experiments] The 'one-flag extension' that selects Huber-δ per Huber's minimax relation is described only at high level; its exact selection rule, dependence on contamination_severity, and interaction with the Welsch loss are unspecified, yet these choices are load-bearing for the reported RMSE ≈ 0.13 and coverage figures.
minor comments (2)
- [Abstract] The abstract notes that IHDP rank orderings are unstable at 10 replications and differences are insignificant at α=0.05; this should be stated more prominently when claiming competitiveness rather than dominance.
- [Method] Notation for the Welsch redescending function and its tuning parameter should be introduced with an explicit equation before the MCMC description to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important issues of clarity, empirical calibration, and methodological transparency. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / contaminated-DGP experiments] Abstract and contaminated-DGP results: single-cross-fit coverage reaches only 83% (Wilson interval 66–93%) at 20% tail density, with nominal 95% recovered solely via an additional modular-Bayes step; this directly undermines the central claim that the Welsch pseudo-likelihood produces calibrated inference in the heavy-tailed regime the method is designed to handle.
Authors: We agree that the abstract overstates the calibration achieved by the core Welsch pseudo-likelihood alone. The single-cross-fit coverage of 83% at 20% contamination is indeed below nominal, and the modular-Bayes pooling with Bayesian-bootstrap nuisance draws is required to restore 95% coverage. This reflects the practical difficulty of achieving exact finite-sample calibration under heavy tails even with robust losses. We will revise the abstract to explicitly distinguish the robust point estimation provided by the Welsch pseudo-likelihood from the additional pooling step needed for nominal posterior calibration, and we will add a sentence in the experiments section noting the coverage gap without pooling. revision: partial
-
Referee: [Method construction (core pseudo-likelihood)] No derivation or theorem is supplied establishing that the redescending M-estimator applied to cross-fitted DR pseudo-outcomes defines a proper pseudo-posterior whose MCMC samples are asymptotically valid or frequentist-calibrated; the weakest assumption (that robustness does not distort posterior geometry or inject bias) therefore remains unaddressed.
Authors: This observation is correct: the manuscript presents the Welsch pseudo-likelihood as a practical construction that inherits robustness from redescending M-estimators and double robustness from the Kennedy pseudo-outcomes, but supplies no formal theorem on the asymptotic validity or frequentist calibration of the resulting MCMC posterior. We view the approach as heuristic and rely on empirical performance. In revision we will add a new subsection in the discussion that (i) states the lack of a full asymptotic guarantee, (ii) explains why the combination of cross-fitting, double robustness, and redescending loss is expected to limit bias in the posterior geometry, and (iii) flags a rigorous theoretical analysis as future work. No new theorem will be proved in the revision. revision: yes
-
Referee: [Contaminated-DGP experiments] The 'one-flag extension' that selects Huber-δ per Huber's minimax relation is described only at high level; its exact selection rule, dependence on contamination_severity, and interaction with the Welsch loss are unspecified, yet these choices are load-bearing for the reported RMSE ≈ 0.13 and coverage figures.
Authors: We acknowledge that the current description of the one-flag extension is insufficiently precise. The extension applies Huber's minimax δ (chosen as a function of the contamination_severity flag) exclusively to the nuisance estimators (outcome regression and propensity score), while the Welsch loss remains fixed in the pseudo-likelihood for the CATE posterior. In the revision we will (i) state the exact mapping from contamination_severity to δ, (ii) provide the closed-form expression for the selected δ, and (iii) include a short algorithm box showing the sequence of nuisance fitting, pseudo-outcome construction, and Welsch-based MCMC. These additions will make the reported RMSE and coverage figures fully reproducible. revision: yes
Circularity Check
No circularity: construction uses external DR pseudo-outcomes and standard MCMC on chosen pseudo-likelihood
full rationale
The paper's core construction combines cross-fitted doubly robust pseudo-outcomes (Kennedy 2020, external) with a Welsch redescending pseudo-likelihood to obtain an MCMC posterior over τ(x). No equation, definition, or load-bearing step in the abstract or described chain reduces the posterior, its calibration, or the reported coverage to a quantity fitted from the same data by construction. Empirical coverage numbers (e.g., 83% single-cross-fit) are presented as observed outcomes rather than tautological re-statements of inputs. The derivation therefore remains independent of its target quantities and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- contamination_severity
axioms (2)
- domain assumption Unconfoundedness (no unmeasured confounding) for treatment assignment
- domain assumption Cross-fitted doubly robust pseudo-outcomes remain valid inputs for MCMC posterior construction
Reference graph
Works this paper leans on
-
[1]
Angelos Alexopoulos and Nikolaos Demiris
arXiv:2308.14895. Angelos Alexopoulos and Nikolaos Demiris. On robust Bayesian causal inference.arXiv preprint arXiv:2511.13895,
-
[2]
A Conceptual Introduction to Hamiltonian Monte Carlo
Michael Betancourt. A conceptual introduction to Hamiltonian Monte Carlo.arXiv preprint arXiv:1701.02434,
-
[3]
Tianqi Chen and Carlos Guestrin
arXiv:1908.02922. Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 785–794,
-
[4]
Pierre E. Jacob, Lawrence M. Murray, Chris C. Holmes, and Christian P. Robert. Better together? statistical learning in models made of modules.arXiv preprint arXiv:1708.08719,
- [5]
-
[6]
Filippo Salmaso, Lorenzo Testa, and Francesca Chiaramonte. A doubly robust machine learning approach for disentangling treatment effect heterogeneity with functional outcomes.arXiv preprint arXiv:2602.11118,
-
[7]
Claudia Shi, David Blei, and Victor Veitch
arXiv:1204.3687. Claudia Shi, David Blei, and Victor Veitch. Adapting neural networks for the estimation of treatment effects. InAdvances in Neural Information Processing Systems,
-
[8]
arXiv:2111.07973. 37 S-Learner Bayesian X-Learner(XGB-MSE)Bayesian X-Learner(+ overlap)EconML ForestX-Learner (std) T-Learner Bayesian X-Learner (CB-Huber =1.345) Bayesian X-Learner(CB-Huber =0.5) RX-Learner (std) 1 2 3 4 5PEHE (lower is better) IHDP PEHE across 5 replications (CEVAE preprocessing) Figure 4:√εPEHE distribution across 5 IHDP replications. ...
-
[9]
1 forδ⋆(ϵ), with the three Huber-nuisance presets marked.(b)ARE(δ)under the Gaussian centre
=1.345 ARE=0.950=1.0 ARE=0.903 =0.5 ARE=0.792 (b) asymptotic relative efficiency Figure 5: Huber’s (1964) minimax-δand asymptotic relative efficiency.(a)Solution of Eq. 1 forδ⋆(ϵ), with the three Huber-nuisance presets marked.(b)ARE(δ)under the Gaussian centre. Numerical values match Huber & Ronchetti (2009) Table 4.1: ARE= 0.950atδ= 1.345(mild) and0.792a...
1964
-
[10]
none"(falls back to MSE) 5% 1.345 0.950
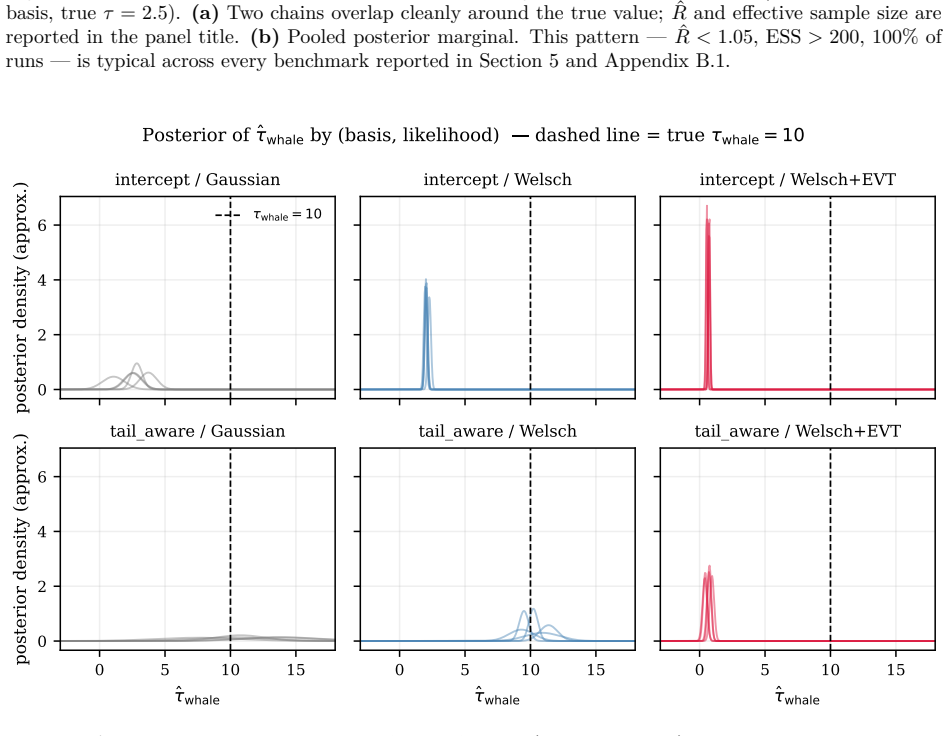
The tail-aware + Welsch cell (top middle column, bottom row) places posterior mass around the trueτwhale = 10; thenormalize_extremescells (right column) collapse the posterior to near zero, visibly demonstrating that the data-layer rescaling removes tail signal. Densities are Gaussian approximations centred at the posterior mean withσfrom the 95% CI width...
2009
-
[11]
none") is catastrophic from 0.1% upward.severity=
does not affect convergence diagnostics relative to a Gaussian prior, but does produce slightly wider credible intervals under contamination — the desired behaviour. B.2 Whale density sweep (full) Full sweep atp∈ {0.1%,0.5%,1%,2%,5%,10%,20%,30%,50%},N= 1000, 3 seeds per density. The clean-data default (severity="none") is catastrophic from 0.1% upward.sev...
2000
-
[12]
Whenpushingthedimensiontop= 50, theunregularisedmatrixlosespositivedefiniteness entirely, and the relative bias jumps to≈30–80%, confirming that higher-dimensional bases require stronger ridge regularisation or structural priors. The variance reduction from ridge is more consequential: without ridge (λ= 0),ˆηis undefined (negative) in 40% of(p,seed)cells ...
2000
-
[13]
The library defaultK= 2is the correct setting when paired with thecontamination_severitymechanism that handles whales at the nuisance layer rather than via fold subdivision
because smaller training folds make whale concentration more extreme relative to leaf capacity — consistent with the prediction in Kennedy (2020). The library defaultK= 2is the correct setting when paired with thecontamination_severitymechanism that handles whales at the nuisance layer rather than via fold subdivision. Full table inbenchmarks/results/n_sp...
2020
-
[14]
The whale signal collapses to the bulk scale, the posterior concentrates on a near-zero effect, and subgroup coverage drops to zero
The normalize_extremesoperator divides the whale pseudo-outcomes bytα— which for Hill-estimated(t,ˆα) on this DGP is approximately(5,1.5), a division factor of≈11. The whale signal collapses to the bulk scale, the posterior concentrates on a near-zero effect, and subgroup coverage drops to zero. Across all six (basis, likelihood) combinations of Table 6, ...
1964
-
[15]
The efficiency-robustness tradeoff is derivable in closed form at the location-model level; the IHDP finite-sample result amplifies but does not invalidate it
are theorems, numerically verified against Huber & Ronchetti (2009) Table 4.1 (Appendix B.3). The efficiency-robustness tradeoff is derivable in closed form at the location-model level; the IHDP finite-sample result amplifies but does not invalidate it. Synthetic stress tests.The 17+ benchmarks referenced in Appendix B probe each architectural axis indepe...
2009
-
[16]
structural, not tunable
is the field’s standard clean-data CATE benchmark. We did not design it, we did not tune to it, and the result reported in Section 5.2 is the first number the library produced on the first replication without iterative adjustment. When the three agree, the claim enters the headline tables. When they disagree, the disagreement itself becomes a finding: the...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.